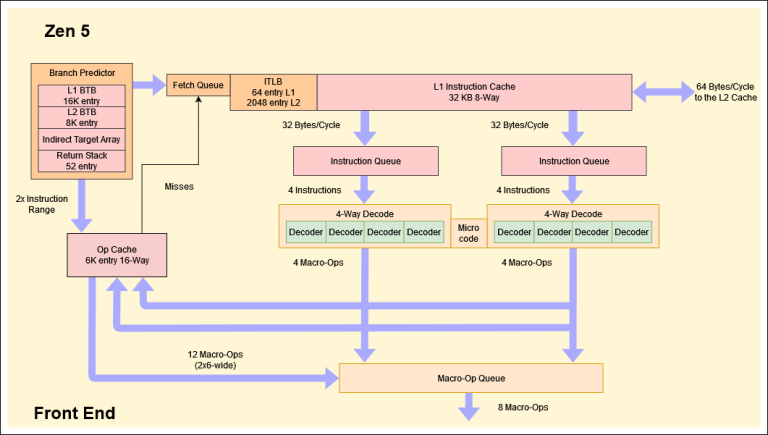
An interesting finding in fields like computer science is that much of what is advertised as new and innovative was actually pilfered from old research papers submitted to ACM and others. Which is not to say that this is necessarily a bad thing, as many of such ideas were not practical at the time. Case in point the new branch predictor in AMD’s Zen 5 CPU architecture, whose two-block ahead design is based on an idea coined a few decades ago. The details are laid out by [George Cozma] and [Camacho] in a recent article, which follows on a recent interview that [George] did with AMD’s [Mike Clark].
The 1996 ACM paper by [André Seznec] and colleagues titled “Multiple-block ahead branch predictors” is a good start before diving into [George]’s article, as it will help to make sense of many of the details. The reason for improving the branch prediction in CPUs is fairly self-evident, as today’s heavily pipelined, superscalar CPUs rely heavily on branch prediction and speculative execution to get around the glacial speeds of system memory once past the CPU’s speediest caches. While predicting the next instruction block after a branch is commonly done already, this two-block ahead approach as suggested also predicts the next instruction block after the first predicted one.
Perhaps unsurprisingly, this multi-block ahead branch predictor by itself isn’t the hard part, but making it all fit in the hardware is. As described in the paper by [Seznec] et al., the relevant components are now dual-ported, allowing for three prediction windows. Theoretically this should result in a significant boost in IPC and could mean that more CPU manufacturers will be looking at adding such multi-block branch prediction to their designs. We will just have to see how Zen 5 works once released into the wild.














More importantly, have they thought about how to protect it against speculative execution attacks?
Sure, if any (public) attacks occur, they just disable all but one with a patch with a “minor” performance hit.
Seeing that was one of the biggest and most heavily publicized security hole in the past decades, you can assume they did.
You can’t have a useful pipeline cache without fetch or branch predictors.
So you have two options available to pick from:
a) Use a chip with a pipeline, getting a huge speed and performance boost, then try your best not to let random people run their code on it, or
b) Use a chip without a pipeline, accept the slower speed as part of your life now, and hand out admin rights to whomever you please.
I don’t know any reason that fetch and branch prediction should be inherently unsafe. It’s the speculative execution that’s risky.
I don’t think there would be much advantage to branch prediction WITHOUT the speculative execution, and in addition, the fetching is also ‘potentially unsafe’.
Since it moves potentially privileged data from a far away location somewhere isolated and ‘close’ where side channel attacks are likely to be more viable.
The issue with any branch prediction is that there are situations where it will be wrong.
And ensuring appropriate data hygiene at all levels of the system after such a branch misprediction is incredibly tricky, especially in the context of the ever advancing complexity of attacks.
Of course.
Easy, just do any speculative execution in accordance with the access rights.
You know, 3D polygon graphics where pioneered first 500 years ago, check out Vase as Solid of Revolution by Paolo Uccello, which he made based on a book “On Painting” by Leon Battista Alberti. He describes there polygons, linear perspective projection, textures and theorizes about ray tracing.
Which 64 bit instruction formats do gcc c compiler writers use?
x86 and amd64 instruction reference.
https://www.felixcloutier.com/x86/
Percentage of all instruction formats?
Do you mean which instructions?
But the big question is if this costs less in terms of die space and performs better than multi-threading a single core. Intel is looking to remove SMT in future processors.
This might make a good replacement to keep IPC up?
Very interesting.
AMD of course is (using automatic design tools?) squashing ‘efficient’ cores of the same logic into a power and space optimized format. And also a high power, high clock format at much larger Die space.
They are somewhat orthogonal aspects. Doing hyper-threading is really to give you higher utilisation of the compute core during a significant stall on your active ‘thread’, there is still a large cost to changing thread contexts, you start to get into questions of how warm your cache is, etc, etc.
Branch predicting is more about minimising (or avoiding) small stalls, like missing a cache hit on the first access of a branch.
They almost target entirely different orders of magnitude of ‘delays’. Hyper-threading makes switching between execution contexts more efficient (for situations like the thread needs to read something from disk, or perform other IO) like one car shared between two people, whilst branch prediction is raw execution speed on winding roads, not having to slow down for corners, because it can see them coming and get the right ‘racing line’.
I could see better threads for an OS for example.