David Letterman made the top ten list famous. [Creel] has a top ten that should appeal to many Hackaday readers: the top 10 craziest x86 assembly language instructions. You have to admit that the percentage of assembly language programmers is decreasing every year, so this isn’t going to have mass appeal, but if you are interested in assembly or CPU architecture, this is a fun way to kill 15 minutes.
Some would say that all x86 instructions are crazy, especially if you are accustomed to reduced instruction set computers. The x86, like other non-RISC processors, has everything but the kitchen sink. Some of these instructions might help you get that last 10 nanoseconds shaved off a time-critical loop.
There are also interesting instructions like RDSEED, which generates a real random number. That can be useful but it takes many clock cycles to run, and like anything that purports to generate random numbers, is subject to a lot of controversies.
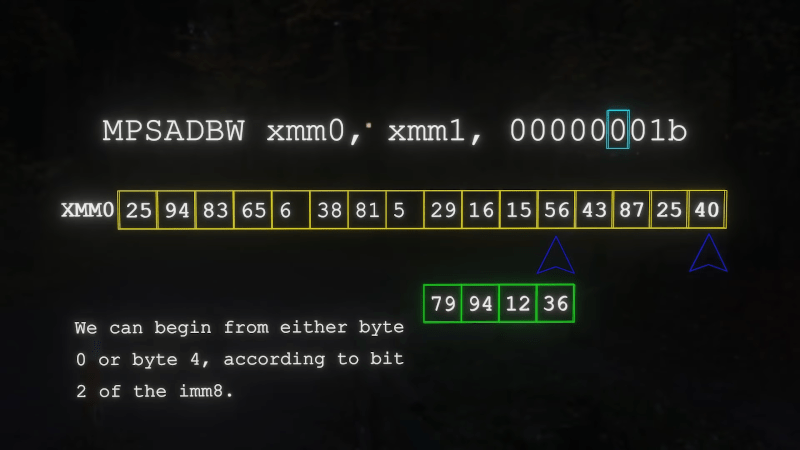
Our favorite, though, was PSHUFB. As soon as we saw “Mr. Mojo Risin’!” as the example input string, we knew where it was going. You could probably go a lifetime without using any of these instructions. But if you need them, now you’ll know.
If you really want to learn modern assembly language, there’s plenty of help. We occasionally write a little Linux assembly, just to keep in practice.














Some actually interesting instructions in here that seems to have just been created on a whim by someone who had something very specific to accelerate…
Though, the string instruction on the end seems fairly useful to be honest.
At times I wonder if the architectures I cook up as a hobby is crazy, but at least x86 is more crazy…
None of these were created on a whim. Most of the crazier ones appear to be hardware implementations of portions of an encryption algorithm. AES uses #8 and #2(?). Some higher level math uses others. It’s all in there for a reason.
Stuff like byte shuffling and redirecting outputs to specific packed bytes for the SSE stuff are also almost certainly “free” (or better-than-free) functions. You already need multiplexers to handle loading those from individual registers in the first place – so pulling the destination address from the instruction rather than a constant doesn’t cost you anything, and depending on how it’s actually implemented it might actually cost you less than hard-wiring the destinations.
If you actually look at the SSE instruction set and notice which instructions are single-cycle versus multiple cycle, it’s usually not that hard to figure out how the actual hardware works. Not sure if it’s still true, but at one point a horizontal-add of packed integers (so if you have data stored like x0/x1/x2/x3, summing all of those) was much slower than a vertical add (if it was x0/x4/x8/x12, then x1/x5/x9/x13, etc.) – which of course just implied that the microcode converted that to “move these to shadow registers and do a vertical add.” Instructions that take a bunch of clock cycle (so microcode converted) likely exist to improve code density.
Honestly I wouldn’t be surprised if a bunch of the instructions were because someone realized they could do something for free. That happens a bunch in processor design: you have some general operation, and then realize that something you would normally hard-code as a constant you pull from unused bits in the operation. Poof, new instruction. Sometimes it’s totally unintentional, too.
The “weird instruction” part of x86 gets a bad rap because of the “oh, this is why x86 is so hard to design!” but that’s not a good way to think about it: it’s better to think of x86 as a *compressed* instruction set. Decompression does take some silicon (the microcode plus its associated logic) but that also gives a benefit in that the instruction bandwidth is increased.
Which is, of course, the reason why even “true” RISC architectures like ARM or RISC-V introduce forms of instruction compression, but for the longest time x86 code density was really, really high. But I’ve always been curious if the trend back to RISC architectures was just due to processor speeds hitting a wall and memory bandwidth/cache sizes catching up. Back in the 2000s, memory bandwidth was so limited and cache sizes so relatively small that keeping code cache-size limited was a huge benefit.
Yes designing new instructions when one sees a need for it is fairly common.
x86 just has 5 decades worth of add-ons by now, so it is kind of expected that it looks a bit bloated from afar.
The advantage of CISC in regards to needing less code for the same job is a fairly major advantage, and one that I think will keep CISC architectures on the table for a long time into the future. (Considering how even ARM largely is CISC these days for the more performance oriented implementations.)
RISC architectures are generally having the benefit of “better power efficiency” but even that isn’t always the case to be fair, another major advantage is less resources being needed for a given core. (Though, not going to repeat my comment I made back at: https://hackaday.com/2020/08/12/degrees-of-freedom-booting-arm-processors/#comment-6270448 )
Though, it is fun to see how architectures evolve over time. Be it commercial ones, or more theoretical ones.
One architecture I have been developing started out as a simple RISC architecture with around 25-30 instructions. But over the years it has seen additions and alterations to its instruction set, enhancing its performance in various tasks. Eventually culminating at a point where a rebuild were in order since the core idea of how the architecture worked had migrated to something new, before setting of onto a new road of gradual improvements. Then I during the last year started rebuilding it again…
So the concept of “in these applications, an instruction/feature doing X would be wonderful to have.” is very familiar.
And honestly how I expect how x86 has accumulated as many instructions as it has.
Great. Do you know why you don’t use these? because if you are coding in assembly, while you can check the processor type using specifics sets of instructions, given X86 and x186 and others will give themselves away on how they execute opcodes. In the end, if you are trying to put something into the field you code for the most common denominator. For years it was 8088, with conditional branching for faster instructions on a newer processor. Things like aligning words on para or segment boundaries was a common way to increase speed as were other tricks of the trade.
In the old days “C” wasn’t fast enough for things like screen handling, that changed when optimizing compilers came out, although many companies writing software still went assembly for the critical sections – like encryption for example, or again video, because writing screen using BIOS routines was much slower than writing directly to video memory. Writing something with an uncommon instructions just means you have the potential to have pieces of software that bug out on a given platform. Extended memory I remember put a curve ball into handling things since you needed a handle for memory blocks instead of actual segment addresses, which you then needed to request from the memory manager.
We in the U.S. are arrogant in that part since we basically forgot the rest of the world has “compatibles” that ALSO run pieces of software. I compare this akin to when DBCS came out under windows, instead of a standard ASCII set of 256, you now had both multiple representative characters for video, and data files with 2 physical characters per logical byte. Really screwed up us “terminal guys” who were used to one-to-one byte handling.
Helped multi-language stuff, but really made a mess out of existing products that had to be re-written. Remember, many products in 8088 DOS were actually ports from the z80/8080 CPM systems.
Almost nobody hand writes x86 assembly nowadays, so I fail to see how that is relevant to x86 instruction design. It’s been over two decades since Intel had the idea of designing ISA’s specifically to be leveraged by clever compilers rather than by humans, and while Itanium ultimately was a failure, the philosophy still had a major impact on x86.
Intel themselves has a software services group, who specifically work with customers on application enhancement. Usually this is big data, scientific computing, super computers… My point is, they definitely hand optimize assembly. Heck, even the BIOS teams hand optimize a lot of the boot up routines, because you only have limited space to store the BIOS in, and bootup needs to be FAST (or normal people start complaining)
I seem to recall including “almost” in that statement. I too am able to list exceptions, but it does not invalidate my point.
Since UEFI, there’s really no need to hand optimize the BIOS, as most of it resides in the EFI partition on disl.
“the percentage of assembly language programmers is decreasing every year”
“Almost nobody hand writes x86 assembly nowadays”
Yes I also assumed that. However, on the TIOBE Popularity Index at https://www.tiobe.com/tiobe-index/ for February 2021, I was surprised to see that assembly language has risen to position 10.
Obviously that’s not just x86 assembly language, but I’m sure there’s a bit of that included.
There still is a huge installation of PC’s outside of the U.S., I guess it’s relevant to those that still do. Like perhaps myself for example. I have machine and terminal emulators built for systems and terminals that don’t exist anymore or don’t have an equivalent, and given the effort it would take to replicate such a system under Windows messaging, I’ll pass.
In fact, until 1995, I worked on hundreds of server based and actual NIC adapter card assembly programs and redirectors, so while that’s a long time ago – those installations still exist in some of the old companies because there is no equivalent under windows in many manufacturing areas. I actually had a company running a YAG laser engraver for steel running under OS2 in 2010 – no, I’m not kidding.
I still occasionally fire up an x86 assembler.
Well, hobbyists of the retro computing scene still do use assembly or machine language.
So do programmers that write homebrew games for 8/16-Bit systems..
People that do *hack* stuff with a hex editor also have basic knowledge of either of them.
Last, but not least, writers of emulators know a lot about assembly, too.
As well as people who tinker with the bare metal. It always depends on the point of view, I believe.
Well, that ‘simple’ 256 character set sure beats the two byte character set(s) we sometimes have to deal with today!
Enjoyed the video. Never did use any of those instructions back when. Of course never did write a complete application in assembler, but did help maintain a Z-80 assembly application running on a SCADA RTU. And of course some video routines and interrupt drivers….
+1
> two byte character set(s)
Heck, UTF-8 can extend up to 4 bytes in length if you’re in some particularly gnarly code pages.
6 bytes, apparently
https://www.joelonsoftware.com/2003/10/08/the-absolute-minimum-every-software-developer-absolutely-positively-must-know-about-unicode-and-character-sets-no-excuses/
While the encoding supports up to 6 bytes, it’s artificially limited to 4 bytes since Unicode only goes up to U+10FFFF (because that’s all they could fit in to UTF-16 with their surrogate pair scheme).
Of course, a glyph that is displayed on screen could be composed of multiple Unicode code points using combining characters or zero width joiners. For instance, 🤷🏼♂️ takes up 17 bytes: f09fa4b7f09f8fbce2808de29982efb88f (at least that’s what https://onlineutf8tools.com/convert-utf8-to-bytes spit out at me) IIRC it’s made from shrug emoji + male + skin tone with zero width joiners between them.
This is why optional extensions suck. If you want to add something, bump the version number and make it mandatory. All those enterprise design by committee standards do this crap, and it since up not being a standard at all, it’s a process used to design custom standards.
For those of us who don’t upgrade entire companies worth of hardware every year based on specs for specific apps.
Even things like WiFi do it, with their automatic TX power and things like that which aren’t mandatory.
And the worst part of optional features is that someone always winds up ignoring them and making proprietary alternatives, creating fragmentation.
Just pick the few best open alternatives and specify supporting at least one. Nobody needs 66567643 different choices of cipher in their SSL. There’s like, two or three new major trusted ciphers a year at most.
This UNIX build everything from small bits to fit one application stuff is way over hyped.
But you can bet the Manager of the Year you work for will want that 66567644th one…../s
“We in the U.S. are arrogant in that part since we basically forgot the rest of the world has “compatibles””
Umm… the only companies that make x86 chips for PCs are AMD, Intel, VIA, and Zhaoxin. The embedded x86 chips are basically 486 chips. Your complaint may have been valid in the past but right now, it’s a solid bet the code will work flawlessly.
My point is that there are a LOT of machines out there that still run these old silicon designs, and it’s not really a complaint – more of a notation that we are used to the largest and fastest to do development for example, but the system you develop for is usually the opposite of that, video is an example. We always designed the GUI at 800 x 600 because there were machines in plants that still had 15 inch screens. I know, makes no sense – But companies are hesitant to do capital expenditures on items that still work in harsh environments, especially small companies.
“In the end, if you are trying to put something into the field you code for the most common denominator.”
It’s practically zero-cost to determine processor type and link in the appropriate libraries at runtime. Storage is so cheap at this point it’s not even a big deal to just have all of the functions available.
“Writing something with an uncommon instructions just means you have the potential to have pieces of software that bug out on a given platform.”
You *always* have the potential for software to bug out on random platforms, even if they’re using the exact same instruction set. Library mismatches, thread-safety issues, hell, even locale settings. Architectural features are actually pretty far down the list.
All true, though it’s nice to reduce the bug part of the equation. Dynamic Runtime loading under Windows is of course the best thing, but under DOS and other systems that just wasn’t done a lot, or at least not by any company I worked for. More likely the program was compiled for a specific architecture and sent as such, with chaining to specific wholly enclosed programs for portions of the entire package. Clearly runtime loading is preferred if possible. But there is still a whole lot of code that can’t use this method – like boot loaders, embedded systems, etc.
I recognize that my background is one that most People don’t have, mainly Manufacturing, which deals with a lot of old equipment and things like L2 machine controllers & such. They need to interface somehow with the higher up systems and require some more interesting solutions to eventually get data into reporting systems which are used to schedule all of the work – so in real time. In large companies it was always a problem with equipment lagging behind the upgrades required to run software – and 90% was custom written legacy system stuff.
In the end there were ALWAYS machines somewhere that wouldn’t work with a new distribution since department Managers didn’t like to use their budget on computers if possible – so small storage and minimum memory. Or, systems that had custom hardware cards for interfacing with large machines that don’t have the ability to upgrade to a newer machine. I saw that a lot.
Think it’s safe to say if you’re programming x86 on a system that doesn’t have runtime linking you’re *not* performance limited.
I would argue just the opposite. The very reasons you use assembly is because you are trying to squeeze that last cycle out of the processor for speed, or that last few bytes so it fits on an EPROM. We think of these things all being PC’s, given the world of components like LED bulbs and routers where you can roll your own with, I would say the People that like to modify them most likely would use assembly/machine code. Even hand assembly of machine code isn’t out of the question these days. Many discrete devices still use these processors or a version of them.
But I will give you another reason, In the last 40 years I have found the People best suited for both trouble shooting hardware and software issues were those that could actually understand the machine at the very basic level. Those that can’t are just average programmers – they never truly understand things, or why they work the way they do. Basically, they are just glorified library managers, using routines other People programmed, before they were born in some cases.
https://datasheets.raspberrypi.org/rp2040/rp2040-datasheet.pdf
Page 340.
Table 376. PIO instruction encoding
I don’t think it’s really fair to say that assembly is going completely away. Here are 9 assembly commands you can use in 2020 Raspberry Pico hardware right now that are actually pretty incredibly real time and useful.
I don’t know who you’re trying to argue against, nobody has said it’s going completely away.
Maybe not completely away but the insinuation that assembly is turning into things like COBOL or Y2K style programming endeavors or insinuating that “that the percentage of assembly language programmers is decreasing every year” in a material manner is something that is insinuating things that are only partially accurate is the issue. Technically more programming languages come out each year and technically some become less important but assembly is still how you program most all computers, you can just do it with newer and more automated and easier to program methods such as Python or MicroPython and so on to make it so the degree and complexity at which these need to be written is materially easier and faster but has some downsides though too.
I guess the main point is that their quoted above statement was more of a marketing style statement that lacks a number of details than really being an accurate statement was the main issue.
Plus, well, RPi microcontrollers now support some limited assembly that you can program directly makes it a new approach that you can optionally take which is both relevant and highly detailed and extremely low level as well which has merit for a broad level use that it lets you do directly in hardware as a fairly new concept compared to things like an Arduino.
The same team that designed the x86 instruction set had to be involved in creating the PL1 language…lol
Anyone who trusts the opcode to generate true random numbers is a fool…
Is it any wonder why x86 silicon is so effin huge.
x86 silicon is like something you might find on a derelict ancient alien spacecraft and be rendered speechless that it could actually control the ship… you would be left to ponder just how strange and yet wonderful those aliens must have been.
I admit that I have actually used most of these instructions.
Bob Feg – founding member of the OCD Coders Alliance
To be fair, at least on AMD 64-bit x86 CPUs, the weird legacy opcodes and infrequently called but necesary opcodes called macro-ops (MOPs) that decode via microcode LUT into a series of native micro-ops. More frequently used opcodes are ‘fast-path’ which skip the microcode lookup and are minimally fixed up into a single micro-op.
Long story short, very little silicon is wasted on supporting legacy opcodes. Most of that waste comes from supporting all of the other legacy x86 stuff, like IO space, MSRs, GART, etc. Still, those make up a negligible amount of die area at modern process nodes. The majority of a modern CPU die is dedicated to caches and IO.
Meh, here is a summary of the video SSE instructions are weird. Im sure AVX is even worse. You want really weird try ia64 – we have 3 different NOPs because reasons.
3 different NOPs ? not even new. The Saturn processor inside the HP48 (and others) has 3 different nops, they were different in length two: 3, 4 or 5 nibbles. Thy where actually jumps to the next instruction.
Even quite ancient and small ISA’s have multiple nops; it’s an inevitable consequence of designing your opcodes in a structured manner for efficient decoding. When you can freely select source and destination registers you’re going to get a move X to X instruction for each register in your system.
Yeah, and in the PSHUFB case, I’ve actually known about that instruction, and used it in the past.
The N64 had a coprocessor called the Reality Signal Processor (RSP). For all intents and purposes, it was a MIPS R3000 (or thereabouts) modified to execute solely out of its internal caches (4K for instructions, 4K for data), with a DMA engine grafted on, as well as a 128-bit vector engine hooked up in the COP2 space of the instruction set.
The relevance here is that the 128-bit vectors it operated on were comprised of 8 16-bit elements, and each instruction tended to be able to select one of 16 possible permutations of the source elements, in order to make things like swizzling more convenient.
When emulating it on x86/x64, it helps to map the RSP’s vector functionality as close as possible to sequences of SSE-class instructions. The problem is, no version of SSE had an arbitrary (16-bit)-word-permute instruction. It only had instructions which could permute within the four upper 16-bit words or the four lower 16-bit words. Given the fixed permute modes of the RSP, this won’t work.
Enter PSHUFB, which allows you to emulate exactly the desired permutation of the RSP source register in one instruction, albeit with twice the granularity as is absolutely necessary.
Someonein Dr. Dobbs analyzed 6502 programs, and revealed a handful of instructiins were used the most. But I’m not sure he analyzed that many programs.
Motorola did analyze a lot of 6800 programs as preliminary to designing the 6809. To get a feel for what was used, but also what got used a lot.
I know I tended to use the same subset of 6502 instructions.
The Z80 improved on the 8080, but some of it seemed to go in the wrong direction, instructiins that made writing code simpler, but were too specific to be a lot of use (and used up a lot of clock cycles)
No wonder x86 CPUs are so hard to design…
A week or so ago, I started designing an ISA, mostly for fun. It’s RISC-ish, but now I see this and some of these instructions look like they might be useful once in a while. On the other hand, I want to keep it implementable by one person. And RISC tends to be more efficient than CISC, which counters the lack of specialized instructions like these. But I was thinking about instruction set extensions already, and the extensions could then be implemented if desired, or omitted to make a CPU design more tractable (as with RISC-V).
I also thought of a feature that might make some obscure instructions unnecessary: programmable reflexes, where you can tell the CPU to perform certain actions every time certain conditions are met (register contents, other operations just performed, maybe other things). Then you don’t have to tell it to do whatever operation(s) every time. It could even be used to implement (serial) SIMD without SIMD instructions, I guess, as long as there’s some stop condition.
I like the idea of “programmable reflexes” a lot!
This is nothing new, the Z80 CPU (which has some Intel 8008 heritage) had a lot of undocumented instructions (I want to say around 600 from memory, but I am recalling back to the early 1980’s and it sounds like a very big number)
It doesn’t sound like these are undocumented though – they’re just part of an insanely huge instruction set.
There are definitely undocumented Z80 (and iirc 6502) instructions, but I think they’re mostly just artefacts of the instruction decoder, not intentionally secret.
Good video though. Prior to this, my most hated instruction set was 68k. Now it’s x86 – just about…
Kinda reminds me of the coffee machine at work a long time ago where it was possible to get fizzy coffee out of it once you’d worked out how it encoded the request numbers :-)
Hah, being a Z80 person I had a similar thought… and then I went and checked it.
https://clrhome.org/table/
All of the red instructions are undocumented. Yeaaaah, that’s a lot. Those damn IX/IY prefixes!
Note that “undocumented” doesn’t mean secret *at all*, just that they’re not part of the explicit ISA and the manufacturer could easily change how they behave in a new revision of the silicon and still be 100% a Z80. If you use an undocumented instruction, you can’t expect full compatibility.
Same situation with the original NMOS version of the 6502, as I recall. A handful of the undocumented instructions ended up having different effects, or were replaced by actual instructions, in the 65C02.
That’s a nice link there pelrun, thanks :-)
For those into hardware details synced with instruction sequencing…
When I did an engineering thesis on electronic fuel injection with transmission control interface I built an LED/keypad center console into a 1972 Ford escort which used a Z80 & ran CP/M as its primary task (rs232 terminal) but, switched to cycling fuel injectors on the NMI to output PWM. Limitations on project time and operation meant I couldn’t do floppy io when engine running. I looked closely at io speed and discovered a side effect of the Z80 OUT instruction specifically which used C as pointer to 8 bit io address with side effect B register expressed on upper 8 bits of address bus :-)
Ie. By first latching the io decode type to use the data bus as the (temporary) io address I could read the 16 bit address bus as the data so with the OUT instruction get BC registers output as a single cycle 16 bit word. Once the hardware did that it latched back to using the conventional address bus for io address and back to data bus for data. Given I only needed to point to one io address then the data bus could be ignored focussing only on the BC registers appearing on the address bus. Ie two instruction sequence with hardware device :-)
My project supervisor back then Ken, puzzled – LoL
I could have rigged up hardware to do block high speed 16 bit parallel output but, beyond the projects utility. This was more interesting than memory mapped io and a lot of fun, principles of microprocessor forensics – leading on to other more interesting stuff ;-)
Mentioned this on previous hackaday link re z80 but, added bit more detail here.
Oh geez the 16-bit OUT thing. Don’t get me started :D (I’ve had arguments with people who insist it was entirely intended as a 16-bit IO bus just because it’s documented that B is on the upper 8 bits… even though that’s a really weird way to word it, and B gets modified by OUTR…)
Sneaky trick using BC as a command bus, but hey, when you control the architecture of the rest of the system it’s entirely up to you how you interpret the bus signals :D
Interesting post and comments, thanks :-)
I wonder if in the future some enthusiastic hardware level designer, perhaps with (out there advanced) quantum computing hardware, could be motivated to design the then ‘QM’ FPGA equivalent implementing x86 instructions on who knows what, just for fun (rhetorical question, though I welcome observations) ?
Hmm, provokes the question:
One wonders if the kooky way the universe seems to work (so far) with all the discontinuities could have arisen from some superdimensional high order being toying with their version of a FPGA offering space-time and QFT applied as an immense genetic algorithm with all life a massive dynamic work in progress, heck with each “observer” a well placed solipsist expressing themselves ;-)
What if we’re just the entropy generator for the crypto in his credit card chip? :-D
The VAX Instruction Set had a POLY instruction for polynomial evaluation. The origin of which could be tracked back to Mary H Payne, the floating point maven.
Vax is even considered “VCISC”… which made the last generation, running at 100MHz (mod. 4000/96A for example) a very smooth experience, considering other machines available at that time
When I was involved with “larger” computers, it was noted that the first three off the assembly line went to Government organizations, to wit: nuclear bomb modellers, weather modellers and an agency that reads other people’s mail.
Sometimes, one or more of these organizations would request that certain instructions be included to make their lives easier. Perhaps this is the case with some of the instructions that seem not to have a reason to be there.
When you have a supercomputer made up of thousands of x86 chips, having these instructions might make more sense.
“You have to admit that the percentage of assembly language programmers is decreasing every year, so this isn’t going to have mass appeal, but if you are interested in assembly or CPU architecture, this is a fun way to kill 15 minutes.”
Those who write compilers need to have a good knowledge of the target instruction set. How many instructions are left out by the best compilers?
ASSembly is slow. Java is fast. Nothing is faster than Java. All you need is a few cores, as little as four, just a bit of ram, as little as 8GB, and just a few GB of disk space as little as 20Gb for a few helper libraries, a few java JRE versions, and some patience.
Hello world in ASSembly takes forever to write. Hello World in java takes 1 min to write, and as little as 4 mins on a quad-core system to execute, and it gets faster every iteration!
ASSembly requires hard stuff, like pointers, memory management, CPU instructions, byte alignment, etc.
Java takes care of all that crap, all you need is imagination! Anyone can be a programmer, anyone can write fast code, that runs anywhere!
No wonder ASSembly programmers are a rare breed. Slow, Machine Specific Crashy Code.
*golf clap*
I never wrote with an assembler past the 8086/8088, and the complexity of the modern versions is astounding to me.
A comment about the 8080 vs the Z80: it’s true that the “new” Z80 instructions weren’t really any faster then just doing the 8080 code, this was INCREDIBLY valuable at the time with 64K limitations and also the high cost and iffy availability of UVEPROMS.
After checking out modern x86 instructions, one is tempted to call RISC PIC16 instruction set beautiful.
The assorted PIC16 instruction sets may be *small* but they do not meet the generally accepted criteria for (e.g. ARM, MIPS) “RISC”. And “beautiful” they most certainly are not.
Source: spent years working on compilers for them.
My condolences. I feel your pain.
Before optimizing compilers came out, I’d compile C into assembly and then go through the code eliminating redundancies.
my least favorite instruction is CKSM on z/Architecture (nee 360). you’re flipping through this great reference manual that IBM provides, and it’s got everything you need to know about each instruction. most instructions take less than a page, two pages at the most. and then 80 !*$@ pages of CKSM describing all the AES variants. there’s a handful of other crypto-oriented instructions but 80 pages for CKSM really takes the cake. destroys the utility of the beast as a reference manual. makes me wish i had it in hard copy so i could cut out those pages.
and obviously the function should be performed by some sort of co-processor or I/O board…which of course it is because IBM’s embraced every different solution at some point over the years.
I my z/Achietecture Principles of Operation manual the description of CKSM is only 3 pages long. It’s CIPHER MESSAGE which is much longer (66 pages).
With clock speeds being what they are and the huge quantities of storage, who needs to shave milliseconds any more?
Almost everyone working on the lower layers in particular.
Add a millisecond (or even just a few wasted cycles) to every call of these common elements and it adds up rather rapidly – even more so as many of the lower level process have to use other low level processes that might use the same other low level process multiple times till it reaches the goal, so the program sitting on the top using them all is stuck waiting for many millisecond delays all the way down..
Also just because the hardware is faster doesn’t mean you should throw out attempts to make the programs run efficiently, its just wasteful (portability and modularity being other considerations that can justify a less efficient methods).
Ask the computer to do something a million times, except each iteration is slower by a millisecond than it could be… and you’ll be waiting for fifteen minutes extra.
No matter how many Ghz you run the CPU at, milliseconds don’t get any shorter.
The big stock trading systems, aerospace, still a lot of places where milliseconds are a lot of time (though prob not using x86) just not my home pc. On the other hand I loved the 68000 assembler class I took, came at a great time to help with a much deeper understanding of computing in general.
If these instructions are not the craziest ever created, then the LSD that the engineers at Santa Clara are doing , needs to be shipped along with the chips they are creating….