When it comes to programming, most of us write code at a level of abstraction that could be for a computer from the 1960s. Input comes in, you process it, and you produce output. Sure, a call to strcpy might work better on a modern CPU than on an older one, but your basic algorithms are the same. But what if there were ways to define your programs that would work better on modern hardware? That’s what a pre-print book from [Sergey Slotin] answers.
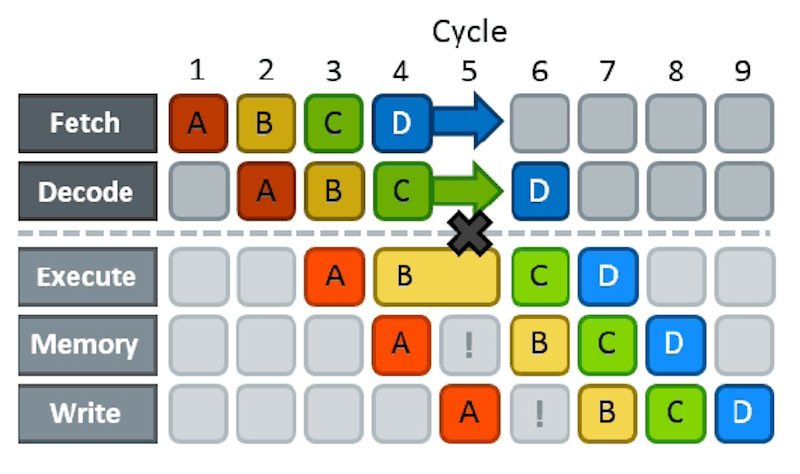
As a simple example, consider the effects of branching on pipelining. Nearly all modern computers pipeline. That is, one instruction is fetching data while an older instruction is computing something, while an even older instruction is storing its results. The problem arises when you already have an instruction partially executed when you realize that an earlier instruction caused a branch to another part of your code. Now the pipeline has to be backed out and performance suffers while the pipeline refills. Anything that had an effect has to reverse and everything else needs to be discarded.
 That’s bad for performance. Because of this, some CPUs try to predict if a branch is likely to occur or not and then speculatively fill the pipeline for the predicted case. However, you can structure your code, for example, so that it is more obvious how branching will occur or even, for some compilers, explicitly inform the compiler if the branch is likely or not.
That’s bad for performance. Because of this, some CPUs try to predict if a branch is likely to occur or not and then speculatively fill the pipeline for the predicted case. However, you can structure your code, for example, so that it is more obvious how branching will occur or even, for some compilers, explicitly inform the compiler if the branch is likely or not.
As you might expect, techniques like this depend on your CPU and you’ll need to benchmark to show what’s really going on. The text is full of graphs of execution times and an analysis of the generated assembly code for x86 to explain the results. Even something you think is a pretty good algorithm — like binary search, for example, suffers on modern architectures and you can improve its performance with some tricks. Actually, it is interesting that the tricks work on GCC, but don’t make a difference on Clang. Again, you have to measure these things.
Probably 90% of us will never need to use any of the kind of optimization you’ll find in this book. But it is a marvelous book if you enjoy solving puzzles and analyzing complex details. Of course, if you need to squeeze those extra microseconds out of a loop or you are writing a library where performance is important, this might be just the book you are looking for. Although it doesn’t cover many different CPUs, the ideas and techniques will apply to many modern CPU architectures. You’ll just have to do the work to figure out how if you use a different CPU.
We’ve looked at pieces of this sort of thing before. Pipelining, for example. Sometimes, though, optimizing your algorithm isn’t as effective as just changing it for a better one.














Welcome to 1995 ‘zen of code optimisation’ by Micahel Abrash.
He was writing about this for original pentiums back in 94-95.
* Michael Abrash; (Writer for Dr Dobbs)
I’ll bite, despite the articles being about CPUs. Your guy’s book wasn’t even written before the demoscene already minified code for C64 and Amiga hardware. Demoscene has the most impressive code optimizations, doing raytracing before even NVIDIA picked up the word.
https://www.youtube.com/watch?v=6F_PZYSuwFA
Enigma Phenomena (1991)
/flex off
I still think the most impressive demo I’ve ever seen is Heaven Seven by Exceed
https://www.youtube.com/watch?v=rNqpD3Mg9hY
Exceed – Heaven Seven (2000)
Real time raytracing, music, lighting etc
all in 64k
https://www.pouet.net/prod.php?which=5
if you want to try running it on your machine
I want my whole day back!
“Your Guy”? Michael Abrash is pretty well respected by Demo Sceners. I think the point here is by ‘Modern CPUs’ the article means Pentiums and beyond where this type of pipeline became the norm.
What about MCUs??
Seconded. Optimizing desktop PC code is important, but I’d really like to know more about optimizing for things like PIC, AVR, MSP-430, etc. Devices with no cache, no pipeline, and slow clocks where every instruction cycle counts.
A fun thing with a lot of MCUs is that some of them don’t have the branching problem. (and usually lacks a slew of other problems on higher end processors as well.)
Here performance optimization is usually by writing more clever code. Like using fewer libraries to be less bloated. And aim for the simplest operations that leads to a sufficiently correct result.
Integer math is kind of where one wants to stay. And going beyond that should only really be done if one really really needs it, since floating point on these types of processors tends to be a software library.
I have seen quite a fair few libraries and projects that uses way more advanced concepts that needed for the application at hand.
For an example.
If one is going to run a few serial RGB LEDs, one don’t need a whole object handling subsystem able to handle an arbitrary amount of LEDs and dynamically change the number of them on the fly. Just write a simple driver and use an array. Even if being able to call on an object and feed in a value into it is “nice” as well as create and destroy those objects during execution, but it sure has overhead… Though, if one makes a project where the amount of LEDs will change or is unknown, then the object oriented approach has a few advantages. but expanding an array is also an option.
Though, object oriented programming can lead to performance regression even on a desktop if used where it isn’t beneficial. Same thing goes for a lot of other more advanced programming concepts. Even floating point is sometimes not what one needs.
Optimization of code is an art, and a lot of programmers are abhorrent at it.
A good workaround for floating point is to used fixed-point arithmetic. I’ve done that for embedded stuff more than once. That is, if you’re going to print, say, amperes to 2 decimal places, then measure/count them in units of 10 mA.
Yes, this is a proper way to do things.
Staying with integers as much as possible is a very good way to ensure good performance on a microcontroller.
Exactly. It doesn’t make sense to use floating point when ADC or other inputs that are integer. It is much easier and in some cases more precise with scaled integer math due to truncation and rounding for numbers that cannot be represent precisely in binary.
Most of the time there is enough range for integer math. (exception: DSP algorithms where you might have to multiply very small coefficients)
An integer can de in integer of fractional units. You can have units of 1/255 and 255 of then make one.
In my code circles (sin cos tan) have 256 or 1024 degrees that yield values from 0 to 255 units of 1/255 this comes from a table of 64 or 256 elements because sine (cos / tan etc) has values that go 0 to 90 degrees, 90 to 0 degrees, negative 0 to 90 degrees, negative 90 to 0 degrees.
If I need a wider range then I use two bytes fixed point with bit values of 128, 64, 32, 16, 8, 4, 2, 1, 1/2, 1/4, 1/8, 1/16, 1/32, 1/64, 1/128, 1/256 so that all the normal maths routines work. Log doesn’t have to be base E’ or base 10, it can be base 2. Just take everything you learnt about decimal and it works with binary. And at the end of it all you just convert to binary coded decimal if a human has to see it.
Or better yet you can use log tables and such to do fast multiplies and division in terms of add and subtract. Provided the loss of precision isn’t a deal breaker. This is another demoscene trick, especially popular on platforms with no math coprocessor, 8-bit cpus, etc…
In one of those marvelous FORTH books was extensive an discussion about using scaled integer. You seldom need relative precision higher higher than 2^16 in non-scientific programs. You the programmer has to know the scaling factor.
Yes an art indeed but it still comes down on the modern MCU to the same thing it did decades ago with the old CPU’s – ASM and cycle counting. Anything else may be “improving” code but not “optimizing” code.
i love embedded development as a mind trip because the optimization problem is so different! my few PIC sort of projects, the whole thing is succeed or fail based on whether i can make an inner loop or interrupt handler work out in a given number of microseconds. the datasheet usually specifies precise execution time for each instruction (there’s no cache or pipelining), so i am often adding comments counting individual cycles. i often care about the specific number of cycles and too few cycles is just as bad as too many. a very concrete optimization problem.
on the other side of it, that’s usually only 10-20 instructions where i am counting cycles. it is such a discrete and finite problem. the rest of the problem is almost always relatively time-insensitive (book-keeping between calls to the interrupt handler, for example). but then i have to turn my mind to limited code (flash) and data (RAM) sizes. a lot of times i will actually use very slow idioms for the logic code because it can be so compact. like using function calls (a single branch-and-link instruction) instead of a sequence of 3 or 4 asm instructions even for basic arithmetic. totally different kind of game, on the same project.
The books premise is that most programmers understand optimizing in terms of algorithmic complexity. So it doesn’t cover that topic.
Optimising complexity is just what you want when it comes to MCUs.
Anyways Microchip put out a short document on optimizing C for AVR platform it covers the basics although it nothing surprising.
Other than that it comes down to quirks of the platform so the text wouldn’t be all that interesting.
Long story short you probably already know how to optimize for MCUs.
STM8 (8-bit) uses pipeline with prefetch so that (most of the time) it can execute instructions in a cycle. e.g. single cycle for complex address mode like stack offset for C local variable/parameter passing and variable instruction length up to 5 bytes!
Code alignment and branch pipeline flush makes it a bit more tricky when you need to count cycles.
Most pipelined MCU’s CPU’s use three to fives cycles to process one instruction, they do however (with few exceptions) complete one instruction per clock cycle.
So slightly different words and slightly different meaning but much the same otherwise.
Thanks, bookmarked.
And folks, Abrash, demoscene and all that: this is a book which has to be rewritten time and again. The underlying hardware changes dramatically.
Back then, RAM was typically as fast (or faster) than your processor (I knew of one system where two Z80 accessed the same static RAM in lockstep). These days, the processor has to wait hundreds (!) of cycles on a cache miss. RAM is getting some characteristics of what used to be external storage. Back then there was no pipeline (or a very short and predictable one). These days…
And so on.
So keep them books coming!
As this article reads, it applies to more than just the cost of branching which is only ever one instruction clock even when pipelined *except* where you have variable length instruction or out of order execution or both.
So it looks like it about a typical x86 which hasn’t existed since the Pentium.
x86 instruction are broken up into smaller microcode elements that are executed out of order and with branch prediction on a Reduced Instruction Set Computing (RISC) processor.
However to the programmer it appears as if they’re simply running x86 instructions on a Complex Instruction Set Computing (CISC) processor.
Other RISC processors just run native RISC.
The argument that x86 is just emulated on a RISC core is an argument that largely doesn’t hold water.
A lot of the complex x86 instructions still execute faster and more power efficiently than microcode could achieve on a simpler core. x86 processors are CISC, but do use microcode to emulate the rare or outdated instructions that frankly would be considered a waste of silicone if one implemented them in hardware. But a large portion is still having dedicated hardware, and it is still a fairly complex architecture.
However, it is true that a lot of x86 processors do not have an “x86” core under the hood, but rather an architecture that better plays with the limitations that modern implementations has to deal with. After all, x86 isn’t taking a lot of stuff in consideration since it frankly weren’t considered a problem back in 1978, let alone the late 80’s when the architecture already had matured quite a bit.
Then one can look at a lot of RISC architectures these days and conclude that some of them aren’t particularly RISC these days. This is the case for both PowerPC and ARM.
The biggest problem with x86 that I’ve read about is – in sharp contrast with ARM – that the instructions are not a consistent length. This apparently causes huge headaches in pipelining instructions because you can’t start instruction B until you know the length of instruction A.
Well, the variable instruction size isn’t that bad for a pure serial on instruction per cycle pipeline.
However, a decoder that has to decode more than one instruction per cycle makes the challenge a lot harder.
Though, the 1-15 bytes that an x86 instruction can be is a bit crazy to be fair. But some of these longer instructions are usually not doing 1 operation and one could argue that they in fact are multiple instructions tied together.
“instructions are not a consistent length. This apparently causes huge headaches”
one of the things i love/hate about cpu development over the past 30 years is that this ‘huge headaches’ concept has been shown to be finite, and to be vulnerable to factoring. in practice, the x86 instruction decode is *much* more complicated than on a CPU with a smaller set of fixed-length instructions. but it’s finite. you just chain together a few gates and look up tables and you can find the length of any instruction. it only takes as much time as gate propagation delay, and it can be done fairly safely speculatively far in advance.
you start looking at the cost of “a few gates and look up tables” and the fact that a given chip might have dozens of parallel instruction decode units to avoid stalls leading into the next step, and you can be talking about thousands or even millions of transistors. it makes a little heat, it has a little performance (or price/performance) hit. but then once you solve this problem, it gets out of the way of all of the other steps! it’s factored out and the rest of the chip can be designed without awareness of instruction length. even operand kinds can be factored away through clever design. and in the big overall budget of real estate and watts, it almost disappears into the noise compared to cache or parallel FP/GPU units.
that’s why x86 survives, but it’s also kind of a bummer. it can survive as long as we can accept a few % overhead. so it survives, and we accept that overhead. only cellphones/tablets (and now macs!) seem to be cost-sensitive enough (battery life) to banish x86.
To be fair, the overhead opens up the gate to higher peak performance in a lot of applications.
x86 is a fair bit hard to beat in a lot of High Performance Computing applications.
Though we are starting to see ARM + custom applications specific instruction set extension combos coming to market for the HPC segment. But these platforms tends to suffer from their application specific nature and the fact that they are more or less unique.
For a super computer the difference in performance per watt is sufficient to go for the ARM + extension approach over x86, but only if one has a select set of applications to run. Since ARM itself isn’t particularly impressive as far as HPC goes.
Phones and tablets, and most consumer systems on the other hand generally don’t care about peak performance. Nor the performance per watt in HPC applications.
Like a Raspberry Pi is a good home server. But performance wise and even performance per watt it still gets blown out of the water by quite old x86 CPUs if one wants it to do “real work”.
Though, most people today just needs a web browser and a video decoder to be on their way, a bit of float performance perhaps.
Typical to see “pipelining with a pipeline stall” as the cover picture. That’s eighties technology. The “instructions execute in parallel” time period started in the late eighties with the i960 and i860. Early nineties marks the introduction of that technique into x86 processors.
In older CPUs a branch was devastating: the CPU wouldn’t know which side of the branch to prepare into the pipeline, so you had to prevent branches. Then came branch prediction: just guess that the the way the branch went last time is the way it’ll go this time. But nowadays CPUs just execute both paths and “pretend it never happened” with the path that wasn’t taken.
(And we’ve seen a bunch of security issues the last decade when that “pretending” didn’t work 100%)
Yes, the concept of pipelines in CPU architecture design is a fair bit outdated.
Though, even some modern architectures seemingly don’t prepare both sides, for whatever reason.
Then there is other fun issues with working on both sides of a branch, as you say one has to go back and fix what shouldn’t have been executed.
In a hobby architecture of mine.
I however just queue the decoded instructions for both sides of the branch, but until the branch direction is known it won’t execute past the branch. (unless it is a short branch (ie a branch that only adds in a bit of extra code but will still always end up on the primary path regardless.)) Doing it like this has some downsides, but at least we don’t have to fix what shouldn’t have been executed.
Though, when the decoder is stumbling onto a branch, it will start interleaving the two paths, ie offer half the serial decode rate. (but that rate is already higher than execution logically should be able to keep up with. In short, the decoder will stall since execution is the bottleneck due to serial dependencies.)
Another subtle improvement one can make on almost any architecture is that the conditional jump that is the branch and the code figuring out if we should jump or not are technically separate. So if we execute the code to figure out the branch as early as reasonably possible, then run some other code before getting to the conditional jump, then we know what side we take. This though depends greatly on how the architecture does its conditional jumps.
In my own hobby architecture, a branch is a specific instruction, so the decoder will know of it pretty fast. And since main memory access times can be quite slow, there is also an instruction to inform the decoder where the branch jumps to in memory so that it can prefetch the code for the branch ahead of time as well. (though, if the code is cached this is somewhat pointless.)
But in my own opinion.
A lot of modern architectures rely quite a bit on just queuing decoded instructions, and then handling that queue in a fashion where we execute an instruction that has all its dependencies available, regardless if this execution is in order or not. Together with register renaming we suddenly have rather decent out of order execution. But I have read very few textbooks that even mentions this queue step that is all so important for out of order execution. (all though, I have seen some architecture implementations do out of order in a far less trivial fashion that in the end still is just a queue of decoded instructions.)
In the end.
Pipelines in a CPU isn’t really that applicable in a lot of cases these days.
Since it is really a pipeline if it has a decoder pushing out a few instructions per cycle, that gets queued up for execution. Picked from the queue in a somewhat “random” order as their requirements gets fullfilled, and pushed down one of many ports to the various execution units.
The concept of a bubble in this type of system also starts getting a bit muddy. Since if an instruction has an unfulfilled dependency, then there is most often other instructions that can be executed inside of our queue. Especially if we use simultaneous multithreading where we either have two decoders feeding the queue, or a single one that can interleave between two instructions.
All though, as far as SMT goes I think a core running 2 threads is just 2x SMT, one can technically go further and run 4 threads, or 5, and so forth. And just call it 4x SMT, 5x, and so forth.
And running beyond 2 threads also makes the port smash vulnerability a lot less feasible. Since threads do not execute like white noise, they have all sorts of patterns. In a 2x SMT system, our attacker thread knows that any behavior it detects is the other thread doing stuff. While in a 4x SMT system, it knows that the pattern it detects is a mix of 3 different threads, this needs to be analyzed and untangled, and doing that requires knowledge about the other 2 threads and not just the thread one is attacking.
Another advantage of running with SMT is that if one thread stalls, we don’t really have to switch it out, the core is still getting utilized by the other thread, we can wait a bit and see if the thread stops stalling. Switching out threads isn’t a free lunch after all, it can be a rather lengthy process.
Then there is also the subtle advantage of being able to run background tasks continuously, keeping them in a core even if they stall for many thousands of cycles. If this background task is important for system responsiveness, then keeping it in a core will make it able to react more or less instantly, instead of having calls to it be buffered and handled when the kernel eventually decides to switch it back in. (this is however only applicable to very few threads.)
(and somehow the “in the end” ended up in the middle of this post…)
Doing that costs you. Depending on implementation details, the costs vary, but…
* Complexifies the cache (“executing both paths” often means effectively simultaneous access of same cache line by different execution units), meaning less cache per silicon die area.
* Either it stalls one of the branches upon cache miss, or it spills out into external-memory bandwidth increases, as well as potentially more complicated memory-access non-collision protocols.
Lots of other costs too. In some cases, perfectly justified… but it seriously increases the minimum size/complexity of the design before it starts paying off the promised performance gains.
Executing both paths can be done by just having the decoder interleaving the two paths. Ie, decode a bit on one, and then the other, switching back and forth until the core knows what side is taken. This means it won’t require any more bandwidth from cache than before. Therefor no more cache complexities are needed to handle it.
In regards to going out to main memory on a cache miss for a so far unknown branch, this is debatable and will vary with what the thread is doing. If the thread is important then letting it go to memory is fine. If it isn’t, then that path can just stall until we know what side is taken and then we actually fetch it. (Implementing this in hardware more or less just requires 1 extra bit to follow our memory call out to cache, to inform the cache to not send the call out to main memory, and this doesn’t require much logic either.)
But as long as we stay in the CPU, the downsides aren’t that major compared to the upside.
Another downside is however the queue holding decoded instruction calls in the core, this queue will now have to handle conditional execution, but since the queue already should be checking for register dependencies, and for port dependencies, adding in the dependency of branching isn’t that much extra work.
The decoder for an example just spits out a 2-3 bit branch ID, there is 1 active ID, and a few dormant ones. When faced with a branch, the decoder will use one ID for one side of the branch, and other for the other side. And each side is going to have a “flush” call to remove the untaken path from the queue. But if one does speculative execution, then things gets a lot less trivial, since then one has a clean up job to do as well.
That can’t possibly be correct.
For one thing, I believe it’s still the case that a CPU will only execute a very small number of instructions between branches. It used to be quoted as 7, but it might have gone up a little now, after years of optimisation to avoid branching – but it’s still not many. And modern CPUs will have *thousands* of instructions in flight at once. The number of binary paths you’re suggesting, each of which will need execution resources, would rapidly become untenable – and a complete waste of those resources. (And, perhaps more critically today, of heat and power – Pentium 4-style space heaters are quite out of fashion these days.)
For another, if you were correct, branch prediction technology would have backed off, being less critical to keeping a processor occupied. It has not; the opposite has happened. AMD are even going as far as using neural nets to predict previously unpredictable branching patterns, which would be completely unnecessary if their CPUs could just go both ways and pick one later. The only reason to strengthen branch prediction is because your CPU is only ever going to go one way down conditionals, and it becomes ever more important to ensure it goes the *right* way – at least, on code that’s executed more than occasionally.
For a third, the whole reason attacks on speculative execution work is that they rely on sending the CPU predictably the wrong way down a branch fork (or an indirect jump), and then deducing from the timings all the work that was done before it had to be cancelled in flight. If the CPU were executing both sides of the conditional at once, the timings would be tested before the work had been done and the attacks would fail. Of course, there would be other subtle interactions and avenues of attack available in such situations – but not that one.
Here’s a 2020 thread on comp.arch on exactly this subject: https://groups.google.com/g/comp.arch/c/CPAjAfEqanY It comes to a similar conclusion.
There is many ways to implement the handling of branches and what one can do is largely affected by the architecture itself.
x86 is rather complex in its pipeline and wouldn’t be a particularly good candidate for decoding and preparing both sides. While other architectures would do this more easily.
Also, there is a difference between:
1. decoding both sides and putting the decoded instructions into the queue ready for out of order processing when the branch is decided, or flushed if not taken.
2. decoding both sides and executing the instructions, and then later cleaning up whatever the untaken side executed.
Point 1 can reduce the number of cycles one looses due to a miss predicted branch without really effecting overall power consumption. I will agree that 2 is impractical and shows few signs of being used in practice by any architecture. But point 1 has merit in a lot of situations. Point 2 is also not to be confused for usual speculative execution. However, I wouldn’t be surprised if some CPUs actually does this exact thing.
And since a decoder is usually one of the faster components in an out of order capable system, then we can interleave our two paths, letting the decoder spend 1 cycle on each side, jumping back and forth as it follows both paths until the core figures out the actual path taken.
If the decoder stumbles onto yet one more branch, the added complexity of interleaving 3 different paths might make this undesirable to go beyond 2 paths in practice. (however more paths has advantages, but there is a point of diminishing returns, especially when one can count more branches than what fits in the queue…)
Personally I think branch prediction is mainly only important for serial instruction rate, and not overall performance. And as software moves to more multithreaded applications that we might see branch prediction as a concept get outdated.
Since with out of order execution and prioritizing instructions that a branch is dependent on can allow the core to not stall due to still having a backlog of calls left to execute. Ie, when a branch comes into the queue, we back solve what instructions it is waiting on, and those instructions in turn are waiting on, and so forth, and then prioritize these instructions above all other.
If we let our decoder just wait until executions solves the branch, or let it interleave across our two paths is a debatable question. The prior is simplest to implement, but the later keeps our queue more full.
Since if we just let the decoder stall when faced with a branch, then our queue is going to more or less drain while we wait for execution to solve the branch. And if branches are happening sufficiently often, our queue won’t save us from a stall since the code might not throw us enough other instructions to fill in the bubbles with.
But when our decoder is interleaving our two paths we will still put new instructions into the queue at half the usual rate. Ensuring that tighter branches won’t effect us as easily, this means that our queue will now always contain the next instructions following the branch, so we have now more or less removed the branching problem.* However at the expense of now needing to handle multiple paths. (as explained in the second half of my earlier comment here: https://hackaday.com/2022/03/09/modern-cpus-are-smarter-than-you-might-realize/#comment-6443989)
*(Actually not, there is more to it than this. Branching also stumbles over into caching since one path might not be in cache, but this is usually more data related than prefetching code. And is another long story…)
In the end.
Queuing decoded instructions for our out of order system to work efficiently gives us the ability to not as easily stall due to a branch. Or at least if we prioritize instructions that the branch is dependent on, if we don’t then we forgo the backlog of calls used to fill in the bubbles.
Though an out of order queue is however not a magic silver bullet, it still require a lot of resources, but since out of order is a major advantage for speeding up parallel sections of our code we still want it regardless.
However, Intel, AMD and a fair few others have all chosen the path of good branch prediction and speculative execution as their silver bullet to skirt around the branching problem. Has it been effective? Maybe.
It’s all true, but nothing new for some 29 years.
I think the “original pentium” , which was from halfway the ’90-ies https://en.wikipedia.org/wiki/Pentium stuff like this has been implemented. From what I remember in those days those processors tried to execute every branch at the same time, and in the meantime generated a lot of heat by chasing all those dead ends.
Since then there has been almost 30 years of making smarter algorithms and optimizations, and I feel this article is barely scratching the surface of that.
In the mean time, a lot of extra performance can be gotten by making more use of parallelization.
I just bought a new Cezanne 5600G, which is no slouch, (but no top model either) and almost every time some task takes a long time then usually 11 of the 12 threads of my 6-core processor are just sitting there and twiddling their thumbs.
Sometimes it’s easy. You can add a “-j12” to speed up building a project with make from over a minute to a handful of seconds, but most often there is not much a mere user can do about such things.
In about 1990 I was in a microprocessor engineering course in college. We breadboarded an 8086 with a ROM. We programmed the ROM with a very, very simple program in assembly that ended in a jump back to the beginning. We then probed the address and data busses to watch it execute.
What was striking was that the two memory locations after the jump were consistently fetched despite the fact that they were just the 0xFF of the empty EPROM.
So even the 8086 was doing some speculative instruction fetching 30 years ago.
A lot of architectures tends to read blocks of memory at a time. Usually a whole cache line. (though the behavior is a bit older than cache itself.)
To a degree it is speculation if one will need the whole block, but the vast majority of the time the answer is “yes” since the block tends to be fairly small compared to even a short bit of code. Ie the potential of it containing a branch that we jump away from it small.
Though, a lot of modern processors fetches more than just 1 additional cache line, they tend to stay a bit more ahead, how much will though vary on the architecture and implementation.
On a lot of x86 systems, one can go into BIOS and turn this feature off if desired. Or even adapt its behavior. Though, depends on the BIOS on what settings it exposes. And why one would turn this off and end up in stalling hell I don’t know…
We already hit the complexity wall but most seem not to have heard the impact bang yet.
Let’s go for simpler instead of adding more to the towers of existing complexity!
Do we really want compilers that are bigger than the sum of all the OSes’ code we have used in the last 50 years?
That can only have one result: Epic fail.
I had a love-hate relationship with the SH4’s Branch Delay Slots https://en.wikipedia.org/wiki/Delay_slot
Essentially you have the next couple instructions after a branch that get executed no matter the outcome of the branch.
It can play hell with debugging if your code branches somewhere and then immediately overwrites the address it branched to with another load operation. But the advantage is no pipeline stalls.
That there sounds like a bit of madness.
Though, at the same time it is just like the branch just happened a bit later on and one has some room to put in a few more instructions ahead of the branch.
It isn’t that uncommon that one has a fair bit of computing to do ahead of a branch that isn’t determining the path taken on the branch. And this code can be executed between computing what side of the branch we will take and actually taking the branch.
But to force that type of branch optimization down the throat of programmers in that fashion seems a bit harsh…
“We were somewhere around Barstow on the edge of the desert when the Delay Slots began to take hold.”
I think that is one particular architectural feature that caused more than it’s fair share of nightmares & perhaps even PTSD. Good times!
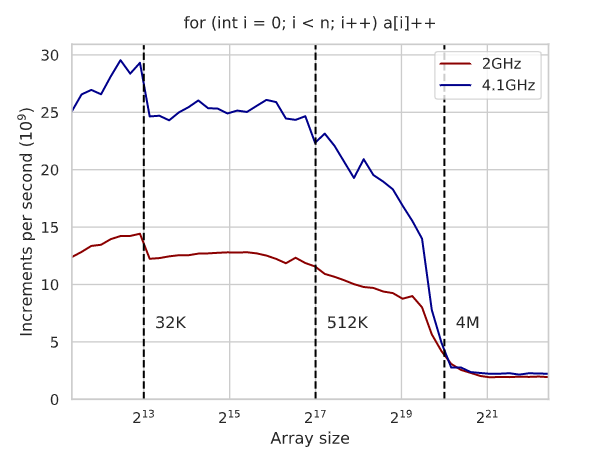
Avoiding cache misses has been the main issue for the last 20 years…