For both the Raspberry Pi and BeagleBone Black, there’s a lot of GPIO access that happens the way normal Unix systems do – by moving files around. Yes, for most applications you really don’t need incredibly fast GPIO, but for the one time in a thousand you do, poking around /sysfs just won’t do.
[Chirag] was playing around with a BeagleBone and a quadrature encoder and found the usual methods of poking and prodding pins just wasn’t working. By connecting his scope to a pin that was toggled on and off with /sysfs he found – to his horror – the maximum speed of the BBB’s GPIO was around three and a half kilohertz. Something had to be done.
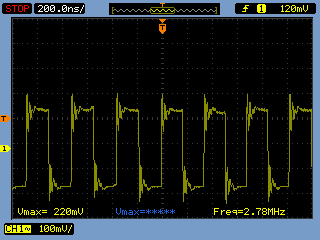
After finding an old Stack Overflow question, [Chirag] hit upon the solution of using /dev/mem to toggle his pins. A quick check with the scope revealed he was now toggling pins at 2.8 Megahertz, or just about a thousand times faster than before.














Compared to this method would it be faster to use the PRU (something like PyPruss) ?
Yes, use the PRU: http://hipstercircuits.com/pypruss-one-library-to-rule-them-all/
The BeagleBone also allegedly has some sort of embedded microcontrollers (“PRUs”) that have more direct access to I/O. How fast can you toggle a pin with one of those?
5ns per instruction?
at least 10MHz doing something fancy, faster doing something simple
The PRU’s work at 200MHz, so one instruction takes 5ns. I used twelve of the output pins and connected them to a 12bit Digital-to-Analog-Converter and easily created triangles with 25 MHz sample rate, limited by the DAC I used. In my PRU code, which has to be written in assembler, I simply write an integer to the PRU register R30 which takes one instruction (5ns), do some calculations and checks and repeat the write instruction. The data are immediately (within 5ns) available at the output pins and get converted into an analog signal. In principle, one could speed this up to the full 200 MHz (i have seen dirty 200MHz squares on my oscilloscope), but the problem is here that you have to be very careful that residual capacities and do not form a low-pass filter with the electrical connections/input impedance of the device connected to the output pin, which can completely filter away your fast signals.
By the way, digital input also works up to 200 MHz, and the integrated ADC’s can go up to about 1.5 MHz when properly handled (i do all this with the PRU).
http://processors.wiki.ti.com/index.php/PRU_Linux_Application_Loader_API_Guide
Thanks for your comment. It was really useful. Can you tell me how you got the GPIO Inputs/outputs to work in PRU ? I wanted to know how to enable the GPIO pins for PRU read or write process.
Same as all other pin configuration, this is done via Device Tree, typically in the same overlay used to enable PRUSS. (In fact I noticed in the uio_pruss driver source code that it will print a warning in the kernel log if it doesn’t include any pin setup.)
It takes two PRU cycles to write to a GPIO pin, but the write gets posted in the interconnect fabric. If you do back-to-back-to-back writes, the maximum rate to toggle a GPIO pin (*NOT* a dedicated R30 PRU output) is 40 nS. I have timing details on reads and writes as comments in some of the PRU code I wrote for doing high-speed I/O for step/dir and PWM for LinuxCNC: https://github.com/cdsteinkuehler/linuxcnc/blob/MachineKit-ubc/src/hal/drivers/hal_pru_generic/pru_generic.p#L135
Which also means the 2.78 MHz that was achieved by using /dev/mem on the cortex-a8 is still crappy performance: 180 ns per toggle. The reason is that annoyingly /dev/mem (and ditto for UIO) make “strongly-ordered” mappings, i.e. non-posted writes are used, making them as slow as reads.
Wow, thats an impressive gain, or an unimpressive starting point, Dam you einstein.
Nice work.
meh, just code it in assembly, like it should have been done in the first place. more abstraction == slower speed.
Or, according to the java lovers out there, code it in java, run it on a java interpreter written in java [add recursion here] for ultimate speed!
no no nooo, he needs to add arduino for gpio and raspee for gui
yep, add an arduino, running an ethernet shield, connected to the raspi. Think how much faster and efficient it would be.
Or better yet, add an arduino, running rs-232C, connected to another arduino, running an rs232C to ethernet shield, connected to the raspi.
arduino Ethernet shield + Raspberry Pi = $85
Beaglebone Black = $45
Missing the joke = priceless
Nobody uses Java interpreter these days. Modern JVM do use JIT for long time already.
rasz says: “no no nooo, he needs to add arduino for gpio and raspee for gui”
Not really… The key limitation is not due to any particular type of code used (but that can matter as well). It’s about the hardware. These ARM (and similar) SoC’s have an internal bus, typically an AMBA bus (Wikipedia knows what AMBA is) that slows GPIO enormously. The fastest way to get through this bottleneck is via DMA – and DMA access is often either not available in the documentation from the ARM IP licensee/SoC integrator or not well documented/supported. Some SoC’s (like the PRU thing on the BBB) have specialized stuff hanging next to the GPIO to get around this to some degree. But you’re never going to see anything even close to the CPU clock speed near the GPIO on these SoC’s. With the Raspberry Pi, you might be better off pairing a capable micro-control than fighting with trying to squeeze more speed out of native GPIO, especially if you’re coding in something like Python.
Actually the DMA (insanely feature-rich) engine on these TI chips is decently documented, and you could indeed hook up a DMA channel to one of the general-purpose timers to periodically sample the GPIO or output data at a fixed rate. It would still be subject to jitter if there’s a lot of other I/O going on at the same time, though you could even use the interconnect’s QoS features to prioritize things.
Using the PRU’s dedicated GPIO will still win big time though since that’s literally hooked up directly to registers of the two PRU cores. I don’t think all of them (17 in + 16 out, per core) are available on the beagle though, due to conflicts. (look for pins labeled PR1_PRU{0,1}_PRU_{R30,R31}_* .. r30=out, r31=in). The PRU subsystem also has direct access to UART0 and eCAP (timer/capture) modules.
AMBA isn’t really used on this SoC family btw, the 128-bit AXI3 port of the cortex-a8 is immediately bridged to a different protocol (OCP) which is used by the various interconnects. The L3 interconnect is an Arteris FlexNOC, the L4 interconnects are Sonics3220.
hehe, look at the scope plot..RING RING RING…
hello? who is there? what, IO termination? IO termination who? hello?
That or a long ground wire on the scope probe.
The problem I had with going through Linux for io is the context switching.
In this example we see a screenshot over a few usec. I bet you that if you look over an area of msec you’ll see large gaps where nothing happens.
The problem is that you need kernelspace to reliably do io in Linux, but that defeats the purpose of the system for a large part.
Lastly: this is good progress, but I hope you won’t need input events with an accuracy of less than 10msec in Linux. You’all find yourself jumping hoops to implement something as slow and simple as a triac-based dimmer.
^True. Kernel jitter is a problem… the next thing to tackle would be to implement a realtime kernel or, even better, to get the RT-PREEMPT kernel patch working.
Once that is achieved, you can reduce that 10ms number to about 10us, making this work much more interesting.
make that 50us, if you google you will find someone who tried it last year for the server control
servo control :/
Typical latency with a xenoami patched kernel for the BBB is about 25 uS, with worst case around 70-80 uS.
This info comes at a good time for me. I’m about to use a BBB for some datalogging and I’ve been concerned that going thru the filesystem for the GPIO access was going to prove to be a bottleneck.
Word of caution. Doing this is dangerous because the kernel driver still thinks it is in control of the GPIO bank. There will be odd side effects if kernel access to the bank is not disabled first.
There are set and clear bits in the GPIO register banks. You write a one to a bit in th set register to set that GPIO pin and write a one to the same bit in the clear register to clear it. This allows safe GPIO twiddling without requiring locks or atomic read/modify/write cycles.
We interrupt this post to remind everyone that you can’t toggle when you don’t have the CPU, and unless there are lots of cores and you are guaranteed one…t
If I remember when looking into this years ago, you have to be very careful when GPIO toggling directly via memory as you may inadvertently toggle some shared by the flash or SD ports and corrupt data.
While in general it’s wise to be careful when poking around in memory-mapped I/O, note that changing the GPIO value for a pin has no effect if that pin is configured to a peripheral (like the flash or MMC controller) rather than to GPIO. Unless linux changes the pinmux also maybe? (I’m doing baremetal programming on a related processor so I don’t really know how linux handles these things)
Not using /sysfs wisely? I use ARM9 at 400 MHz, Debian, and kernel 2.6X, and Python can run /sysfs GPIO at 15 uSec on/off/on. I’ll look it up and leave a note.
mmap ? I have spend a lot of time of getting fast acces to GPIO in C and my way was:
echo 1> gpio124 — a few kHz
file=open(“gpio124″,READ|WRITE);
write(file,”1”,1); — around 100 kHz
gpio=mmap(file,…);
*gpio=1; — around 500 kHz
mem=open(“/dev/mem”…);
fastGpio=mmap(mem,…);
*fastGpio=1; — around 100 MHz
PS: sorry for my English, I was always the worst in my class.
that’s a good summary. gives a great insight into the trouble/speed ratio.
…now i wonder if i can continue to use simple shell scripts instead of compiling C programs… maybe `dd` into /dev/mem?
dd wasn’t working form me. My /dev/mem needs to be mmapped by pages and I can not constrain dd to do that.
Opening the node as a file to write was also the method that gave the good speed in Python. On an A8 at 1GHz it would have be over 100 kHz.
Sending bash commands as strings, as recommended in some blogs and forums it pitifully slow. I will have to try the mmap version. Thanks for that.
The following two articles might also be relevant to discussion:
http://veter-project.blogspot.com/2011/09/real-time-enough-about-pwms-and-shaky.html
http://veter-project.blogspot.com/2012/04/precise-pwms-with-gpio-using-xenomai.html
I’m thinking of building a digital hifi preamp based on Beaglebone Black and high end ADC and DAC parts (e.g. PCM1802 and PCM4202). The audio streams are 2 channels in and 2 channels out at 24 bits/sample and 196kHz. This comes to about 10 megabits/sec in and out. The audio chips support I2C with 3.3v signalling. From the above thread, it seems to me that using the PRU should easily accommodate these data rates with direct connection from GPIO pins to the audio chips. However, because the digital audio stream must run at a precise constant rate, I may need to add externally clocked FIFOs between the GPIO and audio chips.
My questions? Where is a good place to learn about programming the PRUs? Are they capable of maintaining a continuous flow of data? What about maintaining a very precise data rate? I presume the PRUs use the Cortex clock…can I perhaps include a very accurate Cortex clock and dispense with the FIFOs? If so, it appears that a very capable preamp can be built around the Beaglebone with just a few not very expensive parts (small quantities of PCM 1802 are around $15 each and PCM 4202 around $10 each).
Aside: The compute power needed is around 200 Mflops (a fancy digital room correction and speaker equalizer), which appears to be well within the NEON FPU’s capability. I’ve already got the software running on a standard PC under Linux and an external studio quality DA/AD box, so porting to Beaglebone shouldn’t be too hard.
Why on earth would you use GPIO for that? The AM335x has two McASP (multichannel audio serial port) peripherals, each supporting four serial digital audio pins (you need only one for the PCM4202 and one for the PCM1802). It generates the clocks required, handles the I2S protocol, has built-in fifos, and supports DMA.
In general, while these big SoCs are maybe not ideal for doing GPIO, they have a ton of useful peripherals.
Speaking of peripherals, …
“[Chirag] was playing around with a BeagleBone and a quadrature encoder and found the usual methods of poking and prodding pins just wasn’t working”
The am335x has a peripheral for interfacing a quadrature encoder. It does noise filtering, quadrature decoding, position tracking and velocity measurement. I think that will beat poking and prodding pins manually any time ;-)
How can i run this code? i tried cloud9 and it didnt work