
Imagine you were walking down a beach, and you came across some driftwood resting against a pile of stones. You see it in the distance, and your brain has no trouble figuring out what you’re looking at. You see driftwood and rocks – you can clearly distinguish between the two objects without a second thought.
Think about the raw data entering the brain. The textures of the rocks and the driftwood are similar. The colors are similar. The irregular shapes are similar. Thus the raw data entering the brain’s V1 area for both objects must be similar as well. Now think about the borders that separate the pieces of driftwood from the edges of the rocks. From a raw data perspective, there is no border, and likewise no separation because the two objects are so similar. But yet your brain can clearly see a rock and a piece of driftwood – two distinctly different objects. So how does the brain do this? How does it so easily differentiate between the two? If the raw data on either side of the border separating the wood and the rocks is the same, then there must be an outside influence determining where that border is. Jeff Hawkins believes this outside influence is a very special and most interesting type of feedback. Read on as we explain and attempt to implement this form of feedback in our hierarchical structure of invariant representations.
Now, this is not your mother’s feedback we’re talking about here. We’re not simply injecting part of the output back into the input like a neural network would do. Because we are working with a hierarchy of patterns, the feedback must take place between the hierarchical levels. Basically, each level is a child to the parent levels above it. A parent level can “adjust” what the child level below it is actually seeing to accommodate what it predicts it (the parent level) should be seeing.
Each level of the hierarchy is constantly trying to predict what the next pattern will be. On the very low level, these are just lines and edges. But near the top, the constant prediction of high level patterns can act as a base for intelligence. While this is only one of many theories on how the brain does this, replicating this type of hierarchical feedback in silicon should be possible. But it’s not going to be easy. Let’s walk through a simplified example that continues off our previous work of forming an invariant representation of a basic shape. But this time, we shall apply hierarchical feedback.
Finding Structure with Prediction
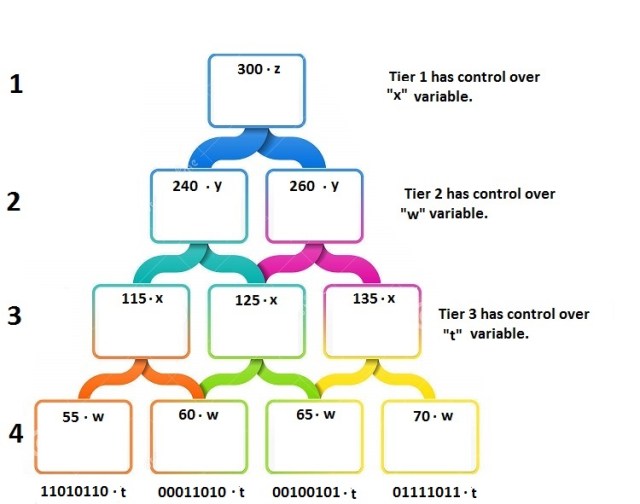
In our previous example of forming an invariant representation of a square, raw binary data was taken into the model through Tier 4. Tier 4’s job was to find repeating binary sequences, give that sequence a name, and pass that name up to Tier 3. Tier 3’s job was to find repeating patterns of names, give the group of repeating patterns another name, and pass that other name up to Tier 2. This process repeats until the invariant representation of a square is formed at the top most tier.
This works in a fixed, unchanging environment with no other shapes or lines to confuse our model. But what happens if we attempt to replicate the rock/driftwood problem by placing our square alongside many other similar shapes? This is where feedback becomes necessary. If we are unable to distinguish between a single side of our square and the side of an adjoining triangle, then we must use stored invariant patterns of the square higher up in the hierarchy to determine what we are seeing. So how do we do this.
The Power of Variability
Each name that a Tier outputs will need an “adjustment” variable, with that variable controlled by the Tiers above it. For instance, imagine Tier 2 sees the pattern 115 & 125 repeat often, and it gives it a name of 240, and passes that name to Tier 1. Fast forward in time, and imagine the name of “115” once again comes across the registers of Tier 2. It can predict with a certain percentage that the next name it should see is a “125”. But say the name coming in is closer to a “123”. Tier 2 will adjust what Tier 3 is seeing by changing the “w” variable of the Tier 4 output, so that it now passes to Tier 3 what is needed for Tier 2 to meet its prediction.
This type of feedback occurs between all stages of the hierarchy. It’s why you can see both driftwood and rock laying together as clearly as you could see an orange basketball laying in their midst. While little to no feedback would be needed to identify the basketball, the majority of what you see of the rock and wood is actually just feedback based upon individual invariant representations of a rock and a tree branch. Likewise, we cannot see a single line of the square next to a line of a triangle – for the data coming off the ADC for these two lines is identical. The two shapes can only be separated by feedback from higher up in the hierarchy.
Keep in mind that this simple example of a working hierarchy is just that – simplified. To operate in the real world, a working hierarchy would consist of hundreds, perhaps thousands of Tiers – each with individual inputs that could reach into the hundreds of thousands. Luckily for you, the entire concept can be emulated in software. With FPGAs, gigabytes of RAM and CPUs that can run billions of cycles in a single second, all of which are available to you, what are you waiting for? Can you write a program that takes the torrent of data off the ADC and configure it into a hierarchy with feedback? How would you even start? Show us your rough draft pseudo code.














laying in their mist.
laying in their midst.
Sorry:)
That’s a portlandia sketch
Fixed. Thanks!
“The irregular shapes are similar.”
Sorry, I don’t see that.
The wood is curvy and knotted. The rocks are jagged, broken. The branches are a smooth surface except for their tips. The tips may be sharp but they are only points, not long edges like the sharp parts of the rock. The branches are much longer than their width. The rocks appear to be closer to equally wide/long.
So your saying it should be easy for you to write a program to identify which is which?
No, it certainly would not be easy. I didn’t write that it would be easy for me either. But if I were defining the problem, looking for an algorithm that works when shape, color and texture are all similar I wouldn’t use this photo to test it.
If someone writes a program that distinguishes between the rocks and the wood I will be impressed. But if they claim their program is distinguishing items where all these properties, shape color and texture are similar I will be skeptical.
I’m not sure there even could be such an algorithm. Give me a good example where you can recognize things where ALL of those properties are similar. Does the human brain even do that? I see the rocks and the wood only because the shapes are not similar.
The only example where everything is similar that I could think of would be if you were looking for specific shapes in a pile of similar shapes. Maybe something like letters in a pile of letter-like objects or maybe a “Where’s Waldo” book. That would just be a search algorithm though since you know exactly what you are looking for. That is a very different and much easier problem to solve.
How’s this example work for you? http://www.visualphotos.com/photo/1×7589640/bengal_tiger_panthera_tigris_walking_in_grass_Z9340669.jpg
Beautiful photo, but it took my brain an immeasurably small (by my own perception) amount of time to pick the tiger out from the grass. This might be exceedingly difficult for a programmer to deal with, but the human mind can do it effortlessly.
I think that the human brain works a lot with pattern recognition, but not entirely. A very small child might not know what a tiger is yet, but he/she could easily tell that there is an animal in the photo.
Just my opinion.
My example wasn’t to provide a picture that you couldn’t discern. It was an attempt to fulfill a critique.
“..Give me a good example where you can recognize things where ALL of those properties(shape, color, texture) are similar…”
@Dain Bramage,
If I understood what I read correctly the article above proposes is essentially pattern recognition by parts.
As I stare at the photo of the tiger from the corner of my eye it seems my brain seeks to impose some order on the image; the darkness in between blades of grass become depth, the ‘noise’ created by the grass in the foreground is filtered somewhat to reveal the underlying outline of the tiger (as well as perceived depth, coloration, etc.).
I guess what I’m trying to put down in words is that the proposed algorithm, when applied to sight, would “learn” about depth or other complex constructs as an abstract concept based on the discrete components that make up “depth”. Unfortunately our understanding of what depth entails is based not just in perception and personal experience, but also language and learned behaviours.
The machine utilizing this algorithm will only have perception and therefore cannot be guaranteed to understand that depth/distance/light/color/outline/etc is even something to be “known”. The machine may, without guidance, learn completely different things about its surroundings and come to completely “wrong” conclusions.
I actually find distinguishing the border between the rocks and the wood a little difficult. I can do it, but it takes a lot more time and effort than determining that I’m looking at wood and rocks.
Perhaps that is part of the problem for software? Do any of the algorithms that exist currently break it down and only look at a small section? I think if you looked at the right parts of the wood in isolation, which our brains do when looking for the pattern, it should be relatively easy for software to figure out that the curves and colour are likely wood. The same would apply for the rocks, if you isolate a section of only rock, it should be clearer that the grey, jagged, squarish, shapes are rocks.
I think that on the tiger example, part of the reason human can see the tiger is that, seeing his head, we can anticipate the shape and position of the body-e.g. we know what to look for. If you cover the last 2/3 of the image, the task becomes harder-then your brain has to rely solely on finding the bigger chunks of the black color.
Yeah agree. Was happy with textures/colours being similar, but not shapes.
neural net is good at this — it’s essentially what’s being described in the hierarchy while not quite hitting that term.
Our brains — our neural networks — have been entrained to recognize animal/vegetable/mineral, and have certain expectations. (I had a dog get quite freaked out by an animated, wireframe xmas-lit reindeer, it broke her expectations in ways that had us laughing so hard we couldn’t film it)
But it’s not foolproof, e.g. the old bar scene with the guy with long blond hair seen from behind problem.
Autism may be a case where it is more difficult to weight the cues that lead to one conclusion or another, leading to all the possibilities being present at near-equal strengths. Primitive robots on the other hand, may not have the cue weighting at all, and have to work out lots of details to try to draw conclusions.
Part of how the brain knows what it is is through experience
We’ve seen hundreds of trees so we have a library of tree references in the brain
We can also see the differences of texture and color…something more easily separated by the data ..kind of like how the magic wand works in photoshop
We also know that the image is a representation of three dimensional objects which gives us more insight as to what we’re looking at
If those can be made into tiers or not I’m not sure
Sounds like Watson level stuff
Experience and context is a huge part of it. The easy conclusion of driftwood on rocks is in part due to the fact you are on a beach, and you would expect that. It could be a big grey bus laying on the beach, but you would expect that so you would probably still think it’s driftwood. Likewise, of you saw the same thing in the distance on the highway, you’d likely have to get s much closer view to figure it out, because you wouldn’t expect driftwood and rocks on your morning commute.
The whole point of this series of articles is that we _don’t_ have a library of reference images in our brain. Instead, our brain has, through experience, identified a common set of patterns that show up in all trees: the invariant form of a tree. Whenever your brain sees this set of patterns, it therefore knows it’s a tree. It’s not taking the image of the tree and comparing it to thousands of other pictures of trees to see if the image is similar enough to justify calling it a tree.
There is a type of neural network that is used for this sort of thing because it is inherently hierarchical – a multi-layer perceptron neural network (MLP). I’ve worked on problems simmilar to this – picking out a specific type of tree crown against rocks, shrubbs etc all with simmilar textures. The trick is to try and tell what is unique about your target, and try to pre-process the data to make it easier on the computer. For the driftwood problem, I would run edge detection, then compute haar wavelets from different angles (in, say, 30 degree increments). This would mean that the driftwood would have longer patches with no edges along at least on of the lines picked. Feed this data into the MLP NN and you’re good to go. Of course, now I have to go and actually try this :/ darn you hackaday!
I have been officially nerd sniped :P xkcd.com/356
I’m self taught so I’m not sure if haar wavelet is the right term. mean travel along a line and returning a 1 if the next pixel (or group of pixels) along the line is darker than the previous ones by greater than a certain threshold. A long string of 0’s would mean the line is going along a path with a fairly constant hue – the beach or a brance of driftwood in line with the line. Short strings of 0’s interspersed with 1’s would indicate rocks or brances perpendicular to the line. When a brance is found, fill in the whole region as determined by edge detection or a colour threshold.
As [Me] said, there are differences in length, angularity, and spacing of edges. Transforming the image into the frequency domain, doing a notch filter, and converting back really brings out features of interest; better than a common edge detection I think. Did it in Imagemagick. Made the trees look remarkably like blood vessels, and the rocks look like cells. There is microscopy software designed to automatically separate such features, I wouldn’t be surprised if it could complete the recognition with fair accuracy. Doing it manually I’d try the Haar wavelets/transform like [Jonathan Whitaker] suggested.
As for Jeff Hawkins’ feedback system? I think we might as well have been presented with a Kabbalistic astrology chart, and asked to determine how a machine might distinguish rocks from trees using that. The same amount of evidence is presented in the article that either method is actually useful for the problem presented – none. Questions about previous installments on the topic were responded to with the promise of answers in future articles, but it seems they’re only adding more vagaries and suppositions. May still be good for some creative general discussion, I have enjoyed that part. But on Hawkins’ theories specifically, you lost me several leaps of faith ago.
How to get started?
Well, I’d go download the open source implementation: http://numenta.org/nupic.html
So…. this is how the Voight-Kampff Test comes about…
Your incredibly powerful brain spent years learning to interpret the data from your eyes!
What? No mention of an Arduino in the entire post???
I kid.. I kid… :)
Interesting stuff.
The structure is not the hard part (not that it is in any way easy), it’s the training of that structure – setting the various weights of feedback and weights of weights of feedback, etc, that is difficult. If copying the structure of the brain was all that was necessary to generate artificial intelligence, we would have achieved it by now. The same goes for almost all of machine learning: building a structure that learns is just the first step. Getting it to learn non-trivial things without hundreds of thousands of iterations – that’s hard. Many would say at this point just to simulate the world in which the structure learns, but most simulations work by smoothing out the world (non-gaussian noise is made gaussian because it is easier to compute and is a reasonable approximation). Many have supposed that rough edges that get smoothed out end up being very important to the learning process.
“If the raw data on either side of the border separating the wood and the rocks is the same, then there must be an outside influence determining where that border is”
The raw data is not the same. That’s why anyone can differentiate the rocks and trees.
“It’s why you can see both driftwood and rock laying together as clearly as you could see an orange basketball laying in their midst. While little to no feedback would be needed to identify the basketball, the majority of what you see of the rock and wood is actually just feedback based upon individual invariant representations of a rock and a tree branch”
Why not? I would argue that an orange basketball in this picture would need more feedback than rocks or a tree. It is not a natural thing to be in this frame. One would think that lower levels (tiers) could mistake it for an actual orange, being on/near a tree and all. A basketball would pro’ly be represented much higher up and enforced down to lower levels.
Things like this are why it takes an organic brain a few years to differentiate objects. Infants have been shown to be able to identify objects by sight, which their only prior contact with is having had them in their mouths.
Try and figure out how that works!
The reason that the infant is able to recognize an object by sight after chewing on it is because they are able to relate touch and position information to the image that they are seeing. When the newborn is chewing and moving the object around they are forming a memory of the object’s dimensions and other physical characteristics. Later on the visual portion of the mind can use this data as feedback to understand the raw visual data. This is the opposite of when we are groping behind something we are too lazy to move. Instead of using touch data to recognize what we are seeing; we are using visual data to recognize what we are touching. Ever notice how the person groping appears to be concentrated, but not on what is directly in front of them.
In the image there are many shadows being cast by the larger stones and the driftwood. Light and shadow play a huge role in parsing visual data.
http://twistedsifter.files.wordpress.com/2012/05/flying-carpet-shadow-optical-illusion.jpg
There are a number of things the human eye is incredibly good at. We have predator eyes and that is reflected in the things you need to pay attention to for effective camouflage (i.e. hiding from other predator eyes): Shape, Shine, Shadow, Silhouette, Spacing (aka patterns), Skyline, Color, and Movement (Regarding Skyline: think silhouette against a high contrasting background – like someone cresting the top of a hill. This is different from ‘Silhouette’ which can be thought of as ‘Outlining’)
Ever follow a housefly with your eyes? It’s easy until it flies against a dark background – then you instantly lose it, because you can no longer see the things you’re good at.
Anyway, the point is to provide a bit more background around how we receive visual data, and helps illustrate how (like it’s alluded to in the article) we do not experience the world “in the raw”. We experience the world through the filter of our senses, and often don’t even realize it.
This series is fascinating and thought-provoking!
So true
http://www.technologyreview.com/view/532886/how-google-translates-pictures-into-words-using-vector-space-mathematics/