
Evolution is one clever fellow. Next time you’re strolling about outdoors, pick up a pine cone and take a look at the layout of the bract scales. You’ll find an unmistakable geometric structure. In fact, this same structure can be seen in the petals of a rose, the seeds of a sunflower and even the cochlea bone in your inner ear. Look closely enough, and you’ll find this spiraling structure everywhere. It’s based on a series of integers called the Fibonacci sequence. Leonardo Bonacci discovered the sequence while trying to figure out how many rabbits he could make starting with just two. It’s quite simple — add the right most integer to the previous one to get the next one in the sequence. Starting from zero, this would give you 0-1-1-2-3-5-8-13-21 and so on. If one was to look at this sequence in the form of geometric shapes, they can create square tiles whose sides are the length of the value in the sequence. If you connect the diagonal corners of these tiles with an infinite curve, you end up with the spiral that you saw in the pine cone and other natural objects.
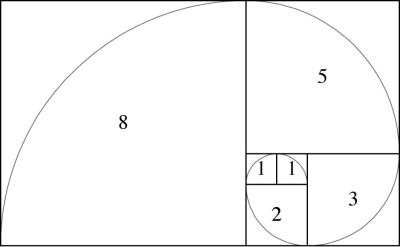
So how did mother nature discover this geometric structure? Surely it does not know math. How then can it come up with intricate and sophisticated structures? It turns out that this Fibonacci spiral is the most efficient way of squeezing the most amount of stuff in the least amount of space. And if one takes natural selection seriously, this makes perfect sense. Eons of trial and error to make the most copies of itself has stumbled upon a mathematical principle that permeates life on earth.

The homo sapiens brain is the product of this same evolutionary process, and has been evolving for an estimated 7 million years. It would be foolish to think that this same type of efficiency natural selection has stumbled across would not be present in the current homo sapiens brain. I want to impress upon you this idea of efficiency. Natural selection discovered the Fibonacci sequence solely because it is the most efficient way to do a particular task. If the brain has a task of storing information, it is perfectly reasonable that millions of years of evolution has honed it so that it does this in the most efficient way possible as well. In this article, we shall explore this idea of efficiency in data storage, and leave you to ponder its applications in the computer sciences.
EFFICIENCY
The following is a thought experiment meant to illustrate how seven million years of evolution might make data storage more efficient. Some will notice similarities with data compression techniques and programming strategies for embedded systems with minimal resources. However, the point of this exercise is to demonstrate the thought process behind efficiency to people of all skill levels.
Let us right click on our computer and create two text files. It doesn’t matter what we name them, but the contents in the first shall be “THIS IS FILE ONE” and the contents in the second shall be “THIS IS FILE TWO”. Let us now save them each to a location on our hard drive. These two files are now stored in non-volatile memory, with each occupying a separate memory space. The inefficiency is obvious. While it is easy to think nothing of bytes of data when we have terabytes of storage; if we want to take the idea of efficiency seriously, we need to see this through. We must ask ourselves – how can we make this process more efficient?
Let us now create a look-up table that has the complete word set of our language. Each word is given a label. For this thought experiment, let us keep things simple and label them as such:
- 01 – THIS
- 02 – IS
- 03 – FILE
- 04 – ONE
- 05 – TWO
Now the contents of our text files will be “01 02 03 04” and “01 02 03 05”. This is certainly an improvement in efficiency, 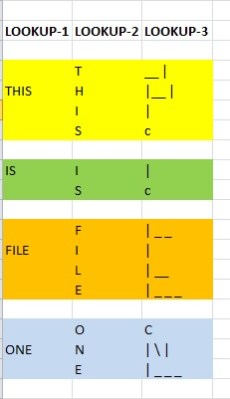 but there is an issue with our look-up table. Consider the words “THIS” and “IS”. The word “THIS” contains the word “IS”. Moreover, all of our words appear to be made of combinations of 26 individual symbols. Thus, we must make another look-up table within our first to increase efficiency.
but there is an issue with our look-up table. Consider the words “THIS” and “IS”. The word “THIS” contains the word “IS”. Moreover, all of our words appear to be made of combinations of 26 individual symbols. Thus, we must make another look-up table within our first to increase efficiency.
- 06 – T
- 07 – H
- 08 – I
- 09 – S
The label of 01 for the word points to the look-up table that gives us a label for the individual letters. Now, the word “THIS” is “06 07 08 09” and the word “IS” is “08 09.” This is better. But we still have more inefficiency in our alphabet table. The letter “T” is composed of a single vertical line and a single horizontal line, while the letter “H” is composed of two vertical lines and one horizontal line. For ease of explanation, let the letter “S” be composed of arcs. Since letters’ “T” and “H”consist of the parts of the same line segments, we can create yet another look-up table to deal with this.
- 10 – —
- 11 – |
- 12 – c (‘c’ represents the arcs in the letter “S”)
If you map out our little thought experiment, you get a clear hierarchical structure. In this way, all words are only stored as line segments and arcs. The data in the letter “T” is composed of the same data in the letter “H”. So there is no sense in storing them in separate locations. Instead, you simply store the label to the line segment. This hierarchical process is repeated all the way up the chain until you get to the entire memory (or data segment). In this case – line segments come together to form letters, which come together to form words, which come together to form the sentence in our text file.
This same process can work with images. One can break down the image of a truck to polygons, then to simple shapes, then to line segments and arcs. The circles of the wheels are the same data that would represent the circle of a dinner plate, or the full moon. The straight lines that run along the doors and windows are the same data that you see in the text you’re reading right now. It is a remarkably efficient way to store information, and what one would expect to see after millions of years of natural selection.
INVARIANCE
Many neuroscientists will agree that the brain stores memories in an invariant form. Songs, for instance, are stored as pitch-invariant memories. The memory of a song in the key of C is the same as that of the song in the key of G. When you hear the song, the memory recalled is the same despite the different incoming frequencies. This is true no matter the key, instrument or style of the song. It turns out that storing data in a hierarchical form as described above is related to invariance. All you have to do is provide a little feedback between the hierarchical layers, and allow higher layers to make changes to lower layers in order to meet a prediction. This process will create what are known as invariant representations. Let us explore this concept with another thought experiment.
Imagine there is a piece of paper in front of you with “THIS IS FILE ONE” written in crayon by a young child. The letters are distorted and oddly shaped. Your job is to read the sentence using our hierarchical structure. The identification process starts off at the very bottom with looking at the individual line segments. Imagine you make out the first three letters of the word “THIS” but the letter “S” comes up the hierarchy as the number “8”. The child wrote the letter backwards, and then tried to correct it. So now we have a problem; where there should be “THIS” is instead “THI8”.
The hierarchical structure of our data storage can deal with this ambiguity by using prediction, and then providing feedback to the layers below it. The layer that’s responsible for identifying words is able to predict (via past experience) that the combination of the letters’ “T”, “H” and “I” should be followed by an “S”, and not an “8”. The ‘word’ layer will either tell the layer below that it should be passing up an “S” and not an “8”, or it will pass up the word “THIS” to the layer above it despite what’s coming from the layer below. The method of hierarchical feedback combined with prediction creates invariant representations. You can read “THI8 I8 FILE ONE” without any issue because of this process. You see “THI8 I8”, but the words recalled are “THIS IS” because the words’ “THIS” and “IS” are stored in an invariant form. Note that it would be more difficult to recall the correct word memories without the rest of the sentence: “FILE ONE”. This is an example of prediction; the brain is using the entire sentence in context to pull the correct word memories.
We have shown that natural selection should lead to efficiency, and that invariance and efficiency are closely related. These are powerful concepts in the arena of data storage, and not even close to how modern computers store data.
YOUR THOUGHTS
Is it possible to replicate nature’s method of memory storage in a computer? One must also consider the resources currently available. Let’s face it — memory is plentiful and cheap. Do we really need to be this efficient with memory storage? I will leave it up to you to answer these thought provoking questions in the comments below.















Somehow I always thought that with rabbits it was 1+1=100….(or something like that)
What about Mormons and Catholics? My family was Mormon, while my wife’s family is Catholic. I have 10 sisters and 4 brothers while my wife’s mother has 7 brothers and a sister. My Dad had 22 sisters and 9 brothers (they were fundamentalists). It fits, LOL.
Many Mormons/Catholics don’t believe in birth control (condoms/morning pill) or abortion (obviously), but they do believe in having lots of sex, for some reason.
Harry Blackitt: Look at them, bloody Catholics, filling the bloody world up with bloody people they can’t afford to bloody feed.
Mrs. Blackitt: What are we dear?
Harry Blackitt: Protestant, and fiercely proud of it.
Mrs. Blackitt: Hmm. Well, why do they have so many children?
Harry Blackitt: Because… every time they have sexual intercourse, they have to have a baby.
Mrs. Blackitt: But it’s the same with us, Harry.
Harry Blackitt: What do you mean?
Mrs. Blackitt: Well, I mean, we’ve got two children, and we’ve had sexual intercourse twice.
Harry Blackitt: That’s not the point. We could have it any time we wanted.
I, having not studied neuroscience, kind of assumed that our brains stored information in interference patterns similar to the way a laser hologram is stored in glass. That may be. But this would explain how we recall that data. Interesting. . .
I like the way you see it !
Nah, memories are more reconstructed on demand, than actually remembered. When you remember somebody’s face, you’re quickly drawing it, from the distinctive bits you remember. That’s also why it’s easier to remember something that you understand well, rather than, say, a list of arbitrary numbers.
Indeed, if you want to remember arbitrary numbers, one memory-expert scheme involves replacing those numbers with words and images, then tying them together into a story. Makes sense, since our lives are kind of stories, we discuss things that happen to us like stories.
If you make an effort, or do loads of different kinds of drugs, you can catch your brain working sometimes, and figure out how it likely works. Of course it’s nothing without proof, but it’s interesting.
Neurology is interesting. Particularly so is how people end up when bits of their brain are damaged. Some very specific aspects of thinking are destroyed, while other aspects are fine. There isn’t a general brain, like a hard drive, with things scattered about it. Everything you know about, say, spoons, isn’t in one place, each aspect of spooniness is stored in a different place, along with the corresponding aspects of pineapples and hula hoops.
My friend’s sister worked in research with people with brain damage, on just that sort of thing. She lives too far away, otherwise I’d doubtless make a complete pest of myself asking her questions day and night. Chatting to her when I could was very interesting though.
I get the sense that chilling with you and a fun gi would lead to some outstanding conversations.
Thanks, bruv! Been a while since I last did psychedelics though.
^This. Neuroscience is super intriguing!
Evolution is dumb as a left foot’s shoe.
Well. . . some of the THEORIES have plausibility; but the way it is being taught – “believe” in all of it or you’re stupid – is quite dumb.
Nonsense. It fits the facts, it beats competing explanations. It’s as much “fact” as any other bit of science. If you’ve got a better method than science for discerning truth about the Universe, do tell.
If you don’t “believe” evolution as it’s currently known, you’re an idiot. What better theory have you got?
” It’s as much “fact” as any other bit of science. ”
There isn’t a singular “Science”, no matter how much the television talking heads like to make it out to be. There’s not even a complete consensus of what is and isn’t science in the first place. See “Demarcation problem”
You’re making the same fallacy as a religious person who points out one little bit that scientists got wrong and declares that all science is unreliable – only backwards. Just because chemistry works really well doesn’t mean evolutionary biology or astronomy is equally powerful and trustworthy in their theories.
All science that is science, is what’s currently known. By rational thought and analysing the evidence, whether that’s experimental or archaeological, biological, and genetic. Science is the best explanation we currently have, subject to replacement by new, better theories.
That’s also how knowledge and rational thought work. It’s the most we can know of anything. There’s no better way of doing it.
It’s never an absolute truth, because there aren’t any. But as far as what’s reasonable to believe, it’s everything.
That said, while evolutionary theory is a work in progress (just like chemistry and all the others), it’s a pretty good theory. Explains everything really well, and fits the evidence really well. The only holes it’s main opponents, religious nutters, have been able to poke in it, have been disproved almost instantly as misunderstandings or irrelevance.
“It’s never an absolute truth, because there aren’t any.”
Having just contradicted yourself, why would anything else you’ve said hold even a grain of truth?
How’d I contradict myself? There is nothing we can know for certain. But we can know that something is the best knowledge, the most likely to be true out of what’s available.
What I’ve said is true because I acknowledge doubt. People with blind faith, people who feel they are certain about things, they’re less reliable, because they don’t know the limits of knowledge.
The explicit statement you’re making, “there are no absolute truths”, is an inherent contradiction. Maybe that’s not what you meant to say?
FFS, smarty-pants. Ok, “as far as we know, there are no absolute truths”, that’s even got a nice bit of self-referential value there. To state “it is absolutely true that there are no absolute truths”, yes, is a paradox. Except I didn’t say that.
I could go on to explain what I actually meant, but I’m sure you know. So here, you win +100 pedant-points. Enjoy them.
Science does well when it remains empirical, when experiments can be replicated by other labs. This whole website only exists because we understand quite well on how to move electrons around to do our bidding.
Given that evolution is hard to recreate (nearly as hard as reproducing the “big bang”), believing it “lock stock and barrel” shows a profoundly closed mind. It is ironic some of it most die-hard adherents are “art majors” in college.Science especially falters when trying to explain the “meaning of life”. Keep in mind I’m someone who believes the universe is billions and billions of years old, so take great care before assigning me to a particular belief camp.
Now, let’s try to keep the conversation cordial, and show my good will, please have a after-dinner mint on me.
Chick out Advaita Vedanta. The only rational religion that ever existed and is alive today.
Maybe some of you are misinterpreting what he meant by “evolution is dumb”. Perhaps he’s not questioning it’s validity but saying that it’s not a process with any intelligent direction. Mutations happen arbitrarily. Some of them just coincidentally happen to solve an issue and they stick. That’s how evolution works. It’s a roll of the dice. When the dice get rolled many many times over ad over, out of chaos and randomness comes something that appears to be order.
I prefer “evolution is reactive, not pro-active”.
Mutations happen, then life threatening events ensure those with the right genes are more likely to survive.
Indeed, a topical example is the Tasmanian Devil facial tumour situation. Studies have shown that within just six generations there has been a level of evolvement to counter the disease: http://www.nature.com/articles/ncomms12684
I don’t think it is easy to consider evolution just a theory anymore, too many observations point in that direction. It’s almost like seeing a random guy driving your car and giving you the finger and telling that that he stole your car is just a theory.
Evolution is a pragmatic process. If it looks dumb but it works, it survives and propagates. Rinse and repeat for thousands of millennia.
Eventually it creates an organism that can directly manipulate this decision fork at the genetic level while others of its species don’t believe it existed in the first place and try to get it eliminated from textbooks.
That would seem to be true, until you begin to unpack it a bit. If the Earth is about 6 Billion years old, as geologists estimate, and life has been on Earth for about 4 Billion years, and it takes Millions and Millions–let’s say 2 Million, for the sake of example–of years for an evolutionary cycle to occur==> 4 Billion = 4 Thousand * Million years. Millions and Millions of years, 2 Million for our example, means there are 2 Thousand evolutionary cycles available in the timeline for which these changes can occur. That seems like a small number, considering the great variety of life on Earth. Furthermore, it would seem that evolution happens very, very quickly, in order to accomplish all of this in the 2 Thousand available “cycles”.
Food for thought.
You seem to forget that evolution is a parallel process. Has branches split each branch continue its own evolution. So it conduct to expnetional growt.
I’m not sure where you got this “evolutionary cycles” idea, but it’s completely made up. Evolution takes place from one generation to the next. E. Coli has a generation time of just 20 minutes. A million years making small optimizations every 20 minutes could lead to a lot of biodiversity.
Don’t forget plasmids and phages! Secondary sources of genetic material add a whole lot of variability and mutation to the equation as well.
And a big help here is sexual reproduction. Different individuals each from different lines can have unique specialities, add sexual reproduction and suddenly all the “knowledge” from different specialised fields may be merged into a single organism. Powerfull.
With sexual reproduction the population size is very important. In small populations, mutations that are beneficial propagate rapidly. There are isolated islands of vegetation in Hawaiian lava flows that are quite young and the mosquitoes and other insects differentiate dramatically over a short time. Sexual selection is also much more rapid than natural selection.
Evolution by Natural Selection doesn’t have “cycles”. Things evolve at different rates, depending on the environment. And since your sparse 2,000 “cycles” are each 2 million years long, it actually isn’t that short a time. You’ve essentially just divided the age of the Earth by an arbitrary number to get another arbitrary number, then decided that, to you, that second number is a bit small.
Even the “perfectly designed banana” guy had a better argument than that.
Even if your time frame of “2000 evolutionary cycles” were correct, the first branch gives you two separate lines that each have the next 1999 cycles to evolve. So that gives you 2^1999 possible end results. I think that would be enough
I’ve always thought of evolution as the culmination of 3.5 billion years of “it seemed like a good idea at the time”.
“We have shown that natural selection should lead to efficiency, and that invariance and efficiency are closely related”
No you haven’t. You’ve simply asserted it.
Given how inefficient so many other systems and designs are, it’s certainly a bold claim to make. One cannot however argue that it’s effective.
*that it’s NOT effective
One doesn’t really have to do much to show that evolution leads to efficiency. It’s a simple process:
1. Start with one or more living things with a genetic code
2. Let those living things try to survive using their own bodily features
3. Some things die, some survive, and of the ones that survive, some reproduce
4. Said reproduced offspring acquire slight random mutations at the time of conception, adjusting their traits
5. Go back to Step 1
In other words, it’s a semi-directed random walk along the infinite state space of an organism’s DNA (which encodes an infinite number of combinations), where the goal is to produce more of the same or similar DNA. Anything that can in any way improve the odds of reproduction (small energy/size savings, greater offspring count, “intelligent” capabilities, etc.) can become a vital part of a species’ existence, and will continue to be included in DNA until it is no longer useful.
TL;DR: Evolution just throws random shit at the wall until some of it sticks and starts growing tentacles. It then scrapes off the shit and throws it again. May the best shit win!
Hardly efficient. Vestigial organs and sub-optimal designs abound. The sole criteria is does it survive long enough to reproduce.
Maybe inefficient in some ways, but efficient in others. Remember that the mammalian species have a very complex, hostile environment to survive in, and thus certain trade-offs must be made, otherwise the species would not survive. I think it’s best to remember that evolution does not have a brain: it’s simply a process of continual replication, guaranteed by having a varied population. Yes it’s slow, yes it has baggage, but so does just about every piece of technology that humanity has created. It’s called the “No Free Lunch Theorem”: no solution is the perfect solution, each is only the best within a slim domain.
Eventually vestigial organs will disappear. Depending on how life in the future turns out, of course. Nothing’s finished yet, it’s just the best of what’s available. Living things aren’t made from scratch, they can only come from other living things. The child of an animal has to be quite a lot like that animal, because of how we reproduce. Which is tied to how we live at all. So vestigial features take a while to shrink away to nothing.
All we can say is, on the long term, things tend towards the optimal “design” for the life they live. Of course, as well as life responding to the environment, the environment is changed by life, and life is PART of the environment. So it all gets a bit convoluted.
“Eventually vestigial organs will disappear.”
If they can.
In mammals the nerve that connects to the larynx (voicebox) loops all the way down to the chest instead of taking the short way around, because it got trapped looping around the main arteries during evolution, and this vestigal loop cannot go away without the nerve path being cut in the intermediate generations, so it remains, even in completely ridiculous cases like giraffes. Evolution simply cannot get rid of it because the changes necessary to do so would be worse before they got better.
“If they can”, no, they will, but only for suitable definitions of “eventually”. Might be on cosmological scales, might be longer than the Universe actually lasts. But the force of evolution drives towards the optimal. For definitions of “optimal” that are very complicated and depend on thousands of things. Random variation, and culling based on fitness, eventually provide the fittest thing, though “fittest” changes along with them.
Still, it’s nice evidence, all these faults are evidence against a rational intelligent designer. Doesn’t rule out one who’s a bit mad, stupid, or evil though. Or pixies at the bottom of the garden.
Actually the time scales and complexity of the whole thing might be one thing that puts people off accepting the fact of evolution. It’s not something comparable to any process we observe in everyday life. That, and our pareidolia-like, animist tendency to attribute every force to some conscious intention.
Evolution is prone to getting stuck into local maximum solutions due to the path it takes through history. It runs into dead ends and can’t advance because the path to the right solution would be temporarily worse. Hence why most species are, or are fast going extinct.
Evolution also cannot optimize solutions very far because it runs into diminishing returns where the difference in performance is smaller than the chance of adverse mutations or other outside factors that force a compromize. Without a strong pressure, evolution is happy to settle for “good enough”.
It’s actually not very likely that the human brain is anywhere near the optimal solution to the problem
You are correct, algorithms based on incremental improvements can indeed get stuck in a local optimum. However, over time and with enough of a push, the Turing-complete nature of DNA can indeed allow for a species to exit a local optima and fall into a better one. In fact, given an infinite amount of time and sufficient resources, this is essentially guaranteed due to how probability and randomness work.
That’s assuming the species survives the transition. You put enough selection pressure and you’re likely to kill the animal entirely.
“It runs into dead ends and can’t advance because the path to the right solution would be temporarily worse. ”
Creation of new species and filling ecological niches works exactly that way. Almost all mutations are a handicap when they are first acquired, forcing their bearers to change their strategy of survival. Once their bloodline entrenches in another niche, or is pushed away from original population by sexual (non)selection, their evolution path diverges from the original, being drawn to new objectives, and they gradually form a new specie. If that new path has higher local maximum in terms of overall biological success, former outsiders will become dominant over their original specie. We can see similar process in non-biological evolution, too: in history, cultures pushed away and kept on the margins of civilized lands, getting hardened by harsh nature and returning as barbarian conquerors of great empires, in technology, inferior but cheaper solutions becoming ubiquitous and then gradually upgraded to near-excellent performance, inferior mental power necessitating invention of writing systems, logic, mathematics, philosophy … Compare puny humans with nature’s top-of-the-food-chain killing machines predators. We are inferior – that is the very reason for our superiority.
Well the dead end that humans have run into is simply the maximum head size that can be given birth to. We have been maximized on intelligence and the limiting factor is now quite simply that the human gestation period cannot be extended as it would make birth improbable.
I live among the top-of-the-line-food-chain killing machines and most of them are per-historic in origin. Thye have not evolved in any way in ant recent history. They have been maximized in other ways.
“Almost all mutations are a handicap when they are first acquired, forcing their bearers to change their strategy of survival.”
That’s a nice hypothesis. You got any evidence for it?
“Well the dead end that humans have run into is simply the maximum head size that can be given birth to.”
That’s not actually true. The limitation is the maximum metabolic rate the mother is able to sustain, which limits the baby’s body mass, which the baby has to divide between growing a brain and being able to survive outside of the womb. The oxygen consumption of the baby at around 9 months is starting to exceed the mother’s cardiovascular capacity and while the mother could push a bigger baby out of her pelvis, she would be overstressed to carry the child for any longer.
That’s as women are currently made. A woman with bandy legs and enormous heart and lungs would be possible. She’d be less good at evading predators and gathering berries, but that doesn’t matter any more. We’re still pretty much cavemen, genetically, our technological development has outstripped evolution.
That’s if there were some pressure to produce more intelligent, or bigger-brained, people. That said, it’s not unlikely the future path of our genome will be in our own hands. While that won’t stop evolution, it’ll reduce it’s influence to almost nothing.
There’s an interesting book you’all might like to read. “Kluge: The Haphazard Evolution of the Human Mind” by Gary Marcus. Two thumbs up and a good read.
A simple process… That in your own words “starts witha genetic code”.
Last time I checked code = instructions and information. The genetic code for even the most simple organisms is incredibly complex. And guess what… they are still the same simple organisms that they were millions or billions of years ago. Thus your argument is invalid.
Your argument does not follow. Can you explain better?
I dunno what point you’re making, but simple organisms still exist because they’re most fit for the niche they occupy. The world needs tiny little things to decompose things and utilise those tasty sulphites in underwater volcanic vents. And yeah, compared to “Hop On Pop” DNA is complex. Compared to the entire Universe, not so much.
There’s also self-modifying code and meta-codes that work on different levels, as well as information compression. Pretty horrible really but it gets the job done from the material available.
OK I know I will get flamed on this one. I love science and believe science is great to pointing to important findings like this one.
But once we jump to say evolution found the solution by natural selection we are now going into the realm of philosophy. To me this discovery how the brain stores data is another indication of intelligent design.
+1
By whose intelligence?
The aliens proposed by History channel shows, the Matrix, Odin, the Abrahamic god, a blind watchmaker?
Intelligent Design pretends to be agnostic but always carries some sectarian baggage. If you’re going to draw a line in the sand, at least give it an honest name.
Science is rooted in philosophy, why make the arbitrary distinction.
“If we should consider intelligence to be just a complicated form of minerals, why shouldn’t we consider minerals to be simple forms of intelligence?”
Paraphrasing Alan Watts.
“If we consider automobile engines to be a complicated form of metal, why shouldn’t we consider metal to be a simple form of automobile engines?”
Does that statement impress you with its insight, or does it just sound really stupid?
To make it explicit: life isn’t the molecules: life is in the particular arrangement of molecules. A rocking chair and a flute are both made of wood, but what makes one a chair and one a flute is the arrangement of wood.
… or more brutally, take a frog which is happily hopping around, and everyone agrees it is alive. Toss it in a blender and power it up for a few seconds. All the same molecules are there before and after you hit the button, but afterwards the life is gone.
The difference is that an automobile engine is a particular thing defined by its shape and composition, whereas “intelligence” is a property not bound to such things.
“life is in the particular arrangement of molecules”
I think you’ll find that to be an entirely too narrow a definition for “life”. There is no particular arrangement of molecules that would be alive – life is a doing, not a being.
“but afterwards the life is gone.”
I think you’ll find many of the cells will survive the blender and continue living for a good while afterwards. Then bacteria take over and start decomposing the slurry. There’s still life.
It’s only the frog that ceased to be.
Dax, you haven’t made a point. Leave the blender on a bit longer and all the cells get ripped open too. The point remains the same: all the molecules which were there before are there after, yet the life is gone.
What if intelligence *is* bound to its physical configuration? Do we infact have any evidence to the contrary?
That must be one good blender you have there. Where did you buy it at? ;)
“. Leave the blender on a bit longer and all the cells get ripped open too. The point remains the same: all the molecules which were there before are there after, yet the life is gone.”
You haven’t made a point. Rip the matter asunder into quarks and you’ve made a particular animal vanish, but you haven’t given the reason of why particular configurations of matter should be considered “life” in general, while others shouldn’t.
The frog isn’t really “a life” that can be destroyed in the sense as frogs can be destroyed. Life is a doing, not a being. When something behaves as life, it is alive. Same as how when something behaves intelligently, it is intelligent, because intelligence is not a thing like a car engine is a thing, but a property like lightness or redness.
Pick up a stick – if you consider it a stick you’ve just fallen into the trap of abstractions and illusions. It’s nothing but a bunch of atoms, which are nothing but a bunch of quarks etc. etc. – but if you don’t call it a stick, you’re denying reality. So what do you call it?
Thanks for your input. The line in the sand was the comment evolution did this, I only stated it looks like to me there was a designer. Hard to stay quiet when someone makes evolution the everything and somehow through millions of years we have a brain that does this.
Yes my “sectarian baggage” is the Bible and Jesus since you asked.
I don’t want to argue this here I agree HaD is not the place.
Indeed.
My questions were largely rhetorical as people are free to follow whatever philosophy they please. The faux neutral portrayal of ID just gets under my skin.
Let’s compromise then, shall we? Let’s say God exists (there’s no way to disprove that anyway). Do you really think he was like, “Yo, I’m gonna spin up a big ball of rock and put humans and some other stuff on it”? Maybe, but probably not. That seems a little far-fetched to me.
Instead, why not assume that God created this wonderful, infinite universe, grabbed a bag of antimatter popcorn, and is now watching to see how things unfold? I mean, what reason does he have to create humans in the first place? He doesn’t need us; he’s all powerful and can do as he pleases. But maybe, just like us, he just wants to create something small and simple that grows, of its own volition, into something infinitely more complex and beautiful all on his own.
Oh, and for those who will then counter this with some teachings from the Bible: Neither God nor Jesus wrote Bible. Humans did. This is the thing that every religious zealot forgets: your faith is supposed to be directed towards your God, not a book. The book is just supporting material.
Of course, in the end neither of us can prove that we are right and everyone else is wrong, which is fine. But I think it’s always worth taking a look at both sides of an argument and seeing if the two actually fit together as parts of a greater whole. Hopefully you agree!
The “A god created the Universe but then left everything else up to natural processes” is known as “god of the gaps theory”. It pisses belligerently religious people off, because step by step, through the centuries, things that were thought to have supernatural causes have been proved to be mundane and ordinary, driven only by natural, unthinking processes.
So eventually you end up in the state we are in now, where basically all the things gods are supposed to have done, we have evidence that they haven’t. So the necessity of having a god shrinks and shrinks. Gods start to look irrelevant.
This threatens the religious. You end up with only as much divinity as is undisprovable, which also applies to basically anything else you might make up without proof. So some of them start doing silly things like challenging basic science, or refusing medicine for their kids and trying to pray away disease instead. It’s a backlash, a reaction. A very silly one, at least if it wasn’t also quite dangerous.
Fortunately it’s only really dim and superstitious countries, like the USA and Africa, where anyone takes any notice of rubbish like that. It’s not like Galileo being suppressed by the Church. In this case the “inquisition” is a bunch of vulgar lunatics who won’t accept reality. The backlash won’t last forever. The rest of the world are too advanced, and benefitting so much from it, for the lunacy to go too far.
Infinite regression. Did the intelligent designer design something more intelligent than itself, or less intelligent. If the first, then the designer’s designer might also have been less intelligent: ergo at the root of it all is a pair of hydrogen atoms bumping uglies. If the latter then every iteration is getting more shoddy and at the root of it all we find an infinitely intelligent designer who could not be bothered to do any better.
Less intelligent.
If the ID appears in the early stages of the universe where entropy was minimal, it would start out as the most intelligent being, with all the information and energy of the universe concentrated into one singularity. It would then produce all the lesser beings out of itself.
That’s actually the hindu/buddhist cosmology where the all-self starts out perfect and devolves into all sorts of complexity as it plays at being all the “ten thousand things” – in doing so it breaks itself into simpler pieces and the world becomes worse and worse until finally it all just breaks down to noise. With everything broken down to just pure energy, the universe becomes indistinguishable from the starting condition, and it starts again, forever oscillating.
“Days and nights of Brahma”. I once saw a beautiful picture of that, where Brahma breathes out, and all possible universes emerge from his pores. Then he breathes back in again, a little while later, and everything is sucked back in and we’re all one in him.
It’s not true, of course, but it’s beautiful.
“It’s not true, of course, but it’s beautiful.”
It’s an narrative of a principle, not to be taken literally, as are all the deities in these religions. You may take them literally if you want to – you can pray to Krishna or sacrifice to Kali, or believe in the reincarnation of the Dalai Lama etc. if it pleases you, but that’s ultimately an illusion to be seen through. The idea is to see the world exactly as it is, past the labels and abstractions.
Or as the Daoist say, “the dao that can be spoken of is not the eternal dao”, and, “I don’t know who made it. It is older than gods.”
We’re are too easily fooled into seeing a design in random things (actually this very article explains why).
Take Galton board for example. Doesn’t the result of pouring sand into it look like a intelligently designed structure?
One thing I’ve always wondered about intelligent design – surely if it existed there would be some sort of measurable bias towards a ‘design’. Take two populations of bacteria, place them in a similar environment and see how they evolve. ID would suggest they always evolve the same way – ie towards some sort of design. Right?
You know your mouth contains an entire ecosystem, with around a dozen different types of microorganism? They live in layers on your teeth, the higher ones can only get a grip once the lower ones are established. They perform symbiosis, they all provide things that the others need. A whole complex system of material exchanges and services.
And what’s it’s purpose? To rot your fucking teeth. To put painful holes, in your teeth, when you eat food. What a fucking fantastic idea that was.
And that’s why there are no gods. Unless the guy’s a massive prankster, or a complete omnipotent cretin.
St. Augustine handwaved the problem away in his book City of God, by explaining that the world is a continuous battle between the city of man and the city of god, where those most aligned with god’s design prosper while those most aligned against god fall to the wayside.
It explains why nations rise and fall, and on the more mundane level why some people get rotten teeth, or succumb into poverty. The people who suffer simply don’t live as God designed, so their own actions cause all sorts of misery.
It’s been offical catholic doctrine since about 300 AD.
I think I’d want some statistical proof of that, before I’d accept it.
No, it’s not philosophy. It’s an explanation, inspired by research, that fits the evidence. That’s science. Since Darwin thought of it, over a century of our best science hasn’t really been able to challenge it.
The principles:
1 Living things produce offspring that are like themselves, but not identically so.
2 These variations may affect a creature’s ability to thrive in life.
3 The more you thrive, the more you reproduce, and the more of the world’s creatures consist of your children.
4 Conversely, if you don’t thrive, you don’t have a lot of offspring.
5 The best-suited creatures of each generation, provide the offspring for the next generation.
6 Therefore, over suitable timescales, the population of creatures in the world will become more and more adapted to thriving in the world.
That’s evolution. We all use the same system of genes, same system of tiny protein machines that do the job of animating us. One thing can be the descendant of a quite different thing, even so different that it no longer resembles it’s ancestor, or could successfully mate with it.
If you accept (imperfect) heredity, and that some individuals will do better than others because of their body’s configuration, you can’t not accept evolution. That’s the necessary implication. Doesn’t work every time, but over long enough times and large enough populations, it can’t not work.
This is the second article in a row of Will Sweatman that has successfully turned HaD into a steaming pile of evolutionist propaganda. Stick to the facts. The debate of Evolution vs. Creation has no place in this forum, so why keep poking the bear?
Will, do you keep stating how smart, intelligent, creative, etc. evolution is, because you don’t think we are intelligent enough to ask ourselves some deep philosophical questions based on the facts presented? Open minds can do this.
An open mind, without being spoon-fed your ideas, would look at the incredible efficiency of the Fibonacci method, the perfect hyperuniformity of the eagles eye, and just be wowed, without trying to convince everyone that obviously it was evolution.
Present the facts. Let your HaD readers ask the questions, draw their conclusions, and be wowed.
Engineers are always on the lookout for inspiration. Improving systems via selection pressure is the latest in a long line of examples where industry emulates nature. Every time code is compiled it is optimized to some standard that the writer of the compiler thought was good. Well, if we can write a compiler that compiles compilers we can iteratively improve the code base.
Likewise this code can find more efficient algorithms that let us do more with less powerful hardware. Understanding how one system works lets us improve other analogous systems.
So to say that discussion of evolution in tech circles has no benefit is simply a lack of imagination on your part. Ignoring all the potential benefits for the biomedical field.
This also appears to be a common misconception: at a short range view, it might be suggested that your compiler evolved to the point of being able to compile compilers. Step back and consider, though, that at each step it was your intelligence and creativity at work in designing your compiler.
That’s not the argument I’m making here. I’m arguing that self improving/generating systems observed in the natural world are worth emulating regardless of how you think we got here.
But to address your point: teleonomic vs teleologic design. Bonus points for reading about conways game of life.
You wouldn’t suggest that compilers evolved unless you had a process in mind for how it happened.
As it happens, algorithms can be evolved, with the right software. The process works a lot like the biological one. Equally you might say that algorithms evolve in the minds of the world’s programmers and mathematicians, who read each other’s work, and improve on it. Gradual improvement by variation.
That doesn’t describe all algorithms, of course. But evolutionary processes happen in all sorts of places beside biology.
Please do not add more hatred to these comments, there is already way too much. The article was about what evolution created, under the assumption that it occurs. Will made no comments asserting that creation is wrong and evolution is right, he just explained one possibility and the wonders that it created.
Ah, we’re just having another massive, dysfunctional, autistic HAD shitfight. Gets it out of our system, and I know I enjoy it. Don’t worry about it, we all go to bed without any bruises.
Because we’re mostly intelligent chaps, who often think “but what about…”, there’s a chance the process might even produce some useful information. Certainly it can last much longer than most Internet arguments, before we start calling each other Hitler and laughing about how the other guy’s going to burn in Hell. Some good references and stuff often pop up in HAD threads.
I’m learning a lot from this article. For example, I’ve learned that the HaD comments section has apparently become a creationist refugee camp.
Curious how the scientific method (the idea that led to all the cool devices we discuss here) is conveniently ignored when it returns a result some perceive as distasteful.
On the topic of the scientific method being conveniently ignored, wasn’t it the atheistic worldview that conveniently ignores the law of cause and effect wrt the initial beginning of a finite universe (ie. for what reason did it come into being if nothing existed before), the irreducible complexity of the living cell, and the hard problem of consciousness (ie. qualia and so forth)? Personally I find the creationist worldview to be a much more feasible starting point. Throw in an old universe with some micro-evolution and merge that in with the rest of what the Bible teaches (but make sure you avoid any fringe interpretations eg. calvinism) and you have a fairly robust worldview.
Well, the athiest and theist viewpoints both suffer from the first problem you described: athiests have “Universe appearing out of nowhere”, theists have some variation of “God(s) appearing out of nowhere and making the Universe”. Personally, I prefer the viewpoint that just requires an expanding singularity out of nowhere, as opposed to the one that requires an expanding singularity plus one or more omniscient and omnipotent beings out of nowhere.
As for the “irreducible complexity” of cells, that doesn’t don’t hold up under scientific scrutiny (nothing about the cell has been found to be irreducibly complex) and comes across as an argument from ignorance.
Finally, consciousness is a much harder problem that we have yet to solve… but I wouldn’t bet on it being unsolved forever. We’ve only taken the very first tentative steps of psychology as a hard science, and putting faith in a “God of the Gaps” has historically not been a winning proposition.
I prefer the view that the singularity -is- the naturally omnipotent and omniscient being that appears out of nowhere, or has forever existed. The universe is by definition all-capable and all-knowing because it can do whatever is possible and contains all the information there is to be known.
Separating God from the world causes the problem of defining God as a separate thing, because treating the two things separately must mean that God must be identifiable and therefore provable to be real, and therefore it falls to the person who believes in this separate God to 1) come up with a way to distinguish it, and 2) showing that it actually is.
And all such definitions end up with a God that is unidentifiable nonsense, or run around back to the idea that the universe is god, whatever the universe happens to be.
There are certainly some areas the scientific method suffers with. Why be good in an infinite uncaring universe? What happens to us when we die? Why are we here?
But there are other areas the scientific method excels in, usually to do with things that exist in the physical universe (space and time). We know with increasing detail how the brain works, how evolution works, what likely happened to create the first living cell, and so on.
Personally I think a lot of happiness would come from keeping these two sets distinct.
Considering we were healing mental illness by driving bad spirits away really not so long ago, I’d say our understanding of consciousness (quite likely a physical universe phenomenon) has come a long way and will likely go a lot further.
As kdev said, the ‘God of the Gaps’ is historically not a very solid place to stand.
Why be good? After the initial hurdle of determining what ‘good’ is, people cooperate now because the critters that didn’t cooperate didn’t survive in great numbers and therefore didn’t become us. As a side effect of self-awareness we can simulate ourselves being in the situation of another and doing so causes feedback similar to actual experience, leading to empathy.
What happens when we die? The software that thinks it is us stops running.
Why are we here? Because entropy didn’t like the wait and wanted to speed the tendency to disorder, much like a falling rock continues to gain speed.
Why be good? Because species which cooperate, generally do better than those that don’t. Depending on the species, of course, but most of the apes are social creatures, who innately understand many of the things that human society understands. So, because evolution, that’s why.
I’m a morally good person, because I care about my fellow people, because, ironically, “There but for the grace of God go I”. I think it’s better to be good because it makes sense to you, because your mind functions that way, than to be good merely because some big dude told you to, and will totally torture the shit out of you (after you die) if you don’t. That’s not really good at all, it’s self-preservation. It’s selfish to do good just because you’re expecting a reward / punishment. It’s somewhat psychopathic.
What happens after I die? Almost certainly nothing. But it’s not a question that can be answered beyond doubt. Doesn’t mean making up any old explanation, or accepting the prevailing myths of the culture I happened to be born in, is a good answer.
Why are we here? I’m here because my parents fucked. They’re here for the same reason. There is no innate purpose, there’s no evidence or reason to suggest there has to be one. Existence works identically whether there is a purpose or not. Assigning purpose and intent, a personal force, to aspects of nature, is animism. It’s something that made sense to primitive people, because most of the stuff we see in our lives was created or motivated by somebody or something. So it’s only a small jump to apply the same principle to the Universe itself.
We know the spear was created by Ug, we know the house was created by Guk, and the world is much more complicated than a spear or house, so logically someone really enormous must have created that. Makes sense, if you don’t know any better. When a flood destroys your village, praying to the flood gods at least lets you think you’re doing something, that you can prevent future ones. Being able to do bugger-all isn’t a very happy thought, and at least praying is doing something.
Incidentally the fact that ancient religions tend to be the big ones, I think is because of that. We can excuse most of the problems and failures in the religion with the fact that people weren’t sophisticated back then, so that’s why the gods never said anything about electricity or genetics or gravity.
A modern, new religion, has a lot more work to do. Obviously expecting people to believe it’s all down to aliens is ridiculous, right?
There’s fairly rational and obvious explanations for how religions came about, if you know how mankind works. “They’re actually true” isn’t the best one.
Incidentally, if, say, Christianity is true, how come so many Hindus have equally faithful belief in their system, which is completely incompatible with Christianity? Are all religions true? Some? Just one? Why? And where did all the false ones come from?
The more you read about cosmology, the more you will find that few people outside of theologians argue for creation of a universe ex nihilo. For a number of reasons unrelated to cosmologists personal beliefs. One theory that’s gotten a lot of press is that this universe is a bubble derrived from energy in the quantum vacuum, which causes particles & antiparticles to pop into existence momentarily before annihilating, our bubble just hasn’t found it’s anti-bubble yet.
The second reason is it’s a bit of a nonsensical question to ask what happened before the big bang. The big bang is not the beginning of the universe. It’s the beginning of the universe as we see it. The big bang represents a cosmic horizon, so to say it’s the beginning, is like standing on a beach saying the horizon is the beginning of the earth simply because you can see no further.
Also, time and space are linked. If space is compressed, time is compressed. Without any space (as in the super dense period of the universe) there is no time to be before. A further wrinkle, are the A & B Theories of time, any concept of linear time may be wholly of our making. If our universe follows the B theory, again, ‘before’ ceases to hold meaning.
Using perceptions of everyday life like the ‘law’ of cause & effect fail miserably when talking about a time in the universe when energy was so condensed atoms could not exist. Our own intuitions do not work for things like quantum tunneling, why would you expect them to for a time when the very laws of physics break down?
@kdev
The idea that the universe was at one time a singularity is also losing favor in light of new evidence but it persists in pop culture and staunch advocates.
” few people outside of theologians argue for creation of a universe ex nihilo.”
But that’s just kicking the can down the road. If the universe came from something, where did that something come from?
IK,R? Why put all that effort into programming your micro, when you can just pray for it to work by itself? Perhaps whichever god is the real one, requires us all to do everything as we were going to do it anyway, but only because he wants us to. So it’s a lot like being sensible, except with a supernatural dude on your mind, like the TM at the end of a brand name.
There’s quite a few interesting anthropological explanations for the existence of religions. Much more so than “one of them is true”.
I imagine it is quite possible, especially with parallel processing getting cheap and easy (making the layers and feedback practical to implement quickly). However, in my experience one reason we don’t do so has simply to do with complementary strength and weaknesses. Humans store massive amounts of data to later recall and process using this efficient, flexible, pattern based invariant representation strategy which gives us wonderfully flexible (if error-prone) recall and processing. Many times, however, we use computers to complement our weaknesses and exploit their strengths and provide rigid repeatable processing and verbatim recall.
Take data mining for example. We use our pattern matching skills to provide the feedback channel to the computer by adjusting the query and use the computer’s rigid recall and compare to apply the query and present the results. By iterating this process we can, by employing both our strengths and those of the machine, develop and articulate clear boiled down relationships in the data that would otherwise have been very hard to codify/articulate and thus it allows us to back our flexible but fuzzy combination of intuition and recognition with a repeatable, precise rule.
The resulting rules will likely still be imperfect but they are much easier to share with others or follow up on with further pondering and hypothesis testing to arrive at the underlying causal relationships than the “I know it when I see it” that our brains tend to give us on their own.
Jeez, “Click-Bait” – AGAIN HaD! There is no verifiable evidence that the Brain stores anything using what’s described in this post. If you disagree HaD, Cite Science-based References. (I don’t expect to see any references – at least outside of pseudo-science stuff – including the current Practice of Psychology).
Why not post this under the header from one of the related topics in Information Theory (yeah, you can be more creative. Just don’t roll the topic into click-bait).
Actually, as a computational neuroscience researcher who uses these exact principles for my work, this is the least click-bait article HaD has hosted recently. The concept of hierarchical pattern matching based on simple associations is a cornerstone of cortical-derived research, and is the most powerful, easy-to-implement algorithm I know of for unsupervised learning of invariant statistical patterns. Lookup Hierarchical Temporal Memory (HTM) by Numenta, it’s a wonderful example of the utility of this concept, and is pretty powerful for how simple it is.
Yeah. My wife is actually a neuroscientist and does fMRI research about memory and memory storage. I looked over at her and asked if there is any current evidence to support what is being g claimed in the article, and she said, “not really”. She then went on to say how there are a lot of theories about how our brains store data on the lowest level, but very little credible science to back it up. They are all just nice theories until we discover better ways to measure what our brains are actually doing.
Not this Fibonacci pseudoscience bullshit again:
https://www.lhup.edu/~dsimanek/pseudo/fibonacc.htm
I think most data compression algorithms can be thought of as a way to automatically extract “features” or “patterns” most frequent in your data: encode frequent words in a dictionary in lossless LZW or ZIP compression, enhance visibly-stronger patterns (low spatial frequency variation) in lossy JPG compression, frame-to-frame correlated blocks in H264, etc.
I assume many lossless or lossy compression methods are trying to store information in a form that relies on invariants or most-sensible patterns to achieve better efficiency.
It depends whether you’re talking about lossless or lossy. Lossy methods are based on understanding of human perception. MP3 relies partly on the fact that, if you have a loud sound at one frequency, and a quiet one at a nearby frequency, a human won’t notice the quiet one, so it can be discarded.
Lossless methods, yes, basically exploit repetition, and encode it into smaller units. Those units themselves may be repetitive as well and can also be encoded.
It’s not really to do with invariants, just repetition. Interestingly, optimally-compressed data is indistinguishable from noise. The more you compress, the more noise-like something looks.
Looks like the author probably shouldn’t have discussed evolution. This is a discussion about image recognition and neural networks maybe even touching out deep learning. As for that I have a video to add: https://youtu.be/jzyCmk7tuts I’ve been doing my own research into this subject and have developed a new algorithm but I’m still working on publishing a paper on it.
The author should have talked about the fractal compression algorithm, and also, how lossy codecs cheat with our brains.
Next we need someone to do an article about how bees are so smart that they use such a fabulously strong structure as the hexagon in their honeycombs. The are just little winged mathematical geniuses! [/Sarcasm]
Good one.
“in the most efficient way possible” seems like a bit of a stretch, one highly efficient solution – perhaps. Evolutionary pressures on humans include things like what materials are feasibly available for construction, and what scale it operates on.
“Evolutionary pressures on humans include…”
Everything between you spotting “that” female and the resulting off-spring doing the same. The only other factor is the mutation rate, which is also part of the first variable set too, but it also has a separate contribution which is also compounded by population size and mixing/isolation factors which may be genetically influenced and therefore they participate in a self reinforcing feed-back loop.
The primary pressure on humans has been for most of history, self-predation.
Quote: “Everything between you spotting “that” female and the resulting off-spring”
Wow – that escalated quickly lol
And whatabout spotting that male and resulting offspring!?
Here’s an analogy for someone to tear apart.
The Human CPU is much like the electronic CPU in that it really has no clue where in memory, things are stored. You can swap around the address bus pins on a RAM but that has no effect on the CPU because things will still return from where they are put even if the CPU is unaware of where that may be.
For memory storage (and retrieval) the address bus is supplied with all sorts of information about the current circumstances like feelings, smell and visual information.
The human CPU however does not have a data bus, instead it has a status bus. The status which is stored and retrieved has things like the number of times this info has been stored 0 = New event, 100 = common memory. The status of many close cells are returned.
It also includes actions that should be a response to the situation like – RUN for your life !!!
To me the most fascinating thing about the human brain is that it ALWAYS returns a response even when the input data is inconclusive or even non-existent (dreaming). In these situations a computer will just crash out with an error but the human brain offers it’s best guess (spok). I have noticed this because many people have unwittingly become guinea pigs for observation buy exposing themselves to noxious chemical substances. At the start they will act out being in a situation that is close the the situation they’re actually in but not quite the same. Progressively they are more ad more distant from the actual information as the quality of the input data reduces (SISO). The lats things they loose as their cognitive ability collapses is a response to perceived emotion and smell. Now I wonder if I have any naloxone left! (Kidding)
It’s interesting that any simple multicellular living organism, let’s say algae, is many degrees more complex (we cannot create them just with the basic components) than the most complex things humans ever engineered, let’s say a space rocket (we can make them).
Yet still, if we dig the earth, we find many remains (fossils) of the first type, none of the second, but statistics tells us it should be the other way round.
What statistics are you referring to? Over the span of time, there have been vastly more natural artifacts than human-created artifacts.
Second, we discovered the structure of DNA only 75-ish years ago, have understood how it encoded proteins for only 65-ish years, and read a full human genome less than 20 years ago. Yet Craig Venter has already cloned one bacterium and created a highly reengineered bacterium from nothing but vials of amino acids (admittedly it was just the DNA; he plopped it into a host cell which had had its dna removed). Evolution has had 3.7 billions years running many trillions of experiments every minute to get things where they are today. Give humans a few decades to see what we can come up with (for better or worse).
Third, why do you say that if we dig up the earth we find nothing that is man-made. That is simply false. There are thousands of tools and spear tips which go back many hundreds of thousands of years.
Evolution aside, much of this fits current neuroscience and psychology research. See “How to Create a Mind” by Ray Kurzweil for a nice survey (disclaimer: the book is a bit narcissistic and lousy with Kurzeil’s audacious ideas).
As far as whether we can achieve such memory storage and if it’s necessary, yes, I believe we can, but it is only necessary in the context of neural computing. The field of artificial intelligence and machine learning is currently experiencing a Cambrian explosion, yielding remarkable algorithms and data structures, several of which are similar in design and structure to those discussed here. These do not benefit from such memory storage. The benefit comes with respect to the neural computing chips being developed by companies like IBM and CogniMem, though the efficiency is a result of data being collocated with computation, rather than the actual compactness of the data.
That’s my two cents.
Despite its magnificience, Internet is a ocean of craps. As an example, the famous myth of Fibonacci serie we supposedly find everywhere in nature. “It’s the TRUTH”, says Homer, “I’ve seen it on Internet”. Here the official debunk for one of the most die hard myth in Internet history: https://www.lhup.edu/~dsimanek/pseudo/fibonacc.htm
Just abstract everything: Read about the R&D behind SuperMemo. All you need is the figure for the time it takes you to forget to master your brain. Your long-term memory decays too. Your brain has two buffers basically.