Open Science has been a long-standing ideal for many researchers and practitioners around the world. It advocates the open sharing of scientific research, data, processes, and tools and encourages open collaboration. While not without challenges, this mode of scientific research has the potential to change the entire course of science, allowing for more rigorous peer-review and large-scale scientific projects, accelerating progress, and enabling otherwise unimaginable discoveries.
As with any great idea, there are a number of obstacles to such a thing going mainstream. The biggest one is certainly the existing incentive system that lies at the foundation of the academic world. A limited number of opportunities, relentless competition, and pressure to “publish or perish” usually end up incentivizing exactly the opposite – keeping results closed and doing everything to gain a competitive edge. Still, against all odds, a number of successful Open Science projects are out there in the wild, making profound impacts on their respective fields. HapMap Project, OpenWorm, Sloan Digital Sky Survey and Polymath Project are just a few to name. And the whole movement is just getting started.
While some of these challenges are universal, when it comes to Biology and Biomedical Engineering, the road to Open Science is paved with problems that will go beyond crafting proper incentives for researchers and academic institutions.
It will require building hardware.
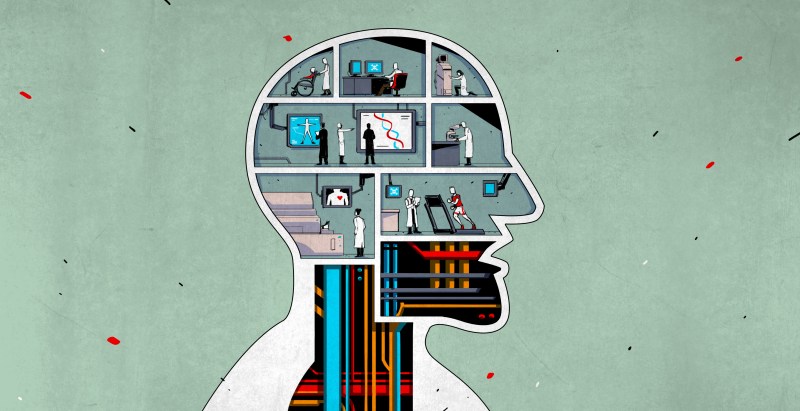
At this year’s SXSW Interactive, we had an opportunity to talk with [Charles Fracchia], a renaissance hacker at the MIT Media Lab. Reinforcing the Media Lab’s “eclectic genius” stereotype, [Charles]’s background spans an impressive range of fields—from Synthetic Biology to Biomedical Engineering and beyond. A biologist by training, he is also a self-taught hardware hacker and, these days, is spending most of his time building “hybrid” systems at the intersection of Biology, Computer Science, and Electrical Engineering. True to the hacker spirit of open collaboration and sharing, he is also a big proponent of Open Science and is committed to making it a reality in the field of Biomedical Research.
Most of [Charles’] recent work has been motivated by the surprising fact that a vast proportion of peer-reviewed biological research is not independently reproducible[1]. Reproducibility is a huge challenge in this field, and part of the problem lies in the fact that a number of environmental factors that could impact the results of the experiments are currently not captured at all. The solution that [Charles] and his team are working on is a range of environmental sensor nodes, designed to be packaged as a part of the standard biological lab equipment. Such nodes could enable an easy collection of necessary data in a “natural” environment of the experiment, making it easier to pinpoint the exact conditions under which the results were obtained.
It is projects like this, especially if created as Open Hardware, which have the potential to change the Open Science game in Biomedical Research. Affordable, peer-reviewed hardware that every lab can independently manufacture can show the way to standardization in the sharing of experimental data. [Charles] and his team are committed to this mission and are taking things beyond academia and into the real world. They are starting a project called BioBright, which aims at revolutionizing the biology lab and making Open Science in this space a reality.
References:
[1] Challenges in Irreproducible Research” Nature Magazine













This reminds me of “Little Computer People” on the Commodore 64, back in the day. (At least the title graphic does.)
This could be relevant: http://www.biomedcentral.com/1752-0509/8/124
To my layman’s eyes, it looks like they use computer vision to recognize synthetic biological-like molecules that are generated by an algorithm. If so, then the problem domain ought to be closely related to the sensors that the hacker suggests, presenting an opportunity for meaningful abstraction.
Look at slicer.org development history for a cautionary tail of FDA politics strangling a well funded working open-source projects.
If these MIT people succeed, they will still run into the same legal problems once they attempt to use it outside in-house evaluative research.
Its a suckers game for this type of project.
Thanks for the slicer.org pointer. I’ll look into this more closely.
You are absolutely correct with regards to FDA being a challenging process. And while there are some encouraging signs that they are looking to create processes to allow for a quicker pace of innovation [1], it remains difficult to transition out of a research setting without significant funding and more traditional structures.
That’s actually one of the main reasons we are looking at focusing on biological research settings at first. And only later, providing we have the right partners, we will explore the FDA regulated processes. We also have much more first hand expertise of the biological research workflow and we think there is more immediate impact to be made there.
That being said, if we are unable to look into the hairier FDA-affected problems (or not quickly enough), we will be looking to enable someone who can for sure. We are looking carefully at how we structure our efforts in a way that can accommodate that type of collaboration without suffocating or jeopardizing the open-source parts. That’s far from being a trivial thing to do, and we are not ready to make any claims about it yet, but it is certainly a core concern of ours. There’s a reason our project is on a specific TLD :p
Oh and by the way, if that is something anyone has special knowledge about, I am very keen to talk with them :D
[1] http://www.fda.gov/AboutFDA/CentersOffices/OfficeofMedicalProductsandTobacco/CDRH/CDRHInnovation/InnovationPathway/default.htm
We are doing similar work, and I love your project concept.
However, you are filing IP with the University Liaison Office, and this means a legal minefield for later technology mergers given licensing complexity excludes small entity cooperation. Thus, we must assume your funding is likely not a true “White Knight” grant. Consequently, we must currently isolate you from our Apache/BSD licensed works set for publication soon, but you are welcome to fork our systems as required.
I already like my job.
;-)
That’s great to hear. This is a problem that is so multi-faceted, it really requires as many people as possible working on all aspects of it in parallel.
But you are making assumptions with regards to the IP and the funding. This article presents my work in general and doesn’t address those questions. In fact, in many of these cases, there really is no / should not be any enforceable IP given such strong prior art. The licensing we have in mind has very strong provisions to enable collaborations with other small entities and individuals.
With regards to forking, I would love to! If you guys are solving/have solved a problem that we don’t have to solve then that’s great! It means we can focus on the next challenge on this long list :)
I’d love to chat further, if you guys are out of stealth mode.
It sounds like you guys/gals are doing interesting, potentially complementary, work :)
I’m not gonna post my email directly here for bots reasons, but it’s easy to find :D
I find it funny that the “mic” that she’s using looks like a taser. Lucky for Caleb not to be there. Oddly though, I’m not sure way, but that image behind him keeps making me think of a memory sector for a boot loader. Is it a visual image of bit-mapped code?
@ganzuul: Thanks for the reference. Absolutely relevant, a technique like this could be incorporated to start validating hypotheses we have of the system. Systems biology as a field has been trying to generate models of this kind, and they can be tremendously insightful. What we are currently focusing on though is the complementary side of gathering experimental data because, to our knowledge, no one is really working to consolidate the collection of this data in an open way. What we want to do eventually is to be able to provide this data to further train, inform and modify these models. We’re trying to connect the so-called “top-down” and “bottom-up” approaches.
@Rollyn01: Ha. Yes, that’s the new MIT Media Lab logo. The idea is that each group at the lab has their own represented by their initials. For example my group is Molecular Machines and looks like two short Ms on top of each other. The one for the whole lab is the one closest to my chubby beard on the youtube video thumbnail. It looks like a smiley face at 45 degrees and spells M L.
:)
I was wondering about that. I thought I was going crazy or something. I like it. How many were doing it and do the highlighted ones symbolize anything?
So, I confirmed with the person who designed the specific poster (not the logo, that was done by someone else), and each group at the Media Lab has their glyph highlighted in red once. There’s a write up here regarding the new logo / identity: http://www.underconsideration.com/brandnew/archives/new_logo_and_identity_for_mit_media_lab_by_pentagram.php
Very nice, thanks. I knew there was something more to it, but I couldn’t quite put my finger on it. After following the link, I feel rather silly for not being able to realize what it actually meant. Funny thing is, I could see this as being used as part of a 2D QR-code image. I think there was something about that on HackADay some time back.
New Open Science Hardware
Open Source Bio
https://www.youtube.com/watch?v=M5Y7ac4aSkQ
This is awesome!
I emailed you guys :)
The whole reproducibility angle is a theme that a number of folks in the syn-bio field seem to have recognized almost simultaneously (BioBright being a great example and Antha being another).
The emerging virlew seems to be that bological systems are reliable machinery IF you can properly identify and control the high-dimensional, often highly non-linear variable space that dictates outcomes. I was actually amazed how many times that very theme popped up at SXSW from people who seemed to arrive at the concept independently, at very nearly the same point in time.