If you are writing a hello world program, you probably aren’t too concerned about how the compiler translates your source code to machine code. However, if your code runs on something that people’s lives depend on, you will want to be a bit pickier and use something like the COMPCERT compiler. It’s a formally verified compiler, meaning there is a mathematical proof that what you write in C will be correctly translated to machine code. The compiler can generate for PowerPC, ARM, RISC-V, and x86, accepting a subset of ISO C 99 with a few extensions. While it doesn’t produce code that runs as fast as gcc, you can be sure the generated code will do what you asked it to do.
Of course, this still provides no assurance that your code will work. It just means that if you write something such as “x=0;” the generated code will set x to zero and will not do anything else. You can apply formal methods to verify your source code and be assured that the compiler doesn’t introduce possible failures. Cases where code like “x=0;” does extra things or incorrect things are very hard to figure out because the source code is correct and an examination of the generated code would be necessary to find the compiler’s code generation bug.
All this does come with a few restrictions. For example, variable-length array types are not available and you should not use longjmp and setjmp. There are also restrictions on how you can code a switch statement. There are also a variety of options that allow you to examine your code under an interpreter.
You may think your compiler doesn’t need verification, but you might be surprised. The compiler documentation references several papers ranging from 1995 to 2011 that have found many incorrect compilation problems with popular compilers.
COMPCERT operates on observable behaviors of a program, such as calls to I/O functions or accesses to volatile memory locations. The compiler is allowed to improve a program’s observable behavior — for example, resolving a divide by zero error — but must not change other behaviors. Note, however, that while you could argue that execution time and memory usage are externally observable, they don’t count in this context.
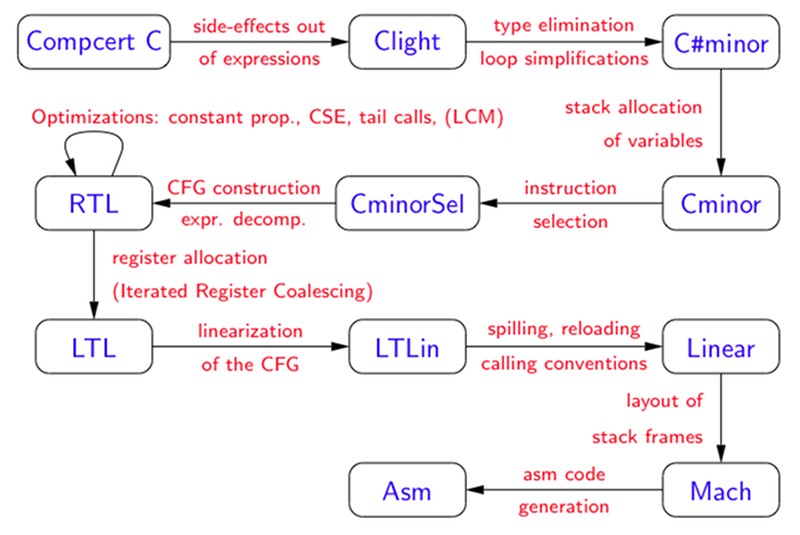
To make the proof manageable, the Coq proof assistant does automated checking on the compiler proofs and the compiler itself uses 15 passes, each proved correct. As of today, there is still about 10% of the compiler that is not proven correct. Researchers dedicated 6 CPU-years to finding compiler bugs using Csmith and could not find any errors (which was not true of other compilers).
Of course, it is still up to you to make your program do what you want it to do. All this does is ensures the compiler does what you asked it to do. Luckily, there are tools to help formally verify your code, too.














Nice hack(?)!
:-Þ
I’ve written C for something like 35 years and I have no idea what you are talking about.
just avoid the clang users, and you will be fine…
;-)
Clang is great…! The error messages are wonderful.
It’s relatively rare, but every now and again you can get weird cases where things don’t compile into code that does what you’ll think it does.
I’ve only encountered it three times over a similar period to you. Twice was MSVC, and both were verified by a much more experienced coder than I (“huh, I’ve never seen that before”) we submitted it to MS, but never heard back.. the third time was gcc. The gcc issue got fixed when the next version came out very soon after we found the issue. We never got around to reporting it. The MSVC one was really strange.. eventual workaround was just to do the damn if statement twice:
blah=1;
if (blah==1)
{
// whatever is in here never fired..
}
if (blah==1)
{
// but this will.
}
I think I still have a backup of that code somewhere…
The person I had reviewing my code wouldn’t sign off on it without really detailed comments about why we’d done the test twice, and a report from both myself and the other coder in the supporting documentation. From memory the first test always seemed to wind up as either a JNE or something else not quite right.
I’ve had that issue myself! It had me tearing my hair out for about 2 weeks, because it was in an embedded system and would only happen when the machine was running hard. In my case it turned out to be noise on the microcontroller reset line. Didn’t cause a crash or anything, it just caused the code to execute *incorrectly* very rarely.
Then the “Video: putting high speed PCB design to the test” must have been very timely.
It’s not that common unless you’re doing odd things.
At a previous job, we typically found a couple of these each year, using MSVC. Each time we’d find a workaround and document it in the source code. This also meant we were slow to upgrade to new versions of MSVC as they’d potentially bring new bugs to code that worked before.
We also did some work with a certain class of embedded devices from a variety of manufacturers, and found an unbelievable range of errors in how they executed instructions. One always gave 8 as a random number. But another crashed when asked for a random number, so we couldn’t use that instruction at all.
Never seen one outside of that job.
There’s an xkcd for that… (Well the software version) https://xkcd.com/221/
Ah, but what’s verifying the verifier?
Gotcha!
Quis custodiat custard.
If you send the custard to me, I’ll guard it. Or at least, I’ll make sure no one else eats it…. :P
But who will make sure that YOU don’t eat it?
See “Reflections On Trusting Trust” by Ken Thompson. You can’t trust any compiler because you can inject code into a compiler and thus any software that passes through a compiler is also suspect. Even as something as simple as a hexdump utility or cryptographic digest utility can be tricked into hiding information necessary to determine if you’re on a compromised platform.
Thank you for the reference.
An excellent paper. By someone who should know.
One of my all-time favorite papers. Mind-blowing, when I first read it back in the day.
If you’re woried on this level then you might be better of not using C at all but languages as Ada, or Haskell with built in verifiability.
And / Or combine it with dual processors which check each other and hardware interlocks.
But solutions vary widely depending on the actual system and it’s to easy to be talking gibberish without real life examples.
re: using Ada/Haskell. That is fine, if those compilers have been formally proved. Have they?
re: using dual processors. That is addressing hardware reliability, but this article is about compiler errors.
Ada, probably yes. That kinda thing is about the only reason anyone uses Ada.
…or just write in 100% assembler.
Oh – then you still have to verify that the hardware does what you told it to !!!!
You can trust smaller microcontrollers and microprocessors, usually. As long as you are aware of all silicon bugs an can write your code around them. You can’t trust anything big and modern, like your own PC because they have hidden processors with hidden code that runs with higher privileged than even your OS. Can you trust huge, USA-based corporations?
Unless you fabricate everything from the silicon and up in your own lab (yes this includes passives as well), you’re going to have to trust someone. Even _if_ you decide to fabricate everything yourself, you are probably going to have the help of other people.
But can you even trust yourself? Trust that you have not forgotten something, trust that you have made full engineering notes, trust that you don’t spill coffee over them, trust that a little hand shake doesn’t result in a little solder bridge, trust that your eyesight can spot little solder bridges?
And can you trust the instruction you use to make your own devices?
“You can trust smaller microcontrollers and microprocessors, usually. As long as you are aware of all silicon bugs an can write your code around them. ”
@Moryc – Agreed! Usually well established processors (especially smaller and older ones) have bugs which are well known in the community, along with their workarounds.
Even emulators are written to faithfully implement bugs in these CPUs. That’s about as trustworthy as one can get.
Yea. Keep it simple, and close to the metal. And then it is much harder for “the bad guys” (TM) to run their code.
“You can’t trust anything big and modern, like your own PC because they have hidden processors with hidden code that runs with higher privileged than even your OS. Can you trust huge, USA-based corporations?”
…Is it just me or did the conversation escalate quickly from accidental glitches in compilers to black helicopters spying on your projects?
He’s right though. Apparently all recent Intel processors have a minix OS built in that runs at privilege -3 when it runs, but how it gets to run is not widely known – outside of Intel and the security services that is.
Good grief, no. Ada compilers, despite supposedly being tested and correct by the DoD are some of the most bug-riddled things I’ve ever seen.
Is that just because the compiler has been so thoroughly tested that all/more bugs have been found? I’m unfamiliar with Ada, and pretty poor with all but basic embedded (PIC) C. Microchip’s XC8 compiler is pretty buggy in my experience too.
You’d hope that. In my case, we found a bug in the garbage collection which meant that even a simple “create a linked list and forget to destroy some of the elements” test program brought the machine to its knees. This was on a DoD-certified (one of 4 at the time, iirc – this was 1991) Ada compiler.
Alphatek, that wasn’t the Ada compiler for the Harris Nighthawk, was it?
In my career I’ve ran into C compiler bugs 3 times.
Microsoft QuickC 2.0 had a bug in the expression evaluation where it was apparently trying to use AX as an offset from the stack frame, i.e. Something like MOV AX, [BP+AX]. Obviously this is impossible and got assembled as MOV AX,[BP+SI] which was incorrect. I reported it and got a reply from Microsoft: They had already fixed it in QC 2.5 which had just been released.
Another one was a problem in Borland C++ 4.0. I don’t remember the details but it took me weeks to find and analyze the problem, and buy then I had gone well past an important deadline. I swore never to use Borland compilers again, and I haven’t.
Another one was the C compiler for the Texas Instruments TMS320C40 DSP. If you write a long function and the optimizer figured out it could skip a lot of code, it would forget that a branch instruction could only go forward by 127 or backwards by 128. So if you did a cascading-if function like the following, execution would jump to a random place if “ok” would get set to 0 too early.
void main( )
{
int ok = 1;
if (ok)
{
ok = …
}
if (ok)
{
ok = …
}
/* repeat 40 times or so */
return ok;
}
Another shout out to the defective TI DSP compilers.
The TMS320F206 compiler used to compile code that would shorten integer operation results by two bits in random places, so 2 x 2 would return 1. Reported it to Ti, who refused to fix it.
By law, 2×2=1 in Texas.
XC8 compiler from Microchip screws u code n purpose in “Free” mode: it adds additionl jumps to make code slower and bigger so user is tempted to buy a license for it. You can:
1. Live with bloated code.
2. Pay for license.
3. Rewrite ASM code to remove those jumps.
4. Crack your compiler and use all the optimizations for free and give a big “F**k you!” to marketing people from Microchip.
5. Find an alternative compiler that is cheaper and just as good.
Yeah it’s infuriating.
I’m far from an XC8 power user, but I’ve encountered several bugs (documented and undocumented) with XC8 over the past 5~ish years. It’s had me tearing my hair out for a week at a time on more than one occasion. I seem to find that the largest concentration of bugs seem to be centred around the peripherals, especially the PITA MPLAB Code Configurator. Bring back !
I don’t use MCC for anything. Peripherals are rather simple to configure and use by directly accessing registers. I even skip more advanced usages of C and avoid pointers because they are always causing problems…
“XC8 compiler from Microchip screws u code n purpose in “Free” mode: it adds additionl jumps to make code slower and bigger so user is tempted to buy a license for it”…
I think you are demonizing Microchip unjustly here. It may be true that you are seeing all kinds of rubbish being added to the non-optimised executable but I think you will find that if you dig deeper it is the optimiser that is actually ***removing*** that rubbish from the optimised executable.
What you will probably find is that internally the XC8 compiler is generating code for some other CPU (maybe a Z80, maybe even an imaginary CPU) then converting that code into PIC machine code. Optimisation will be performed at several levels. One level will undoubtedly look for special cases (sequences) of internal code that can be directly mapped to optimised PIC equivalent. If you look at some of the convoluted machine code generated by the XC8 compiler for testing and setting bits and consider that the internal code probably does not have the equivalent features then it becomes clear why the non-optimised code is so bad (for this case).
It’s wild to think that Microchip is profiting enough off of XC8 licenses, that it would justify them not putting out a free version (and thus selling more PICs because their performance is improved!).
an empty loop which is legitimately used in some embedded timing delays gets removed by some embedded compilers, AVR Studio for example. Now If I do use them I put ASM NOP inside the inner loop to ensure it doesnt get removed.
I thought it was a bug when I originally asked on stackoverflow but got shouted down as an idio who knew nothing about C or compilerst, it was about the time I closed my stackoverflow account as I remember
https://web.archive.org/web/20180530204709/https://stackoverflow.com/questions/50593733/atmel-studio-7-optimizing-out-whole-procedure-in-c
Deleted but Not Forgotten :-)
Well, boz’ stackoverflow problem still seems like the typical I-want-a-delay embedded c beginner’s code.
Compilers SHOULD and CAN optimize code without side effects. In this case, the code is unnecessary, because removing it doesn’t alter the program flow.
It’s not just the “program flow” that is unaltered — variable j has no side-effects as it’s local and it’s value is never used outside of that loop. Even if the compiler “figured out” that in the end, the variable is zero, so it eliminates the middle and set it to zero, but then “oops — don’t need it anyway” so it skips that too and it just disappears. Sure, the optimization may be too aggressive when removing it, but what about something like:
If(0) /* then */ exit;
This should never exit since 0 cannot be true, but then just eliminate the entire statement as being (stupid) dead code. I have seen (more complex) examples of this in released code that only got “caught” when the code was finally validated. Leaving dead code in violates EVERY SW safety standard I have ever seen (and common sense). One thing I know for sure, is that compilers cannot read our minds (let alone, out intentions).
There are ways of preventing a compiler from optimising out functions such as you mention here. volatile can help, and pragmas that turn off optimisation around your function.
That’s generally what compilers are supposed to do, generate the most efficient code and they can be quite clever about it, but sometimes too clever, which is why we have things like #pragmas and optimisation settings so you tell the compiler what you want it to do in such situations
There are several compiler bugs. Ex. on arm gcc 8.2 with optimization on if you compile some byte accessing code, (on arm you should access the word memory content word aligned), the gcc 8.2 will optimize this code to word access without volatile => unaligned access!
…
if (n&16) {
*(volatile unsigned char*)d++ = *s++; *d++ = *s++; *(volatile unsigned char*)d++ = *s++; *d++ = *s++;
*(volatile unsigned char*)d++ = *s++; *d++ = *s++; *(volatile unsigned char*)d++ = *s++; *d++ = *s++;
*(volatile unsigned char*)d++ = *s++; *d++ = *s++; *(volatile unsigned char*)d++ = *s++; *d++ = *s++;
*(volatile unsigned char*)d++ = *s++; *d++ = *s++; *(volatile unsigned char*)d++ = *s++; *d++ = *s++;
}
…
Hi Andy,
How did you end up fixing this specific issue?
Thanks.
Compiler bug thread? Compiler bug thread.
Once I worked on a strange uC which was supposed to be 16 bit, but in reality it was 8 bit. The only 16 bit part was the work register (and the ALU). But that (work register) was even strange too: it was made up from two 8 bit registers. You could address it as A or B to get 8 bit or as C to get 16 bit mode (three separate addresses!). I suppose the compiler bug arised from this.
I wrote code in C. One function returned a boolean value as an 8 bit number. Then in another function it got tested. Something like this:
uint8_t func() {return True/false;}
if(func()) { do something }
The compiler used the B register to return the value from “func”, but during testing it decided to test the value as the C register with a single instruction (there was no 8 bit if zero instruction, but there was a 16 bit one). Obviously the A register always had some leftover junk in it. In result the A register got OR-ed with B, resulting the branch executing most of the time. It took me like 3 days to figure this out…
And this was an automotive certified compiler and uC.
> You could address it as A or B to get 8 bit or as C to get 16 bit mode
That’s not very unusual, for example the Z80 registers BC, DE, and HL work that way.
I my 35 years as an engineer, I or someone on my team has encountered a compiler bug maybe three times. (and many instances of higher level optimization settings breaking things)
While this is no big deal for your everyday Joe, this is great news for people who write code for mission-critical systems. When I say mission-critical systems, I mean systems that MUST NEVER fail and MUST be bug free. You don’t want your car’s ECU or satellite to have any bugs in them and you have to get it right the first time.
Romans not having zero, were not able to close their c programs
In my experience producing a C compiler that produces a 1 to 1 mapping between source and executable is not an issue. That is to say for each source statement produce a well defined group of machine code instructions that perform the statement as intended. In this case a bug free compiler is easy to produce. In my experience the overwhelming cause of compiler bugs is optimisation. Programmers want compilers that produce executables which are lean and fast. Unfortunately just turning off all optimisation does not guarantee that a compiler will produce a 1 to 1 mapping as some optimisation will be built in and not suppressible.
I’ve found numerous compiler bugs over the years. Most of them were in non-mainstream compilers – like from Renesas, MicroChip, HtSoft, Atmel, Motorola. Almost all the bugs were related to the optimizer, and many with hardware access using volatile or use of pragmas. gcc for me has been pretty clean. I regularly look at the compiler’s generated assembler when I see suspicious program behavior.