Sometimes you might need to use assembly sometime to reach your project objectives. Previously I’ve focused more on embedding assembly within gcc or another compiler. But just like some people want to hunt with a bow, or make bread by hand, or do many other things that are no longer absolutely necessary, some people like writing in assembly language.
In the old days of DOS, it was fairly easy to write in assembly language. Good thing, because on the restricted resources available on those machines it might have been the only way to get things to fit. These days, under Windows or Linux or even on a Raspberry Pi, it is hard to get oriented on how to get an assembly language off the ground.
What Do You Need?
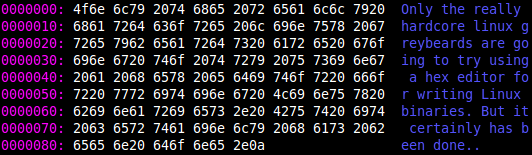 Obviously, one thing you need is an assembler. Granted, if you are a true macho hacker you could just use a hex editor to build executable files by hand from your binary notation, but in reality that is probably too much for just about everyone. You also need to understand your CPU architecture, the instruction set, the mnemonics the assembler uses for the instructions, and the interface to the operating system.
Obviously, one thing you need is an assembler. Granted, if you are a true macho hacker you could just use a hex editor to build executable files by hand from your binary notation, but in reality that is probably too much for just about everyone. You also need to understand your CPU architecture, the instruction set, the mnemonics the assembler uses for the instructions, and the interface to the operating system.
In this example, we’ll look at writing code for Linux on a PC. The same ideas will apply to other Linux platforms like the Raspberry Pi. The details will be different for other systems (like the AVR found in an Arduino) but the basic outline of steps will be the same. Of course, some systems don’t have an operating system at all, which makes it both easier and harder. Easier because you don’t have to conform. Harder, because you have to find resources (like a serial port or display) and handle them yourself.
Linux Asm
Generally, if you have a C compiler, you probably have an assembler. For gcc, this assembler is named gas or as. That’s usable, but they aren’t always as friendly as you would like. On PC-based Linux, you might consider using the netwide assembler (nasm) that you can install with your package manager.
Even for Linux, you have to consider the platform. In my case, I’m using a 64-bit Intel/AMD PC. But you might be using a 32-bit version or running on ARM (or any other CPU Linux supports). There is even a 32-bit interface for 64-bit Linux (x32), if you are interested in that. The second order of business, then, is to figure out what the CPU architecture looks like.
To start, you need to understand the registers (like the diagram below). Of course, that diagram assumes you have some idea what those registers are for, so you’d have to do more digging in a reference manual, a data sheet, or a tutorial aimed at your specific processor.

That can be daunting on any modern CPU. You can always find the data sheets, but it can take a long time to parse through one of those. There are also plenty of resources online, as you might expect. If you are working with something like an AVR, the data sheet is pretty straightforward. The more complex processors usually have a lot of details you don’t need to know, so that’s part of the problem with the data sheets. For example, an Intel processor has a lot of features aimed at people writing operating systems. Unless you are writing an operating system or programming bare metal, you don’t care about that.
Also, unless you care about bare metal programming, you need to know the application binary interface or ABI that defines how the program starts and can call libraries and services. For example, for 64 bit Linux, you can read this document.
In Practice
If you start reading data sheets and ABI documents, you might feel like giving up pretty quickly. However, it really isn’t that bad. You can find many sites (like this one) that you can use to find out the particulars of calling system calls.
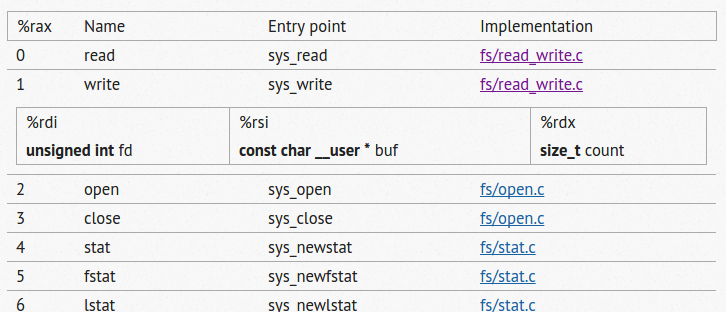 For example, system call with code 1 writes to a file. If you look it up on the site above, you can double-click the corresponding row and see how you need to make the call. This image is an example of how to use that table.
For example, system call with code 1 writes to a file. If you look it up on the site above, you can double-click the corresponding row and see how you need to make the call. This image is an example of how to use that table.
In this case, you’ll see that %rdi gets the file descriptor, %rsi gets a pointer to the data to write, and %rdx is the count of bytes to write. Call 60 is the exit function (you can look it up on the same table). You probably know that file descriptor 1 is the stdout device for a Linux program. So using nasm, a very simple program can look like this:
section .data
msg db "Hello Hackaday!",10
msgend equ $
section .text
global _start
_start:
mov rax,1 ; print msg using syswrite (1)
mov rdi,1 ; fd 1
mov rsi,msg ; buffer
mov rdx,msgend-msg ; count
syscall
mov rax,60 ; exit
mov rdi,0 ; return code
syscall
Granted, this is pretty much the simplest program you could write, but it works. A simple nasm command does the assembly:
nasm -f elf64 -o hello.o hello.asm
Then you need to link it just like you would an object file from a C compiler (you could even link in some object files produced from the C compiler, if you wanted to):
ld -o hello hello.o
Go Forth and Assemble
Clearly, you have a lot of details to fill in, but the point is, it doesn’t have to be very hard. If you use 32-bit Linux or ARM, the details will be different (there will be different syscall numbers and registers, for starters).
Just as a reminder, I’m not suggesting that writing entire programs in assembly is a great idea. But it is a challenge and one that can have unexpected benefits. If all you want to do is optimize a few hot spots, you are better off sticking with inline assembly (discussed last time). But if you want to flex your logic and programming muscles, try writing some entire programs in assembly. You might get it to work and you might not, but I’d bet you’ll learn something.














your opinion of “But just like some people want to hunt with a bow, or make bread by hand, or do many other things that are no longer absolutely necessary, some people like writing in assembly language.” is so wrong it absolutely hurts and this goes across the board from making bread to using assembler in a project. I’ve had project that have nearly zero headroom to deal with and it isn’t just a “want to use” situation it is a have to do situation. The same can go for the other items mentioned making bread correctly while doing a window pane to get correct texture on a bread instead of what people consider good enough at the store. or even hunting with a bow when a lot of places the season only allows for a bow hunt during those times.
anyway enough rand about your silly wrong opinion, assembler can be a very very good thing to know for your projects
Very first line of article: “Sometimes you might need to use assembly sometime to reach your project objectives.”
Or maybe you should just reread the stuff that set you off. Quite clearly the point was that there are things people do for fun even when they don’t need to, not that nobody ever needs to do those things. That’s pretty common among hobbies, which are things that are commonly discussed in HaD blog posts.
When writing code for ATtiny13’s I find it much (MUCH) easier to write in straight assembly. To understand what some of the C code for AVR’s do I have to translate to assembly first.
Man.Good opener. If you do anything where timing is super critical, ASM is a life saver. I can’t speak for arduino because I am a hater and never adopted it. Though I have poked around a library file or two for giggles and found plenty of ASM sprinkled about. For the micro and the high level language I do use, dropping down to ASM now and then is needed to push some pulses in the right direction or for getting an ISR to play nicely when I’m pushing the bounds of how well the high level stuff gets optimized. But writing fully in ASM on the 8051 was, um, mind numbing.
Something that most people don’t seem to consider during discussions about assembly language is that if you can at least read it, that will help your understanding of how higher-level languages work, and even processors (definitely one of the “unexpected benefits” you refer to).
I’d like to see someone bring ANY part out of RESET without assembly language.
You can write C programs to run on bare metal 8-bit AVR chips with just a standard invocation of main(). Okay, slightly non-standard since it takes no arguments, but I can assure you that you can write that program with out a single byte of assembly, download it over ISP and it will run just fine.
Can you show us how the stack is setup, how the processor clocks and interrupt peripherals are setup and how statically-initialized variables are set without assembly language?
Because I’m still ready to be shown not told.
Oh my mistake, I though we just read an article that was talking about how you might want to learn assembly even if you don’t often need to write any yourself to get programs running, rather than an article saying no assembly is created or used by any part of your toolchain. Silly me.
Here’s another one you can try, if you’re running out of straw: I’d like to see someone bring ANY part out of RESET without transistors.
I usually put an RC filter from the supply to the /RESET pin ;)
AVR Stack point is mapped at IO register location: 0x3d-0x3e SPH and SPL. I/O registers are declared inside C header files and the same way you would use a GPIO or timer or ADC.
You can write code like the following to set up the stack which is probably the most tricky part if it weren’t in I/O registers/
SPL = 0x00;
SPH = 0x04;
Statically allocated variables can be zeroed or initialized with a value just by having a loop to zero the memory and a memory copy routine to copy FLASH space initialized values into RAM. It is not efficient, but can be done.
Also see this start up code for STM32 in pure C.
https://github.com/geoffreymbrown/STM32-Template/blob/master/startup_stm32f10x.c
This show how to initialize the variables in C.
BTW documented AVR starup code in assembly here: http://cvs.savannah.gnu.org/viewvc/avr-libc/avr-libc/crt1/gcrt1.S?revision=1.17&view=markup
Like I said, I have not see anything that is not accessible with C as stack and other things that needs to be initialized are in IO registers. That’s probably by design (vs traditional microprocessors).
The start up code looks very simple. It is a matter of recoding things in C. Not sure if there are any practical value in this except understanding how things works before your main() get called. Everything is done for you if the compiler supports your device.
The C code would be very similar structure to the ARM one.
Just read the datasheets for the AVR. Everything that need to get the job done is in there. Clock and interrupt set up code is pretty much what bare metal is all about. Anything that can be setup in I/O registers can be accessed in C. Nothing difficult if you can read and understand a datasheet.
The only thing that you need to use assembly is if you want to write a RTOS and having to mess around with the context switching saving and accessing the individual CPU registers. Regular C have no direct and controlled way of doing so without messing up the registers.
So we don’t need the crt any more. Excellent job.
The initialization code is all available with the library downloads from Atmel. For their SAM chips, it’s mostly C. I imagine there’s more assembly for the AVR parts, though C gives a programmer enough control to directly twiddle bits in I/O registers that are mapped at known addresses.
Don’t wait to be shown. If you care, go find out for yourself.
I bet you’re forgetting that you’ve linked with a version of crt0.s aren’t you?
This was actually my disappointment with this article. I thought it was going to cover crt0 and talk more about the scaffolding that is required in order to make the assembly program actually run on linux.
Cortex-M? With proper linker script you should be able to use plain C.
Can you show me how to use a linker script to set the stack pointer register in the CPU or copy values from FLASH to RAM for statically initialized variables?
What exactly is your point? Are you claiming this can only be done in assembly? Are you trying to claim that the article is saying assembly is never needed for anything?
I was going to say Cortex-M as well.
You still need to tell the linker to put two const uint32_t’s in the beginning of ROM (reset vector and initial stack pointer), but other than that it’s plain C. Even the variable initializations can be done in C, because the availability of so many registers ensure that there are no spills to stack in your initialization function that eventually calls main().
Yes, I’ve tried it and it works. Was quite a revelation to see it happen. All previous architectures have required at least some assembly.
Do you know ANYTHING about CM cores? The initial stack pointer, along with the reset vector, is loaded from the vector table by the CPU on reset. You can copy rwdata initializers in C with a for loop and symbols defined in the linker script. Same for bss initialization. You could even do both with memcpy and memset if you have a standard C library. When branching to an interrupt vector, all registers not pushed by the compiler are automatically pushed by the processor. No need for assembly wrappers there. On CM cores, you do not need to write one instruction of assembly. Please do your homework to back up claims.
You can write startup code for 8051 in pure C as all the registers including stack pointer, pointer register, accumulator, flag registers are memory mapped in the SRF and that’s accessible in C. The reset pointer can be done in compiler directive to place an array of pointer to function in program memory space.
It is not done, but it is entirely possible.
That satisfy the “ANY” part of your assertion and disprove it.
I’ ve already done it easily. Check my answer here: http://electronics.stackexchange.com/questions/224618/minimal-code-required-to-startup-a-stm32f4/224654#224654
There is not a single line of asm in any of the called functions. No standard start files are used/linked. Pure C from the first instruction.
I work in a company that in our projects we absolutely do not care if we spend a few more cycles during initialization, but readability, portability and ease of code maintenance are priorities*. In fact I enjoy my code more like this.
@HaD. Maybe starting up properly an ARM MCU, writing the linker script etc, would be an interesting idea for a future series of articles…
Absolutely! Please, HaD, do this!
Hunting with a bow is no longer needed. You can buy meat in a grocery store.
Timing-critical stuff in x86? Are you seriously believe you can optimize large piece of code better than a modern C++ compiler? Even for SSE SIMD there are C++ extensions.
Yes, it is nice to know the ASM, but nowadays even C++ is too low level for pretty much all the practical purposes (even SIMD you can do on MONO .NET)
BTW, I did full-time programming on IBM370 and x86 asm and also programmed on I8080, i8051, and PDP11 asms.
It isn’t necessarily optimization but regular timing that can be important in control-systems. There are a few ways to get there, but bare-metal assembly is one such.
Yes you can still beat a modern C++ compiler. No one wants to write entire applications in assembly but certainly you can do better by hand than a compiler in important inner loops. The downside is usually you are targeting a particular processor, whereas a compiler can often recompile when processors change. You do need to get to know your processor intimately if you want to stand a chance of doing better and that’s where most people today will balk at the complexity and throwaway nature of your current gen. See Agner Fog’s documentation for x86.
If you don’t know assembler you wont be able to work out what your compiler will produce.
I’ve worked on plenty of project where we’re gone into the C compiler output worked out where optimizations could be had re-worked the C code. Cahce-misses in algorithms are generally what we target as slow code (outside a loop at least) is fine in the modern CPU world. Cache misses and expirary can quickly humble you.
Just because you can’t do something. Don’t assume other don’t have the knowledge, skill and experience to leverage opportunities.
I think I still have a book(or had and threw it away) that shows how to make DOS programs using the debug utility to write the instructions directly in memory, crazy stuff, I never got past the few first pages.
Oh boy I miss that debug.exe so much, That was the DOS/WIN killer app.
Using it looked like black magic for most peoples.
You could do some amazing stuff with that, like corrupting the BIOS CMOS CRC ;)
Anyway I think I leave windows for good at the same time debug.exe did…
Inb4 MORE arguments. ASM Vs. C
ASM roolz, C droolz! (And C++ fouled the bed.)
Raspberry Pi aren’t special
Okay.
I learned to program in assembly on a 6802. We did not have an assembler – we translated op codes and operands into hex by hand and poked them into the machine one nibble at a time. IIRC, the difference between one of the load and its store counterpart was 0xb6 and 0xb7. I mis-assembled an otherwise perfect program (used a store instead of a load) and it took about an hour to find that bug.
(Much) later, I was writing mixed C and assembly for an ADSP21020. Our emulator could not do C, so everything we wrote in C, we debugged in assembly. That is a highly instructive exercise, and teaches you very quickly how expensive/cheap some C constructs are compared to others.
Nowadays, I never write in assembly and do not miss it very much. But it was great fun while it lasted.
I can get my processor type with the following line,
cat /proc/cpuinfo | grep -i -m 1 ‘model name’ | tr ” ” “\n” | sed -n ‘5p’
If that does not work for you remove the end section of the pipe until the result gives you enough to get a result here,
http://www.intel.com/content/www/us/en/search.html?keyword=
It should point to info on your exact CPU, which will have a link to here,
Datasheets are here, http://www.intel.com/content/www/us/en/processors/core/core-technical-resources.html
One more click after that and you should have the PDF file you need. :-)
Speaking of Assembly Language and going Forth,
https://web.archive.org/web/20080418193057/http://annexia.org/forth
Nicely documented too,
https://web.archive.org/web/20080509084436/http://www.annexia.org/_file/jonesforth.s.txt
I was going to applaud the last headline also. It is ingenious if it is worded like that in purpose.
RISC processor like the ARM are a nice & easy for learning assembly, with the multitude of registers, you’re not constantly juggling with reg/stack/memory (which is not the fun), and if you really need speed, you can make code small enough to fit and that can stay inside the cache, which is not really big. C/C++ is a memory eater.
“Sometimes you might need to use assembly sometime .” Do you work in the Department of Redundancy Department?
Can you tell the difference between, “Sometimes you might need to use assembly sometime” and “Sometimes you might need to use assembly, sometimes” because I can and I suspect there is a typo, or two rather than a conceptual error.
How about NO. Or How about “Install Gentoo or Exherbo”… Take the pain out of this garbage and install Funtoo already. You can build an Hypervisor as Dom 0 in Gentoo and run all your old crap on Windows 98/Vista/7 without sounding like a little whiny whatever via H/PVA hybrid with 10% performance hit. Hell they even have a “real-time” Linux for Audio Studios.