
In a previous article, we talked about the idea of the invariant representation and theorized different ways of implementing such an idea in silicon. The hypothetical example of identifying a song without knowledge of pitch or form was used to help create a foundation to support the end goal – to identify real world objects and events without the need of predefined templates. Such a task is possible if one can separate the parts of real world data that changes from that which does not. By only looking at the parts of the data that doesn’t change, or are invariant, one can identify real world events with superior accuracy compared to a template based system.
Consider a friend’s face. Imagine they were sitting in front of you, and their face took up most of your visual space. Your brain identifies the face as your friend without trouble. Now imagine you were in a crowded nightclub, and you were looking for the same friend. You catch a glimpse of her from several yards away, and your brain ID’s the face without trouble. Almost as easily as it did when she was sitting in front of you.
I want you to think about the raw data coming off the eye and going into the brain during both scenarios. The two sets of data would be completely different. Yet your brain is able to find a commonality between the two events. How? It can do this because the data that makes up the memory of your friend’s face is stored in an invariant form. There is no template of your friend’s face in your brain. It only stores the parts that do not change – such as the distance between the eyes, the distance between the eye and the nose, or the ear and the mouth. The shape her hairline makes on her forehead. These types of data points do not change with distance, lighting conditions or other ‘noise’.
One can argue over the specifics of how the brain does this. True or not true, the idea of the invariant representation is a powerful one, and implementing such an idea in silicon is a worthy goal. Read on as we continue to explore this idea in ever deeper detail.
if someone can figure this out, it would be a monumental step forward in computer technology
If we could stick a sensor in different areas of you brain during both scenarios, we would find an interesting pattern. The part of the cortex that is connected directly to the eye is called V1. As one would expect, the neuron firing in this area is changing rapidly and in completely different patterns between seeing your friend’s face up close and seeing it in the night club.
But a peculiar thing happens if we put the probe in the area of the visual cortex known as IT. The patterns are stable, slow changing and very similar to each other. Your brain has somehow identified the invariant representation of your friend’s face in the IT area, from the raw, fast changing data coming from the V1 area.
It does this through a hierarchy. Information flows up the hierarchy, and back down, as we will learn in the next article.
The Hierarchy
It has been long known that the visual cortex is laid out in a hierarchy. The neurons in V1 fire when certain line segments appear in the visual field. One set of neurons might fire if it sees a horizontal line, while another set will fire when it sees a line at, say, 45 degrees. V2 cells will fire when it sees shapes like circles, boxes and star shapes. It’s not until you get to IT, that you will see cells firing for things like a car, tree or face.
These are fast changing, low level patterns transitioning into slow changing, high level patterns. The cortex forms sequences of sequences, or invariant representations of other invariant representations as information climbs the cortical hierarchy.
This is our goal – to identify a tree, car or any real world object by forming an invariant representation of it, and doing so in a hierarchical form. This is not easy, and has never been successfully demonstrated before. If someone can figure this out, it would be a monumental step forward in computer technology.
Modeling [Hawkin’s] Theory in Silicon
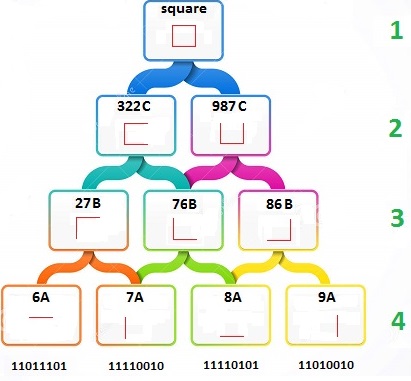
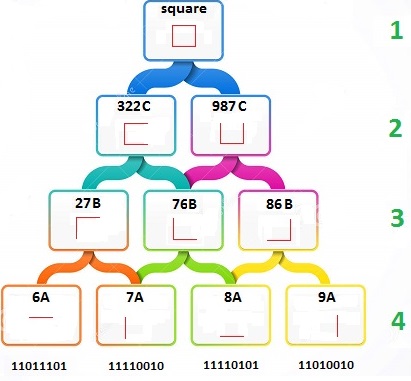
Each level of the hierarchy only has three jobs – to identify repeating patterns, assign these patterns a name, and pass that name onto the next level in the hierarchy.
The primary tier (like V1) sees the pattern 10100101 repeating often. So it gives it a name of 56a and passes only that name to the next level. The next level sees the pattern of 34a, 56a and 12a repeating often. So it gives this pattern the name of 866b and passes only that name to the next level up. That level sees the pattern 845b, 567b, 866b and 435b repeating often. So it gives it a name 7656d and passes it up. This process continues until a steady invariant representation is formed of the real world object.
Let’s work through an example of identifying a simple shape, such as a square. Imagine that whenever a horizontal line is in the field of view of our camera, the pattern 11011101 appears on our ADC. We see this pattern a lot over a period of time, as the square stays in the field of view. So we assign it the name 6A, and pass it up to Tier Three of the hierarchy. The same process takes place for the other three lines of the square.
It is critical to understand that the ONLY thing Tier Three sees are the names passed up from Tier 4. Now, Tier Three does mostly the same thing Tier 4 did – find repeating patterns, give them a name, and pass that name up to Tier 2. It notices that names’ 27B and 76B occur together often, so it assigns the pattern a name of 322C and passes it up to Tier Two. This process gets repeated until the invariant representation of the square is created.
Let this sink in, and in the next article we will explore the roll of feedback in the hierarchy, and how it can be theoretically combined with prediction to create an artificial intelligence.
None of this is possible however, without getting the theory onto hardware and into code. Now the onus is on you. How would you program an Arduino to implement this theory in hardware and software?














Very interesting series, keep rolling!
Whoa there don’t jump ahead so fast Will. V1 can’t work without edge detection (which you completely skipped). How do you distinguish a line from the background? Gabor filter? LoG? V1 is NOT a primary tier. Individual pixels have to be strung together into these components, already blurring the lines between V1 and V2.
—> “How do you distinguish a line from the background?”
Feedback. We will cover this process in the next article.
We’re assuming visual data as the only input for any system that implements this. I would suggest a more holistic (perhaps abstract) point of view where any input of data could be processed such as text, audio, any signal really.
I think so far this is a good intro to the subject. As an intro, it’s not really in it’s scope to deal with the nitty gritty details that NotArduino mentions.
And Albert, I’d argue it’s clearer to stick with a concrete example rather than going the abstract route from the start. It’s more interesting to read because a motivating problem is built in. And it’s easier to follow because it builds off of a problem people may have already thought about.
Rather good points, asdgasdg. I do understand the pedagogical reasons for having something concrete to consider. For me, however, the motivating problem is the least interesting part of this whole example. Potential application, on the other hand is extremely interesting (hence the abstraction I called for).
Though, to be completely fair I can’t really use a thing that has not been invented yet. (I think invented is the wrong word…)
I am quite interested in this series. I’ve been interested in hierarchical memory systems since I saw a talk from Oracle on it last year.
Really interesting, but I have some questions !
Your ADC gives different values to 6A and 8A, meaning it makes a difference between a ‘top line’ and a ‘bottom line’.
How can it do that ? Top and bottom have a meaning when speaking about a square, because squares have top and bottom edges. But your ADC doesn’t know (neither your IT yet !) -> isn’t the spatialization a problem here ? Your square is in fact 4 times the same pattern, how can you use your layers to spatially combine them ?
Or shouldn’t you find 4 different shapes to define you square ?
Good question [louis]! We would need to introduce some movement of the camera, perhaps similar to the way our eye’s seccade.
Saccade, new word for a familiar concept. Thanks for educating me.
http://en.wikipedia.org/wiki/Saccade
If successfully implemented, this would be a powerful pattern recognition tool. Pattern recognition is not intelligence. It is a component of intelligence, but not the whole thing. Automated reasoning systems are the biggest challenge right now.
Does a consensus about what reasoning is exist? I mean… we might now know when we have built an AI which is smarter than its creators. We’re very successful at building ones which everybody agrees are a bit dumb though.
One issue here is that the entire line of thinking about invariant representations may be well outside the scope of trying to recognize patterns such as changes in pitch, the relationships between a persons eyes and nose etc etc etc….. Consider that you can recognize a cartoon drawing of Obama that has no actual relationship to the way he looks in real life. Rather, your brain is drawing on an entire bank of cultural information that has nothing to do with visual data…… What I’m trying to get at is that you can for instance often see a painting or hear a song that you’ve never seen before and go “OH, that’s an M.C. Escher isn’t it?”. There are categories of “information” that your brain is using that are very fuzzily defined feelings and subconscious intuition at play here that simply can’t be broken down into something based on visual pattern recognition alone.
A photograph of a man with a gun and a grim look on his face and a cartoon image of a man with a gun and a grim look on his face may not convey the same feeling at all, and looking for relationships between line definitions etc to explain this is barking up the wrong tree.
Totally agree.
As an example, the brain could not understand spoken words correctly if it doesn’t know the language. Sometimes, even if the spoken language is the native language, a context (like a phrase, a situation, the speaker’s face, etc.) is also necessary in order to understand the spoken words.
Remember, THE MIND DOES NOT PERCEIVE THE REALITY, THE MIND PERCEIVE WHAT IT _THINK_ IT IS THE REALITY.
The whole concept of invariant representations seems too similar with the idea of classes (from object oriented programming), and the detection of common patterns already resemble neural networks.
I just hope the next article about feedback for invariant representation will not be just another twisted presentation of the old back propagation algorithm from neuronal networks.
Still, this article sparkle my interest, and I can hardly wait to follow the next one(s).
Good luck and thanks!
It has been suggested that caricature is actually taking the recognized portions and exaggerating them, making them hyper-recognizable. (See V.S. Ramachandran “The Tell-Tale Brain”)
Question from this end, what happens if your data starts at the other end and defines details out, to use as comparators, when trying to distinguish one face from another.
We will talk about this in the next article. Invariant representations will have to be “unfolded” and this info will travel down the hierarchy in an effort to help predict what is coming up.
Awesome series. keep them coming please! I love the thought experiment as it gets me thinking about this problem in a way I haven’t considered before.
So if recognized repeating patterns are past up the chain slowing combining other recognized repeating patterns. Can a predictive variable be introduced over time to see if any additional input changes what has been predicted as a complete shape. thus speeding up the process and skipping tiers?
Yes, prediction is key to Hawkin’s theory. Information will flow back down the hierarchy and is used to increase probability that what a tier is seeing is related to a larger structure. For instance, say we have 11011101 set to a horizontal line. But now imagine a pattern comes in of 11011100. Prediction from higher up in the hierarchy can change that pattern to 11011101.
We will get deep into this next article. Stay tuned!
Worse. Consider how you can recognize voices. Including mimics (Rich Little might be before your time). This is less intensive than visual but also works.
There are specific pathways for “faces” and “voices” which don’t apply to something more generic, e.g. trees or musical instruments.
Just thought I’d say thank you for this series, and please keep it going. I’m foreseeing a long discussion that will end up with an algorithm being created :)
This looks for me like a artificial neural network(aNN). I am working on this for some time.
Atm, i am trying to use the system theory (like convolution integral) to describe the system mathematical. Maybe u can leave me a Feedback about this approach. (Sry for my english)
i think part of the problem/difficulty could be assuming we’re line mapping to reality and also that it’s not done as a concurrent processes.
what if you assume the brain also has stored light maps or reflectivity maps, (lighting direction actually does make people harder to recognize) color maps and texture maps and then mapping the lines and shapes to them. and we probably have movement maps too.
i mean if it was me, i’d start by checking shape inferred by reflectivity, (because this is laws of physics based i assume it’s hardwired) then movement, then color then shape or pattern if i hadn’t already arrived at an answer, then continually cross check.
also, it seems like all of our brains processing is assumption based, like when people driving hit someone they always say “she came out of nowhere” which really means they weren’t expecting it and looking for it. likewise if you make plans to meet up with a friend somewhere it will be easier to find them than if you both happened to go to the same place.
so with your pattern detection process i’d guess you run multiple patterns side by side and cross check against each other. the system could work by checking against a confidence system and once it got close enough it jumped to a pool of answers and worked backwards from there to prove itself wrong.
the process could be akin to a look up table unique to each process, but keeps an indexed database to check which matches in one you have linked together. so like, if you were meeting a friend will red hair curly it would only check that against the other options that you linked in the past. so your brain wouldn’t be looking for a star out line for their face or green skin, unless you checked against the halloween table. :)
i think the real difficultly in the modeling would be the database linking and the rules of your assuming code. i mean human assumption code evolved based on survival in reality so it’s pretty finely honed to do so. :)
ok, but I think the example is bad, you can put up an image with dots in the 4 coners of a square and a person can pick out the square even tho its not there. The example also fails on conditioning of where the horizontal and verticle edges are relative to each other. 2 things seem apparent to me, first, that the human system reffers to points and angles to recognize things (which I think is only partly accurate) and that there is a rendering process, and some things cause a fault in it.
http://www.mobile-pedia.com/images/thumbnails/illusion_Spinning.png