[Alessandro Carminati] spends the day hacking Linux kernels, and to such an end needed a decent compilation machine to chew through the builds. One day, this machine refused to boot leaving some head-scratching to do, and remembering the motherboard diagnostics procedures of old, realized that wasn’t going to work for this modern board. You see, older ISA-based systems were much simpler, with diagnostic POST codes accessible by sniffing the bus with an appropriate card inserted, but the modern motherboard doesn’t even export the same bus anymore.
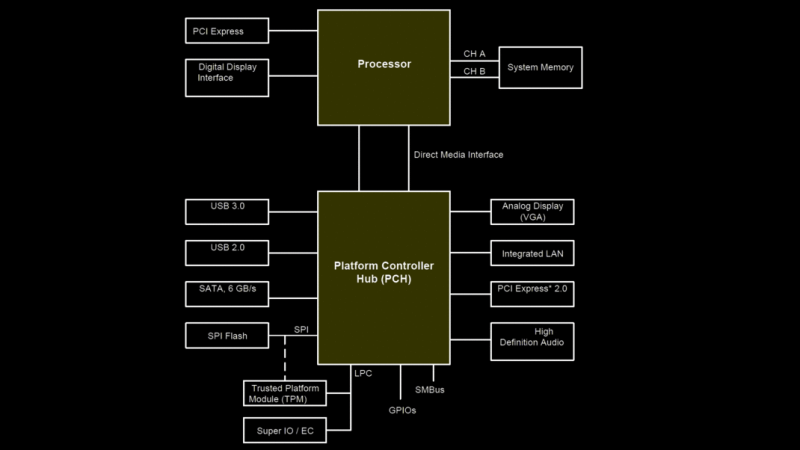
Do modern machines even run a POST test at all, or are there other standards? After firing up a Linux machine and dumping the first meg of memory address space, it clearly contained some of the BIOS code. [Alessandro] looked at a disassembly of the BIOS update image and saw a similar structure, with POST code data sent to port 0x80 just like machines of old.
But instead of an ISA CPU bus, we have the Low Pin Count (LPC) bus which is used to hook up the ‘super IO’ functions, controlling things such as fans, temp sensors, and other system management functions. It also serves as the connection for the TPM feature, which usually appears as one of the motherboard connectors intended to be user-accessible. It turns out that POST codes can be accessed from this point with an appropriate POST card that can talk LPC.
[Alessandro] demonstrates his faulty motherboard dumping POST codes encoding for a CPU error, giving at least somewhere to look to debug further. This all goes to prove that even though a modern PC may seem totally different from the first PCs from any viewpoint, there still are considerable vestigial remnants baked in there. After all, if it works, then there’s no need to change it. We’re no strangers to PC hacks, here’s a committed hacker who after upgrading the RAM beyond that supported by the motherboard, was determined to make his machine boot windows, no matter how much it complained. And won.













Computers are still a set of gates talting to other sets of gates through wires using mostly ascii codes. “In the beginning was the command line” by Neal Stephenson – a must read for any hacker.
There are some flashers for LPC with fashrom tool:
https://github.com/wosk/stm32-vserprog-lpc
I hope these diagnostic cards have a UART output. I do not envy anyone having to read a long message using only a two digit display.
That’s why the messages are short.
Usually posted in the manual that came with the board.
When it comes to troubleshooting a hardware issue and using POST codes to diagnose the problem, the general rule is that only the last code displayed before a hang or freeze is relevant. However, in my case, this rule did not apply because instead of hanging on a single code, the BIOS seemed to be stuck in a loop. Nonetheless, the last POST code displayed before the repetition began was still the most meaningful in terms of diagnosing the problem.
Initially, I suspected that the issue was with the motherboard, but further investigation revealed that the problem was actually with the processor (as POST suggested).
If you want some stores about the system, I was in the BIOS industry for a while.
The diagnostic info are just 2 digit code (or 4 if you have a fancier diagnostic card) that you look up in a table to see where in the bootstrap process the firmware is currently at. Even on modern PCs, the process is still fairly linear and the code can help a technician figure out if there is a faulty component or a configuration issue.
In the past, text strings would not be used for reasons around storage space (EEPROMs were small), and that serial ports had more important functions. On modern PCs, storage space and issues around implementing string printing infrastructure isn’t so much of an issue, but having a UART at the appropriate IO port at power on is and there isn’t really a good method to ‘just detect if there is a UART’ for a number of reasons.
Again, if you’re interested, I can provide more of my perspective from my time as a BIOS and UEFI engineer but I don’t want to get long winded here.
“Again, if you’re interested, I can provide more of my perspective from my time as a BIOS and UEFI engineer but I don’t want to get long winded here.”
You’ll fit right in. :-D
POST codes definitely still exist. They are used for debugging in the early stages of boot. Some server boards even still have the little 7-seg displays.
Higher end consumer boards.
https://youtu.be/pzEJ1c1TYps
Low end motherboard used to come with them but recently they were left out to save about $0.05 per motherboard.
NO ONE should buy a motherboard without that little LED display! Been down that bumpy dark dirt road, don’t do it to yourself… And the only way to encourage them to keep putting one is to only buy MBs that have the display!
FWIW, many years ago I proposed changes to the PCIe spec that would enable POST cards to work they have on PCI and ISA systems.
In response some additions were made to PCIe 3.0, but not in the way I had proposed. Unfortunately their take just didn’t meet the main requirement of KISS (“it just works”), and instead required the UEFI/BIOS to detect the POST card and enable routing to it. Thus now, many years later, we still don’t see PCIe POST cards.
Oh well…
Did you get a spec for this? Uefi is open source… So in theory you and a group of your friends could maintain the uefi module responsible for doing the translation.
Id help out
It’s not an issue of writing UEFI code. The implementation needs to go into the “secret” bits from Intel in order for it to really be useful, e.g. to send POST codes during the early bringup. If it happens later, the system is mostly up already.
Not to mention that such a solo venture would have a snowballs chance in a BBQ to overcome adoption on the system side before someone bothers to make POST cards to work with it.
UEFI depends on TPM/Secure Boot, though. Certificates everywhere. UEFI us a closed platform in reality, not an open one. That was the PC or PC/AT BIOS, with its ability to load Option-ROMs. There will be a point in time soon in which the option to disable security options is gone in UEFI. Being opt-in all the time. Just think about it. CSM (BIOS emulation) is forcefully being removed in order to prevent the user from having a way to by-pass these limitations and boot DOS or any other older OS without modern restrictions. Open Firmware was a real open platform.
In another reply, I was thinking out loud that something based around the SMBus might work. Pins are available on PCIe slots, it’s needed pretty early in the boot process since it’s needed to read SPD info from DIMMs, and I see a PPI in the MdePkg libraries of the EDK2 project.
So it looks like a standard status code listener might be possible pretty early in the boot process (it depends on when the SMBus PPI gets published).
The biggest hurdle I see is getting a platform that has an SMBus to work with and a totally open source firmware based on the EDK2.
One of the questions I left open was how POST can function on the PCI bus and why it cannot on PCIe. Since the BIOS only sends values to port 0x80 when dealing with POST, it is likely that PCI bridge is responsible for the actual work. Could you please direct me to any relevant documents that can explain this? Thank you in advance.
(I don’t know what happened, but I wrote a long response and it vanished when I hit Post Comment. I’ll try to restate in case it doesn’t show up again.)
The issue with PCIe vs PCI is that writes to I/O and regular memory are broadcast on PCI but on on PCIe. E.g. a port 80h write will be seen by all cards and as long as one card indicates that they are responsible for that region of memory, the topology will deliver the write to the card.
On PCIe the entire topology must be configured for a write transaction to reach an endpoint. I.e. an endpoint must request I/O addresses and the firmware or operating system must assign them. This means that a port 80h I/O write will only go to a single recipient that’s been specifically configured for it.
A truly transparent solution would be to mimic a broadcast capability on the PCIe bus. I proposed two alternatives to achieve this:
Either assign a broadcast message to POST traffic, or
Allow specific I/O port ranges to be broadcast to all endpoints.
These were not adopted, but instead the PCIe 3 spec (and later) allow the system firmware to detect a debug card type and if it feels like it, configure the system to route POST codes to go to that card.
From what I can tell, there has been no adoption of this method for obvious reasons. One, the endpoint configuration happens so late in the system bringup process that the POST codes are no longer that useful. Two, it requires the system firmware writer (e.g. Intel) to write and debug code for which there is no obvious user.
When I was working for a server hardware company, there was a customer demand for video output ASAP because, even back in the Sandy Bridge days took forever and only got worse with multiple sockets. The BMC we used has Super IO capabilities and could receive data on port 80h, it still didn’t provide enough to satisfy customers either over a remove KVM or using the built in KVM redirection.
In our case, the BMC had the video hardware built into it and because it was integrated, we always knew what bridges it was behind and the amount of resources it would request.
IIRC we were able to set up enough memory space (I don’t recall if it was just address space, if it came from the CAR pool, or if we went against Intel’s recommendations and added another cache bank to the CAR pool) and hard code the IO ports we needed to get some basic text output.
At least for the IO ports, something like that would be needed under the current spec. Maybe if an OEM wanted to dedicate a specific slot to a diag card, that could work on a modern system.
Otherwise, some sort of broadcast system like you lay out would be needed but I think it would have to be limited to ports 80h and 81h. It also would only be PC compatible (and I believe cross platform compatibility is high on the PCI-SIGs priority list these days).
There were a couple of other debug interfaces the industry explored in the time just before I left but the idea that I kicked around with some other engineers was the potental to do it via the SMBus since it has to be up early enough to read SPD data from the DIMMs. I don’t recall if there were any major issues other than it just being non-standard.
This made me think about the fact that the EDK2 project is open source.
https://github.com/tianocore/edk2/tree/master/MdePkg/Library/PeiSmbusLibSmbus2Ppi
I wonder if that PPI is available early enough to be useful and if the maintainers would be open to a contribution for an SMBus based status code listener (though finding hardware that could be used to develop on would be a problem).
The simplified requirements for a PCIe POST card are the same as for what has been around since ISA and PCI:
1. Minimal chipset configuration (preferably none) — so that debugging info is available early on.
2. No requirement for RAM to be configured — as RAM bringup is one of the tricky things.
3. No protocol requirements (i.e. single instruction emission of status) — so that the debug interface has minimal impact on system operation.
4. No debugging requirements (i.e. it’s a byproduct of normal system behavior) — as otherwise some bean counter could simply decide to drop support for it to save 5 cents.
Assigning one of the precious broadcast message types to debug traffic would’ve done it without impacting any compatibility with other uses of PCIe. As would have allowing the broadcast of magic I/O ranges. (On systems that don’t use I/O transactions it doesn’t make things not work, it just doesn’t do anything useful.)
But it seems that the PCIe SIG is like any other “standards” body; full of little fiefdoms and alliances that logic, reason and common benefit has difficulty penetrating. Especially without a trillion dollar company backing an idea up.
Hey aki009, thanks a ton for your feedback. I really appreciate it!
To be honest, I’ve never been involved in the PCI SIG or written a BIOS firmware. But that didn’t stop me from taking the fun route of trying to reverse engineer the BIOS. I’ve always been fascinated by the magic and voodoo tricks hidden in that software.
The biggest problem I faced was the lack of documentation. It’s frustrating when you come across code that messes with random CPU state registers or dives into undocumented PCI address spaces, and you have no idea what those bits are supposed to do.
Anyway, the BIOS POST is something I’ve always taken for granted. But when I actually needed to understand how it works on modern hardware, I was clueless. I didn’t even know about the broadcast that happens in old PCI systems, as you mentioned. I’d love to dig deeper into that if I can. Thanks for your input, and please feel free (actually, I encourage you) to share any other details that can help me and other curious folks understand this process.
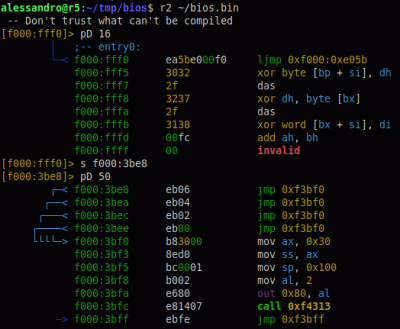
Just a quick note: The POST can start as early as the third instruction after the reset vector. In the BIOS I looked at, there’s an “out 0x80, al” before the system switches to protected mode. Here’s a proof I generated using my trusty friend radare2 to analyze the BIOS running on my machine.
“The biggest problem I faced was the lack of documentation. ”
Usually that falls under “standards group wants money”.
Hey aki009, thanks a ton for your feedback. I really appreciate it!
To be honest, I’ve never been involved in the PCI SIG or written a BIOS firmware. But that didn’t stop me from taking the fun route of trying to reverse engineer the BIOS. I’ve always been fascinated by the magic and voodoo tricks hidden in that software.
The biggest problem I faced was the lack of documentation. It’s frustrating when you come across code that messes with random CPU state registers or dives into undocumented PCI address spaces, and you have no idea what those bits are supposed to do.
Anyway, the BIOS POST is something I’ve always taken for granted. But when I actually needed to understand how it works on modern hardware, I was clueless. I didn’t even know about the broadcast that happens in old PCI systems, as you mentioned. I’d love to dig deeper into that if I can. Thanks for your input, and please feel free (actually, I encourage you) to share any other details that can help me and other curious folks understand this process.
Just a quick note: The POST can start as early as the third instruction after the reset vector. In the BIOS I looked at, there’s an “out 0x80, al” before the system switches to protected mode. Here’s a proof I generated using my trusty friend radare2 to analyze the BIOS running on my machine. (https://imgur.com/a/0ASuPm7)
Sure.
On PCI, similar to ISA, by default all attempts at writes to memory and I/O space are reflected to all buses.
The writes are a three step process:
First the bus master (whoever is trying to do the write) puts up an address and sets signals to indicate if it’s a read/write and memory or I/O space.
If there’s a device on the bus that is configured to respond to that address, it does so within 2 cycles. Two devices can theoretically respond at the same time on the same bus. (A “nice” POST card can wait a cycle to see if anyone else claims the transaction; if someone does, the card just listens in on the data. In a POST card that I designed this is a configurable feature.)
Once the recipient has identified itself, the master puts the data on the bus. Then the recipient acks the receipt and the transaction is done.
On PCIe the same process is emulated, except that by default roots and hubs route traffic based on knowledge of what endpoints are responsible for what address segments.
Thus a write to I/O 80h will not be reflected on the PCIe bus, unless an endpoint is configured to “own” the address. And even then only the root and hubs leading to the endpoint see the transaction.
Theoretically there is no downside (other than using up bus bandwidth) to sending all transactions to all endpoints so they can monitor what’s going on.
But the powers that be didn’t want that feature, partially for security reasons, and partially for performance. It would’ve been nice if they had made it available for POST.
BTW, the reason the POST stuff works on modern systems, but in a limited manner, is that many chipsets are configured to send I/O 80h traffic to the LPC (low pin count) bus. That bus uses a small number of pins to emulate PCI and theoretically a POST card can easily listen in. Unfortunately there is no standard for connectors, and getting the pinout wrong extracts the magic smoke from the system. This is how the built-in POST code displays operate.
Just a thought
Since PCIe is supposed to be backwards compatible, shouldn’t inlining a PCIe-to-PCI converter between the slot and a PCI-compatible POST card do the trick?
Here’s a copy of the PCIe 3.0 spec:
https://picture.iczhiku.com/resource/eetop/wHiSRjtztkeJLnVc.pdf
What’s interesting is I do see a provision for POST codes on page 42:
A Root Complex is permitted to generate I/O Requests to either or both of locations 80h
and 84h to a selected Root Port, without regard to that Root Port’s PCI Bridge I/O decode configuration; it is recommended that this mechanism only be enabled when specifically
needed.
Unfortunately, that language around ‘selected root port’ is a problem and there is other language that will effectively mean an OEM is unlikely to set up their firmware to use a diagnostic card.
That’s the stuff that is part of the piecemeal and incomplete implementation for POST code support. It’s supposed to work in tandem with a card type that can accept those POST codes. So the firmware is supposed to look for PCIe cards, and enable this mechanism if a suitable endpoint is found. In other words, it’s mostly on the firmware of the system, plus this implementation requires hardware changes to the PCIe root, which is even less likely to happen.
What spec changes were you proposing? Would they have been PC specific? Would they co=exist along side an ARM PCIe implementation that doesn’t have IO ports?
NVM, I see the reply above
heh a “POST card” in my mind is a piece of paper with a table that looks like
one long beep – memory failure
two long beeps – printer on fire
two short beeps – cpu failure
etc
How many beeps for speaker failure?
zero
The system uses smoke signals for that.
Magic smoke visible == speaker failure.
Some laptop AT BIOSes also had the ability to output POST codes via LPT1.
Darn it, I’ve been saving a box of Post Cards hoping to score some cash.