
Ring buffers are incredibly useful data structures that allow for data to be written and read continuously without having to worry about where the data is being written to or read from. Although they present a continuous (ring) buffer via their API, internally a definitely finite buffer is being maintained. This makes it crucial that at no point in time the reading and writing events can interfere with each other, something which can be guaranteed in a number of ways. Obviously the easiest solution here is to use a mutual exclusion mechanism like a mutex, but this comes with a severe performance penalty.
A lock-free ring buffer (LFRB) accomplishes the same result without something like a mutex (lock), instead using a hardware feature like atomics. In this article we will be looking at how to design an LFRB in Ada, while comparing and contrasting it with the C++-based LFRB that it was ported from. Although similar in some respects, the Ada version involves Ada-specific features such as access types and the rendezvous mechanism with task types (‘threads’).
Port Planning
The C++ code that the Ada LFRB is based on can be found as a creatively titled GitHub project, although it was originally developed for the NymphCast project. In that project’s usage scenario, it provides a memory buffer for network data as it’s being fetched from a client and made available to the local media player. Here the player requests additional data when it doesn’t have enough buffered data to decode the next frame, resulting in a read request to the LFRB. If its buffer doesn’t have sufficient data left to fulfill the read request, it triggers the data request task, which for NymphCast means fetching more data from the client until the LFRB’s buffer is full again.
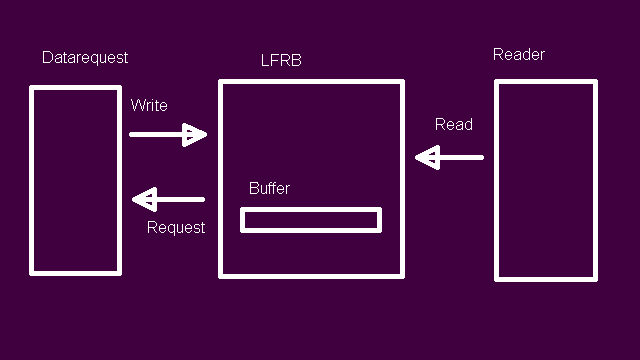
With this C++ version we are using only C++14-level features, including std::thread, std::chrono, mutexes and condition variables. For the internal buffer we use a heap-allocated buffer, a uint8_t array, with raw pointers into this array which keep track of the reading and writing locations, alongside a number of atomic variables for the number of free bytes, unread bytes, buffer capacity, and so on. This means that while seemingly simple, the main trick lies in properly updating the pointers and variables to properly reflect the current state.
So what would the Ada version look like? We would need a heap-allocated buffer, obviously. Here we would use a simple array, which has the advantage in Ada that its arrays are bound-checked during compile- and run-time. Meanwhile the uint8_t* pointers are replaced with simple index trackers, which will use the predefined Unsigned_32 type from the standard Interfaces package. This guarantees that we can have a buffer capacity of up to 4 GB, just in case that much is ever needed.
For the data request thread we use an Ada task, which is effectively the same thing as in C++, just with it being a native part of the language. This means that no packages have to be included and task synchronization mechanisms are also an integral part of the core language. What we do notice here is that Ada’s multi-threading features are very different from that found in other mainstream languages which overwhelmingly follow the POSIX pthread model. We will look at this in more detail when we get to this part of the design in the next part of this series.
Unchecked Operations
Although in Ada we can allocate more memory as much as we want using the new keyword, one thing which the language doesn’t like you to do is deallocating it, akin to free or delete in C and C++. This is because manual deallocation like this is a common source of really bad things, so you’re generally asked to not do this and instead rely on the automatic deallocation methods. If you feel that you really, really have to do manual deallocation of previously allocated memory blocks, you can do so via the Ada.Unchecked_Deallocation package that was added with Ada 95.
Since we would like to maybe get rid of the buffer which we allocated when the LFRB’s capacity was set, for example when the user demands that a differently sized buffer is created, or just for housekeeping reasons when shutting down the application, we have to enter unchecked territory. Fortunately, this isn’t hugely complicated, merely requiring us to define a procedure that uses the provided generic template from the Ada.Unchecked_Deallocation package.
To demonstrate this, we can implement the allocation and deallocation, starting with allocating the byte array:
type buff_array is array(Unsigned_32 range <>) of Unsigned_8; type buff_ref is access buff_array; buffer : buff_ref; buffer := new buff_array(0 .. capacity);
As the new allocation returns an access type reference (‘pointer’) for the type which we are allocating, we need to define a type for this and use this as the reference from then onwards.
When we’re done with the array, we need to use the custom function which we defined as follows:
with Ada.Unchecked_Deallocation;
procedure free_buffer is new Ada.Unchecked_Deallocation
(Object => buff_array, Name => buff_ref);
free_buffer (buffer);
To create a deallocation procedure, we just need to provide the generic template with the details of what we’re trying to deallocate. This means the buff_array type for the object type and buff_ref for the access type name (the ‘pointer’ type). These correspond to the types which we defined earlier when we allocated the buffer.
Setting Bounds
To be able to safely write and read the buffer’s contents, we need to keep track of more than just the current read and write indices. We also need to know the starting index of the buffer (always 0), the last index (capacity – 1), as well as the current number of free and unread bytes. The latter two start at zero and are updated as data is written and read. This is similar to the C++ version, except for a few offset differences due to the C++ version using mostly pointer arithmetic and this Ada port pure array indices. We are of course free to start an Ada array at any index (like 1) we desire, but for this port we are sticking to 0 as the first index because it’s tradition.
One nice thing about Ada is that if we do get an offset or index wrong, we get a constraint_error exception raised during runtime, along with the where and how. For example if we go out of bounds an Index Check is raised:
raised CONSTRAINT_ERROR : datarequest.adb:26 index check failed
Then if we use array slices to write to or copy from part of an array, making a mistake there gets us a Length Check:
raised CONSTRAINT_ERROR : lfringdatabuffer.adb:329 length check failed
Here array slices follow the pattern of array(first .. last), where the first byte that’s part of the slice is specified with first and the last byte to be included with last.
Dereferencing
This leaves us with one more detail regarding access types, which includes the earlier array access type, as well as that of procedure, function and task access types (first two called function pointers in C++ nomenclature). For our array access type this is fairly easy, as demonstrated when e.g. creating an array slice to write data into the buffer:
buffer.all(data_back .. writeback) := data;
Dereferencing on the buffer array is done using .all, after which we can use it as normal. For references to procedures, functions and also tasks it’s even more straightforward, which we will take an in-depth look at in the next part as we begin to implement the LFRB and assemble all of the pieces which we have discussed in this article.














I’ve used this great little guide on a similar lock-free implementation for single-producer / single-consumer in C – https://embedjournal.com/implementing-circular-buffer-embedded-c/ thought I might share here since ring-buffers in embedded work are crucial to get right.
Oooh thanks. I need to figure one out
Single producer/consumer lock free is a walk in the park.
I have yet to see a lock free implementation for complex cases.
Well, it’s pretty easy to make a ring buffer without a lock it it’s single producer – single consumer, and you are happy to throw away data if it is full.
And I agree there are many times – ie some sensor readings – when you can throw data away..
However, if any of those assumptions isn’t true, you’ll be having to use a lock somewhere..
Sure, ‘lock free’ is also a matter of definition as can be read on in e.g. “An Introduction to Lock-Free Programming”, https://preshing.com/20120612/an-introduction-to-lock-free-programming/ .
Here lock free is attained through using atomic operations instead of mutexes/locks around non-atomic operations.
That page and definition is good – but it’s definition of ‘lock free’ (which I don’t have a problem with) means that the code in this article is ‘lock free’ only because you can’t suspend the task during a ‘atomic’ operation, and another task can’t run while you are doing it.
So it’s more a statement of atomic operations than locks as such..
Everything old is new again.
Lock free databases, by running all updates on a single database update thread.
Still a dumb idea.
JS kids are spending years developing, to save hours in the library.