
After seeing how Google’s Duplex AI was able to book a table at a restaurant by fooling a human maître d’ into thinking it was human, I wondered if it might be possible for us mere hackers to pull off the same feat. What could you or I do without Google’s legions of ace AI programmers and racks of neural network training hardware? Let’s look at the ways we can make a natural language bot of our own. As you’ll see, it’s entirely doable.
Breaking Down The Solution
One of the first steps in engineering a solution is to break it down into smaller steps. Any conversation consists of a back-and-forth between two people, or a person and a chunk of silicon in our case.
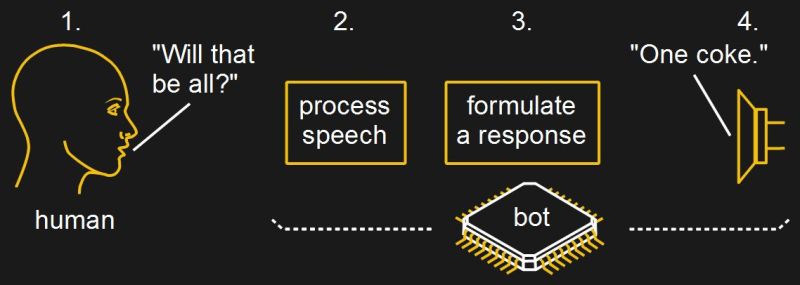 Let’s say we want to create a bot which can order a pizza for us over the phone. The pizza place first says something to us. Some software then converts that speech to text or breaks it down into some other useful form. More software then formulates a response. And lastly, text-to-speech software or pre-recorded sound bites reply to the pizza place through a speaker into the phone.
Let’s say we want to create a bot which can order a pizza for us over the phone. The pizza place first says something to us. Some software then converts that speech to text or breaks it down into some other useful form. More software then formulates a response. And lastly, text-to-speech software or pre-recorded sound bites reply to the pizza place through a speaker into the phone.
The first half of the solution falls under the purview of natural language processing, at least part of which involves converting speech to a form which software can easily understand.
Converting Speech To Text
While there are plenty of open software options for converting text to speech, there aren’t as many for going the other way, from speech to text. They’re also typically in the form of libraries, which is fine for our use. Examples of open ones are CMU Sphinx, Julius, and Kaldi.
More recently, Mozilla has been working one called DeepSpeech which uses TensorFlow and deep learning. We’ve seen it used once so far when [Michael Sheldon] adapted it to convert speech to text which he then injects into X applications.
Understanding The Text
Once you’ve converted the speech to text, what do you do with it?
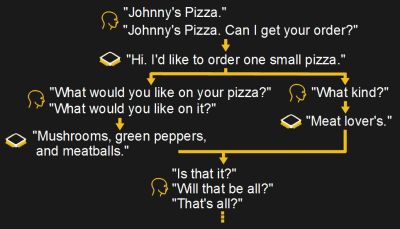
In our diagram, the human at the pizza place asked us “Will that be all?”. This could have been worded any number of other ways, for example: “Is that it?”, “That’s all?”.
One way to handle all these possibilities is to write the formulate-a-response code by throwing together a bunch of if-then-else statements, or perhaps write up a parser backed by some tables. If the conversation is expected to be structured then you can create a decision tree and have the code use that as a guide.
AIML (Artificial Intelligence Markup Language) makes that approach easier. AIML was created between 1995 and 2002 by Richard Wallace and has been the basis for a number of chatbots since, including an award-winning one called A.L.I.C.E. Since 2013, the A.L.I.C.E. foundation has been working on a specification for AIML 2.0.
With AIML, you fill an XML file with all the possible things the pizza place could say. The number of them can be minimized using patterns such as “Hi *”, but the pattern language in AIML is limited. It also allows you to provide responses and to limit the conversation to specific topics as they arise. And among its many other features, it has the ability to learn by writing novel things to a file.
For starting out with AIML, see the docs at pandorabots.com. There is also a relatively old interpreter called ProgramAB.
This video shows AIML in use by an open source InMoov robot.
https://www.youtube.com/watch?v=S59JlEdu4bU
Determining Intent
 Much of the process-speech portion of our solution basically involves figuring out the intent of whatever the pizza place is saying, except that if our code is a mass of if-then-else statements or decision tree structures, it might not seem that way. Ultimately, when the pizza place asks in one of its myriad ways if that’s all we’d like to order, we’d like to boil down all the possibilities down to a single, simple intent, “asking_is_that_all”.
Much of the process-speech portion of our solution basically involves figuring out the intent of whatever the pizza place is saying, except that if our code is a mass of if-then-else statements or decision tree structures, it might not seem that way. Ultimately, when the pizza place asks in one of its myriad ways if that’s all we’d like to order, we’d like to boil down all the possibilities down to a single, simple intent, “asking_is_that_all”.
Or the intent may come with additional data for us to use. They may say “It’ll be ready in 20 minutes.” or “You can pick it up in 20 minutes.”. In that case we can label the intent “give_order_ready_time” and store the duration, 20 minutes, as additional data.
Online Services
Free online services exist which do both the speech recognition and determining the intent and capturing of any data. Wit.ai, owned by Facebook, is one such. Another is DialogFlow, formerly Api.ai and now owned by Google. DialogFlow does charge for some things, but nothing a hacker would need. IBM’s Watson Assistant is also free but has a mix of limits.
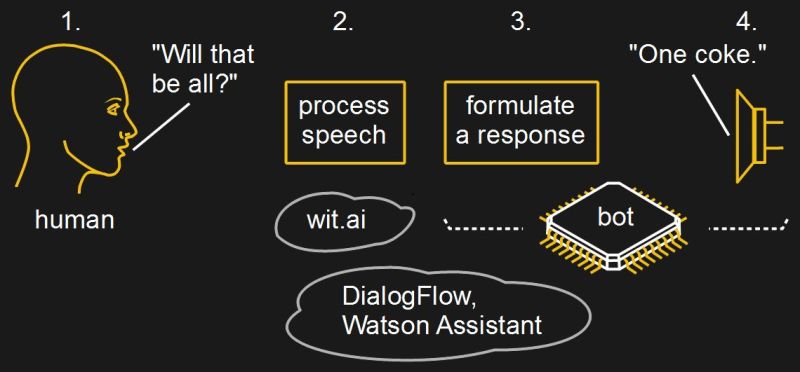 While Wit.ai does speech recognition and intent determination, DialogFlow and Watson implement the full decision tree, allowing you to use their UIs to script the whole conversation.
While Wit.ai does speech recognition and intent determination, DialogFlow and Watson implement the full decision tree, allowing you to use their UIs to script the whole conversation.
Ordering Pizza Using Wit.ai
I decided to try out Wit.ai and here’s the resulting conversation, placing an order for a pizza with a fictitious Johnny’s Pizza. Disclosure: No phone call was actually made, but more on that below. Two approaches were taken for speaking to the pizza place. The first used prerecorded speech:
The second approach used Festival text-to-speech software to create the speech on the fly.
In brief, here’s how I did it. First, I wrote up a script with all the possible combinations of things Johnny’s Pizza could say as well as what my bot should respond with. Then I went to Wit.ai and created an App. That involved giving it all the things in my script which Johnny’s Pizza says and for each one, assigning intents and indicating any data which should be reported to my code.
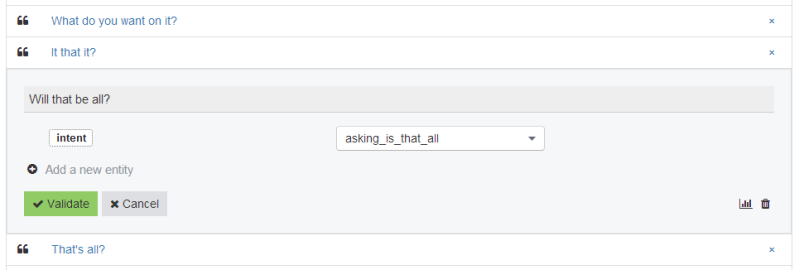
In Wit.ai you actually create entities, of which intents are just one type, but I found my code was easier to write if I made everything an intent. Shown here is a snapshot of some of the expressions, i.e. the things the pizza place might say. I’ve expanded the “Will that be all?” one to show the intent entity with a value of “asking_is_that_all”, which is what I’ll look for in my code. The expression above it and the one below it share that same entity so for any of them my code only has to look for “asking_is_that_all”.
After that, it was just a matter of writing some Python code on my Raspberry Pi based on their docs and example code on their Github. I have an amplifier (a noisy DIY one) and speaker attached to the Pi. I recorded a separate sound clip for each part of the conversation and saved them in individual .wav files. For the version where I used prerecorded speech for the bot’s side too, I deepened the bot’s voice since my voice was used for both sides of the conversation.
In the code, I iterate through the sound clips for the pizza place as if I’d just received them from a phone, sending them one at a time to Wit.ai. Wit.ai does the speech recognition and analysis and returns the intent and data. I also play the clip to the speaker. Then I use the intent to figure out which of the bot’s clips to play in response or which text to convert to speech, depending on which approach I’m taking for the bot’s side. What you hear above is the resulting conversation just as I heard it from the Pi’s speaker.
The code can be found on our Github.
The Ultimate: How Google Duplex AI Did It
Listen again to the conversations Google’s Duplex AI had and you’ll be astounded at the language produced by the AI. Impressive as that is, more amazing is that there’s no if-then-else or decision tree involved. Instead, all that logic was trained into a neural network using copious amounts of sample phone conversations on hardware we can only dream of (or pay to use through online services). So for now we’ll have to do that part the old school way.
Adding Natural Language To AIML
One thing we can do, which would be a great open source project, would be to combine something like DeepSpeech with AIML, producing something more similar to DialogFlow or IBM Watson. Perhaps then ordering a pizza over the phone will become only a matter of pressing a button, or we could hook it up to Alexa and have her initiate it. Of course, we might want to announce that we’re a bot at the start of the call and be alerted to intervene if the conversation goes awry. Or record the conversations for posterity, so that the AIs have something to laugh about in ten years.














I’d rather eat a Johnny’s box than any other pizza.
Yeah, most pizzas taste like cardboard…
>”there’s no if-then-else or decision tree involved. Instead, all that logic was trained into a neural network ”
A neural network can, when the task is simple, simply replicate a list of if-then or decision tree like structures. When you train a network, it picks up whatever gets through the test, so as long as you’re presenting it with just input-response pairs, it will likely encode the majority of them as simple triggers the same way you can train the network to perform any logic function.
In other words, DNNs aren’t magic. What results from training a DNN after the network is frozen down is a deterministic algorithm, and all such programs can be reduced to a big list of if-then statements.
The major difference between a DNN and programming an algorithm the traditional way is that the DNN is guaranteed to halt. The power of it is that you can’t crash it, although it may give you undesired outputs.
Neural networks can, or at least should be able to, handle input that’s similar but not exactly the same as what they’re trained on. So they’re a little different than if-then unless your ‘if’ includes patterns and you’ve managed to think of a large variety of the possible patterns you could come across.
For example, for the greeting, I trained it on:
“Johnny’s Pizza.”
“Johnny’s Pizza. Can I take your order?”
And yet when I placed my “phone call” I gave it the speech:
“Johnny’s Pizza. Can I get your order?”
So the word “get” was different.
Similarly, I trained it on:
“Pick up or delivery?”
“Will that be pick up or delivery?
And yet the speech I gave it was:
“Is that for pick up or delivery?”
which differs in two words.
In all cases it recognized them as I wanted it to and gave me back the intents and values which I wanted.
The same applies for DNNs which do object recognition in images.
But you’re right, DNNs aren’t magic. It’s more like you train them to learn a non-linear function which approximates the training data. The output, at least in speech and object recognition, includes a probability or confidence level. In my case I was getting around 0.83 out of 1 or better, for most things 0.99.
Yeah, they can, but that doesn’t change the point. The DNN doesn’t necessarily handle the input as such, because the if-then statements do not have to concern all the information given. That’s how they deal with the similiarity – the IF statement is refined to ignore the dissimiliar parts.
That’s also one of their weaknesses, because you can device adversial input which finds the bits that the NN has concentrated on, and then changes only that. That’s how they recently got the Google’s DNN to identify a turtle as a gun, or a dog as a house etc.
The point being that a neural network always does the simple thing first, because that solution is easier to find. It’s evolving a program. The first solutions it find is simple pattern matching solutions (basically if-then), and then as you keep training it further with examples that break those simple assumptions – assuming it has enough neurons in the right topology to support it – it evolves more complex algorithms that can double guess and do the more intelligent stuff.
Just throwing a bunch of virtual neurons at the problem isn’t likely to generate a very smart DNN. That’s likely why biological brains have special folds and partitions and distinct specialized areas that are found to perform particular tasks. Plus, biological brains constantly reconfigure themselves – they’re not frozen – so they can improve on the fly which is yet out of reach for their computational counterparts because of the catastrophic forgetting problem (new training “averages” with old training and produces faulty results for both).
Though on the forgetting problem, the research has gone some ways into reducing the effect. There’s two major approaches: one is to pre-train the network with a whole bunch of prior general knowledge which seems to cause a sort of partitioning effect where the network assigns some parts for different “categories” of learning, so new information uses these existing structures rather than overwriting the whole network.
Another approach is more difficult to implement as it involves looping the output of the NN back to its input, so the network constantly replays its own input and fixes onto these patterns, constantly re-teaching itself the correct response. When new information is presented, it adds to the stream. The difficulty then is that the NN doesn’t really produce a well defined output that says “I see an apple”, you still have to identify (IF-THEN) the activity pattern corresponding to an apple which is just kicking the can down the road.
Both still gradually degrade the network over time as new information is put in, so the network eventually forgets things, because there’s a limit to how much information it can hold and it has to overwrite the weights eventually, which is a problem of simply too few neurons. We’re trying to make the equivalent of an insect’s brain identify thousands of different things and respond appropriately, which isn’t possible because it simply runs out of “memory”.
Plus, on a qualitative point of view, you have to consider John Searle’s argument about computer programs. DNNs are perfectly deterministic (or pseudo-random), which is why they reduce back to ordinary programs, which can always reduce to a buch of IF-THEN statements even if a very very long list of those. You have to introduce some other “causal power” like quantum indeterminacy or just random noise to break that pattern.
The question is still out there whether brains operate on probability, but there’s strong evidence that they aren’t fully deterministic. Neural networks are a form of cellular automata, somewhat like Game of Life, which exhibit a phenomenon called “edge of chaos” where the rules of the “game” are either producing uninteresting predictable results, or devolve into unpredictable (chaotic) noise. Altering the rules slightly can produce either or, and teetering on the edge of chaos maximizes the information processing capability of the resulting network. Brains are observed to do this periodically.
Now, the question is whether the network is deterministic or indeterministic, as both are possible, and both produce distinct overall patterns of activity. Samples out of real brain tissue, and simulations thereof, point strongly to actual brain tissue being indeterministic. Then, the question is whether this is classical or quantum indeterminancy.
So, there’s still a long gap between DNNs and “intelligence” as we know it.
Sorry there is no “deus ex machina”. As far as the subject of deterministic or indeterministic, I guess that’s a rather Ontological argument addressing the meaning of reality and determinism itself.
To sum it up, the use of simple neural networks trained for specific cue phrases is just a new way to implement an Expert System. It skips the problem of obtaining the experts to write the rules by having the NN discover the rules by itself, but it still inherits the same fragility when you’re operating at the limits of their knowledge.
http://home.klebos.net/philip.sargent/book/7_knowledge_based_systems.html
>”Simple expert systems are fragile when dealing with problems at the edges of their expertise for a fundamental reason: such systems often have the ‘absent equals false’ assumption built in to their inference systems. Taking the step to more sophisticated systems and away from ‘complete’ problems requires moving from normal logic to three-valued logic: true, false and maybe, and the manipulation of ‘maybes’ has the same problems earlier discussed in connection with NULL values in databases.”
>”This fragility with respect to absent knowledge is why simple systems built using commercial expert system shells usually succeed with small, complete problem domains but can fail disastrously when attempts are made to scale them up for real problems.”
This failure of expert systems is mainly what lead to the “AI winter”, or the disillusionment about AI after the initial hype.
read the whole article to see what you’d done for text -> speech and then found you wimped out and recorded it!
Oh, I hadn’t thought of that. I guess I could very easily have done the same thing I did for my object recognizer and used Festival. It would especially easy since I still have it installed on the Pi.
I just tried it and it worked fine:
#os.system(‘aplay audio_customer_greeting_order_pizza.wav’)
os.system(“echo %s | festival –tts” % “Hi. Id like to order one small pizza.”)
https://elinux.org/RPi_Text_to_Speech_(Speech_Synthesis)
https://hackaday.com/2017/06/14/diy-raspberry-neural-network-sees-all-recognizes-some/
I modified the code on GitHub to include the use of Festival text-to-speech. I kept the previous versions which use prerecorded speech there too. Uncomment whichever you want to use. I also added a sample conversation using Festival to the article above.
A while ago I sought a decent, free, computer transcription solution. My thinking is to record the audio of meetings and transcribe them using software so that the audio could be text searchable. It didn’t have to be all that accurate and I’m transcribing English from native speakers in a conference room.
I’m a software guy (C is my #1 language) but the open source tools are obtuse and difficult to adopt and they seem mostly focused on short phrases common in “command” systems, not for freeform speech transcription. Simple “transcribe this .wav file to a block of text” command line “hello world” examples are beyond most/all, but I’ll be honest I have only spent a couple hours researching this. I haven’t looked into DeepSpeech, yet; it looks more promising.
Pointers for a free and easy way to take a .wav and generate a .txt would be greatly appreciated. And for folks developing speech recognition, having this capability as a “first test” is always advised to gain adoption of your software and expanding the community.