In the world of software development the term ‘optimization’ is generally reason for experienced developers to start feeling decidedly nervous, especially when a feature is marked as an ‘easy and free optimization’. The final keyword introduced in C++11 is one of such features. It promises a way to speed up object-oriented code by omitting the vtable call indirection by marking a class or member function as – unsurprisingly – final, meaning that it cannot be inherited from or overridden. Inspired by this promise, [Benjamin Summerton] figured that he’d run a range of benchmarks to see what performance uplift he’d get on his ray tracing project.
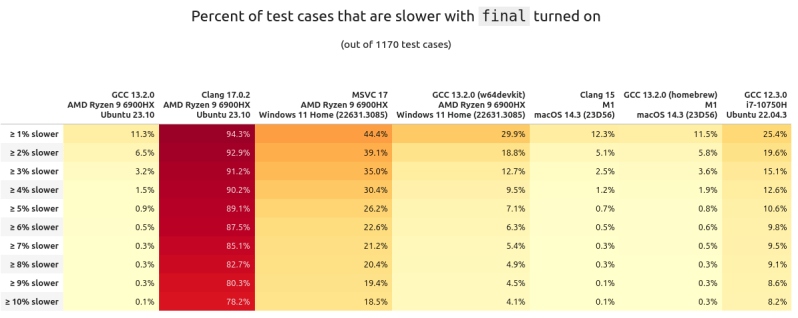
To be as thorough as possible, the tests were run on three different systems, including 64-bit Intel and AMD systems, as well as on Apple Silicon (M1). For the compilers various versions of GCC (12.x, 13.x), as well as Clang (15, 17) and MSVC (17) were employed, with rather interesting results for final versus no final tests. Clang was probably the biggest surprise, as with the keyword added, performance with Clang-generated code absolutely tanked. MSVC was a mixed bag, as were the GCC versions other than GCC 13.2 on AMD Ryzen, which saw a bump of a few percent faster.
Ultimately, it seems that there’s no free lunch as usual, and adding final to your code falls distinctly under ‘only use it if you know what you’re doing’. As things stand, the resulting behavior seems wildly inconsistent.














> “final“ was placed on just about every interface.
https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#c139-use-final-on-classes-sparingly
People should learn more best practices from more mature developers.
:eyes emoji: to observe a /degradation/ in performance for this feature is truly stunning. good to have someone pull the curtain back. “know your compiler”, I suppose….
Final isn’t really a performance optimisation for a modern compiler. The compiler already knows which functions are effectively final.
It can be a good way to stop particular methods being overridden by another developer.
It does seem strange to see a performance degradation though. I would have assumed the compiler would only consider it a hint for specific optimisations and a restriction on other code overriding it.
Could also be that the compiler developers have spent less time making optimisations for a less used language feature.
Maybe it’s inlining the methods, making the code larger, filling up the code cache memory
> Final isn’t really a performance optimization for a modern compiler. The compiler already knows which functions are effectively final.
This isn’t true. The compiler cannot know this for C++ in a lot of cases with virtual functions. (without virtual, any function is final)
Simple case:
https://godbolt.org/z/ja8rbj8Wd
Remove the final, and notice the difference.
and add ‘-whole-program’ and the difference vanishes.
yeah…i mean, final *can* have performance implications if you’re passing around a pointer to an object, it basically tells the compiler whether it might be a pointer to a subobject of a larger derived class (either for a whole class or for specific functions).
imo it does speak to bad engineering choices. final implies a lack of flexibility and virtual implies an excess of flexibility and i think the class heirarchy should be designed correctly from the beginning, rather than introducing a pointless tug-of-war between extremes. it’s likely there is an underlying base class here that is too generic for its own good (or generic in the wrong way, perhaps even less generic than it should be), creating a problem that Summerton is trying to solve with final.
but i think you’re right that it’s most likely something in the vein of inlining decisions that is ultimately blowing it up. this is an awful lot of experimentation and publishing effort considering that there’s zero actual investigation. my guess is that the real story here is this is a rehash of -O3 considered harmful. final allows -O3 to be even more unrestrained. obviously, the optimization settings are more central to this than final itself. but they aren’t even discussed in the write up and i’m not about to try to detangle the makefile.
i’m gonna pontificate from a position of relative ignorance here: the real story is that a lack of understanding of software engineering fundamentals resulted in a poorly-performing project, and instead of trying to understand the underlying causes (poor factoring decisions, duh), they’re trying to blindly hack the compiler instead.
C++ considered harmful. an obfuscatory write-up that is well-matched with the obfuscatory language.
Damn I wish I was better at programming.
Whipping together something on a weekend night is in no way comparable to writing proper large projects with maintainable codebase, with everything properly compartmentalised so that you can easily understand what’s happening where.
There is a hacker news post for the same article that is a good read ( I won’t link it here as it might get flagged). It does through doubt in my mind if this behaviour is ubiquitous and if the outcome is actually due to a compiler bug instead of the intent of the final keyword.
I really recommend this talk:
https://youtu.be/7g1Acy5eGbE?si=Zg0gVd1wPfKrzbc0
Drawing conclusions from single measurments isn’t right.
Doesn’t anybody examine the machine code output any more to see what’s going on when a compiler behaves unexpectedly?
The whole premise of this is wrong. the final keyword has no run-time performance impact and no effect on the vtable. Look at a simple example, make class with one method, call it X, and look at sizeof(X). Now make the method virtual and look at sizeof(X). Now mark the whole class final. There’s no change in the generated code or the size of the object (which includes the vtable).
The optimizations don’t apply to the class as you have noted. The optimizations apply to functions whose perimeter is a X*. without final, they have to load the virtual function table, get the virtual function pointer, and then invoke it. with final, they can invoke the function directly, and even potentially inline it.
as other comments note, the performance degradation is probably the inlining.
I really wouldn’t take these conclusions at face value.
This is a very specific kind of benchmark and a very specific kind of program. It’s a single sample point, and even trivial changes can produce quite substantial differences in small benchmarks like this due to unrelated things like code layout moving around and crossing page boundaries, along with all sorts of other factors. Do not let “final is slower” be the conclusion you get from this.
Yes. Any conclusions on performance are always tricky. I’m currently working on performance intensive code. And things can get wild. For example, I have code that is 30% faster in single threaded, but performs 20% worse in a multithreaded environment. Especially on x86_64, it’s really hard to get a grip on performance. The CPU is doing so many wild tricks, where it shares ALUs, cache, and does predictions.
And that’s not even looking at the compiler. So far, GCC has been doing the best job for me, and clang the worst (sometimes even 40% worse!)
The only way to know really, is to measure. And measure a lot. I had to switch to a dedicated linux box that only runs my software and as little else as possible, as everything else running on the machine was just adding 5%-10% randomness to the results.
Just because I’m interested:
“code that is 30% faster in single threaded, but performs 20% worse in a multithreaded environment” – what’s the baseline for those two different numbers?
“Especially on x86_64” – on which architecture(s) is it not “especially”?
Just a stab in the dark but your thread safety is probably getting in the way of your thread performance. Remember you want as few mutexes, locks, etc. as possible. Fixing it is probably restructuring it.
Threads have some effect onto each other because they share memory and maybe some of the cache. When they access RAM simultaneously they block each other.
An other obvious effect is that due to heat and power limit one core has to be slowed down once the other core is also working. Single core highest clock can not be maintained when multiple cores are working. This is typical for most current CPUs and mainboards.
A third problem is accumulated heat. Once I run benchmarks to compare algorithm A and B. Benchmark of A run first then B second. I could not reach the performance of A even though in theory B was better. It took me long time to recognize that the CPU started throttling when executing B because of the heat build up from running A full speed. I had to benchmark them with a pause in between them to let the CPU cool down. It is not an issue if you have server or gamer grade cooling but on a cheap laptop this is to be considered.
Once we use not whole cores but also the “hyper” threads then performance becomes even worse. I have measured such an algo today on a gamer 8 core (16 thread) AMD. The single threaded benchmark finished at 1:07. When 8 are executed parallel then about 1:30 and when 16 are executed parallel then 1:47. It is still worth to use all cores but it does not scale linearly.
Luxury!
When I was a kid we used to dream of having eight cores…
We had one eight bit core running at one megahertz and we liked it…
By ‘had’ I mean we had one, for one hour, shared by 30 students. 29 distracted the teacher, while one played games…
Tell that to kids these days, and they won’t believe you
If nature intended code to be “final” then evolution would have hit that point and stopped. Preventing a class from being inherited misses the point of being object oriented in the first place.
Final should be used to show intent – that class is final. This could for example be because more inheritance could violate LSP (Liskow Substitution Principle). If performance is needed virtual inheritance is the wrong construct. Just code without and show intent of no dynamic dispatch and the compiler will automatically generate performant code.
Easy and free has nothing to do with performance.
The identifier final is used to make sure functions are not modified by derived classes.
I don’t really trust the tests he wrote. He’s running a raytracer and I think the tests should be a lot more simpler/stripped down than that
eg https://quick-bench.com/q/Vk4Sv-92hi52pk2M3opWTUyPJnA
With final, I would assume you are invoking an additional condition check. For example, if final is used anywhere in a program, then every derived class would have to have a check for every function accessed to see if it was final or not. If the compiler doesnt see final in any of your code, it could leave this permission check out of the resulting program. That would make sense in longer execution times for final, just think of it as another permission check function.