Hackaday reader [nats.fr] wrote in with some code from a project that resizes a video stream on the fly using an FPGA. Doing this right means undoing whatever gamma correction has been applied to the original stream, resizing, and then re-applying the gamma. Making life simpler, [nats.fr] settled on a gamma of two, which means taking a bunch of square roots, which isn’t fast on an FPGA.
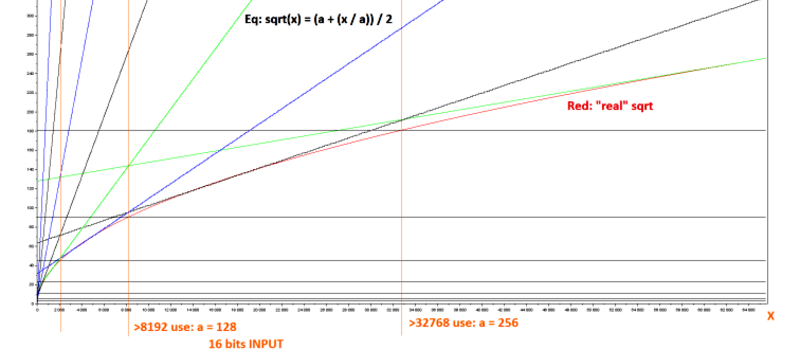
[nats]’s algorithm is pretty neat: it uses a first-stage lookup to figure out in which broad range the value lies, and then one step of Hero’s algorithm to refine from there. (We think this is equivalent to saying he does a piecewise linear interpolation, but we’re not 100% sure.) Anyway, it works decently.
Of course, when you start looking into the abyss that is special function calculation, you risk falling in. Wikipedia lists more methods of calculating square roots than we have fingers. One of them, CORDIC, avoids even using multiplication by resorting to clever bitshifts and a lookup table. Our go-to in these type of situations, Chebyshev polynomial approximation, didn’t even make the cut. (Although we suspect it would be a contender in the gamma=1.8 or gamma=2.2 cases, especially if combined with range-reduction in a first stage like [nats.fr] does.)
So what’s the best/fastest approximation for sqrt(x) for 16-bit integers on an FPGA? [nats.fr] is using a Spartan 6, so you can use a multiplier, but division is probably best avoided. What about arbitrary, possibly fractional, roots?














LUT to logarithmic, then every power (or root) is just a multiplication.Then LUT back.
This paper from the university of Jakarta, Indonesia claims digit-by-digit calculation is the most efficient one of them all:
“An optimized square root algorithm for implementation in FPGA hardware”
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.174.6832&rep=rep1&type=pdf
And since the spartan 6 also has multiplication, this paper from Inria, France might help as well:
“Multiplicative square root algorithms for FPGAs”
https://hal.inria.fr/ensl-00475779v1/document
@jklu, Thank you for the link to the paper “AN OPTIMIZED SQUARE ROOT ALGORITHM
FOR IMPLEMENTATION IN FPGA HARDWARE”. However, I would like to make one correction:
The paper cited in your link is not from “university of Jakarta, Indonesia” as you said; it is from the Universitas Ahmad Dahlan (UAD) a “private” institution (as if any university in Indonesia can truly be “private”) which located in the city of Yogyakarta (a.k.a, Jogjakarta or simply Jogja) on the Island of Java. Yogyakarta is a significant distance from the Indonesian Capital of Jakarta, which is also located on Java. Here are a couple of links: https://en.wikipedia.org/wiki/Yogyakarta -and- https://uad.ac.id/id
Best Regards, Drone – from Jakarta
How does a handheld calculator do it? I would assume the hardware in these is logic-based, similar to an FPGA.
You’d assume incorrectly. A calculator used a microprocessor and conventional algorithms. An FPGA uses pure hardware in parallel, and to get maximum performance out of it you want to be able to either pipeline or calculate in a single clock cycle. You’re looking at a different way of thinking about the problem.
Would it not depend on the calculator in question? I don’t think the Elka 6521 used a microprocessor in 1965. The Intel 4004 and others like it didn’t hit the market until 1971 or so.
That’s not a handheld calculator though.
I seem to remember that a very early calculator (HP?) did this in very few bytes of code so there be an easier way.
As a child (before calculators) I was taught a way of doing square root on paper that took some time because it was rather iterative. The reason it was iterative is that the base was different to the inverse power being calculated. ie – decimal would be a much easier approach if you wanted the tenth root. I later converted that technique to digital electronics and found that the base of 2 (binary) is perfect for calculating a *square* root. It was just bit shifts and addition. Both of which an FPGA would be very good at with minimal resources.
Newton-Raphson algorithm? Each answer gets closer to an acceptable result.
If number = N, and current guess = X, calculate new, better guess X’ with: X’ = (N + X^2) / (2X)
Small code doesn’t mean it’s fast. Newton-Raphson is a method of successive approximations and isn’t fast. As I said, you’re looking for a different type of algorithm for maximum performance on an FPGA.
True but there are advantages for raw math in FPGA to offset that.
1st is that you may have limited requirements for accuracy and you can tailor the logic to that.
The second is that unlike a CPU, FPGA can do most things in parallel so the over all number of cycles can be reduced dramatically compared to a CPU or even FPGA emulated CPU.
3rd is that most ball park FPGA can run fine at 300MHz or more and that is a lot faster than you can get from any common and small CPU architecture.
I’m not say it’s fast – but it might be the method Rob learned “as a child”.
If one is using 8-bit colors on input and output, a 256-entry lookup table is enough. On input it is trivial, but also on output you don’t need more than 256 entries if you are going to round the result to 8 bits anyway. For example perfect hash functions can be used for fast lookup.
Or in fact one could probably throw a bunch of autogenerated “if linear > 1234 then output 1296 then output <= 36; …" statements at the synthetizer and see how huge the logic would be. It might find a reasonably compact optimization of the LUT when the output is just 8 bits.
AFIK, the fastest way to do a LUT this big would be to use a dual port block-ram initialized with the forward and reverse look up tables. You’d use one port for gamma removal lookups and the other port for gamma re-application lookups.
A successive approximation method should also be just as quick if you pipeline it. I.e. CORDIC or binary digit-by-digit.
Which is better, depends on weather the design is limited more by logic or memory.
There’s a 32 bit square root in VHDL over here:
https://www.csee.umbc.edu/portal/help/VHDL/samples/sqrt32.vhdl
Cordic apparently does nearly everything. I just wish i understood it enough to trust I could implement it.
I guess one good thing I can say about ISE is the CORDIC wizard allows you to pretty much treat it as a black box and is pretty simple for things like this.
You could use my log/antilog Verilog blocks to do a SQRT in one cycle:
http://www.edn.com/design/systems-design/4424046/Single-cycle-logarithms—antilogs
I think i used your implementation in my undergrad project.
“Which is best” is an underspecified question. Best for what? Do you need to calculate this infrequently and can live with a 30 cycle latency? Are you going for one result per clock? What are the precision requirements? Are there other calculation that you need to do which might be able to share part of the computing machinery?
Looking at this particular application, where the video components are low precision, and need a high throughput but latency doesn’t matter too much, probably a piecewise linear lookup is fine – two small LUTs, one small multiply/add.
This is also a question of required accuracy!
In this case the accuracy can be really low – just to make the scaling look good. I guess you could trick with number of leading zeros (somewhat cheap in an fpga) or very small LUTs and some interpolation.
For example: y = rightshift(x , numberofleadingzeros(x)/2 )
But again the Barrel shift is expensive/slow and would use a multiplication…
Since they’re using a Spartan-6, why not use ISE/coregen to generate a cordic block? No implementation required.
Add a good size RAM / EPROM, and you can look up an 8-bit value simply by selecting a 16-bit address.
Remember, an FPGA is not a microcontroller. Unless you write a microcontroller on your FPGA.
What algorithm is best? Well that depends what kind of processor you’ve implemented on your FPGA.
There are a large number of other types of implementation between a stateless combinatory machine right though to a Turing complete machine so you don’t have to implement a micro-processor or micro-controller to do maths based things as all the math itself can be encoded without a CPU etc.
http://upload.wikimedia.org/wikipedia/commons/a/a2/Automata_theory.svg
Maybe this would be suitable in your particular case:
https://en.wikipedia.org/wiki/Fast_inverse_square_root
What a gem of a link.
I am about to write the kinematics for an arc delta robot to run on an 8-bitter so this is excellent and simple to implement.
Thank you [Al].
Look up tables in memory, as many others suggested. Quite an old concept to simplify logic:
https://en.wikipedia.org/wiki/IBM_1620
Not that it was asked for, but is it checked that the monitors have a gamma adjustment in the on screen display settings? If it has then your problem is solved.
I’m not sure why you do this in two steps instead of one for gamma adjustment. In two steps there’s a loss in accuracy twice instead of doing it in one step.
Resizing an image with gamma correction already applied does not produce a result image with the correct gamma.
The Spartan-6 has a 6-input LUT so you can check 6 MSB (D10 – D15) with just one LUT. If all bits are zero, input is < 2048, output is < 45
Beyond that, I'd want to know if (for example) the input range 81 – 99 is truncated to 9, or range 73 – 90 is rounded to 9.
Everything above 65,025 is rounded down to 255.