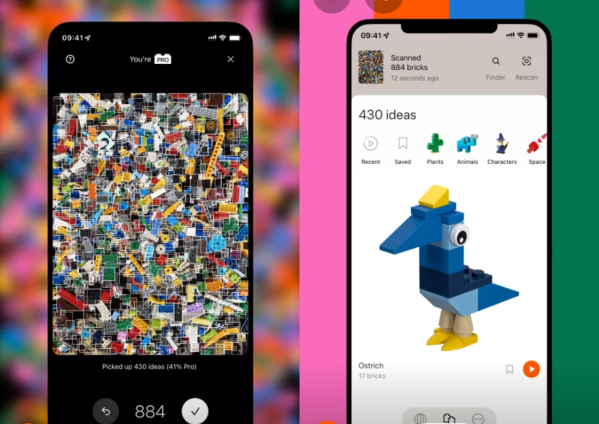
What if there was some magic device that could somehow scan all your LEGO and tell you what you can make with it? It’s a childhood dream come true, right? Well, that device is in your pocket. Just dump out your LEGO stash on the carpet, spread it out so there’s only one layer, scan it with your phone, and after a short wait, you get a list of all the the fun things you can make. With building instructions. And oh yeah, it shows you where each brick is in the pile.
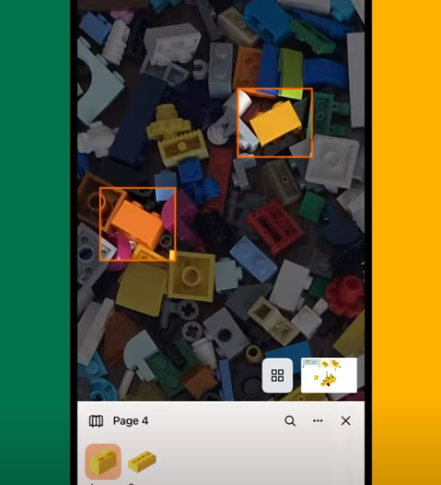 We are talking about the BrickIt app, which is available for Android and Apple. Check it out in the short demo after the break. Having personally tried the app, we can say it does what it says it does and is in fact quite cool.
We are talking about the BrickIt app, which is available for Android and Apple. Check it out in the short demo after the break. Having personally tried the app, we can say it does what it says it does and is in fact quite cool.
As much as it may pain you to have to pick up all those bricks when you’re finished, it really does work better against a neutral background like light-colored carpet. In an attempt to keep the bricks corralled, we tried a wooden tray, and it didn’t seem to be working as well as it probably could have — it didn’t hold that many bricks, and they couldn’t be spread out that far.
And the only real downside is that results are limited because there’s a paid version. And the app is kind of constantly reminding you of what you’re missing out on. But it’s still really, really cool, so check it out.
We don’t have to tell you how versatile LEGO is. But have you seen this keyboard stand, or this PCB vise?