[Mark West] gave an interesting presentation at last year’s GOTO Copenhagen conference. He shows how he took a simple Raspberry Pi Zero webcam and expanded it with AI. He actually added the intelligent features in two different ways: on in the Amazon cloud and another using the Intel Modvidius NCS USB stick directly connected to the USB. You can see the video below.
Local motion detection uses some open source software. You simply configure it using a text file and it even handles the video streaming. However, at that point, you just have a web camera — not amazing, nor very cost effective. However, you get a lot of false alarms with the motion detection software. A random cat walking past, clouds, trees, or even rain would push [Mark] an email and after 250 alert e-mails a day, [Mark] decided to make something better.
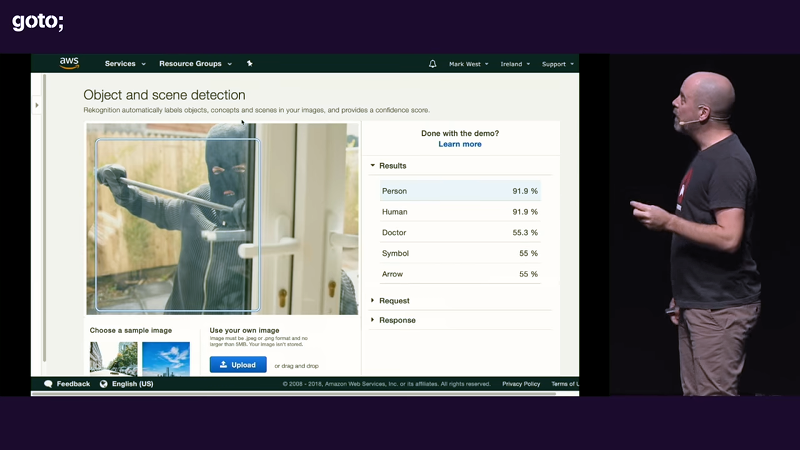
[Mark’s] first pass was to use Amazon’s Rekognition service to process video. This allowed the camera to actually be smarter about what would trigger a detection event. In particular, the new camera only alarms if Rekognition sees a person in the frame.
This worked well, but there’s a cost associated with using a cloud service in this way. You can probably get a free trial and there’s some level of free usage. Eventually, though, you’ll wind up paying per image processed. With [Mark’s] four cameras, he wound up paying a little less than $30 per month. However, costs could increase if he sent more pictures to improve recognition.
Of course, it is possible to do more sophisticated processing without the cloud. The Pi isn’t the best platform for doing neural networks, but [Mark] found the Intel Movidius Neural Compute Stick (NCS). This USB device offers advanced neural network processing and lets the Pi offload most of the work to it. Of course, that increases the upfront cost but saves on future cloud fees. It also processes all frames, not just frames that show changed pixels. [Mark] noted that Google’s Edge TPU Accelerator could do the same task if it would ever actually go to the market. (Editor’s note: yesterday.)
We wondered if [Mark] could have made his own private cloud where all the PIs sent their data to one node with NCS to do the processing. We’ve done our own take on using the NCS. We also have looked at doing object detection using TensorFlow.














I like, how the person in the picture is a doctor with 55.3% certainty.
But I always wear a ski-mask and wield a crowbar when performing surgery. Don’t you?
Percussive… medicine?
Better than Rapid Unplanned Disection I guess.
Retro Phrenology
He may be breaking into your house… but look… there’s a 55.3% chance he’s a doctor!
He’s coming for your organs!
Anyone have an idea on Intel Movidius Neural Compute Stick performance vs Google’s Edge TPU for tasks like this (recognizing what’s in an image)?
The Movidius X hardware is great. The raspberry pi > USB > Movidius X configuration introduces a CPU-bound bottleneck for processing video. Movidius X USB stick is better for easily connecting to a desktop or laptop device.
So, to answer your question, the Google Edge TPU dev board and the Google AIY Video (available at Target!) products should perform better than the Movidius X USB stick connected to a raspberry pi via USB. I have the Edge TPU dev board on order from Mouser and I expect to be testing sometime next week.
And they still haven’t figured out international availability for the AIY Vision Kit.
I’d like to sell a device that counts chickens inside a coop. Is it feasible to send the video from Pi Zeroes to Tensorflow my own server and expect reasonable accuracy in counting? Or does that require using a pre existing cloud service?
hi!
have you try it in wolfram Mathematica? it came pre installed in raspbian and processed the data locally
https://www.wolfram.com/raspberry-pi/
https://demonstrations.wolfram.com/CountingObjectsInImages/
here is a short demonstration of image identify from configuring the camera to execute the example code:
https://hackaday.io/project/163578-easy-raspberry-image-object-identification
greetings!
Cool thanks!
Cool thanks!
“you get a lot of false alarms with the motion detection software”
Depends how you configure it.
There should be options for the size of area to monitor (not whole frame), the amount of change in that area, the rate of change and the change in pixel threshold – call it brightness or color
There are also inbetweens not just jumping from pixel change to object recognition. Looking at object sizes within a frame with some basic maths to setup the FoV sizing of a static camera. You can exclude cats, clouds, rain, trees, and even vehicles because people are of a certain size. This is what companies do now (and for a decade or so on crappy hardware) before the AI bandwagon came along
I’ve seen lots of attempts are object recognition in CCTV. And most of them frankly suck. The same false positive result problem for for different reasons.
it’s a case of application and environment of course.
But if you want to recognise people in a scene near the road, what do you do when a bus goes past with a person on the side in an advert?
You’d combine object recognition with the knowledge that few people can move at 20kph
Or you use thermal cams for detecting people where no people should be
Thank you for saying it. This is another example of a solution looking for a problem which AI is the king of doing.
It’s clear his system has false positives, hell it’s 55.3% confident the thief is a doctor and this is the “good” example pulled out to highlight success. As you show there is so much more info he could have given a motion detector to properly have it only hit on objects that are a plausible threat, only 4 pixels in a group moved, well it’s probably not a human breaking into your house vs a leaf rolling along the screen. AI has it’s purposes but please let’s not look at devices that already exist and have X% success rate, slap AI on a crappy implementation and go look I have X-n% success rate that’s way better then the near 0 success rate I got with my crappy version (please ignore all previous work on this effort that didn’t use AI).
” [Mark] noted that Google’s Edge TPU Accelerator could do the same task if it would ever actually go to the market. (Editor’s note: yesterday.)”
So when are security cameras getting neural processing?
My CCTV from at least 5 years ago does object recognition (claims to do stuff as far as ‘person wearing glasses’ but I’ve never tested it as the software is terrible. I understand that these systems can ‘learn’ but I wonder how much learning is required, once you can identify an object reliably anyway. I.e. do you need a compute unit for the life of the system, or for a ‘short’ period of training, at which point you can hand off to a cheaper ‘non-learning’ model handling subsystem ?
As with most of this AI / ML stuff the hype is quite a way ahead of the reality and there’s a lot more wrinkles to it than you’d like.
Also, object tracking from a moving platform is hard – are those pixels moving because it’s moving or because you’re moving or both? All the recognition engines out there (that I’ve seen) operate purely on the image data – which kinda by default forces the assumption the camera is a fixed device, so there’s no easy way of telling them “by the way, you’re tracking across the frame at 5deg/sec so subtract that from the motion of the image”
Do something controversial like bolt lights to the camera and all of a sudden you’ve got a device which can and will literally chase its own shadow. Ask me how I know all this ;)
Nice project, This would work great on Google AIY vision without the NCS.
I have a Raspberry Pi doing facial detection and facial recognition using python’s face_detection and opencv. It can crank through about two frames a second without any acceleration. I think if I used better multiprocessing and regions of interest I could improve it to at least 4 frames per second.