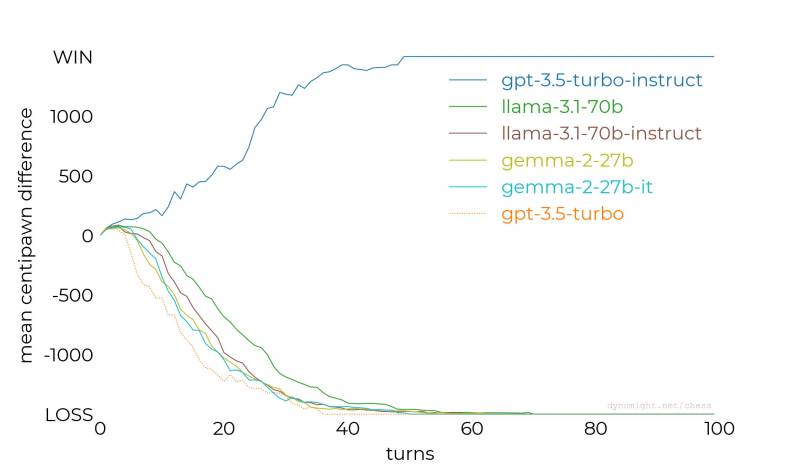
At first glance, trying to play chess against a large language model (LLM) seems like a daft idea, as its weighted nodes have, at most, been trained on some chess-adjacent texts. It has no concept of board state, stratagems, or even whatever a ‘rook’ or ‘knight’ piece is. This daftness is indeed demonstrated by [Dynomight] in a recent blog post (Substack version), where the Stockfish chess AI is pitted against a range of LLMs, from a small Llama model to GPT-3.5. Although the outcomes (see featured image) are largely as you’d expect, there is one surprise: the gpt-3.5-turbo-instruct model, which seems quite capable of giving Stockfish a run for its money, albeit on Stockfish’s lower settings.
Each model was given the same query, telling it to be a chess grandmaster, to use standard notation, and to choose its next move. The stark difference between the instruct model and the others calls investigation. OpenAI describes the instruct model as an ‘InstructGPT 3.5 class model’, which leads us to this page on OpenAI’s site and an associated 2022 paper that describes how InstructGPT is effectively the standard GPT LLM model heavily fine-tuned using human feedback.
Ultimately, it seems that instruct models do better with instruction-based queries because they have been programmed that way using extensive tuning. A [Hacker News] thread from last year discusses the Turbo vs Instruct version of GPT 3.5. That thread also uses chess as a comparison point. Meanwhile, ChatGPT is a sibling of InstructGPT, per OpenAI, using Reinforcement Learning from Human Feedback (RLHF), with presumably ChatGPT users now mostly providing said feedback.
OpenAI notes repeatedly that InstructGPT nor ChatGPT provide correct responses all the time. However, within the limited problem space of chess, it would seem that it’s good enough not to bore a dedicated chess AI into digital oblivion.
If you want a digital chess partner, try your Postscript printer. Chess software doesn’t have to be as large as an AI model.














Stockfish is not AI.
It is AI. The problem you are having is that you have completely bought into the marketing department’s idea of AI when it’s actually a entirely subjective designation. Too bad for you.
Sorry, you are the one that bought into it. LLMs aren’t AI either.
i wouldn’t mind hearing your definition
fwiw i tend to retcon it…once we know that AI is nothing but a pattern matching system, i am inclined to say that natural intelligence is nothing but a pattern matching system. what do you say
That may be. In humans the size of the weighted model is just significantly more vast than current llms.
Stockfish is definitely AI as defined by NIST and other widely accepted definitions of AI.
It is not “generative AI”.
For that matter, spellcheck, autocorrect and spam filters are all “AI”.
None are generative AI.
Software that can be considered AI has existed for at least 60 years.
You mean there DOD definition? NIST doesn’t have one and the DOD version can be satisfied by a slide rule. None of these things are AI, that’s marketing. Applied models were called expert systems before the current boom.
In my limited experience of trying to get an LLM to play chess, the main problem is that they will very frequently give an illegal move, as they have no concept of the board state. Constraining the results to legal moves really doesn’t seem like a “fair” assessment of the LLM’s playing strength to me.
It also seems like a possible vector for corruption of the results, although I’m still trying to figure out how that happened in this case. For example, if the legal moves were generated by reading the output from Stockfish in multi-variation mode then they would be ordered from best to worst and so an LLM picking a move nearer to the start of the list would perform better.
It seems like the author has an idea what’s going on but isn’t saying… yet.
Can you let me know about your post? Thanks!
It doesn’t look like this kicked in yet, but I’d think eventually the instruction to be “a chess grandmaster” becomes more hindrance than good: GMs are weaker than Stockfish at any reasonable strength. The Stockfish settings used were very weak though.
(There’s also the fact that the LLM is, in effect, a single node search depth – “policy only”, if I have the jargon right. But that’s not really distinguishing as far as I know.)
Whatever you want to call all of this is just a list of instructions written by a programmer to do a task given a data set. No more no less. Handy for some jobs. AI is just a glowing marketing term to get the masses to spend money on subscriptions or whatever.
Golly I had no idea the self-hosted LLM RAG I have been using was costing me money. /s
I love the comments because they quickly reveal who does and does not comprehend how machine learning works.
Again, AI is a very broadly defined term. Look at NIST or ISO or OWASP resources. Heck, read a Wikipedia article on Alan Turing and Marvin Minsky and perceptrons and the (re-)birth of deeply layered neural nets.
AI, machine learning, deep learning, generative AI, RAG are not just “marketing terms” and in some cases have very very different meanings.
Saying they’re just “instructions written by a programmer” is a very inaccurate way to describe LLM, RNN, CNN, etc. outputs.
In fact that’s the whole point and has nothing to do with marketing or subscriptions.
The mystery is less of a mystery – that specific model was trained on millions of chess games! They specifically included all games above some ELO threshold, in PGN notation IIRC. I’m having trouble finding a public source, I’ll update if I find a link so you don’t have to trust me :)
Sounds to me like a roundabout way of creating expert system AIs. It’s the 1970’s all over again.
Expertise is what we learned not to use. For decades, every step of the way smart people people like yourself desired to program or guide the model based on expertise but turns out that was the bottle neck.
But we are mostly blind to why we do things, even experts. If you pause and think sincerely to why you make decisions, you will start to see that most of what happens is automatic and emotional where conclusions come first. And you will start noticing this in others.
Instead of asking an expert to explain their reasoning, all we needed was a way to compress information (attention) and to leverage compute and data.
I think a lot about this too because I’ve been around a lot of experts. I have a masters in electromagnetics and photonics, went to medical school, worked on high level projects at national labs, etc.
I often feel like an imposter even when I have solved problems that other obviously more expert than me were blocked, and continue to do so. It feels like there is something else besides the thing we call intelligence or expertise that is more critical. And I think this other thing is what we will start valuing more as opposed to expertise. I see it happening now in software and in medicine.
Very well said!
It is that kind of “thing” that is / will be very difficult (imposible ?) to replicate/automate.
We can call it creativity, “thinking out of the box”, serendipity, you-name-it…
May be, some day, who knows… we must keep trying, and hoping, and (humbly) learning as we go…
Best regards,
Daniel F. Larrosa
Montevideo – Uruguay