While it may not look like much, the image above is a piece of the original email where [Ken Thompson] described what would become the implementation of UTF-8. At the dawn of the computer age in America, when we were still using teletype machines, encoding the English language was all we worried about. Programmers standardized on the ASCII character set, but there was no room for all of the characters used in other languages. To enable real-time worldwide communication, we needed something better. There were many proposals, but the one submitted by [Ken Thompson] and [Rob ‘Commander’ Pike] was the one accepted, quite possibly because of what a beautiful hack it is.
[Tom Scott] did an excellent job of describing the UTF-8. Why he chose to explain it in the middle of a busy cafe is beyond us, but his enthusiasm was definitely up to the task. In the video (which is embedded after the break) he quickly shows the simplicity and genius of ASCII. He then explains the challenge of supporting so many character sets, and why UTF-8 made so much sense.
We considered making this a Retrotechtacular, but the consensus is that understanding how UTF-8 came about is useful for modern hackers and coders. If you’re interested in learning more, there are tons of links in this Reddit post, including a link to the original email.














I was expecting something amazingly clever, but this seems rather straightforward.
I think that’s why it’s amazingly clever (i.e., because it is quite straightforward). (c:
But it’s also quite straightforward to come with the idea. The hardest part is coming up with a list of requirements. Once you have those, the implementation follows naturally, especially if you’re familiar with Huffman coding.
easy to say in hindsight my good man.
+1. (c:
He might have done it in a busy cafe to be in the same setting that UTF-8 came into the their mind according to a linked file on the Wikipedia page : “I very clearly remember Ken writing on the placemat and wished we had kept it!” (http://www.cl.cam.ac.uk/~mgk25/ucs/utf-8-history.txt)
It looks like a hotel lobby. Probably at a convention.
Looks like a text book Huffman encoding header onto variable bits. Not the first time
it is being used. http://en.wikipedia.org/wiki/Huffman_coding#Compression
Superb! Great explanation. Thanks :-)
Actually, I think Dijkstra’s algorithm (which is how a GPS figures out shortest path) is the most elegant hack you can describe on the back of a napkin.
The algorithm and how it works: http://en.wikipedia.org/wiki/Dijkstra%27s_algorithm
The story of how he invented it in 20 min while shopping with his fiancee: http://dl.acm.org/citation.cfm?doid=1787234.1787249
Poor guy. At least he gets to do something productive and make everyone’s life
a bit easier.
For men, shopping is a sport. i.e. get to the cashier in the shortest time possible.
For women, it is a long classic Quest collecting meaningless objects on the way
while trying to stretch it out to escape from reality.
You don’t read real books, I guess.
How many fedoras do you own?
How many women have you shopped with?
Well. I would say that subnetting is in the running for most elegant, as in it is so simple it takes a month to understand how it works, then it is easy forever.
Gorgeous explanation, thank you. Now if only programming languages could all agree on how to process unicode. Natural language processing in Python is infinitely more difficult with unicode, in spite of how elegant a solution it is for information transmission.
As John Pinner said at PyCon UK last week, that’s because Guido was too good to Americans: Python 1.x/2.x was basically built with ASCII users in mind, and tried to make their life very easy *in the common case*. Unicode support was tacked on later, thanks to the generous efforts of a few French guys.
Things should get better with Python 3, once all “six”/legacy hacks are shed from 3rd-party libraries. It might take a while.
And still, Microsoft managed to spoil the elegance of UTF-8 by strong-arming the Commitees to allow a Byte Order Mark at the beginning of UTF-8 files, killing one of the most elegant properties (a plain ASCII file can be seen as the same content in UTF-8).
BIG FAIL.
Starting the alphabet at 65 in the ascii table was brilliant because if you look at it in binary it makes sense? That’s absurd! I’ve been programming since I was a kid before the days of DOS, and I always had to look those damn character tables up because I could never remember where the letters started. And knowing this trick in binary would have done me little good because who the hell ever inputs text or examines text, in binary?
It isn’t exactly difficult to convert decimal to binary
Difficult no. Tedious yes.
Take a decimal number, OR it with $30Hex and you get an ASCII digit. OR it with $40 and you get the alphabet starting with the first letter after zero being “A” ($41). $60 gets you the lower case alphabet.
Simple ORs and ANDs make conversion and alphabetizing simple.
ASCII was standardized in 1963. If you think what kind of hardware was available back then, I think you can appreciate why they decided to use every bit of bitwise magic they could.
It wasn’t meant to be simple for humans. Who examines text in binary? Computers! Also teleprinters and god knows what other half-mechanical abominations whirring away with enough torque and speed to take your finger off.
If you look at ASCII, the 16s and 32s bit high means numbers. The 64s bit means letters. 64+32 means lower-case letters. With 64s high, A B C is 1 2 3.
How do you convert a digit from 0-9 into it’s ASCII rep? Add 48. Or OR it with 48. That’s pretty simple, now, isn’t it?
The whole thing’s pretty clever, dividing the symbols up into groups that are easy to tell apart just by checking one bit. That one bit powers an electromagnet that moves a lever or the carraige or some bit of heavy metal, which means an ASCII-powered typewriter is nice and simple to make. So it’s cheaper, so more people can have one. And it breaks down less often. And when that happens, it’s easier to fix.
I actually figured out this aspect of ASCII for myself just idly thinking one day, that’s when the genius of it struck me.
In the case of stuff like this, standards that go back a way, you have to bear in mind what they were invented for. Mechanical typewriters instead of screens and keyboards, mainframe computers with 4K of memory that cost ludicrous amounts, and reams of bank records on paper cards or magnetic tape, brought in in huge batches at the end of the day to keep everybody’s records balanced. It’s evidence of how well the designers did their jobs that we still use it all now. Them were the real men’s days!
Though myself I grew up with a collection of tiny plastic 8-bitters as various xmas presents, and I wouldn’t give them up either.
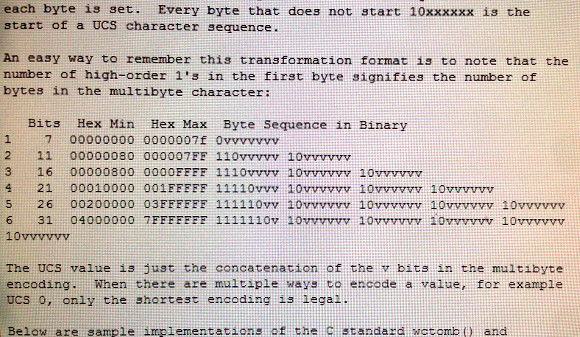
Why is there a need for “continuation bits”? That seems very wasteful to me. There are lots of ways to avoid 0x00. Just simply start by making them as reserved and not map to any character. i.e. 0xc300 is not mapped to anything. You waste only 1 out of 256 instead of 1 out of 4 for the subsequent bytes.
Then how do you distinguish 0x36, ?
Shitty CMS can’t handle <
how do you distinguish a 0x36 ascii byte followed by a null end byte?
In addition to the problem Gdogg brought up, there’s also the requirement of being able to “hop in” mid-stream. If the first byte you get starts with 10, you immediately know you’re in the middle of a character and can start skipping forward/backward, depending on what you want. When you hit a byte that starts with a 0, you know it’s a 1-byte plain ASCII character. When it starts with 11, you know it’s a start byte.
Compare that with having a map of reserved values…
The reason for the continuation bits is to make resynchronization easier. Without the continuation bits if you’re plopped into the middle of a string you don’t know whether the byte you’re reading is a single ASCII character or the middle of a multibyte character. By adding the continuation bits resynchronizing is as easy as “move forward until you find a byte that doesn’t have 10 as the first two bits.”
Keeping continuation bytes distinct from starting bytes has nothing to do with avoiding NUL bytes. The UTF-8 encoding of U+0000 is a single NUL byte. The purpose is to make the encoding self-synchronizing (meaning it doesn’t need to be parsed from the beginning to be accurately decoded). No representation of a single character can contain the encoding of another character, and one must be able to determine if a byte is the first byte of a character’s code-unit sequence or in the middle of it without backing up. Yes, you could fit 4 times more of the BMP into 2-byte encodings instead of 3-byte ones, but most of it would still be encoded with 3 bytes, including all of unified CJK and the U+2xxx punctuation and symbol codepoints. Of course there’s also a bunch of non-BMP codepoints which are represented with 4 bytes in UTF-8 that could be encoded in 3 bytes with this modification, but thats of even less concern given that virtually no codepoints outside the BMP are used on a regular basis. And the price you’d pay for being able to represent 0.5% of the UCS codepoints in 2 bytes instead of 3 is that every single UTF-8 string you work with would have to be parsed from the beginning to the end, and corruption of a single byte could cause an indeterminable number of characters following the corrupted one to also be incorrectly parsed.
After the C language being in wide use for, what, 20 years at that point when utf-8 was designed? And suddenly you decide that 0x00 can appear anywhere in a string? I can see how that would work out..
Really cool video. The camerman-in-a-rocking-chair effect did not help though, so distracting.
He really should have gone to the bathroom before the interview started…