
Git is one of those tools that is so simple to use, that you often don’t learn a lot of nuance to it. You wind up cloning a repository from the Internet and that’s about it. If you make changes, maybe you track them and if you are really polite you might create a pull request to give back to the project. But there’s a lot more you can do. For example, did you know that Git can track collaborative Word documents? Or manage your startup files across multiple Linux boxes?
Git belongs to a family of software products that do revision (or version) control. The idea is that you can develop software (for example) and keep track of each revision. Good systems have provisions for allowing multiple people to work on a project at one time. There is also usually some way to split a project into different parts. For example, you might split off to develop a version of the product for a different market or to try an experimental feature without breaking the normal development. In some cases, you’ll eventually bring that split back into the main line.
Although in the next installment, I’ll give you some odd uses for Git you might find useful, this post is mostly the story of how Git came to be. Open source development is known for flame wars and there’s at least a few in this tale. And in true hacker fashion, the hero of the story decides he doesn’t like the tools he’s using so… well, what would you do?
War of the Version Controllers

Historically, a lot of software that did this function had a central-server mindset. That is, the code lived on the network somewhere. When you wanted to work on a file you’d check it out. This only worked if no one else had it checked out. Of course, if you were successful, no one else could check out your files until you put them back. If you were away from the network and you wanted to work on something, too bad.
However, more modern tools relax some of these restrictions. Ideally, a tool could give you a local copy of a project and automatically keep other copies updated as you release changes. This way there was no central copy to lose, you could work anywhere, and you didn’t have to coordinate working on different things with other teammates.
Closed Tool
A very large distributed team develops the Linux kernel. By late 1998 the team was struggling with revision management. A kernel developer, [Larry McVoy], had a company that produced a scalable distributed version control product called BitKeeper. Although it was a commercial product, there was a community license that allowed you to use it as long as you didn’t work on a competing tool while you were using the product and for a year thereafter. The restriction applied to both commercial and open source competition. Although the product kept most data on your machine, there was a server component, so the company could, in fact, track your usage of the product.
 In 2002, the Linux kernel team adopted BitKeeper. [Linux Torvalds] was among the proponents of the new system. However, other developers (and interested parties like [Richard Stallman] were concerned about using a proprietary tool to develop open source. BitMover — the company behind BitKeeper — added some gateways so that developers who wanted to use a different system could, to some extent.
In 2002, the Linux kernel team adopted BitKeeper. [Linux Torvalds] was among the proponents of the new system. However, other developers (and interested parties like [Richard Stallman] were concerned about using a proprietary tool to develop open source. BitMover — the company behind BitKeeper — added some gateways so that developers who wanted to use a different system could, to some extent.
For the most part, things quieted down with only occasional flame skirmishes erupting here and there. That is until 2005 when [McVoy’s] company announced it would discontinue the free version of BitKeeper. Ostensibly the reason was due to a user developing a client that added features from the commercial version to the free one.
New Tools
As a result, two projects spun up to develop a replacement. Mercurial was one and Git, of course, was the other. [McVoy] contacted a commercial customer demanding that their employee [Bryan O’Sullivan] stop contributing to Mercurial, which he did. Of course, both Mercurial and Git came to fruition, with Git becoming not only the kernel team’s version control system but the system for a lot of other people as well.
Birth of Git
[Linus] did look for another off-the-shelf system. None at the time had the performance or the features that would suit the kernel development team. He designed git for speed, simplicity, and to avoid doing the same things that CVS (a reviled version control program) did.
Initial development is said to have taken a few days. Since the version 1.0 release in late 2005, the software has spawned more than one major website and has become the system of choice for many developers, both open source, and commercial.
Repo Man
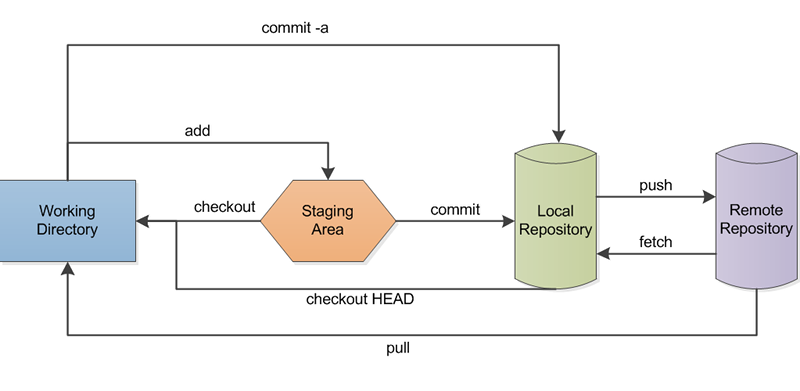
The flow chart shows the secret of how git handles lots of developer’s at one time: repositories or repos. Each developer has a total copy of the entire project (the local repository). In fact, if you don’t care about sharing, you don’t even need a remote repository. Your private repo is as much a full-featured git project as anyone else’s, even the remote one, which is probably on GitHub or another network server. You make your changes in the working directory, stage what you are “done” with (for now), and commit it to your repo. When it is time, you push your changes up to the remote and it gets merged with other people’s changes.
Interestingly, git doesn’t only work on text files (I’ll show you more about that in the next installment). It does, however, work best on text files because it is smart enough to notice changes in files that don’t overlap and merge them automatically. So if I fix a bug involving a for loop in some code and you change some error messages, git will sort it all out when our code merges.
That doesn’t always work, of course. That leads to conflicts that you have to manually resolve. But unless you have two people touching the exact same parts of the code, git usually does a nice job of resolving the difference. Of course, binary files don’t generally get that luxury. You can’t exactly diff an icon to see that one person drew a mustache on it and another person turned the background green. However, technically, if you could figure out the algorithm, you could add it into git.
Denouement
If you want to increase your knowledge of git beyond just doing a clone, you could do worse than spend 15 minutes on this tutorial. If you already know the basics, you might find some new things in a more advanced tutorial or check out the video of a talk [Linus] gave on git a while back.
In 2016, by the way, BitKeeper announced they would move to the Apache License which, of course, is open source. Kind of ironic, isn’t it?
https://www.youtube.com/watch?v=8ET_gl1qAZ0
Photo credits:
- Tux Soldier, by [Sharkey], CC BY-SA 3.0
- [Linus Torvalds] from Linux Magazine, CC BY-SA 3.0
- Flowchart by [Lbhtw], CC BY-SA 3.0














https://xkcd.com/1597/
Yup, that’s me. :)
Who is Linux Torvalds? (That’s a bit like Homer with “what is le grille” in the building a BBQ episode but nevertheless. :)
> https://xkcd.com/1597/
Soooo true!
I use Git for years now but far too infrequently and still sometimes screw up my local or remote repos… but luckily not both at once… ;-) …so it’s not ragnarök!
I believe you can’t really screw up a git repo as it is mostly (very very mostly) append only structure and hardly ever anything gets thrown away for good. That being said, you can always checkout a commit that was good and git reflog is your BFF.
Yup, me too. Although using GitKraken does make life easier.
GitKraken seriously changed life around my company. Git went from an arcane tool that everyone was afraid to enrage, to a meaningful system of collaboration. I have always been a git/bash guy, but its honestly so easy to use that i have even converted to GUI… their scrum/project management tool AxoSoft isn’t too shabby either.
http://ohshitgit.com/
+1. I have learned a new thing.
“no one else could check out your files until you put them back” This was never true, even using the now obsolete RCS. From RCS documentation:
Locking assures that you, and only you, can check in the next update, and avoids nasty problems if several people work on the same file. Even if a revision is locked, it can still be checked out for reading, compiling, etc. All that locking prevents is a checkin by anybody but the locker.
Technically true, yes. But git handles this “locking” automatically by different means. Repositories with read-only access allow you to change whatever you want to, and even push changes to another repository. But if you want your changes to be merged to the repository and branch you checked out from, you send a “pull” request (this is how github does it). Seems like I’ve encountered git addons that do per-branch permissions within repositories as well.
There is plenty of software that does lock checkouts. Cadence circuit simulator, for example.
Look like to be a very unusual case to me, maybe because of other technical reasons. There are others Cadence software that uses lock normally. For example from Cadence support site:
“The Design Entry HDL (DEHDL or ConceptHDL) .lck files are generated whenever a designer opens a page of a schematic. If another designer attempts to open the same page of the schematic, they will receive a warning that the page is in read-only mode and they will not be able to write to that page.”
Also SolidWorks.
I remember we had problems with this on Litestep back in the day (before 2000). I want to say we were using CVS? For bonus points, it was hosted on a contributor’s university account in South Africa, so for nearly everyone involved it was excruciatingly slow.
A bunch of the commercial VCSes did this, so “never true” is incorrect. IBM’s ClearCase is the one I had the misfortune of encountering a few years back.
I predict this article only receiving 5 replies!
I get annoyed at repo admins in a corporate/enterprise environment insisting on using git over a central tool like subversion because of some righteous religious doctrine. They then wonder why developers doing new pulls for a local sandbox of very large – very legacy projects take hours or even days to get it all and eat GBs or TBs of network bandwidth – multiplied by hundreds of devs. There are ways of mitigating this in git, however it’s not intuitive to most in the same way (eg) subversion is. While I can’t blame the tool, I can certainly blame it’s ease of use.
As git is now used on more and more large projects, it will be gradually optimized for that workload. Some big company don’t use git because of scaling issues, but there mostly use some others modern tools instead of the venerable subversion.
If the Linux kernel isn’t large, then what is?
You can run a bank with 22M lines-of-code!
Uh, I don’t know that SVN (subversion as you mentioned) does very well as scalable tool. I’ve used all of them, CVS, SVN, and git with large organizations having large teams and large codebases, and only git seems to scale well. The key word here is DISTRIBUTED. Neither CVS nor SVN have any concept of being distributed. That’s the key scalability difference between these systems. Git can be centralized if you want it to. But it doesn’t have to be, and it isn’t limited by being so. Tell us how github would work at all with SVN. Then tell github their system isn’t scalable. Nothing religious about it.
I’m actually in love with git, but just wanted to clarify a couple things.
GitHub supports SVN
https://help.github.com/articles/support-for-subversion-clients/
Microsoft needed to build custom tools to use git at scale
https://github.com/Microsoft/GVFS
Microsoft problem was more related to defective NTFS performance and inability to split a really over big repository into coherent sub-projects.
I used to transfer repositories within machines using an archive file (sometimes USB sticks were faster than using the network), which was a way faster that svn or git for cloning a repo.
Git, svn or even rsync transfers data in a same way, with a huge overhead for checking and keeping the revision history. It’s very efficient for daily or weekly syncs, but it’s terrible when there are lots of changes on either side of the repo.
I am not “racist” among sync/version tools, although I definitely agree with you on git’s ease of use…
I fail to see how subversion is any better in this regard – since you HAVE to sync from the server EVERY time.
Also, one of the things that fundamentally drives people towards distributed VC systems (even if their development model is mostly centralized) – More and more people do their work on laptops, which may not have network connections 100% of the time.
SVN becomes useless if the network is down, that alone makes it unsuitable in modern times.
It’s a trade-off. Most enterprise configurations have network connectivity 100% of the time.
When you are working on a product with 480 git project repos and thousands of developers contributing every day, checking out the history of all that code when all you really want is the latest commit can take some time. There are intelligent ways to manage distributed VC with large projects with large commit logs, but most people read chapter 1 of a HOWTO and default to git pull. It takes a deeper understanding and attention span to work with git in that environment and that doesn’t always work with a 75% mix of greenhorns you find in most large companies.
git clone –depth=1
“Most enterprise configurations have network connectivity 100% of the time.”
Most enterprises never have anyone travelling for work and never have people take a vacation and need to get something done while they’re away?
Care to at least /share/ whatever it is your smoking?
Hmm. that makes me the fifth replier. Oh well
git clone –depth 1
You’re welcome.
“However, more modern tools relax some of these restrictions. Ideally, a tool could give you a local copy of a project and automatically keep other copies updated as you release changes.” Confusing words.
Even the old RCS give you a local copy on where you can do anything you wants. The locking is only there to forbid more than one person to modify a file on the server side only. No control system I know, even git, keep other copies updated as others releases changes, and I don’t think this is a desirable feature. Updating is always an explicit command to do.
ClearCase did. It was magnificent. It was also $5K per user, required Monster Hardware for the server, and with ~45 developers we had to have a full-time ClearCase administrator and release manager. Then again, we also kept a few custom branches in there (because we couldn’t expose any part of any customer’s custom code to the other users, and Java de-compiles beautifully). IBM wound up owning it so it’s probably close to dead now.
Oh, my bad – IBM is maintaining it after all. Looks like they’ve done a little bit of work. They had some big clients back in the day, so maybe some big shops are still using it. Dunno.
I hated every second I had to use ClearCase or any other tool that IBM bought from Rational and left unchanged for years. Perforce however was very nice and simple. Although they put the “Revert” and “Repair” (I think) buttons next to each other in the Windows context menu, which once led to a bit of lost work on my part.
We still use ClearCase (and ClearQuest to go with!) at work, for a ~10MLOC codebase. Starting to wind it back now in favour of git.
ClearCase has a hellish learning curve to do even very basic stuff, but the way it allows you to combine components into baselines then evolve them separately (and keep track of it all properly) is much more powerful than any other CM tool we’ve tried, including git. Of course more power is more opportunity to break your repository, so it’s a hard tradeoff to make.
Magnificent? Craptastic, in my opinion. Waiting for it to incredibly slowly check in and check out files was the basis for me to play with creating my own RCS. That basically stopped in it’s tracks the second I found Perforce. Perforce is the high performance tool RCS should be. It worked, 15 years ago, about three times faster in a remote fashion over my slow internet connection than ClearCase/ClearQuest did on the local LAN at my employer at the time.
I don’t get this: what is the relationship between Git and GitHub? I mean, the actual git-scm (https://git-scm.com/) page seems to be hosted on gitHub, so is gitHub the “main” system used by Git or not?. The article mentions gitHub only once (CTRL +F’ed it).
GitHub is just a collection of freely available remote repositories. You can create there a project and push your local repository there for other people to clone it.
git-scm is not hosted on GitHub per se (github does not handle http requests), but its source code is hosted on github, since GitHub is the “facebook of developers” : it has the most “social” features on its web UI. This is done to aid people in modifying this website.
GitHub is not affiliated with Git itself, as the git developers use some other repository for it. Moreover, the “git/git” repo (https://github.com/git/git) is, as stated by the developers, only a mirror of their own remote repository.
Actually you can host a website from a git repo on GitHub! https://pages.github.com
GitHub is a hosting provider for git repositories in the cloud. The git project uses them to host their code and their website like many other opensource projects.
Github is hosted git service. Just like you can host your own web site, you can host your own git repository. Or you can pay Github to do the hosting for you (and its free for open source projects). It also provides some “social coding” features like pull requests and issue tracking, and contributor graphing.
There are a bunch of hosted git providers that do similar things as Github: Kiln/Fogbugz, Bitbucket/Jira, Gitlab, and so forth. One thing I like about Kiln/Fogbugz is that when you reference a case number in your commit message to Kiln, it automatically logs an entry in that case in Fogbugz. Jira probably does the same. I think Github probably does too. So there are “value added” features like that in Github and others. I think there may even be some open source git hosting softwares that have issue trackers doing similar things.
I find Gitlab has an amazing bug tracker.
One of the neat features is that you can mention “Fixed issue #314” in commits and it will not only reference, but close that issue.
Plus there’s lots of goodies like tagging and groups.
Remember Sourceforge? Github is the new hotness.
I never understood git until I saw that diagram
Thank you!
Sorry Al, I have to disagree with your characterization of git being “so simple to use”. Yes, cloning a repo and kicking off a build is easy, but when you start making changes, working in branches and (worst of all) trying to revert things it gets hairy quickly.
Example – How do I undo a local, uncommitted change? The “revert” command only works on committed changes. Instead you use the “checkout” command with a non-obvious double dash. This is the same command you also use to switch branches or create a new one. Go figure!
Reverting committed changes is usually simple. However, when it’s time to put it back, you’d best revert the revert. If you just re-merge the original branch, it will happily ignore your change and you are none the wiser since the merge completed.
What if I want to revert PART of a committed change? Go get your PhD to figure that one out!
Totally agree. Look anywhere for the pros and cons of git, and you’ll undoubtedly find “tough to learn” in most of them
Try git cola https://git-cola.github.io/
It makes looking and your changes and deciding what to revert (by selected lines for example) and the actual operation of reverting extremely easy. It also has many other features.
I can’t imagine going back to subversion now.
Looks like you got confused with Git’s wording. Equivalent to ‘svn revert’ isn’t ‘git revert’, but ‘git reset’. One resets the checked out set of files to what’s in the repo. There’s also a ‘git revert’, but this does something else.
Checking out an older version of a file, ignoring what’s in the latest commit? Simply tell Git this version: ‘git checkout HEAD^ myfile.c’. (HEAD is the latest/current commit, HEAD^ is the one before that)
Undoing part of a commit? Check out the older version, then commit that with ‘–amend’. Can be done for entire files, or even with hunks (parts of files) using the ‘-p’ option.
I think the secret of Git is to run ‘gitk –all’ all the time and reload that graph often. As soon as one can see what happens after every command, all the fog suddenly clears up and the brilliance of this tool appears.
When you run ‘git status’, it tells you what to do:
# Changes not staged for commit:
# (use “git add …” to update what will be committed)
# (use “git checkout — …” to discard changes in working directory)
> What if I want to revert PART of a committed change? Go get your PhD to figure that one out!
A revert isn’t special; ‘git revert’ is just a shorthand for a new commit doing the opposite of the original commit. You could checkout the files at the revision before the one which introduced the changes you want to revert:
git checkout revert^ path/to/file
then add back in the original content:
git add –patch path/to/file
Although I would do an interactive rebase to split the commit into two separate commits, and then work on them separately.
Hmm… Is GIT really a DVCS? Maybe a merge of GIT & Blockchain technology as storage and/or auth?
I stopped reading at “Git is one of those tools that is so simple to use, that …”
LoL. I found a web page that touted it self as the easy guide to git. It was several pages of instructions. Fail….
svn commit
svn update
all I need to remeber.
git, well , what is it. add, stage then push then upload then sync or was it merge, add or push and pull, or pull then push…. wibble…..
git add path/to/file/or/dir/
git commit
git push
Looks like it’s maybe one more command than svn.
Oh, wait, you can do
git commit -a
git push
Now they’re the same. I’m also pretty sure if you start doing some other things with EITHER version control system, you can list other commands, but your example is about as contrived as I can imagine.
Now yes, you have push vs pull, but c’mon, if you want your code over there, it’s a push. If you want the code over there to be here on your copy, it’s pull. That’s not exactly a brain twister.
I think git is the sharper tool. I used to like svn’s simplicity, but the more I learned with git, I started to think “how the hell would I do this with SVN???”
Really true. Good analysis.
Perhaps you didn’t recognize yet that Git is far more than a dumpyard for old code. If you’re satisfied with just committing, you could use and ordinary file backup tool just as well.
Git is about dealing, remixing, refining code changes. Experienced Git users commit first, then they test their code. Because commits can be refined any moment, just use ‘–amend’.
Every set of instructions or tutorials on Git have been horrible. How do people get started on this thing?
I’m following the try.github.io tutorial linked to on this page.
Everything seemed good until 1.10 – remote repositories.
So.. at this point I’ve created a local repository, added some files, done some commits and checked status.
Now is when I add the remote URL? How does this work. So.. the tutorial has me type in a GitHub url. Ok, I will forgive the lack of instructions on setting up my own remote server as I guess that’s not a beginner thing. Where does this url come from though? The tutorial pulls it from between cheeks apparently!
I’m going to guess that the “/try-git/” part refers to one’s GitHub account. Then “try_git.git” must be the name of the repository the user is creating. So.. do you just make up a unique name and it then opens a new repository for you on GitHub (assuming you have an account called try-git)? Or do you have to go to the server (GitHub.com) and create an empty or skeleton .git file with that name beforehand. What if you already have a try-git.git repository in your GitHub account? Is it going to overwrite it? Merge them? Throw an error?
What about authentication? GitHub doesn’t allow just anyone to upload anything under anyone else’s name right? Did we skip over a part where the real application would have asked for a password or something?
How about “origin”. Where did that come from?
Too much magic!!!
Now 1.11 – Pushing Remotely
Still wondering where “origin” came from. Now I am wondering about “master” too. Ok.. those names do make sense to me. The remote repository is your master copy. The local one, being where you originally started everything is therefore the origin. Ok.. but how did they get named. More importantly… When I go to download this on a second machine, or a second person does, or I create a branch… how are those going to be named?!?
Why do I even have to specify origin? I’m in origin’s directory. What else would I be pushing? And why do I specify “master”. Where else would I push too… some other developer’s local copy? How would that work!?!
1.12 – Pulling Remotely
Ok.. We are pulling changes down from the remote repository to local right? I guess this makes sense. This one used to trip me up a lot more than it does now. “git pull origin master”. My English speaking brain reads “Git, pull the stuff in origin to the master.” exactly opposite of what is happening. I’ve been studying German. Ok.. so it’s a differing word order by language thing.. .got it. I bet it makes total sense to a native Swedish speaker. That’s cool but English language manuals and tutorials would do well to explain this explicitly. Maybe something like “git pull “. Examples are nice and all but sometimes these sort of usage descriptions are still helpful.
1.17 – Undo
What does resetting octocat.txt have to do with getting rid of octodog.txt?
1.19 – Switching Branches
This is scary. It feels like I am downloading a branch to the local folder from the repository. Is that what I am doing? Am I overwriting my uncommitted work in the current branch? I don’t just keep different branches in different directories and switch between them with cd (commandline) or by browsing in a gui?
1.23 – Preparing to Merge
Ok, so I got my files back when I switched back to the master branch but all the files were deleted in the mean time. Did I just lose any and every uncommitted change? Is that what stash was all about? That seems easy to forget to do. Why would I want to work that way when I can just put separate branches in separate local folders connected by a common remote repository? Hard drive space is just not that rare and precious these days. Risking losing a whole lot of work sounds unreasonable to me.
Well.. this is the farthest I have ever made it through a Git tutorial before throwing up my hands, crying WTF and surfing on to read something else. And yet.. I am still thinking.. WTF?
Yes, it’s a bit hard to learn.
95% of the time you only need add, commit, and push though.
I can help with some of your questions.
1.10
The command “git remote add origin https://github.com/try-git/try_git.git” is where the name “origin” is assigned (to the github link). I’m not sure if you have to create it in github first or if this command does it for you (I’ve previously created them in the github web site first)
The interactive tutorial skips the authentication step.
1.11
> the default local branch name is master
you have master / origin swapped in your mental model (I can see why, origin is a deceptive name when you’re starting locally then pushing to a remote).
1.12
“Git, pull the stuff in origin to the master.” Yes, that is correct.
1.17
> What does resetting octocat.txt have to do with getting rid of octodog.txt?
It’s not directly related. Back in ~1.10 you commited a change to octocat.txt. Since then, you’ve fucked around with octodog.txt but now want to purge any evidence of it. The command here specifies octocat.txt because we want to:
> Go ahead and get rid of all the changes since the last commit for octocat.txt
1.19
A branch is just a label. You’re telling git “hey, this work I am doing, I want to keep it separate from the main code”. Nothing is being downloaded from the remote. It won’t overwrite uncommitted changes (I just tested it).
1.23
Do you lose uncommitted changes when you run checkout? Yes. Checkout is telling git “please replace my working files with those from master”. If you want to keep changes, you need to commit them. Run “git status” before the checkout to confirm you won’t lose something.
Think about it this way: having only one valid set of files on your computer is a risk too. You should be committing frequently.
I don’t think stash was mentioned in the tutorial? I haven’t used it myself but it’s similar to a temporary branch.
If you want to have multiple local copies, one per branch, you can certainly work that way with git, it will work as you expect (each copy will know what branch its on).
TL;DR: Yes, git is complex, because it is powerful. For one-man projects you probably only need one branch, commit & push (the latter only if you care about having a backup).
Run ‘gitk –all’ all the time and refresh (Shift-F5) this graph after every command. Seeing what happens clears up a lot. Gitk is part of Git and comes with the standard distribution.
I’ve used about five version control systems over the past 30 years. Currently, my employer uses perforce, and at home I use subversion (with a local repository). From everything I’ve seen, GIT has a reputation for complexity and a difficult to understand model. Yes, it isn’t hard to get started and just use the voodoo commands to check out files, but as soon as something goes wrong, you have to do a deep dive or get an expert to tell you what arcane steps to take to fix things.
For one of my emulator projects, an enthusiastic person begged me to move to github so they could help develop it with me. (normally I develop using svn locally, then once in a while I put out a zip file of all my source to my website). Reluctantly, I learned enough to put it on github, the person did a test commit (added a space to a comment or something) to make sure it was all working Then they disappeared.
Please don’t give up so easily on git. I used CVS, then SVN, then git, in that order. In windows there is TortoiseSVN and I think Tortoise* for the others too, with nice shell integration. But it is better to know enough of the CLI to do the basics. I don’t know nearly all the commands and features of git but whole heartedly embrace it above the others (I’ve also used mercurial which is more like git than the others.) I also use and highly recommend the git gui and gitk commands, it works on both windows and linux and can help people (like myself) who are more gui oriented.
Just like any powerful system, there is a lot to know, and yes it might seem like voodoo till you master the basics.
I used RCS 20 years ago, then CVS, then Subversion and then git. Git can be complex only because it can do some very complex features unusual to most control version software. It’s certain that you can go to hell if you do some wired commands, but on the other side, because on how git handle change, it make it fairly resilient to data loss. There is also a very motivated community that share amazing competences, even on very tricky situation.
This week at least four FOSS projects received similar requests, “Please migrate to GitHub/CMake”. Yet those projects already use cmake and/or self host the git repo to be free of issues like Source Forge ones (yet anyone is free to clone in github).
Maybe it’s a new trend in trolling.
I think it might be a new form of link spamming. I’ve received a pull request from someone making trivial changes (changing license text in README). Then I noticed this person making very similar requests in many repositories on github and now all the repositories that merged his pull request mention him as contributor.
Looks good on your resume i guess…
Basically, you start by learning how to commit, then you learn what a remote is, and how to push and pull. Then you fuck something up and Google how to fix it. Over time you get comfortable and start to realize just how powerful and flexible of a tool it is. That was my journey anyway
IMHO, SVN users have a hard time seeing the power because they are used to the limits of SVN. I came from CVS to git, skipping SVN, but branches and stashes are just so easy with git, and it’s really fast to have several active versions, and skip between them, without any connection to the server. The few times I’ve worked on SVN, branches were such a pain that I realized that they were used for large, painful forks in projects, not just for topics.
That being said, if you work on a project by yourself, then it really doesn’t matter all that much. Revision control is 90% about what happens when there is a conflict, and 10% about the quality of the history.
Linus says he always names his projects after himself, hence the name git.
Actually, he named it “git” because he thinks of it as a “stupid (but extremely fast) directory content manager”:
https://github.com/git/git/blame/e83c5163316f89bfbde7d9ab23ca2e25604af290/README
Those came after the name was decided.
https://git.wiki.kernel.org/index.php/GitFaq#Why_the_.27Git.27_name.3F
It’s funny to call this “history”. I remember it as if it were just yesterday…
There was a while (2004ish?) when SVN was supported by Canonical/Ubuntu and Git was still young, when it looked like SVN would become the open-source version control “standard”. But it wasn’t distributed, and it was too slow with many many files, like the kernel has. And Git became pretty good pretty fast.
Mercurial was always kind-of the third wheel, IMO, without any large-scale patrons but with a decent userbase. And then there’s the oddballs. Hands up for DARCS!
I really wish darcs had got more traction, the ideas behind it really are great, but the practical implementation is a pita.
The whole idea of “cherry picking” sounds like in Darcs it would be a thing of beauty and it is what attracted me to darcs 6 or 7 years ago where in my workflow cherry-picking is very common – “I want this patch, but not that patch” sounds like something darcs was made for – but as time went on I soon found that this is not the reality, the reality is “I want this patch” and darcs says “sure, but you have to take ALL of these ones too that are implicitly depended on, even though it’s actually only like 1 line in 1 file that changed in that patch”
I would still really like to use darcs, if somebody came up with a conflict-resolution/substitution system so you could say “I want this patch only, just give me any missing dependencies as a conflict and let me work out how to resolve it”.
That said performance was a problem with large repos.
“Mercurial was always kind-of the third wheel, IMO, without any large-scale patrons…”
Facebook isn’t a large-scale patron?
FWIW, I find Git to be incomprehensible and Mercurial to be intuitive and very easy to understand and maneuver around with.
Be nice if there was a revision control for binary objects.
A binary file with no useful information on the internal format would require massive amounts of cross correlation analysis. A file checkin could take a prohibitively long time. You do not want to checkin a large binary file and still be waiting for your prompt to return hours later. It is the same issue faced by disk de-duplication, and what is done there is the files are thrown on disk as is and the server if idle tried to identify and categorise the files and if possible use binary format information backward engineered by the storage companies to reduce the storage. I’m not saying that it is impossible, but the pattern matching algorithms are not as efficient and the usual end result is a lot of energy is wasted, minimal or no matches are found and the file is stored as a BLOB (Binary Large OBject).
Comparison of ASCII files is usually much easier ever line has an easy to find delimiter [DOS uses carriage return and line feed (“\r\n”) and UNIX just uses a line feed (“\n”)] which splits the text into lines which are quickly compared for changes. The speed of processing are at many many orders of magnitude different because of that one delimiter in text files usually every 80 characters give or take.
Git handles binary files just fine.
If you want to handle binary files across platforms, you have to tell Git which files are binary, else it’ll try to adjust line endings for each platform.
Obligatory Downfall git parody:
https://www.youtube.com/watch?v=CDeG4S-mJts
No matter how many tutorials I watch, or how-to guides I read, or whatever, I’m just incapable of understanding git. I sort of have an idea of what it’s supposed to do, but implementation-wise it just doesn’t make any sense to me. I’ve shot my foot off so many times, like completely and utterly made a mess of everything, that I don’t bother with git any more. It’s not worth the hassle never being sure that what I’m doing is what I’m supposed to be doing.
I also know if you ask a question about git on StackOverflow, and you aren’t 100% appreciative of everything git offers, you’ll get downvoted to oblivion by the git mafia. If your question does exhibit the right amount of deference and does get answered, you’ll get half a dozen different responses and no idea which one applies. The one answer you do try will be the one that makes everything worse.
Comparing to earliest control version software, git commit a set of files instead of just a single file per commit. I found myself this aspect confusing at first.
The git add command is to select the files on the staging state, and then the git commit command commit coherently all the staged files in a single commit. The big advantage of committing a set of files is that it make the set atomic from the point of view of the others users. Not longer worry about an update that carry only some of the files that an other is currently checking in one after the other.
Aside of that, a simple local git workflow is easy: ‘git init’; then cycle: ‘git add ‘ [repeat as needed], ‘git commit -m “<message"'.
Is it possible to just commit the changes to a file (e.g. a dictionary text file), instead of replacing the whole file?
Also, I accidentally added a lot of huge files to a github repo, and now they’re stored in the objects tree and can never be removed.
Honestly, I don’t really like git for these reasons. I use it to commit to github, but I wish I could just FTP my files up there so people can find them. It’s the best free web host though.
Git always handles complete files and that’s generally a good thing. Diffs are created for viewing, only.
To remove older files, use an “interactive rebase”. For example, ‘git rebase -i HEAD~10’ gives you a list of the last 10 commits and allows to edit, remove or squash (join two commits into one, removing the middle version) them. After files were removed in the local repo, push that branch with ‘-f’ and it’ll vanish in the remote repo, too.
> Git always handles complete files and that’s generally a good thing. Diffs are created for viewing, only.
Uh, are you sure about that? I as far as I know a large part of what make git work is that it only stores the diffs. Entire files are only stored when it detects that the file has been rewritten (almost) entirely.
> Uh, are you sure about that?
Yes.
Exactly. And this is precisely why git is fairly resilient to data loss. If you remove references to some intermediate version from your tree, only the reference are removed, not the actual files content until you optimize your repository. And because you only need the hash of a content to access it, you just need that to recover removed references including the whole associated content.
One largely underestimated power of Git is rebasing. To join two development branches with older version control systems, one can only merge them and hope to resolve all the conflicts properly.
Git can merge, too, but this should be a strategy of the past. Rebasing branches before joining them is a much safer strategy to get good results. Another strategy is to cherry-pick commit by commit from one branch to another, essentially replaying the history of that other branch, reviewing the result after every step.
With both strategies, conflicts can be handled in much smaller and more atomic chunks, easing such joins a lot. Just this week I managed to join two branches which initially had a diff of a whopping 750,000 lines. Resolving such a diff with a single merge? No chance. By rebasing in small steps, Git resolved most of them automatically.
Git’s parlance for this is “working with topic branches”. Rebasing and cherry-picking are next generation version control.
one thing one must learn with git and fast is how to make impact isolated and well-formed commits. Once that practise sinks in working with git is a breeze. Treat the code like spaghetti and you’ll have a rocky ride …
Could you guys do one of these for Mercurial? I am curious to know why it ‘lost’ of sorts when a few projects used it (Mozilla was one if I recall). Git had the Kernel so it got a bunch of devs automatically and then folks day GitHub happened and that was all she wrote but I am curious why people still pick it today over others.
Here’s a good summary of why Facebook chose Mercurial.
https://code.facebook.com/posts/218678814984400/scaling-mercurial-at-facebook/
tl;dr version: They were both crap, but Mercurial looked easier to rewrite, so Facebook went with them and rewrote it. :D
No mention of Plastic SCM?
Full dvcs with easy to understand UI, good visual studio integration. And works with git, so I don’t have to learn a different tool for different projects.
Not expensive either
..
His name is Linus, not Linux!
Buddy here again, about one year later. Once again, made an error in a commit, tried to revert, and lost all my changes, and this is using Github Desktop! This is maybe the tenth anniversary of my exposure to git, and I am not any closer to understanding it. Every single time I need to do anything other than the regular four steps, I fuck up. Anything I do to fix it, I fuck it up even more.
I’m not a stupid person, I’ve written a real-time fault-tolerant operating system from scratch, a WYSIWYG editor in C/C++, and a distributed and multi-threaded OLAP system in a half-dozen languages. But I’ve come to the conclusion that I’m fundamentally incapable of understanding git, and will always rely on local full backups and cloning in lieu of whatever git tries to do.