
Why Buffer? Because buffers cut you some slack.
Inevitably, in our recent series on microcontroller interrupts, the question of how to deal with actual serial data came up. In those examples, we were passing one byte at a time between the interrupt service routine (ISR) and the main body of code. That works great as long as the main routine can handle the incoming data in time but, as many people noted in the comments, if the main routine takes too long the single byte can get overwritten by a new one.
The solution? Make some storage room for multiple bytes so that they can stack up until you have time to process them. And if you couple this storage space with some simple rules for reading and writing, you’ve got yourself a buffer.
So read on to see how to implement a simple, straightforward circular buffer in C for microcontrollers (or heck, for anything). Buffers are such a handy tool to have in your programming toolkit that you owe it to yourself to get familiar with them if you’re not already.
Buffers
Generally speaking, you’ll want a buffer between two processes whenever they generate or handle data asynchronously or at different instantaneous rates. If data comes in slowly in individual bytes (as letters) but it’s more convenient to handle the data in bigger chunks (as words), a buffer is just what you need. Conversely, you might want to queue up a string from your main routine all at once and let the serial sending routine handle splitting it up into bytes and shuttling them along when it can.
In short, a buffer sits between two asynchronous routines and makes sure that either of them can act when they want without forcing the other routine to wait for it. If one process is a slow and steady tortoise, but the other is a bursty hare that needs to take frequent breaks to catch its breath, the buffer is the place where the data stacks up in the meantime.
The family of buffers that we’ll be interested in are buffers that makes sure that the data comes in and leaves in the same order. That is, we’ll be looking at first-in, first-out (FIFO) buffers. For a simple FIFO you can store your incoming data in the last free slot in an array, and read the data back out from the beginning of that array until you run out of data.
Note what’s great about even this simplest buffer; one process can be reading data off of the front of the array while the other is adding data on the back. They don’t overwrite each other and can both access the array in turns or in bursts. But eventually you run out of space at the end of the array, because the buffer only resets the writing position back to the first array element when it’s been fully read out.
This kind of linear buffer works great for situations where you’re likely to read out everything at once, but when the reading and writing are interleaved as shown here, you can run out of space in the array before it gets cleared out, while at the same time there’s “empty” space that’s already been read out in the front of the array.
The solution is a circular buffer, where the data can wrap back around to the beginning again to use up the extra space. Circular buffers are great because they make use of more of the allocated memory than the linear buffer and still preserve the FIFO ordering.
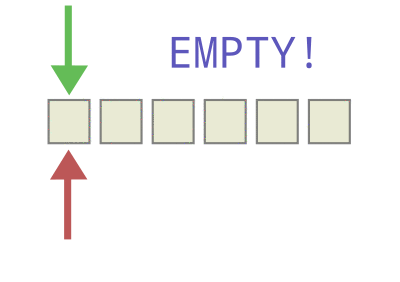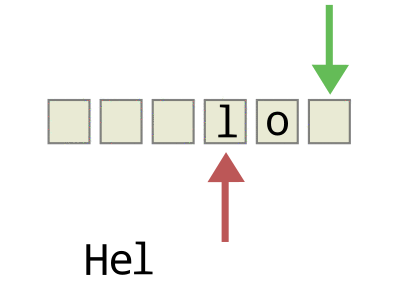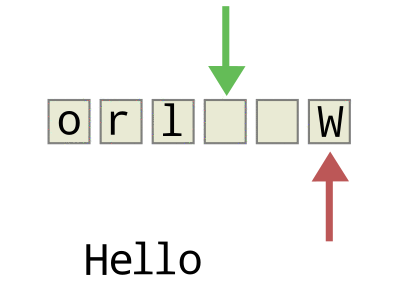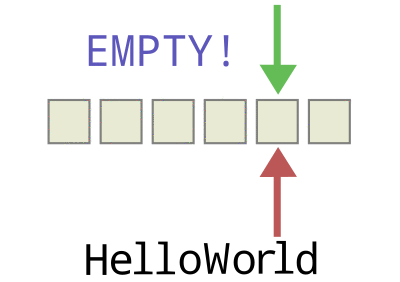
To make a circular buffer, we’ll need to keep track of the beginning (red) and end (green) of the buffer, and make up some simple rules to deal with wraparound and to keep us from overwriting existing data, but that’s about the gist of it.
Circular Buffers: Empty or Full?
With a linear buffer, it’s easy to tell when the buffer is empty or full. If the last available slot is the last byte in the array, it’s full. If it’s the first slot in the array, it’s empty. But things are a little bit more complicated with the circular buffer because the wrapping around often leaves us in situations where the newest data is being written into a slot that’s numerically lower than the oldest data.
So we’ll create two additional variables (indexes) to keep track of where the newest and oldest data elements are in our array. When the two indexes are the same, we’ll say that the buffer is empty. Each time we add data to the buffer, we’ll update the “newest” data index, and each time we pull data out, we’ll update the “oldest”.
If the buffer is empty when both of the indexes are the same, when is it full? This gets tricky, because when the array is completely full — every slot is filled — the oldest index and the newest index are equal to each other, which is just exactly the condition we wanted to use to test for it being empty. The easiest way, in my opinion, to deal with this is just to leave one slot empty at all times.
Watch the animation again, and notice that we declare the array “full” when it’s actually got one free space left in it just before the newest (green) index reaches the oldest (red). That is, we declare the buffer to be full when the newest index plus one is equal to the oldest, which keeps them from ever overlapping except when the buffer is empty. We lose the use of one slot in our buffer array, but it makes the full and empty states easy to distinguish.
There are a bunch of other ways to implement a circular buffer. In all, unless you’ve got seriously pressing optimization constraints, any of them are just fine. We’ll stick with “newest index / oldest index” because I find it most intuitive, but feel free to try them all out on your own. Let’s see it in action.
Code
So here’s what we need our code to do:
- Set aside some memory (we’ll use an array) to use for the buffer
- Keep track of the beginning (oldest entry) and the end (newest entry) of the data in our buffer
- Provide functions for storing and retrieving data from the buffer:
- Simplest methods use bytewise access
- Need to update the buffer indexes on read or write
- Nice to pass error codes when full / empty if trying to write / read
Off we go! First, we’ll set up the data.
#define BUFFER_SIZE 16
struct Buffer {
uint8_t data[BUFFER_SIZE];
uint8_t newest_index;
uint8_t oldest_index;
};
If structs are new to you, don’t fret. They just enable us to keep our three important bits of data together in one container, and to give that container a name, “Buffer”. Inside, we’ve got an array to store the data in, and two variables for the first and last active entries, respectively. Besides the obsessive-compulsive joys of keeping all our data in a nice, tight package, we’ll see that this pays off when we generalize the code a little bit later.
Writing
Now let’s write some data into the buffer. To do so, we first check to see if we’ve got space for a new entry: that is, we make sure that the newest_index+1 doesn’t run into the oldest_index. If it does, we’ll want to return a buffer full error. Otherwise, we just store the data in the next slot and update the newest_index value.
enum BufferStatus bufferWrite(uint8_t byte){
uint8_t next_index = (buffer.newest_index+1) % BUFFER_SIZE;
if (next_index == buffer.oldest_index){
return BUFFER_FULL;
}
buffer.data[buffer.newest_index] = byte;
buffer.newest_index = next_index;
return BUFFER_OK;
}
Here you’ll see the first of two ways to refer to elements within a struct, the . (“member”) operator. If we want to refer to the data array within our buffer struct, we just write buffer.data, etc.
Note that when we’re calculating the next_index, we take the modulo with BUFFER_SIZE. That does the “wrapping around” for us. If we have a 16-byte buffer, and we are at position fifteen, adding one gives us sixteen, and taking the modulo returns zero, wrapping us around back to the beginning. As we mentioned above, as long as we’re using a power-of-two buffer length, this modulo is actually computed very quickly — even faster than an if statement would be.
OK, there’s one more (stylistic) detail I’ve swept under the rug. I like to handle the return codes from the buffer as an enum, which allow us to assign readable names to the return conditions. Using an enum doesn’t change anything in the compiled code in the end, but it makes it easier to follow along with the program logic.
enum BufferStatus {BUFFER_OK, BUFFER_EMPTY, BUFFER_FULL};
Internally, the compiler is substituting a zero for BUFFER_OK, a one for BUFFER_EMPTY, and a two for BUFFER_FULL, but our code can use the longer text names. This keeps us from going insane trying to remember which return code we meant when returning a two.
Now notice what the return type of our bufferWrite function is: a BufferStatus enum. This reminds us that whenever we call that function, we should expect the same enum — the same mapping from the underlying numbers to their text symbols. Unfortunately, GCC doesn’t typecheck enum values for us, so you’re on your honor here to do the right thing. (Other compilers will throw a warning.)
Reading
The bufferRead function just about as straightforward. First we check if the newest_index is the same as the oldest_index, which signals that we don’t have any data in the buffer. If we do have data, we
enum BufferStatus bufferRead(uint8_t *byte){
if (buffer.newest_index == buffer.oldest_index){
return BUFFER_EMPTY;
}
*byte = buffer.data[buffer.oldest_index];
buffer.oldest_index = (buffer.oldest_index+1) % BUFFER_SIZE;
return BUFFER_OK;
}
This brings up an important C programming idiom. We want to get two things back from our bufferRead function: the oldest byte from the buffer and a return code to go along with it. For reasons lost to time, probably having something to do with efficient programming on prehistoric PDP-8s or something, a C function can only really return a single value. If your function wants to return multiple values (as we do here), you’ve got to get crafty.
We haven’t really dug into pointers in Embed with Elliot, but here’s another standard use case. (For the first, see our post on pointer-based State Machines) The bufferRead function returns a status code. So where does it store the data it read out of the buffer? Wherever we tell it to!
A pointer can be thought of as a memory address with a type attached to it. When we pass the pointer uint8_t *byte to our function, we’re passing the memory address where we’d like the function to store our new data. Our main program declares a variable, and then when we call the bufferRead function, we pass it the address of that variable, and the function then stores the new data into the memory address that corresponds to the variable in main.
enum BufferStatus status; uint8_t byte_from_buffer; status = bufferRead(&byte_from_buffer); /* and now byte_from_buffer is modified */
The only potentially new thing here is the “address-of” operator, &. So we call bufferRead with the location in memory that our main routine is calling byte_from_buffer, for instance, and the function writes the new byte into that memory location. Back in the calling function, we get our two variables: the status value that’s passed explicitly, and the byte_from_buffer that’s written directly into memory from inside the bufferRead function.
And that’s about it. To recap: we used a struct to combine the array and its two indices into one “variable”, mostly for convenience. Then we defined an enum to handle the three possible return conditions from the reader and writer functions and make the return values readable. And finally, we wrote some simple reader and writer functions that stored or fetched data from the buffer, one byte at a time, updating the relevant index variable as necessary.
Refinements and Generalizations
As it stands right now, we’re storing the buffer as a global variable so that it can be accessed by our main routine and the read and write routines. As a result we can’t re-use our code on more than one buffer at a time, which is silly. For instance, if we were using the buffers for USART serial communication, we’d probably want a transmit and receive buffer. And once you get used to buffers, you’ll want them between any of your asynchronous code pieces. So we’ll need to generalize our functions a little bit so that we can define multiple buffers that will work with our reader and writer functions..
Fortunately, it’s easy. Two simple changes will allow us to re-use our bufferRead and bufferWrite functions on an arbitrary number of different buffers.
enum BufferStatus bufferWrite(volatile struct Buffer *buffer, uint8_t byte){
uint8_t next_index = (((buffer->newest_index)+1) % BUFFER_SIZE);
if (next_index == buffer->oldest_index){
return BUFFER_FULL;
}
buffer->data[buffer->newest_index] = byte;
buffer->newest_index = next_index;
return BUFFER_OK;
}
enum BufferStatus bufferRead(volatile struct Buffer *buffer, uint8_t *byte){
if (buffer->newest_index == buffer->oldest_index){
return BUFFER_EMPTY;
}
*byte = buffer->data[buffer->oldest_index];
buffer->oldest_index = ((buffer->oldest_index+1) % BUFFER_SIZE);
return BUFFER_OK;
}
In both instances, instead of relying on a buffer variable defined in the global namespace, we’re passing it to the function as an argument. Or, more accurately, we’re passing a pointer to a Buffer structure to the function. We declare the buffer volatile because we want to update the buffers using interrupt routines later. (See our article on volatile if you need a refresher.)
The other change is how we refer to the buffer struct‘s elements. The problem is that we don’t pass the struct itself, but a pointer to that struct. So what we need is to get (“dereference”) that struct first, and then access the data element within it. The cumbersome way to to that goes like this: (*buffer).data, but since this pattern occurs so often in C, a shortcut notation was developed: buffer->data.
Receiving
Those two changes aside, the logic of the read and write code is exactly the same. So how do we use these functions? Glad you asked. Let’s take the example of setting up receive and transmit buffers for an AVR microcontroller to shuttle data in and out using its built-in hardware USART and interrupt routines. Once you’ve got a good circular buffer at hand, handling incoming serial data becomes child’s play.
volatile struct Buffer rx_buffer = {{}, 0, 0};
ISR(USART_RX_vect){
bufferWrite(&rx_buffer, UDR0);
}
int main(void){
uint8_t received_byte;
enum BufferStatus status;
initUSART();
initUSART_interrupts();
while (1) {
status = bufferRead(&rx_buffer, &received_byte);
if (status == BUFFER_OK) { /* we have data */
do_something(received_byte);
}
}
}
This isn’t a full-fledged example, but it hits the main elements. The code defines an interrupt service routine (ISR) that simply stashes the received byte into the circular buffer when anything comes in over the serial line. Note that the bufferWrite function is pretty short, so we’re not going to spend too much time in the ISR, which is what we want. The combination of the interrupt and the chip’s hardware serial peripheral take care of filling up the buffer for us. All that’s left to do in main() is try to read some data from the buffer, and check the return code to see if we got something new or not.
Because the buffer is shared between the main() routine and the ISR, it needs to be defined outside of either function, in the global namespace. Note that since we write to one end of the buffer, and read from the other, there’s not as much need to worry about race conditions and atomicity here. As long as the ISR is the only routine that’s writing to our buffer, and we only read from the buffer in main(), there’s no chance of conflict.
That said, if you want to be doubly sure that your shared volatile variable isn’t getting accessed twice at the same time, or if you’re writing a more general-purpose circular buffer routine, it wouldn’t hurt to wrap up the sections with access to shared variables in an ATOMIC_BLOCK macro.
Transmitting
Finally, setting up a transmit buffer is a little bit more complicated on the AVR platform, because we’ll need to enable and disable the USART’s data-ready interrupt when the transmit buffer has data or is empty, respectively. Defining a couple convenience functions and checking for the buffer status in the interrupt routine take care of that easily:
static inline void enable_transmission(void){
UCSR0B |= (1<<UDRIE0);
}
static inline void disable_transmission(void){
UCSR0B &= ~(1<<UDRIE0);
}
ISR(USART_UDRE_vect){
uint8_t tempy;
enum BufferStatus status_tx;
status_tx = bufferRead(&tx_buffer, &tempy);
if (status_tx == BUFFER_EMPTY){
disable_transmission();
} else {
UDR0 = tempy; /* write it out to the hardware serial */
}
}
The UDRE interrupt fires every time the USART data register is empty (“DRE”) so that the ISR pulls a new character off the transmit buffer as soon as it’s able to handle it. Your calling code only needs to pack all the data into the transmit buffer and enable the interrupt one time, without having to wait around for the actual transmission to take place, which takes a long time relative to the fast CPU speed. This is, not coincidentally, a lot like what the Arduino’s “Serial” library functions do for you.
Peeking Inside the Buffer
Finally, there’s one very common use case that we haven’t addressed yet. It’s often the case that you’d like your code to assemble data out of multiple bytes. Maybe each byte is a letter, and you’d like your code to process words. On the reading side, you’d like to stack up data in the buffer until a space character arrives. For this, it’s very convenient to have a function that looks at the most recently added character, but doesn’t change either of the index variables.
We’ll call this function bufferPeek() and it’ll work like so:
enum BufferStatus bufferPeek(volatile struct Buffer *buffer, uint8_t *byte){
uint8_t last_index = ((BUFFER_SIZE + (buffer->newest_index) - 1) % BUFFER_SIZE);
if (buffer->newest_index == buffer->oldest_index){
return BUFFER_EMPTY;
}
*byte = buffer->data[last_index];
return BUFFER_OK;
}
The code should be, by now, basically self-explanatory except for the one trick in defining the last_index. When the buffer has just wrapped around, newest_index can be equal to zero. Subtracting one from that (to go back to the last written character) will end up with a negative number in that case. Adding another full BUFFER_SIZE to the index prevents the value from ever going negative, and the extra factor of BUFFER_SIZE gets knocked out by the modulo operation anyway.
Once we’ve got this “peek” function, assembling characters into words is a snap. For instance, this code snippet will wait for a space in the incoming data buffer, and then queue up the word as quickly as possible into the output buffer, turning on the transmit interrupt when it’s done.
// Check if the last character typed was a space
status = bufferPeek(&rx_buffer, &input_byte);
if (status == BUFFER_OK && input_byte == ' '){
while(1) {
status = bufferRead(&rx_buffer, &input_byte);
if (status == BUFFER_OK){
bufferWrite(&tx_buffer, input_byte);
} else {
break;
}
}
enable_transmission();
}
Code and Conclusions
All of this demo code (and more!) is available in a GitHub repository for your perusal and tweaking. It’ll work as written on any AVR platform, but the only bits that are specific are the mechanics of handling the interrupts and my serial input/output library. The core of the circular buffer code should work on anything that you can compile C for.
There are all sorts of ways to improve on the buffer presented here. There are also many possible implementations of circular buffers. This article is far too long, and it could easily be three times longer!
But don’t get too bogged down in the details. Circular buffers are an all-purpose tool for dealing with this common problem of asynchronous data creation and consumption, and can really help to decouple different parts of a complex program. Implementing buffers isn’t black magic either, and I hope that this article has whetted your appetite. Go out and look through a couple more implementations, find one you like, and then keep those files tucked away for when you need it. You’ll be glad you did.
If you’ve got favorite bits of buffer code, or horror stories from the trenches, feel free to post up in the comments. We’d love to hear about it.














Having dabbled with FIFO’s and circular buffers, a couple of notes come to mind:
Use buffer sizes which are a power of two (2n). This allows you to not use division [/%] which can consume precious cpu cycles, especially in embedded applications, but rather ANDing [&] with the buffer size minus one to get the index.
Use
unsignedtypes for the read/write/in/out/rx/tx/oldest_index/newest_index pointers, and have at least one one bit to spare above the buffer size.Subtracting the
oldest_indexfromnewest_index[to_go = newest_index - oldest_index] gives you the number of elements in the FIFO/circular buffer.Subtracting
to_gofrom the buffer size [can_go = buffer_size - (newest_index - oldest_index)] gives you the number of elements in the FIFO/circular buffer.In the previous two tricks, you need to assign the result to a temporary variable and not put it in a conditional expression, as when the oldest/newest pointers wrap around, you can have architecture flags set/cleared which muck up the results of the expression.
can_goandto_gocan’t be greater than the buffer size. If either are, it is an indication that the structure has been corrupted.The usual caveats with regard to concurrency and race conditions apply. Generally, writes should only increment the newest_index, while reads should only increment the oldest_index, peeks should leave them untouched.
Reading/writing arbitrary lengths can complicate things a bit, but the general rule is that you can’t read/write more than what’s available.
Power two as in 2 to the power of n, nothing else. *notes SUP/SUB tags are not allowed*
Even with power of two you can use %. Every modern compiler will optimize that to the best operation. The code will then still be generic for non power of two buffers.
Yes, but as Teukka said, the division that can result in the general case might be quite expensive (in terms of clks) eg on limited 8-bit architectures with no HW div.
If this level of optimization is important for your app, you could consider some pre-processor macro magic, so the % is only used with power-of-two buffers (i.e. becomes fast, single op AND in practice) and in other cases replaced with something like “if (index >= BUF_SIZE) index -= BUF_SIZE;”
That would give you fast and optimized ANDs with pow(2) buffers, but still allow generic buffers with just a slight penalty.
Of course, if you’ve already joined the 21st century CortexM or other 32-bit world; chances are great that your micro in fact has fast, single-cycle HW integer division. And then yes, just use the simple % for any buffer sizes.
No need to write a macro — that’s exactly what using modulo does on a reasonable compiler! (At least AVR-GCC) uses the bit-masking trick when the buffer is power-of-two, and resorts to division when it’s any other length.
Using modulo is already optimal / optimized. And painless to boot. Thanks, compiler!
We discovered that % was (relatively) very costly in CPU cycles, just because it only takes one character to type doesn’t mean it’s efficient code. In our case, doing something like while(a > mod) a-=mod was way faster.
It really depends a lot on what you’re doing.
For example, a%b, where a and b are both variables is not easy to optimize.
a%b where either a or b is fixed is much easier. Any decent compiler that sees a % SOMECONSTANT will replace % SOMECONSTANT with a bit mask if SOMECONSTANT is a power of two. Otherwise, it will use the divide operator or whatever operator it determines to be most efficient.
“Subtracting the oldest_index from newest_index [to_go = newest_index – oldest_index] gives you the number of elements in the FIFO/circular buffer.”
No, you need modulo the buffer size here. It’s a circular buffer, the pointers wrap around: if BUFFER_SIZE is 16, then when ‘oldest_index’ hits 15, ‘newest_index’ will be 0 when there’s 1 entry in the buffer, and obviously 0-15 isn’t 1.
“Subtracting to_go from the buffer size [can_go = buffer_size – (newest_index – oldest_index)] gives you the number of elements in the FIFO/circular buffer.”
You can also do ((oldest_index – newest_index)-1) % BUFFER_SIZE. Math works out the same (yay two’s complement) and can be cheaper on certain platforms.
Also I would find the names “write_ptr” (or index) and “read_ptr” much clearer than “newest_index” and “oldest_index”, but maybe that’s just me.
Ah, but that’s the beauty of it, you don’t reset the read_ptr/write_ptr, you let them keep on ticking. Using unsigned and the bit size of the word takes care of the rest. Modulo Buf_size has its place, when you get the actual index into the buffer, and if you use power-of-2 buffer size, you can simplify that to anding with bufsize-1.
Basically, if you have two values on either side of a wraparound of a binary word, you still get the same difference. E.g. you have wrapped around new_index and it’s 2, but old_index is still, say 252. 2-252 is -250 in signed 32-bit maths, but for an
uint8_t(unsigned 8-bit (byte)) it’s 6.You have an implicit MOD 256 because of the word size. Try it out.
There are two catches tho.
You MUST use an
unsignedinteger type, and you need assign the result to a temporary variable so that the carry/borrow is ignored when you do the expression for the conditional:to_go = newest_index - oldest_index ; /* Can't merge with the below like: if ((to_go = newest_index - ....) */if ( to_go > buffer_size )
return ENOPE ;
else
nBytes = min(n, to_go) ; /* Can at most read the # of elements in buffer */
/* Do actual read data movement here */
And the code is remarkably similar for writes, just substitute to_go with can_go and use
buffer_size - (newest_index - oldest_index).And yeah, I use rdptr and wrptr, I’ve seen in and out in the linux kernel code for kernel fifos.
http://lxr.free-electrons.com/source/kernel/kfifo.c?v=2.6.32
And they seem to be using this:
len = min(len, fifo->size - fifo->in + fifo->out);rather than subtraction all the way thru;I like it! But, I feel like it will confuse people who aren’t in-the-know when they read the code. ie. Myself.
Re: zerocommazero:
> I like it! But, I feel like it will confuse people who aren’t in-the-know when they read the code. ie. Myself.
I banged my head against the wall myself coming up with a quick and simple FIFO / circular buffer set of functions for my little OS, until I found an early version of this method in the linux kernel. And it confused me about as much as it did you at first. So lessons to take home for OS and embedded coders and amateurs alike:
o Study how kernels do it, e.g. the Linux kernel at http://lxr.free-electrons.com/
Kernel coders often work with CPU cycle and other resource consumption restraints.
o Learn the arcane art of “unrolling loops”, the limitations of each data type and how you can make those limitations work for you.
o Learn assembly, if not fluently, at least basically so you can follow what a piece of assembly code does.
o Study what assembly code your C/C++ compiler of choice produces for a given set of HLL code (gcc has the -S option to force it to produce assembly).
o Don’t shy away from doing one step of coding in a HLL, then tweaking the resulting assembly code to perfection.
o For timing-critical applications or when you run into running out of CPU cycles to use, begin the habit of having an 8-charcter wide column in your comments – before the real comments -for clock cycles, and specifying clock cycles in the function header comment. For the AVR, the AVR 8-bit instruction set reference can be found here: http://www.atmel.com/images/atmel-0856-avr-instruction-set-manual.pdf
Anyone have more lessons to share?
That assumption bit me in the tail in my current compiler (IAR Embedded Workbench 7.20 for ARM).
I assumed that 255+1 = 0 for an unsigned int8, but in an if statement (and only in an in if statement), the code didn’t work so I still had to use modulo even if technically the int8 could not have a bigger value than 255.
For example:
if (rxBuffer[(rxBufProcPntr+1)%256]==’O’ && rxBuffer[(rxBufProcPntr+2)%256]==’K’ )
Yeah, I missed the fact that you were doing modulo on the assignment/read, not on the indices.
The problem with this is that it saves you a quick instruction on operations that occur infrequently (when getting number of total bytes), at the cost of forcing you to do an extra operation in a time-critical place (the ISR, before reading/writing the actual hardware register).
Then again, if you’ve got the RAM, if the buffer size is 256 the two solutions are identical anyway (which is actually what I do for serial transmit buffers).
It’s probably worth pointing out that there are then 3 ways I can think of to set up the buffer nicely:
1) Use large index variables and modulo on each access (like you suggest).
2) Use index variables and modulo on each increment
3) Directly use uint8_t *rd_ptr, uint8_t *wr_ptr, align the buffer to a higher power of 2 (e.g. for a buffer size of 16, align to 32), then AND the pointer with (~BUFFER_SIZE) after increment.
Each of those has advantages and disadvantages, depending on the platform and the use case.
can_go = buffer_size - (newest_index - oldest_index) ;Gives you the number of elements which can fit into the buffer.
Darn. Not my day today :(
These articles aren’t light reading for me, but I sure do get a lot out of them. Reading Hackaday when one of these comes up is like:
click
click
click
(Embed with Elliot)……………………………………………
.
.
.
.
(a half an hour later)
click
click
click
“Note that since we write to one end of the buffer, and read from the other, there’s not as much need to worry about race conditions and atomicity here.”
Every time I hear that, my immediate thought is “that means you’ve probably got a race condition you haven’t seen yet.”
And you do. :)
bufferPeek is the culprit. You’re using newest_index twice. Consider the buffer being empty when last_index is calculated. So if oldest_index = 0, and newest_index = 0, last_index ends up being 15.
Now the data comes in immediately after that calculation. So newest_index is now 1. It passes that check, and continues on… and returns data[15], which is nonsense. Oops!
The solution is to grab a local copy of newest_index right away, and do the math on *that*.
e.g.
enum BufferStatus bufferPeek(volatile struct Buffer *buffer, uint8_t *byte){
uint8_t newest_index = buffer->newest_index;
if (newest_index == buffer->oldest_index){
return BUFFER_EMPTY;
}
*byte = buffer->data[(BUFFER_SIZE+newest_index-1) % BUFFER_SIZE];
return BUFFER_OK;
}
I should also point out that you could also just not create the ‘newest_index’ temp – that’d work as well, because after the check, there’s guaranteed to be at least 1 byte in the buffer. If an interrupt comes in, you’ll get 2, and grab the second.
However, that requires you to grab the volatile newest_index twice. Just using a temporary means the compiler will just use the copy it already has.
Damnit!
My original code (what I actually use in my own projects) wraps the functions in an ATOMIC_BLOCK statement, which should beat the race condition down. (I hate it when I say things like “should” in this context too.)
I removed it so that it would compile/run on Arduino, which for some reason doesn’t use the -C99 flags to compile with, even though they could, and ATOMIC_BLOCK uses some tricks from C99.
Your solution is even better. Thanks!
I really, really dislike wrapping ATOMIC_BLOCK stuff just to be safe, because it’s so expensive in terms of potential latency, but obviously if you’ve got the cycles/power to spare, it saves a lot of headaches.
But this is related to the ‘volatile’ keyword article you had: a useful way of dealing with volatiles in a function is to always grab them into a local temporary, and use that local temporary only. If you only use it one time, the compiler will optimize away the temporary, and if you use it more than once, it won’t refetch it and you won’t have race issues.
(Obviously if you want to refetch it – like you’re polling – then you fetch it directly.)
Fair enough. And here the local temp copy (as long as you’ve got fewer than 256 elements in your array) is foolproof as well.
If you need a 16-bit int to refer to the array, the ATOMIC_BLOCK is your only hope. Or, if you know for sure that global interrupts will be enabled otherwise, just wrap in a cli()/sei() pair. Or, if you know which specific interrupt you’re afraid of (as with the USART example) you can just knock that one out specifically for the duration as well.
But again, like you said: where the local copy method works, it’s probably optimal.
Oh, absolutely. And of course, a lot of people don’t understand that what look like atomic operations in C aren’t in any way atomic, or they might be atomic on one architecture, but absolutely not on another. So ATOMIC_BLOCKs are really pretty handy for someone just getting started.
A long, long time ago, I worked with a processor (ADSP2105, ancestor of the Blackfin) which has circular buffering built into the CPU’s I/O engine. The I/O engine would also generate an interrupt if incrementing the index caused a wrap, which was very nice. So the serial I/O engine could jam data into the circular buffer, and when it incremented it past the wrap point, we’d get an interrupt telling us to service the buffer.
The only problem was that when that interrupt went off, you had to service the buffer before another I/O sample arrived, or it would overwrite the beginning of the buffer.
I realized that if I set the I/O to increment by 2 instead of by one, and if I set the buffer length to an odd number, then the first time through the buffer it would use the even indices. Then it would wrap (generating the interrupt) and use the odds. I set the buffer length to 25 (because that is a nice odd number). The first time through I would service the 13 even samples, and the next time I’d service the 12 odds. That gave me a minimum of 12 sample periods to get around to servicing the data before it was at risk (and could have had more time than that by making the buffer bigger, but still odd).
sounds a lot like a ping pong buffer
The most hardcore implementation of uart circular buffer, what I have made for my lib.
“`
ISR(RX0_INTERRUPT, ISR_NAKED)
{
asm volatile(“\n\t” /* 5 ISR entry */
#ifndef USART_UNSAFE_24_CYLCE_INTERRUPT
“push r0 \n\t” /* 2 */
“in r0, __SREG__ \n\t” /* 1 */
#endif
“push r31 \n\t” /* 2 */
“push r30 \n\t” /* 2 */
“push r25 \n\t” /* 2 */
“push r24 \n\t” /* 2 */
“push r18 \n\t” /* 2 */
#ifdef USART_UNSAFE_24_CYLCE_INTERRUPT
“in r18, __SREG__ \n\t” /* 1 */
“push r18 \n\t” /* 2 */
#endif
/* read byte from UDR register */
“lds r25, %M[uart_data] \n\t” /* 2 */
/* load globals */
“lds r24, (rx0_last_byte) \n\t” /* 2 */
“lds r18, (rx0_first_byte) \n\t” /* 2 */
/* tmp_rx_last_byte = (rx0_last_byte + 1) & RX0_BUFFER_MASK */
“subi r24, 0xFF \n\t” /* 1 */
“andi r24, %M[mask] \n\t” /* 1 */
/* if(rx0_first_byte != tmp_rx_last_byte) */
“cp r18, r24 \n\t” /* 1 */
“breq .+14 \n\t” /* 1/2 */
/* rx0_buffer[tmp_rx_last_byte] = tmp */
“mov r30, r24 \n\t” /* 1 */
“ldi r31, 0x00 \n\t” /* 1 */
“subi r30, lo8(-(rx0_buffer))\n\t” /* 1 */
“sbci r31, hi8(-(rx0_buffer))\n\t” /* 1 */
“st Z, r25 \n\t” /* 2 */
/* rx0_last_byte = tmp_rx_last_byte */
“sts (rx0_last_byte), r24 \n\t” /* 2 */
#ifdef USART_UNSAFE_24_CYLCE_INTERRUPT
“pop r18 \n\t” /* 2 */
“out __SREG__ , r18 \n\t” /* 1 */
#endif
“pop r18 \n\t” /* 2 */
“pop r24 \n\t” /* 2 */
“pop r25 \n\t” /* 2 */
“pop r30 \n\t” /* 2 */
“pop r31 \n\t” /* 2 */
#ifndef USART_UNSAFE_24_CYLCE_INTERRUPT
“out __SREG__ , r0 \n\t” /* 1 */
“pop r0 \n\t” /* 2 */
#endif
“reti \n\t” /* 5 ISR return */
: /* output operands */
: /* input operands */
[uart_data] “M” (_SFR_MEM_ADDR(UDR0_REGISTER)),
[mask] “M” (RX0_BUFFER_MASK)
/* no clobbers */
);
}
“`
Something like this is still generating bigger code (and taking more cycles)
“`
ISR(USART_RX_vect){
bufferWrite(&rx_buffer, UDR0);
}
“`
guess why
Well, it’s quite difficult to write a “naked” ISR that’s *not* more efficient than the default shotgun prologue and epilogue.
We use these circular buffers quite a lot in our codes. We call it ringbuffer. IMHO one of the best usage, is for debugging the running system over serial line. We have our own real time operating system, we use a lot of tasks, and we wanted to see whats going on inside the tasks in real time (not just real time, but with as little execution overhead as possible), so the solution is debug ringbuffers, one for every task, and one for the debug task. When a task wants to print out a debug string, than writes in it’s own debug ringbuffer, and writes into the debug task ringbuffer a debug item (id, timestamp, length). The debug task wakes up periodically and checks for debug items, and sends the formatted debug string to the debug output (serial port). Only the debug task waits for the serial port, the normal tasks can run without blocking. It is possible to make dump debug string from interrupt servers.
This is a sample output (115kbaud serial output) of this debug system, the first 4 hexa digit is the integer part of the time stamp the next 2 is the fractional part. The timestamps are in ms. It is a cortexM3 MCU.
[ DBG 0038:CD*] GPIO conf hal 0008000c port 0 pin 3
[ DBG 0038:DE*] GPIO conf hal 0008000d port 0 pin 2
[ DBG 0038:FE*] conf irq a0003
[ DBG 0039:08*] rx buffer memory at 0x20006400 size 512
[ DBG 0039:16*] tx buffer memory at 0x20006600 size 512
[ DBG 0039:23*] rx_rb 20007624 tx_rb 20007644
[ DBG 0039:36*] CFW init reached
[ HWC 0039:4F*] configure 140001 eeprom
[ HWC 0039:59*] phase1 4 phase2 6 phase3 2
[ HWC 0039:68*] act freq 375000 freq 375000 src 96000000 div 256 40602
[ HWC 0039:8A*] GPIO conf hal 00080005 port 0 pin 4
[ HWC 0039:9B*] GPIO conf hal 00080007 port 0 pin 8
[ HWC 0039:AC*] GPIO conf hal 00080006 port 1 pin 5
If you replace the newest_index/oldest_index with counts of total bytes written/read instead, then the code becomes a lot simpler. You only need (count % BUFFER_SIZE) to calculate the appropriate index, and you don’t have the weird edge cases to worry about. Just make sure that your buffer size is a power of 2 so there’s no discontinuity when the count variables overflow.
you don’t need modulo at all, or power of 2 size buffer !!!
Uh, yes you absolutely do. Otherwise you’ll try to access memory past the end of the buffer. C doesn’t care if you try that, it’ll either corrupt the memory outside the buffer area, or it’ll segfault.
And the only other way to avoid the modulo operation is to do it manually with an if statement, which seems to be what you’re doing in your other comments. It’s far messier doing it that way, and there’s absolutely no benefit to it.
Additionally, buffers are usually of fairly arbitrary length. So there’s no reason to avoid going to a power of two, which also makes it more likely you’ll hit an alignment boundary – having a non-power-of-two buffer that the compiler pads out to a power of two *anyway*, wasting the extra, is just silly.
Nice article, there is just one thing i do not agree with, due to the possible waste of memory:
‘The easiest way, in my opinion, to deal with this is just to leave one slot empty at all times.’
There is a better and easier way to do this, simply having a counter that show the number of items in the circular buffer.
By using a counter you make sure you can fill the circular buffer 100%, and not always having at least one empty place, like with your solution.
If you just have a buffer storing integers, it does not make any difference. But often you store more complex objects in the buffer and then the waste of memory is a lot bigger.
Let’s say you have a circular buffer with 16 places, each item in the buffer is a package of data of the size 1k.
With my solution the total buffer would take up 16kB + 2 byte for the counter. (16 bit integer)
Your solution would only take op the 16 kB, but due to having to have an empty place in order to figure out if the buffer is full or empty, you waster 1kB of memory.
Personally i would much rather waste space for 1 integer, instead of 1kB.
When studying computer science, I had this discussion many times with my teacher who prefered your solution.
The funny part was at one of the exam’s the subject i got was …… Circular buffers.
And the external examining teacher, had to tell my teacher my solution actually was the most memory efficient :-)
You were right in your computer science exam.
I also really like the “first entry” + “total length” method, but the code needs to call a lot more modulos. Which is no big deal if the buffer is a power of two length, but will really screw you in terms of CPU usage otherwise. It’s funny how optimizing something as simple as a circular buffer can get really implementation-dependent really fast.
It’s a wash here, like you say, so I went with simple. In general, if your buffer is full of (type A) and you need a (type B) to count them, you’ll win with this architecture if sizeof(type A) < sizeof(type B). You'd be right to use the method presented here if you had a 512-element buffer of 8-bit unsigned integers.
You don’t need modulo at all, simply you have to count the number of push and pop and have the size of the buffer
so the push is like this:
res = RINGBUFFER_OK;
if ( (rb->push_cnt – rb->pop_cnt) != rb->capacity )
{
next = rb->write_ndx;
RB_STORE_ELEMENT( rb, next, arg );
if ( (++next) >= rb->capacity )
{
next = 0;
}
rb->write_ndx = next;
rb->push_cnt++;
}
else
{
res = RINGBUFFER_FULL;
}
return res;
One thing that’s really nice about the newest/oldest pointers version, though, is that the read function only has to know/modify the oldest index, and the write function the newest — they’re already essentially thread-safe.
I’ve also used oldest + length methods, but using the length (or push_cnt – pop_cnt) mixes the read/write variables and functions together in a way that invites race conditions. You can do it if you’re careful, or only using a single UART, or etc.. But you’ll have to think about it.
This solution with the push/pop count is also as thread safe as your code (your code definitely not fully thread safe, in case if you are calling the push from 2 different threads at the same time). The push code only writes the push count and the write index, the pop code only writes the pop count and the read index. The decision about the number of items in the buffer is only made with the push/pop counters, the write/read index is just internal for the push/pop, the pop function never touch (does not read or write) the write index and push function never touch the read index. So this solution is nearly identical to the newest/oldest, just does not need any modulo, and the size of the buffer can any number (regarding the number limit of the cpu). The “modulo” calculating is made with the write/read index comparing against the capacity. The push/pop counter can, and will roll over, but the 2’s complement subtraction will make it perfect.
Just to be clear this is how the pop function works:
res = RINGBUFFER_OK;
if ( rb->push_cnt != rb->pop_cnt )
{
ndx = rb->read_ndx;
RB_LOAD_ELEMENT( rb, ndx, arg );
if ( (++ndx) >= rb->capacity )
{
ndx = 0;
}
rb->read_ndx = ndx;
rb->pop_cnt++;
}
else
{
res = RINGBUFFER_EMPTY;
}
return res;
I don’t get the point. What’s the point of having a write index *and* a push/pop count? They’re completely identical, and it takes twice the operations to handle it since you need to increment both.
Modulo operators are extremely cheap for a power of 2, and if it’s not a power of 2, it’s easy to special-case both the size calculation and the rollover.
No they don’t have to be identical. That’s the point, you can have any number of capacity, and still don’t need any modulo at all. The push/pop count is for detecting the free space or the items in the buffer, the “modulo” is made with the write index, capacity compare.
My first ‘snake’ game was just a circular buffer.
What’s wrong with this way. Integer tests are cheap.
enum BufferStatus bufferWrite(volatile struct Buffer *buffer, uint8_t byte){
uint8_t next_index;
if(buffer->newest_index == BUFFER_SIZE)next_index = 0;
else
next_index = buffer->newest_index+1;
if (next_index == buffer->oldest_index){
return BUFFER_FULL;
}
buffer->data[buffer->newest_index] = byte;
buffer->newest_index = next_index;
return BUFFER_OK;
}
For a non-power of 2 buffer, that’s the best way. But it’s much more complicated for a power-of-2 buffer. You have:
compare
jump if equal
increment
jump past
set to zero
versus
increment
and/bit clear
In an MSP430, for instance, that’s something like 7 or 5 cycles versus 2 (so you also lose the definite timing).
yes I see what you mean. But for general code that can handle any BUFFER_SIZE I like my solution better than a modulo. I know its not pretty code but that’s how i roll.
I would just come up with a macro that autodetects whether it’s a power of 2, use modulo in that case, and use the if/else construct in the other case.
Test it out before you write that macro! I betcha your compiler does the already for you. (AVR-GCC does.)
Try it. If your buffer size is a power of 2, the modulo operator will just be a bit mask, which is simpler and produces more efficient code than your if statement ( which requires a branch, as written)
You don’t need modulo at all, simply you have to count the number of push and pop and have the size of the buffer. I wrote an example push code above
i’ve read it’s not advised to put local variable as you do in interrupts routine and it’s also not advised to call routine from interrupt too .
At least on microchips 8 bits devices ( XC8 documentation )
can somebody give me an answer ?
If you’re looking to save on expensive MCU RAM and you need a buffer for multiple subsystems, consider using a linked ring buffer (https://github.com/fefa4ka/linked_ring).
This data structure allows you to allocate a single buffer for multiple consumers, maximizing efficiency and minimizing memory consumption.
Linked rings are like a circular party – everyone’s connected and having a good time, but you can still leave whenever you want (just don’t forget to update your ‘next’ pointer on the way out).