
Fingerprinting text is really very nifty; the ability to encode hidden data within a string of characters opens up a large number of opportunities. For example, someone within your team is leaking confidential information but you don’t know who. Simply send each team member some classified text with their name encoded in it. Wait for it to be leaked, then extract the name from the text — the classic canary trap.
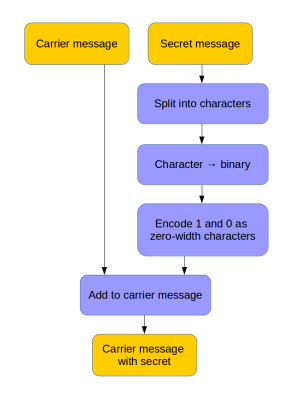
Here’s a method that hides data in text using zero-width characters. Unlike various other ways of text fingerprinting, zero width characters are not removed if the formatting is stripped, making them nearly impossible to get rid of without re-typing the text or using a special tool. In fact you’ll have a hard time detecting them at all – even terminals and code editors won’t display them.
To make the process easy to perform, [Vedhavyas] created a command line utility to embed and extract a payload using any text. Each letter in the secret message is converted to binary, then encoded in zero-width characters. A zero-width-non-joiner character is used for 0, and a zero-width-space character for 1.
[Vedhavyas’] tool was inspired by a post by [Tom], who uses a javascript example (with online demo) to explain what’s going on. This lets you test out the claim that you can paste the text without losing the hidden data. Try pasting it into a text editor. We were able to copy it again from there and retrieve the data, but it didn’t survive being saved and cat’d to the command line.
Of course, to get your encoding game really tight, you should be looking at getting yourself an enigma wristwatch…














“making them nearly impossible to get rid of without re-typing the text or using a special tool.” — Copypaste to Notepad++, change encoding to ANSI instead of Unicode. BOOM, gone.
I was just going to say that anything old enough to not understand UTF-8 is going to display junk characters in place of the special symbols.
oh… and how long before this is used in some way by malware…. *sigh*
Already been in use for a good while, including in tricking people into going to malicious URLs and stuff. Nothing new.
On one forum that doesn’t exist anymore it was impossible to have to have two consecutive sequences for making separated paragraphs. Inserting space or tab character didn’t work, as these were stripped by the posting script too. However there is an invisible space-like character that can be created with [ALT]+0160. It looks like this: …
Character 160 was common to get spaces in filenames in the 1980s…
Alt+255 always used to be good for those tasks
In ISO-8859-1 and also the standard windows code page (1252?), character 0xA0 (160) is the non-breaking space. In CP437 (US DOS), character 0xFF (255) is often now interpreted as the non-breaking space
(In Unicode, 0xA0 is still the non-breaking space, but it has a multibyte encoding)
Libre Office writer shows shadows and the spell checker doesn’t like it either.
Past it in wordpad and you’ll see a bunch of extra spaces.
this gives “reading between the lines” a whole new meaning!
Cool. HaD posters can send secret messages to each other.
Ostracus – I wish… Another HaD’er and I have tried but WordPress defeats us every time. We tried the HTML color-tag word masking gambit but the post remains with its CSS colors, thereby defeating our attempts to cloak HaD secret messages.You could just open CHARMAP.EXE on your PC and paste something like this: ♣♥♪♫▼█ – btw that 6-character string is TOTALLY unbreakable and is not an OTP. Got the idea from Penn & Teller. Tougher than Kryptos, and the Puzzle Palace will be scratching their heads for about 5-seconds. :-)
“zero width characters are not removed” not necessarily in theory you could write a script that uses a table of characters you want to find and transfer
take the word “Ænima” from the “https://www.youtube.com/watch?v=QSvtGQUqldA” for example “Æ” is 1 character it is actually ae.
do a normal search (command f on mac or control f on windows for ae the character Æ will get selected.
ok apply the following logic
repeat with some variable to the number of characters of the document
if character variable is within a-z and 0-9 and space then type that character into a new document.
otherwise leave that characters blank
Ligatures and logograms abound. Though depending on what language you’re using, aesc and eszett may be considered their own letters. The ampersand is another common one.
These aren’t really the same concept though since they’re meant to combine letters, rather than hide them, to save character counts on a printing press or telegrams where you would pay by the character. They also arise from common handwriting styles or frequent combinations in different languages like vowel+e vowel+o being melded into the umlaut and ring respectively..
Leithoa – Here’s one for you to decode my friend: ꞵꭎꞎꞇꞕꞓꞧ
(friend is sincere, not rhetorical) :P
Sorry, HaD inside joke!
Hidden characters played a role in a software copyright case back in the 90s. I was an expert witness (in C) for this federal case.
The Kid wrote some software for the Plaintiff (P). Then went on to write similar software for the Defendant (D). There was one obvious but trivial copy of the main icon in the GUI. P asked that it be changed and was refused. P sued.
I worked for P with 2 other developers, notably Dr. P. J. “Bill” Plauger, who wrote the first non-Bell Labs C compiler. P managed to get the code from the Kid. I demonstrated and testified that 6 utility routines were exact copies except for minor name changes.
Bill used Unix command line tools to compare every line in P’s source code with the ‘new’ source code from the Kid. Duplicate lines were found throughout the code which showed reuse and copyright violation. What really jumped out in the comparison were the hidden characters, specifically tabs characters.
If you’re old enough you should remember that tabs were often set to 4 characters in editors. When that was printed, a tab got expanded to 8 characters by the printer. Nicely formatted code came out skewed. Especially interesting were lines where a tab began the line but after editing the tab was in the middle of the line but didn’t disturb the formatting in the editor. When printed it really screwed up the formatting.
We could visually see this in the printouts and knew what was happening but couldn’t prove it using them. Bill showed it with his line by line comparison. The Kid claimed a great memory and that he’d recreated the code, not copied it. But couldn’t answer how he recreated it with tab characters in exactly the same place.
I led off testifying. The next day D talked about settlement but didn’t fold until P’s lawyers slammed Bill’s work on the table basically saying, “Wait! There’s more!”. The settled.
Bill was going to do more research on the hidden character situation similar to the article but I don’t know what happened with it.
junk characters can wreak havoc somewhere i heard of a flaw in ntfs that if you renamed a file with a given character it caused windows to lock the file as in use and you either could not open it or delete it until you restarted.
And in modern days we use auto-indenting software :)
I wonder if hidden UTF8 symbols would confuse compiler? (Some certainly did it just a year or so back).
I think it is strange they went down to functional comparison, although algorithms can be copyrighted, and subsequently knowledge of those algorithms cannot legally be replicated elsewhere without the permission of the copyright holder, unless they prove those functions implement copyrighted algorithms it should be nonsense.
What else is copyrighted is design, which a pictorial icon defiantly can be considered part of, I think if there was a similarity its foolish they did not remove something so insignificant.
As for copying functions code reuse is a common part of implementation, often programmers will keep their gold code examples 5-10 lines or so, of course if they copied it from somewhere else what is described here is a perfect example why they should not, because the possibility of potential vulnerabilities introduced.
In the contrary if they copied entire functional blocks, i.e. files, classes, modules, that is clear copyright violation, it is part of the design, and you are reselling the same product or effort to implement. But then I guess it can get all hazy and tends to end with whoever has the largest legal budget.
So if you are going to leak a document.. and need it in a searchable digital format… print to pdf and then OCR it?
nah… cause the printer prints the hidden characters in invisible ink. ;)
it doesn’t work with textedit on mac they show up as question mark boxes.
I white-space character encoded my commercial software downloads with PayPal receipt details, to find out which miserable sod had been uploading source to Chinese ‘sharing’ sites, and putting me out of business.
I suspect those DVD rental machines, the ones that burn disks to order, don’t take cash and require a credit card, employ a similar ‘fingerprinting’ scheme?
reminds me of how you can hide whole novels inside images
post it online, then a person saves the image and then renames it as a rar
unzips it and the novel is inside
illegal obviously but is a unique subversive way of file sharing
You could interleave a signed checksum into it too. This would let you prove that it was your text and that it was a full and accurate copy.
Not at all difficult to detect. OCR text, count characters, count bytes, compare.
Yes and you can firewall it completely by streaming all of your text through a tiny sed script in a pipeline, or just view it in a hex editor, but that is not the point of the exercise and there are multiple valid use cases that do not rely on it being undetectable.
Current version of MS Word seems to eat the special characters even if pasted with formatting.
Regular Notepad is fooled unless you select “Show Unicode Control Characters” – at which point the zero width characters appear.