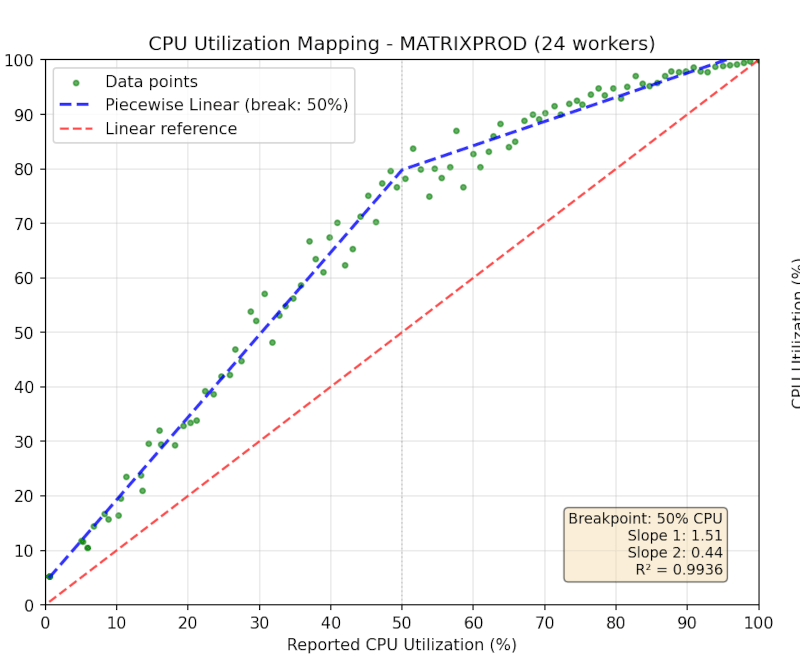
If you ever develop an embedded system in a corporate environment, someone will probably tell you that you can only use 80% of the CPU or some other made-up number. The theory is that you will need some overhead for expansion. While that might have been a reasonable thing to do when CPUs and operating systems were very simple, those days are long gone. [Brendan Long] explains at least one problem with the idea in some recent tests he did related to server utilization.
[Brendan] recognizes that a modern CPU doesn’t actually scale like you would think. When lightly loaded, a modern CPU might run faster because it can keep other CPUs in the package slower and cooler. Increase the load, and more CPUs may get involved, but they will probably run slower. Beyond that, a newfangled processor often has fewer full CPUs than you expect. The test machine was a 24-core AMD processor. However, there are really 12 complete CPUs that can fast switch between two contexts. You have 24 threads that you can use, but only 12 at a time. So that skews the results, too.
Of course, our favorite problem is even more subtle. A modern OS will use whatever resources would otherwise go to waste. Even at 100% load, your program may work, but very slowly. So assume the boss wants you to do something every five seconds. You run the program. Suppose it is using 80% of the CPU and 90% of the memory. The program can execute its task every 4.6 seconds. So what? It may be that the OS is giving you that much because it would otherwise be idle. If you had 50% of the CPU and 70% of the memory, you might still be able to work in 4.7 seconds.
A better method is to have a low-priority task consume the resources you are not allowed to use, run the program, and verify that it still meets the required time. That solves a lot of [Brendan’s] observations, too. What you can’t do is scale the measurement linearly for all these reasons and probably others.
Not every project needs to worry about performance. But if you do, measuring and predicting it isn’t as straightforward as you might think. If you are interested in displaying your current stats, may we suggest analog? You have choices.














You normally see them in server sockets; but you can get CPUs aimed at minimizing the effect; normally fairly low core counts by the standards of the socket, so cores aren’t contending for power and thermal headroom with one another, and relatively modest differences between base and boost clocks(often with the option of more aggressive measures like disabling hyperthreading, boosting, or dynamic clocks entirely). There’s also the class of high core count predictability oriented CPUs(Ampere, in particular, seems to favor these; or at least talks them up to put a brave face on their tepid single threaded performance) aimed at people VM farming who want ‘1vCPU’ to be a consistent unit of measure when chopping a host up; rather than having actual VM performance wiggling around depending on how heavily loaded other VMs on the same socket are.
Sort of a niche; because ‘consistency’ is generally a nice way of saying ‘leaving performance on the table sometimes’ and you can often get more throughput on a ‘worker processes completing within SLA’ basis with one of the less predictable parts; and systems where nobody has really taken a hard look at careful scheduling or you are stuck with relatively single-threaded workloads can be absolutely saved by what a modern CPU can do to knock idle cores to low power and throw the savings at maximizing per-thread performance on the heavily loaded ones; but absolutely a niche large enough to keep getting made(mostly for server sockets; sometimes in embedded-oriented desktop or mobile derivatives; not so much in generalist desktop and mobile parts, where the assumption is normally that being able to adjust wildly to cope with whatever random nonsense generalist use throws at you is a virtue).
i don’t understand. i feel like i just read a story my wife is telling me, where she debates the merits of some idea but forgot to introduce the idea itself :)
it seems like the goal is to estimate the amount of server resource you need in order to handle a heavy load, while only actually using a light load during testing. that is fundamentally pointless. nothing scales linearly. and i mean nothing. the underlying real complexity of the problem won’t scale linearly, and neither will the awful real world implementation. “does the os-reported cpu utilization scale linearly” will not even be a footnote compared to those.
the design task before you meet a real load is to design your software to be scalable. minimize dependencies and bottlenecks.
for an existing server load, i just can’t imagine any utilization metric other than “is it slow? is it reliable?” if you have a server supporting 100 simultaneous users, and it runs on a monolithic server that can’t be scaled, and you want to add 100 new users in one step, my assumption is that you’re screwed whether it’s at 10% or 90% utilization. you’re a growing organization with an unscalable backend and it simply can’t work. but i can’t imagine there’s any shop in the world that wouldn’t just add the 100 users and watch it fall over before doing anything about it. because if they were forward-thinking, they would have designed it to be scalable. i hope no one is forward-thinking and asks “how long until my unscalable solution falls over”!
Take out the word embedded and everything reads right: These are the issues you have to deal with when using high performance CPUs that support out-of-order execution of instructions, deep pipelining, multiple levels of cache, multiple cores. These offer speed at the expense of tight predictability of latency. This is the world of Intel and AMD and A-series ARM processors (A-76, A-53, etc).
A typical embedded project, using an M-series ARM or other similar CPU, will have more predictable execution times once DMA is accounted for. Primary among the considerations in this environment is the time from receipt of a signal on an interrupt pin, the time spent servicing the interrupt. These impact the context switching time guarantees.
I agree, it’s a lot easier to predict interrupt latency on an embedded project. Bare metal programming really helps too.
There are a few considerations though. Some Cortex-M cores have cache. The NVIC supports tail chaining – if the core is already in exception handler mode there’s no need to pop the thread context off the stack only to push it right back on again. Then there’s also different Flash access methods that can impact latency in hard-to-predict ways (not a Cortex-M situation, but relevant nonetheless).
Years back I wrote some interrupt handler code for an 8051 that would exactly compensate for the jitter caused by whatever multi-cycle instruction was being interrupted. I was using a timer interrupt for waveform generation so the slight increase in latency wasn’t an issue, but the jitter was.
After I started working with the STM32F051 (Cortex-M0), I found it much more difficult to make it work the same way. I could improve the jitter distribution but could not completely compensate for it. There are hardware resources available to help with waveform generation, and that’s what I wound up using.
Perhaps this is an extreme example of needing deterministic interrupt latency, but it is an occasional requirement for an embedded project.
There are MCU cores that have highly predictable latency behavior, and on Cortex-M you can turn off some of these optimizations for a performance penalty.
Or you could use XMOS sCORE processors where the IDE will examine the optimised binary to determine the exact cycle count through every code path. Plus up to 32 cores per chip, with a software environment that encourages you to use the hardware parallelism.
Embedded is annoyingly overloaded term these days. It can include anything from a MHz RISC-V MCU running 100 lines of pure C to a GHz ARM SoC running Linux with Docker containers.
His testing is kinda worthless with PBO enabled, as it’s precise job is to speed up the processor when it is not at the absolute limits. (Absolute limit is if course a difficult thing to find as different instructions and any bottlenecks can result in “wait cycles”)
I think he did just measure PBO effectiveness however. Since he didn’t mention which PBO he was using it’s double useless as a metric because PBO gets updates and can improve performance and thermals if you believe the anecdotal evidence of gamers.
Also he may have proved that a 6 or 8 core processor is a better value proposition if the cost scales linearly (although it often doesn’t, making them even better value). For a single workstation; for a scaleable server the difference may be a little tighter, especially if you consider cost of additional sockets.
I agree but lets throw some more mud into the water. If you don’t know what a superscalar processor is, and how that might affect cpu utilization, you cannot really tell whats being utilized. Also, add in the different types of execution units. (GP, memory, logic, vector, floating point) and understand when resources are shared and when they aren’t…and it gets really really muddy!
Modern machines are even more absurd. Not only CPUs slow down when when they get hotter, but as the fans kick in and generate more vibration the disk heads suddenly generate more misses and the disk I/O speeds are going down. And yes, you can measure that. And if you want reproducible benchmark results stuff like sun shining directly at wall of your server room can introduce small deviations in the test results.
The “Shouting in the server room” video comes to mind
Brendan mentions [quote] Ryzen 9 5900X (12 core / 24 thread) processor[/quote] which seems correct, but hackaday simply calling this a “24 core” machine and then a few sentences later cutting that in half annoyed me enough to just stop reading the article right there.
It’s very common for “PC” CPU’s to have two threads per core, but when you start mixing that up it gets really confusing Brendan just mentioning the part number of his processor is much clearer here.
I first thought this was about uC’s. For my own project, I think I rarely get above 0.1% CPU utilization. And then I connected an TFT to my AVR, and suddenly the menu’s rendered very slow, so that was barely an option.
Now I’m dabbling with ARM Cortex, and I’ve seen demo’s of pushing 30+ FPS to a decent size TFT. Last week I did a bit of reading, as I’m thinking of doing software RMS calculations for Voltage / Current / Power and STM32F411 (max 168MHz) does apparently a float multiply & accumulate in 3 clock cycles. That means you’d need a pretty quick (external) ADC to stress it out.
uC’s are a bit weird here. It’s quite often either <0.1% or “not enough”. Multi core uC’s (running something like FreeRTOS) are an interesting development. It allows you to assign one core to some critical task, while the other can do the house keeping.