There are basically two ways to compute data. The first is with a DSP, a chip that performs very specialized functions on a limited set of data. These are very cheap, have amazing performance per watt, but can’t do general computation at all. If you’d like to build a general-purpose computer, you’ll have to go with a superscalar processor – an x86, PowerPC, or any one of the other really beefy CPU architectures out there. Superscalars are great for general purpose computing, but their performance per watt dollar is abysmal in comparison to a DSP.
A lot of people have looked into this problem and have come up with nothing. This may change, though, if [Ivan Godard] of Out-of-the-Box computing is able to produce The Mill – a ground-up rethink of current CPU architectures.
Unlike DSPs, superscalar processors you’d find in your desktop have an enormous amount of registers, and most of these are rename registers, or places where the CPU stores a value temporarily. Combine this with the fact that connecting hundreds of these temporary registers to places where they’ll eventually be used eats up about half the power budget in a CPU, and you’ll see why DSPs are so much more efficient than the x86 sitting in your laptop.
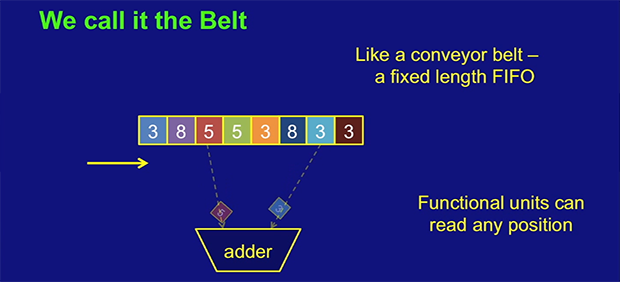
[Ivan]’s solution to this problem is replacing the registers in a CPU with something called a ‘belt’ – basically a weird combination of a stack and a shift register. The CPU can take data from any position on the belt, perform an operation, and places the result at the front of the belt. Any data that isn’t used simply falls off the belt; this isn’t a problem, as most data used in a CPU is used only once.
On paper, it’s a vastly more efficient means of general purpose computation. Unfortunately, [Ivan] doesn’t quite have all the patents in for The Mill, so his talks (two available below) are a little compartmentalized. Still, it’s one of the coolest advances in computer architecture in recent memory and something we’d love to see become a real product.
[youtube=http://www.youtube.com/watch?v=LgLNyMAi-0I&w=580]
[youtube=https://www.youtube.com/watch?v=QGw-cy0ylCc&w=580]














Wow. This writeup… wow.
First off, there’s either many ways to compute data if you want to talk architecture, or just one: a turing machine. How many ways to compute is a matter of what level of detail we’re discussing.
Superscalar has nothing to do with CPU’s vs. DSP’s. There really isn’t a hard distinction between the two, and if there was it wouldn’t be having superscalar features. There are DSP’s with superscalar processing, for example.
I’ll watch the videos, but my kneejerk reaction after reading this writeup is that you’ve been taken in by crank with a new weird architecture.
This “belt” kinda look like a bit shift right/left if you want my guess. It’s a cool way to implement it and I’ve never actually seen in in processors but hey,no need to rename a well known process =P
The belt is a concept, it is not an implementation. One could perhaps implement it using a large shift register, but that would be inefficient and it is now how it is implemented in the Mill.
“=P”
Conceptually it’s a shift register. Internally the belt it is held on the functional units output latches, and the belt names are instructions for how to configure the mux network for each cycle. Implementation may vary be member.
2 hours of footage! That’s my night sorted! This sounds like it’s gonna be interesting.
Well, our x86 processors don’t have hundreds of registers, a modern i7 have 8 registers in 32 bits mode and 16 registers in 64 bits mode.
The design of the modern processors should be a commitment between amount/complexity of fuctional units and control unit complexity. In the video the say they talk about decoding in other conference i’m looking forward to see, so, despite this been a neat hack it sure adds some complexity to the CU.
It could be interesting to try, but i don’t thing this is going to be a big big iprovement, maybe interesting for mobile devices as it seems to have a nice cost/calculation.
The mentioned “Itanium” CPUs implements
-128 82-bit Floating Point Registers
-128 64-bit General Purpose Registers
-64 1-bit Predicate Registers
-8 64-bit Branch Registers
-8 64-bit Kernel Registers.
128+128+64+8+8 = 336 Registers per core
Some of this registers can accessed by lower and upper half.
Cu Ben
>a modern i7 have 8 registers in 32 bits mode and 16 registers in 64 bits mode.
http://en.wikipedia.org/wiki/Register_renaming
This has been in the x86 family since the pentium pro.
There is a difference between architected registers and physical registers. Look up “register renaming”.
Holy crap, it’s like a geek version of Willie Nelson! Seriously though, what a fascinating idea!
Heh. I was thinking Santa Claus.
I’m pretty sure I’ve seen the same scheme used for optimizing some kind of virtual machine, at least from the brief description. But I’m not hardcore into cores enough to watch two hours of video! At least now I’ll know who’s responsible if the design ever hits the market.
there are so many errors in that article. It should say DSP or CPU, not DSP or superscalar. Non superscalar CPU’s are still perfectly capable of running regular software etc. Superscalar is just a technique which can increase the throughput of a CPU, it is not a fundamental thing that all general purpose CPUs are superscalar (however most modern ones are)
Agreed, the number of errors per sentence is amazing. For one thing, of course you can do general computation on a DSP. Also, we have heard of stack architectures before. They are slow, which is why all successful CPU architectures have register files. However, cranks love them…
So is this guy’s stuff not revolutionary? Can you elaborate on why/why not?
Well, some EE PhD. (candidate) students are required to design and implement a new CPU architecture, (or at least implement a working subsystem of that CPU), So there are probably “hundreds” of “revolutionary” designs out there, just sitting on breadboards, prototype silicon (or germanium or gallium arsenic wafers) and documented in Manila folders, having been abandoned after the Degree is awarded.
In the past Math PhD.s were required to invent a new “Math” for their degree.
David doesn’t know what he’s talking about. It’s not a stack. The instruction operands aren’t pre-defined (top of stack and next on stack), they must be specified as positions on the belt. The second video explains it much better than I can. If you’re impatient, skip to 17m or so where he starts explaining the problem with having lots of registers and what they do to solve it.
What is currently better for performing either of the operations discussed in the article except DSPs and superscalar type CPUs? (respectively)
Stack based architectures are also good for virtual machines since it’s easier to map a virtual stack to native a register set but harder to map a number of virtual registers to a different number of native registers.
Sounds like another stack based CPU.
Did you watch the video? You’d know that a stack expands and contracts, while the belt simply treads along. It’s closer in concept to a transport-triggered architecture than it is to a stack architecture.
*sigh*
No, Belt is neither a register file with shifting address, nor a stack. Belt implementation would probably be closer to a forward pipeline in a similar way they are in MIPS (ALU can access to a register content computed in a previous stage instead of the register file, removing any RAW lantency). As the result of the ALU is put in the forward pipeline, Mill ALU put it in the Belt. The main difference is the forward pipeline timeline is very short (I think it contains only the previous two results). Another good thing is Belt also stores the metadata like integer or float flags which allow an execution unit to compute faster by getting those metadata as input instead of rebuilding them at each instruction execution as in a standard architecture. For instance, metadata can say if the value is not a result: execution unit will do nothing and output a Not A Result value if one of input is a Not A Value. Float point values greatly benefit for the metadata too.
It’s a belt machine.
Like a stack machine…
the result is implicitly addressed (top of stack, front of belt) .
it’s designed to avoid expensive multi-ported register files
Unlike a stack machine ..
belt values are single static assignment, you can use any position in the belt for any instruction
dead values on the belt are discarded automatically (for live values the compiler will spill/fill to scratchpad)
“so much more efficient than the x86 sitting in your laptop.”
implying i have a laptop
implying i use x86 processors
How dare they make an assumption that will be accurate 95% of the time!
Shhh! He thinks he’s the only person on the Internet! Be vewwy quiet!
+1 to both of you!
– Sent from roboman2444’s iPhone
Show me the cheap DSP’s please..
Just quit writing articles, you are just the worst person for this job..
For example, you can get several TI DSPs from Digikey in quantities of 1 for under $20– some as low as $7. I think that qualifies as “cheap.” Sure you can find DSP chips that cost several hundred dollars, but there are inexpensive ones as well.
As for him being the “worst person for the job,” what would you have to complain about if he stopped writing? Be civil.
that is plain rude and pointless. Please win a Darwin award. You’ll save some oxygen for us.
A Darwin award implies notoriety.
/There’s your burn for the month.
Something similar has been around for years – counterflow pipeline. Never took off, but on paper it has much better performance as well. The problem with taking and placing data on the belt is that when you turn it into the actual chip it results in a lot of slow logic.
I don’t know why… but reading this made me angry.
Probably because this article basically marks the point in history when quality of technical data in HaD articles has reached Gizmodo levels?
Ah yes, on paper it would be faster. On what workloads? How about running a modern OS? For which compilers?
Sounds like another pie-eyed RTL designer thinking they know everything.
The RTL is done! It simulates! everything is perfect! In wonderful simulation land, everything is always perfect. Everything is always fast, everything always meets imaginary timing.
Sure, I can run at 4Ghz! It passes RTL simulations!
I’ll skip all the practical problems that this wonderful design has, and leave it in the imaginary happy land where everything always works.
I feel compelled to set the historical record straight – people have done general purpose computing on DSPs at least since 1991. They were being used then to control the relatively new-fangled tunelling electron microscopes. Or for a computational physics application, Google “QCDSP” – the forerunner to QCDOC, later renamed “Blue Gene” by IBM.
Errr….ummm…..no.
Blue Gene was powered by PowerPC CPUs, not DSPs. QCDOC inspired Blue Gene, but they’re very, very different machines.
Ok, the editor is clearly not qualified to talk about cpu technology. It’s ok, usually hack-a-days editors seem very competent, but cpu technology is a bit of a special field, and it’s no wonder even hack-a-day struggles. I kinda felt the same reading the write up how I usually feel when reading technology or science news in general media.
Yeah, I give Brian a pass on this…
if for no other reason than the followup comments can be so educational and/or humorous.
This seems awfully similar to how the TI-99/4A handled registers in RAM.
“Thou shalt not pass” gandalf
From an architecture viewpoint the packing complexity would simply flip the space time relationship.
From a functional viewpoint, how is re-patenting Transputer algorithms ethical?
http://en.wikipedia.org/wiki/Transputer
From a comedic perspective, its funny seeing the google crowd going “WTF?” at leaving the details to hardware designers. Patents are dumb, as anything thats truly valuable is stolen anyways…
The DSP chips cannot be classified as a separate architecture these days, and this is especially true for some multicore MIPs machines.
Sorry, what they are patenting is nothing like the Transputer. They make no bones about using existing ideas and technologies, but have come up with their own way of implementing things that is patentable (don’t forget that patents are about “a device/method to do X” rather than the basic idea of X).
The Belt for example is only how programmers see it, under the hood it’s based on a fusion of registers and CAM. When you call a subroutine/function you get a new Belt, containing ONLY the passed parameters. When you return you can return more than one result to the original belt. Any operation that was in mid flight before the call drops its results AFTER the return.
I’m not sure how it manages things like context switches, but a general problem like the Unix Word Count utility is quoted as running at 25 operations and 1 input character read per clock, so that’s 1.2 GB/sec (if you can feed it data that fast).
First of all, you all need to chill about the article. In-depth knowledge of CPU design is very rare and even if he spent a few hours researching, he’d still likely come up with errors due to misinformation/dated terminology/general unfamiliarity. Cut him some slack. I wouldn’t envy his position.
That said, I watched the second video and found it very informative. You all have been a very hypercritical bunch about it, but it looks promising. Not sure it will succeed in becoming much of anything, but from what I can tell it really diverges and brings something new to the table.
I enterely agree with Logan: most of comment seem to be from people who just the read the misleading article and didn’t care to watch the video. The videos are very interesting and if you know how a CPU works you can only admit that the guys knows what he is talking about. Sure everything is not new and he is the first to admit it so what’s the point of being so hateful as “yet another XX-like cpu”, you are not being better than the editor here.
I think it is promising, even though it is nowhere near production and I’m eager to see other videos. Wait and see.
>Combine this with the fact that connecting hundreds of these temporary registers to places where they’ll eventually be used eats up about half the power budget in a CPU
I do CPU design for a living. The rename register file is simply a memory, and consumes little power. “bypassing” registers does consume some power, but the big spenders are often the caches and ALU.
Also power is not the same as energy, and most people now days care about battery life – energy. It’s generally better for energy to have a out-of-order or otherwise faster core that might take more power than a ‘simpler’ lower power architecture that runs longer (as the former can be powered down sooner).
The presentations I can find focus on the ALU and instruction decode, but frankly these don’t mater much, for general purpose applications the bottleneck is memory latency, not how the ALU etc work. That’s one of the prime reasons why DSPs do better – they can pipeline memory references, which is usually impossible with general code. Out of order (along with prefetching) cuts some of that latency out, which is why it is in common use.
Since 1980’s we’ve known how to scientifically evaluate new architectures – take industry accepted benchmarks, compile them onto a model of the proposal, and see the performance and energy use. I couldn’t find these numbers.
It sounds good.
I think it’s better to let users experiment this processor architecture via FPGAs if it’s really as good as on paper. :-)
Having watched the two videos here are a few of my thoughts:
1) As with all of these sorts of projects, it will be interesting to see if they have real-world results which match their theoretical results. Here’s to hoping it works out!
2) Since the belt length isn’t fixed the number of results you can “address” changes depending on your processor and you’ll have to shove data in and out of scratch more or less frequently if you swap your harddrive into a different machine. It seems like it would make more sense to fix the length of belt at some long but reasonable level for the “general” level they’re aiming for, then essentially make the promise to only increase the length. This would make binary compatibility within a specific generation possible, and then you could increase the belt length when you released a new generation if it enabled some great performance increase.
3) Putting fixed latency instructions into the set is always kind of scary. I don’t like the idea that if someone invents a signed multiply that runs in two cycles it couldn’t be put into newer versions of the processor without breaking old versions of the code (belt positions wouldn’t match). I get that they’re doing it because you either get stalls or limit belt utilization to some sub-optimal level, but it still seems crappy. I would much prefer stalls to having pipeline-latency-aware compilation.
4) I’m curious what defines the order for belt insertion within a single instructional block (i.e. who wins when I dispatch multiple adds simultaneously). This must be well defined, but I would still like to know. I also did not wholly follow the whole multiple latency register thing, there must be some tagging involved, but it wasn’t explicitly mentioned so I remain in the dark.
5) It’ll be interesting to see what happens with the presentations on protection, exception handling, memory hierarchy, etc. I wish they had finished their patents so that they could answer more of the questions!
I’m sure I missed a few questions I had over the course of the nearly three hours I was watching these, but these were the ones which stuck out when I was done.
Oh! I remember one of my other comments: toward the end of the decoding section he revealed that they restricted certain types of decode operations to specific decoders. It sounds like this was done to limit the maximum bit size of the instruction set (i.e. instruction 0x1A may mean ADD on one decoder and LD on the other decoder), simplify the decode logic on each specific decoder, and limit the number of interconnects. But I’m curious what this means for instructional blocks: does this mean that you’ll have to interleave the type of operations in each block? If I only perform one type of operation for a given interval does that mean that the other decoder will be idle? Does the compiler have to create an empty instructional block?
It sounded like the balance was 17 ops in the non-load decoder, so the chances I would have something to the effect of 34 arithmetic operations with 0 loads interleaved is hilariously unlikely, but I’m curious how the case is handled.
This also means that if something goes wrong and you start feeding the blocks into the wrong decoder the behavior will be incredibly mysterious.
They do explain it in the early vids.
Instructions are broken into two code streams. (two each of the L0 and L1 instruction caches. It’s broken up into flow on one side (constants, load, store, read, belt mangling, spill/fill, branch, jump, call and return) and execution on the other (add, mul, shift, compare, gangs, picks and args)
Decode is also pipe-lined (phasing). Phasing means you are only decoding certain types of ops in each cycle.
Instructions are tagged with metadata to help decode, includes the number of instructions in each phase. Pipelines are arranged in such a way it’s more likely only the first execution slots of a type will be used and the last will be empty. For instance the Mill gold (the 33-wide one) has 8 ALU’s, the first four are pretty complex and can handle floating point, while the last four are much simpler.
It’s possible, but rare to need a no-op to pad between instructions. Otherwise the no-ops for the higher FU’s are implied in the meta-data. Also if the instruction is truly a no-op on one side or the other, you do need to send one no-op in the stream. But usually you are saving quite a few bits if you aren’t using the whole width.
First of all, to spite all the hate received earlier in this article, i personally really enjoyed both talks and appreciate this article, which got me thinking- one of the reasons I always come back to HaD. Thanks Brian.
I hope when it is released it is combined from the start with TIs octa-core DSPs in a power efficient performant combination.
Great article and video. A lot of people here are making some bad assumptions based on the article due to their own lack of knowledge — I’m guessing they didn’t watch the video.
I agree with the ones who don’t know whether it’ll actually work.
This actually reminds me of a 1-core GA144 chip (which has 144 cores); it has a hardware stack which is like a belt, except that ALU only and always reads the top 2 items on the stack (unlike the belt, where you can read any element).
A man talked about zombies pushing and moving some suspicious items toward the north of the town.
However, it is possible to infer some information about
the TESO economy just from the small bits of information being released onto
the web. It is not so much that they want to help improve Ibo civilization,
but they actually believe the Ibo are inferior and that their entire culture needs to be erased and then rebuilt in the Christian model.
it is not FiFo it is FiLo. thats why it is new.
I enjoyed this … but why no reference to the original computers EDVAC and EDSAC, which used mercury delay lines for storage, and thus had a “belt” (programmers had to “time” their code to pick up the right value as it flew past).