
For many embedded C developers the most predominate and questionable feature of C++ is the class. The concern is that classes are complex and therefore will introduce code bloat and increase runtimes in systems where timing is critical. Those concerns implicate C++ as not suitable for embedded systems. I’ll bravely assert up front that these concerns are unfounded.
When [Bjarne Stroustrup] created C++ he built it upon C to continue that language’s heritage of performance. Additionally, he added features in a way that if you don’t use them, you don’t pay for them.
Data Hiding
Prior to the object-oriented paradigm shift in, roughly, the early 90s, structured programming was the technique to use. One of the principles that came with it was data or information hiding.
A good example for C programmers is the FILE pointer (FILE*). The only thing you know about a FILE* is that it points to a data structure somewhere in a library. You can open, read, write, and otherwise manipulate a FILE* through a set of functions. The actual data about the file you’re working with is hidden. In a sense, this is a step toward object- oriented programming. The FILE* points to the object, a struct, and the functions are the class methods that operate on the object, or instance.
[Stroustrup] took C’s struct and extended it to create a class based form of object-orientation. He might have taken another approach since there are other forms of object- orientation. For instance, if you work heavily with JavaScript you’re doing prototype object- oriented development.
Let’s look at classes and their non-existent code bloat in this article. We’ll encounter some other features of C++ along the way. I’m compiling with C++11 as implemented by the GNU Project GCC compilers to obtain the latest features of the language. I chose it because it’s the compiler used by the Arduino family of boards and can be used by the Raspberry Pi. It is often available for other processors, making it well suited for the hacker community.
I’ll be compiling the code for both an Uno and a Due board to illustrate that the type of processor is irrelevant. The Uno uses an ATmega328P 8-bit processor and the Due an ATSAM3X8E ARM Cortex-M3 CPU 32-bit processor, so there is quite a difference between them.
Declaring Classes
Classes are user defined types (UDTs). In C++ classes, structs, unions, and enums are all UDTs. A UDT is the equal of the data types you are familiar with in C: integer, char, float, double, etc. UDTs act just like built in data types in C++ statements: initialization, function calls, function return values. Operations on UDTs mimic the built in operations: arithmetic operations, logical operations. It was a design goal for C++ that UDTs and regular data types operate with no noticeable differences.
[Elliot] discussed ring buffers in a recent article, Embed with Elliot: Going ‘Round with Circular Buffer, so I borrowed his C code with a few modifications and created this equivalent C++ class:
namespace had {
using uint8_t = unsigned char;
const uint8_t bufferSize = 16;
class RingBuffer {
uint8_t data[bufferSize];
uint8_t newest_index;
uint8_t oldest_index;
public:
enum BufferStatus {
OK, EMPTY, FULL
};
RingBuffer();
BufferStatus bufferWrite(const uint8_t byte);
enum BufferStatus bufferRead(uint8_t& byte);
};
}
The first new C++ features in the code are the namespace and using keywords. They aren’t specific to classes so let me defer explaining them for a few paragraphs.
A class declaration begins with the keyword class followed by a name, just as C creates structs. In fact, struct could be used here instead of class. The difference between the two is struct, by default, provides public access to data and member functions while a class restricts access by default.
The next three lines declare data members of the class exactly as you would do with a struct in C. Since this is a class the members are private and cannot be accessed from outside the class. This is how C++ supports and stringently enforces data hiding.
The public keyword says the following lines are openly available. These can be accessed outside the class. You can also use private in the same way as public to make the following lines not accessible. A third access keyword is protected but it is used for class inheritance, a more advanced discussion, and we’ll ignore it for now. These access control keywords can be mixed as you wish in a class.
Next an enum is specified. Here it works just like a C enum.
The next line declares the class constructor. The purpose of a constructor is, in my vernacular, to make the class sane when it is created. It should set all the variables in the class to default starting values and contain code that sets up the class for proper operation. That may mean allocating dynamic memory for the class to use. For instance, RingBuffer could be setup to handle buffers of a chosen length instead of a globally defined fixed length. The length would be passed as an argument to the constructor and used to size the dynamically allocate memory.
The next two lines are member functions for writing and reading bytes of data to and from the buffer, the array data, in the class. There is no difference between these declarations and similar ones in C, except for one more C++ feature that is again not specific to classes, the & in the parameter declaration for bufferRead(uint8_t& byte). The & indicates the parameter is passed by reference. We’ll add that to the list of additional features to discuss below.
These are the basics for classes as UDTs. There are a lot of details about their design and implementation but those are beyond the scope of this article. A key point is that a class encapsulates within it all the capabilities you would provide for a data structure in C.
Using the Class
The code using RingBuffer is just a skeleton to illustrate how classes are used:
had::RingBuffer r_buffer;
void setup() {
}
void loop() {
uint8_t tempCharStorage;
// Fill the buffer
for (int i = 0; r_buffer.bufferWrite('A' + i) == had::RingBuffer::OK; i++) {
}
// Read the buffer
while (r_buffer.bufferRead(tempCharStorage) == had::RingBuffer::OK) {
}
}
Line 1 of the code is the definition of a RingBuffer variable. The had:: is a scoping operation that tells the compiler to use the RingBuffer declared in the had namespace. Similarly, on lines 9 and 12, the enums OK are scoped in had.
Calls to class member functions use the same dot-notation that C uses for accessing members of structs. The calls are just r_buffer.bufferWrite and r_buffer.bufferRead. If you want to call a class member function from a pointer to a variable the arrow-notation is used. Except for that adaptation, member functions calls are the same as C calls.
Behind the scenes, the compiler is passing r_buffer as a hidden parameter to the member functions. It is passed as a pointer and within the functions is accessed by the name this. You can access the member data using the this pointer like this->newest_index but it is typically unnecessary. There are situations where it is used.
C Version of Code
For completeness let’s look at the C version of the code. It’s remarkably similar. Here are the declarations:
typedef unsigned char uint8_t;
enum BufferStatus {BUFFER_OK, BUFFER_EMPTY, BUFFER_FULL};
#define BUFFER_SIZE 16
struct LifoBuffer {
uint8_t data[BUFFER_SIZE];
uint8_t newest_index;
uint8_t oldest_index;
};
void initBuffer(struct LifoBuffer* buffer);
enum BufferStatus bufferWrite(struct LifoBuffer* buffer, uint8_t byte);
enum BufferStatus bufferRead(struct LifoBuffer* buffer, uint8_t *byte);
We’ve got a typedef instead of the using, and a define instead of a const. After that LifoBuffer defines the same data, and the function declarations are about the same. The initBuffer serves basically the same purpose as the constructor. And we see a pointer instead of a reference.
One difference is the explicit passing of the pointer to the data structure. That is the same as the hidden this that C++ passes to member functions.
The calling routines look very similar also:
struct LifoBuffer buffer;
void setup() {
initBuffer(&buffer);
}
void loop() {
uint8_t tempCharStorage;
// Fill the buffer
uint8_t i = 0;
for (; bufferWrite(&buffer, 'A' + i) == BUFFER_OK; i++) {
}
// Read the buffer
while (bufferRead(&buffer, &tempCharStorage) == BUFFER_OK) {
}
}
Source Files
Sorry to disappoint, but I’m not going to post the complete source files. You wouldn’t see any more difference than in the calling routines. But here is a snippet from each to satisfy your curiosity. I’ll show the bufferRead function so you can see how the reference parameter is handled. First the C++:
RingBuffer::BufferStatus RingBuffer::bufferRead(uint8_t& byte) {
if (newest_index == oldest_index) {
return EMPTY;
}
byte = data[oldest_index];
oldest_index = nextIndex(oldest_index);
return OK;
}
Now the C version:
enum BufferStatus bufferRead(struct LifoBuffer* buffer, uint8_t *byte) {
if (buffer->newest_index == buffer->;oldest_index) {
return BUFFER_EMPTY;
}
*byte = buffer->data[buffer>oldest_index];
buffer->oldest_index = nextIndex(buffer->oldest_index);
return BUFFER_OK;
}
The major difference is the C++ version looks cleaner without the pointer dereferencing operators needed in C to access the buffer data structure. The parameter byte, the reference, also is accessed more easily. The main drawback with the C++ version is the need for the scoping operator, the ::, necessary to tell the compiler the functions and enums are part of the RingBuffer class.
There are two advantages to having the BufferStatus enum within the class RingBuffer that make using the scoping operator worth the effort. First, the enum names are shortened by having the buffer_ prefix removed. The scoping operator tells the developer and the compiler when these status values are valid. Second, it avoids name conflicts that can cause confusion. You might have other classes that use a status of OK or FAIL. Those may not use the same underlying values. If those classes are buried in a library you have no way of changing their values. One may say OK‘s value is 1, and the other 4. The scoping operator sorts out that problem, and the compiler enforces it by refusing to allow an enum from one class to be used with another.
Additional C++ Features
Let’s back up and look at the additional features of C++ we’ve encountered: namespaces, using, and references.
Namespaces
I didn’t intend to introduce namespaces in this article but the need to use them came up when I compiled the C++ code for the Due. I’d been compiling for the Uno without any problems; but when I switched to the Due, the compiler generated errors that it took me a few moments to understand: my RingBuffer class name was clashing with a RingBuffer class name used by the Due for serial communications.
Name clashes amongst libraries and user code is exactly the reason for having namespaces. I could have changed the name of my class to FifoBuffer which is actually a better name because it describes the usage while RingBuffer describes the implementation. Another name, more Computer Science oriented, is queue. I didn’t use it because the C++ standard library implementation of a FIFO is named queue. I left it at RingBuffer so I could discuss namespaces.
Creating a namespace is easy:
namespace <name> {
// some code }
So is using one:
using namespace <name> {
// some code
}
I wrapped the entire header file, RingBuffer.h, and the source file, RingBuffer.cpp, in the namespace had, for HackADay.
In the Application.cpp file where I used the RingBuffer class I needed to qualify the constructor and the uses of the BufferStatus enums with the had namespace so the compiler knew I wanted them, not the ones from the library.
Aliases: Using and References
Both the using keyword and references create aliases. The ability to create aliases is a general feature of C++ that was extended and improved in C++11. For the most part, aliases allow the use of simpler names to refer to more complex expressions.
Using
The using keyword creates an alias for a complex data type. Here the type unsigned char is given the alias uint8_t. This usage replaces the use of typedef, which still available to not break legacy code. If this simple example doesn’t impress you how about having an alias to simplify const unsigned long int* const or a pointer to a function with a large number of parameters.
Here are the two lines of code from above:
using uint8_t = unsigned char; const uint8_t bufferSize = 16;
Notice how the statements are similar. The second line creates the variable bufferSize and initializes it to the value 16. The first line creates the name uint8_t and sets it to the data type unsigned char. This parallelism of the constructs is why using was introduced. A big effort in C++11 was the standardizing of expression forms along these lines.
References
References are a feature of C++ that appear in many places. Since this is not a tutorial on C++ I won’t elaborate beyond their use as a function parameter.
Function arguments can be passed in multiple ways. One way is by value. This is the usual way in C/C++ for arguments: a copy of the value from the argument variable is passed. Any operations within the function modify the local value but have no affect on the argument variable.
C/C++ can also pass arguments by pointer, which is a form of reference passing. Operations affect the original value. We know that pointers are dangerous so C++ wanted to minimize their use.
A reference is an alias of the argument variable. Just as with a pointer the address of the argument variable is passed. The big difference is you cannot manipulate this address since it is not exposed as with a pointer. The original value of the argument variable is affected by any operations in the function.
Cost of Classes
I teased above about showing that there is no cost to using classes. This is 99.9999%, or something around there, true. In this article I’m only going to look at code size because someone looking at C++ classes and seeing their additional complexity expects there has to be a cost.
I used Eclipse with the Arduino plugin mentioned in Code Craft: Using Eclipse For Arduino Development to compile the code for the Arduino Uno and Due. Here are the results:
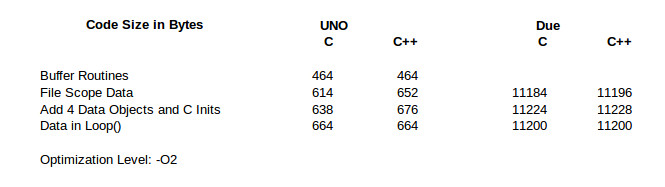
Clearly there is no major code bloat when using C++ on either processor. Let’s walk through the table first for the Uno and then come back to look at the Due results.
The line Buffer Routines is the code size for just the FIFO buffer code and empty Arduino setup() and loop() routines. I did this only for the Uno because I was too lazy to go back and strip the Due version down to the minimum. As we’ll see, it doesn’t matter.
The next line, File Scope Data, has the definitions of the data structures at file scope in the Application source file. The C++ code is 38 bytes larger because the class constructor is called. In order to call the constructor additional code is executed before main() is called. In any C/C++ application there is system specific initialization code executed to setup the application. C++ just adds a little more to call all the file scope constructors.
The next line shows that it is the initialization code as I suggested. An additional 4 data structures were added to both programs, with calls to their initialization inserted in the C version. The difference between the two versions remains at 38. That is a fixed overhead you’ll see on an Uno for using C++.
In the final line, I moved the definition of the data structure, and initialization for the C version, into loop(). That takes them out of file scope which means the C++ special initialization code is not needed. Now both versions have the same code size.
So, at least for the Uno, I rest my case. C++ classes do not cause code bloat.
The results for the Due are identical except for the case with multiple data structures at file scope. There is a 12 byte overhead for having a single data structure at file scope. Okay,I assumed that’s the C++ pre-main() initialization code. But that overhead reduced to only 4 bytes when the additional 3 data structures were added. What? This deserved additional investigation.
I went back to having one data structure at file scope then added more one at a time, recording the increase in code size. The C version alternately increases by 8 and 16 bytes. The C++ version increases by 16 bytes for the second data structure and by 8 bytes for each one after that. I could generate some guesses on this but frankly it’s not worth the effort since these differences are small.
As with the Uno, the final line demonstrates there is no code bloat. This is when the data structures and initialization are moved to within loop().
There it is. No code bloat from using classes in embedded systems.
Wrap Up
I just scratched the surface explaining classes in this article. I wanted to provide enough explanation so C developers would understand the concepts sufficiently to accept classes are not going to increase code size. More details would just be confusing, and there are a lot more details. I also don’t want to play language lawyer so the presentation is pragmatic, not pedantic.
Software development is a complex process. A continuing goal for language developers has been to provide a tool that is efficient to use both in writing and executing code. C++ classes not only are efficient in code size but they help avoid common errors made during development. One measure of development is that rate at which bugs are fixed. Even better is preventing bugs from occurring.
The class constructor is a bug preventor. When you instantiate a class the constructor is going to be called to initialize the variable. Consider the situation with the C code where I created FifoBuffer a number of times. For each of those variables I needed to add the call to init(). It’s very easy to forget that initialization, especially if you create the variable in a file other than where the initialization is to take place, like the setup() in an Arduino application.
The Embedding C++ Project
Over at Hackaday.io, I’ve created an Embedding C++ project. The project will maintain a list of these articles in the project description as a form of Table of Contents. Each article will have a project log entry for additional discussion. Those interested can delve deeper into the topics, raise questions, and share additional findings.
The project also will serve as a place for supplementary material from myself or collaborators. For instance, someone might want to take the code and report the results for other Arduino boards or even other embedded systems. Stop by and see what’s happening.














The problem with using C++ in the embedded realm is not code bloat, it is dynamic allocation. If you don’t understand how C++ handles dynamic allocation, or why you need to worry about dynamic allocation in a memory-constrained environment you shouldn’t be using C++. There are plenty of other issues as well, but that is the big one.
The key here is understanding what C++ is doing under the hood. If you understand what C++ is doing under the hood it can be a great tool for embedded development. Likewise, if you do not understand what C++ is doing under the hood you are best avoiding it until you do.
What do you mean by ‘what c++ is doing under the hood’?
As an example, consider inheritance and method overloading in C++. Someone who wants complete control over code size and execution would probably want to understand how the compiler translates a class with a virtual method into a vtable structure with function pointer indirection for calling the right method version at runtime based on object type. How that happens is well understood and it can be predictable but it’s not free in terms of code size or execution time. The differences between C and C++ aren’t “free” except in the most trivial cases.
Except that the whole point of C++’s implementation of VTables, is that if you want the same functionality (virtual functions) in C, you will build the same constructs.
Not that I say that virtual functions have any place in small embedded controllers (just like dynamic memory shouldn’t be used)
Exactly. In fact, a lot of the cost of using C++ in embedded systems is just stupid. You want to abstract hardware away, which is great. Except it comes at the cost of the compiler somehow thinking you might want to do “Serial *p = new Serial()”.
A great example as to the cost of C++ comes from the PDQ_GFX libs, which in detail goes through what the costs are and how to mitigate them. That project is here:
https://hackaday.io/post/18729
Thanks for the shout-out. :-)
IMHO C++ does bring some useful things to embedded development, but you do have to have some discipline to use it properly in this space (e.g., probably with -no-rtti and -no-exceptions). It probably does take a bit more “care” and knowledge than C coding though (since it is a more complex language), but you get some benefits too. E.g., I find static templates helpful in embedded development in that they allow me to have the compiler “bake” things out at compile time (but still have the source code flexible – with fewer macro games).
Bad code can be written in any language.
As long as you don’t use the ‘new’ keyword, I don’t believe in C++ you are dynamically allocating anything by default. In the above examples there is almost no difference in what the compiled code does. As you see he declares the variables directly as the class type, not pointers to the classes. The memory is allocated the exact same way as any other primitive or struct type would be.
Depends, as long as you don’t use anything from the standard template library (which is pretty much part of C++)
Another difference could be if you only make a single instance of your object. The C version you could access static data, while in the C++ version you still have a “this” pointer that needs to be referenced. But I’m not sure how well the optimizer handles this.
You can still use static methods and fields in a C++ class, which I believe is preferred over over a singleton pattern.
There’s no single thing which is why people are nervous about C++ in an embedded. It’s a whole set of things!
It used to be that C++ compilers would do really unpredictable things, which meant that it was more difficult in a resource-constrained environment to know that your code was going to work if you made small changes. This one is pretty much passed now, clang/llvm and g++ for ARM are pretty solid on applying optimizations intelligently for embedded platforms.
That being said, you’re often writing to a company’s specific compiler, which unfortunately often means that you do have really varying performance characteristics. If you’re using gcc/g++ with a big-endian chip, you also can run into optimizations and things which behave strangely in a big-endian environment.
The next is ALLLLLLLLLL the features! For an embedded setup, you’re often running something like:
$ arm-non-eabi-g++ -fno-exceptions -fno-rtti -fno-asynchronous-unwind-tables
Where you’re trying to pull out “nice” features of C++, run-time type inference, exceptions, and the support structures for exceptions. These features all introduce overhead which you don’t want in a smaller embedded system.
With RTTI disabled, you also can end up getting code which works on bigger machines to stop working, as C++ compilers often choose to discard type information in favor of the run-time information, which can also be a new factor of unpredictability in your code’s performance, as you exercise much different paths in the compiler’s operation.
The other thing is that if you’re writing idiomatic C++, you’ll often have templates! Templates can often end up producing lots and lots of bloat in code size, because you’ll stamp out lots of copies of your functions. You need to dig down and start adding in things like “-ffunction-sections” to your C options and “–gc-sections” to your linker settings to successfully prune out templated code that’s never called!
If you’re writing with lots of inheritance (I normally prefer composition over inheritance, but I digress) virtual table lookup is yet another runtime expense.
If you can get a C++11 compiler for your chip, a lot of the dynamic allocation problems are “solved” by using the move semantics.
Anyway, I could keep rambling, but I’m gonna stop! C++ is okay, but man that is a really full kitchen sink!
I don’t know anyone who actually uses RTTI in C++ code, I’m sure it has its uses but I wouldn’t say it is one of the nice features of C++, more of a curiosity.
Many companies also do not use exceptions so again it is not an essential feature of C++.
The killer feature of C++ is RAII which can be used to automatically free memory, release resources and so on with no additional overhead over C. If you just use C++ for this without any of the extras it is worth it IMO.
This, so much this!
I write C and can easily picture what the compiler will produce even with GCC -O2 I can just about picture the rough steps but obviously it outdoes me in the details. Rarely am I shocked by the output.
Anyways, when I try to imagine what a single line of c++ might compile to it’s bind blowing.
IMHO c++ should only be used once you’ve reached the limits of c.
The biggest program with C++ is the quality of program is so poor. Perhaps thats due to the programmer, perhaps the language.
If I look at C code I can easily assess it easily. I can tell if the programmer is new, adequate or experienced or a master.
If I look at C++ code from so long as they aren’t new it’s impossible to get this instant understanding.
A moderate programmer can really frak things up in C++ and it’s damn near impossible without a viva/walk through to notice.
Thats my worry when I see C++.
Don’t you think that has to do with a relatively high level of experience with Language A and less with Language B? I’ve been developing in C++ for long enough that I can tell the same things about the programmers that you can about C, but I couldn’t look at Ruby and decide if the programmer knew what they were doing.
Trick answer, no one using Ruby knows what they’re doing ;)
That’s the crux of the matter but while I program mostly in C I have a lot of passive experience in C++ that comes with that, so while I don’t have active knowledge I do understand all but the most esoteric C++.
But in a sufficiently large and complex project when C++ gives you dozens ways to do something that dozens of proficient programmers could use effectively (depending on the task they could all) how is anyone supposed to pick the poor programmers out of the soup?
When I write C++ I essentially write C with classes. I do that alot but I don’t think that makes me a C++ programmer because I don’t make sure of the vast majority of it’s features. Maybe it’s the old: I was writing C but programming in FORTAN issue of programmers transitioning between languages and the similarity between C++ and C means I’m not willing to leave C.
“When I write C++ I essentially write C with classes. I do that alot but I don’t think that makes me a C++ programmer”
Using C++ as if it were C explicitly makes you NOT a C++ programmer. That’s the easiest way to identify a bad C++ programmer, when you see someone using C++ as if it were C or, even worse, Java, you know s/he doesn’t know what s/he’s doing.
C and C++ are very different languages and if you’re going to program C++ like you program C you’re probably better off programming C :-)
“even with GCC -O2 I can just about picture the rough steps”
No, you don’t. Please, look at what -O2 means and rethink your statement: https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html
In my job I have to check a lot of code generated by gcc -O2 and even with support (like references to functions and lines of code) I often find it hard or even impossible to know where the code comes from or why the compiler does certain things. Actually, it’s not that much harder when we use -O3.
C++ is worse, that I won’t deny :-)
I agree, especially the part about accessibility.
Computer languages come in basically two flavours – those that all you to reprogram their semantics and those that don’t. This is the essential difference between C and C++.
Languages that allow that kind of programmability will always be less accessible – especially to less than expert coders new to any particular project – than those that don’t.
This is because you can take almost any line from the latter in isolation and basically grasp what it approximately does to the as yet unfamiliar tokens you haven’t examined the source for yet.
If your interest in a project is “I just want to add/fix this one annoying feature/bug that affects my use of this project and then disengage from developing it” then guess which kind of language you’re much more likely to quickly succeed with?
And this is the most important issue for embedded things (with available source code! But that’s a separate issue.) too – because by the time that someone need to tweak that one bug, no one remembers exactly how that old codebase really works, and no one really wants to get too familiar with it either – it’s not their baby, it’s the original coder’s who is unavailable anyways.
This is likely also why OSS OS kernels written in C are far more popular than those in C++. If C++ were such a time saving panacea than surely the opposite would be true ? But in this case the point I make is even weightier – most stakeholders in those just want to cheaply make a tiny alteration without investing in the effort to fully grasp the whole thing.
This is essentially why everyone hates systemd. Sure it’s written in C too – but in such a way as to basically weld on C++’s design patterns – which is even worse than it being written in C++ to start with.
Likewise, everyone’s Arduino is basically written in C++ that sticks to C’s subset, more or less. And it’s popular because so long as the library for whatever doesn’t head too far down C++’s rabbit hole, it’s essentially the same as C with the occasional singleton class API to talk to some simple peripheral.
As an extreme example – look at the strange unpopularity of OSS forth and lisp projects.
Despite those languages maintaining an extremely capable elite hardcore who – in both the “heavy iron (lisp)” and “embedded (forth)” domains – can and do absolutely run productivity rings about their competition who use C/C++.
But both of those are basically extremely “semantic programmable”, because their syntax is so extremely limited as to force it to be. (Both extend all their keywords, and there is really no demarcation between keywords that are “part of the language” and not, and that means that newcomers to a project have to figure out which varient of the language they’re dealing with.
Just as newcomers to a big C++ project (that relies heavily on inheritance) need to spend a lot of time reading back through the rest of the class hierarchy to grok how the small part that they’re interested in works.
But not so in C, where there’s a clear distinction between functions and operators & types, where the latter two are usually what they say on the tin, and the semantics of accessing structs hint that they aren’t simple data types.
Here’s an exercise:
Assuming you’re unfamiliar with modding either: Get Quake , and Unreal Tournament.
Get the “quakeC compiler” for the former.
Now with what you have (UT comes with its own compiler) just try and add a simple feature to both – make the rocket launcher in in both always fire guided missles towards whatever enemy is in front of the player and nearest the crosshairs.
QuakeC is much closer to a typical C codebase – no inheritance. UnrealScript by comparison is ultra heavy on inheritance.
Post how much time it took you from the first time you compiled the vanilla code base with one change verified by running the game, until the time you succeeded for both. (So, Excluding the time it takes you to learn to do a build and run a test.).
If a few people do this, we’ll have hard data by experiment to support or deny my point.
I won’t post my times, as I’m already familiar with both codebases. :)
Unfortunately this example is not very helpful for pointing out the actual problems C++ faces in the embedded space. It doesn’t use any inheritance, virtual methods, exceptions, dynamic allocation with constructor / destructor side effects, etc. A single class with no inheritance or virtual members is essentially a C struct. Namespaces and using directives are lexical scope features that don’t impact runtime. I’d be concerned that anyone reading this would take it as carte blanche to start using C++ without understanding the impacts in any of the features that make C++ more than “C with classes.”
The ISO C++ Standards Committee recently formed a study group (SG14) on improving C++’s reputation and performance in the high performance space. One of the targets is game design needs but the concerns of that community often deal with resource usage and “automatic” features like exceptions and vtables, and that affects C++ usage in embedded contexts as well. It’s in its early stages now but it could provide some exciting things in future versions of the language.
At bufferRead c version, line 2 there is an extra semicolon.
I have been programming in C for years on various embedded platforms. I tried the MSP430 in C++ about a year ago and found that my execution times were a bit higher than expected. After porting the same code, my execution times decreased by ~10% to 30% and I didn’t know exactly why. I ended up staying with C primarily b/c I know how to make it fast in that realm and I had a deadline, but I am still interested in using C++ on this platform and on others.
I would like to see a similarly detailed follow-up article on execution times and how to potentially decrease those. I suspect that a liberal sprinkling of ‘static’ keywords would help things along.
Thanks for the post!
If anyone wants the code it is at https://github.com/rud-had/RingBuffer.
Thank you so much for this article! I’m struggling with learning this stuff for a college course and this is exactly the kind of explanation I needed.
“Predominant”, not “predominate”.
I totally agree with Chris’s comments. This article is not about C++, just showing a way how you can use C++ as if it was C. The RTL does a lots of things ‘under the hood’. Looking up for a virtual method in the vtable is the cost I don’t want to pay for. Same for operator overloading. I use C++ in my PC projects where the CPU and the environment is strong enough to handle these cases, but I would not even try for example on a 16bits PIC.
Even if you just think about malloc and free in case of C, there is already something that you don’t control. There is a virtual “os” that does at least the memory management. In case of C++ it’s a lot more complicated.
” Looking up for a virtual method in the vtable is the cost I don’t want to pay for.”
I agree. .A CRTP-type implementation (using templates) can avoid that, but I really, really, really wish there was an intermediate language between C/C++ which is more built from a fundamental CRTP-type perspective: as in, if you can’t figure out what kind of class it is at compile time, it’s an error. Something that flat out forbids run-time polymorphism.
In general ‘this’ pointer dereferencing/virtual methods tend to help with code size, at the cost of code execution speed. Other people may disagree, but I typically find that nowadays, flash is cheap, but cycles are still costly.
…it sounds like you want rust!
http://www.rust-lang.org/
Not the be-all, end-all language or anything, but it basically behaves exactly like you asked: it resolves everything strongly-typed at compile-time. The objects are less expressive because of it, but it’s a very nice step up from C without all the crazy drawbacks of C++
You have to declare methods as virtual, so it’s easily avoidable if you don’t want it. If you want to forbid runtime polymorphism, just use a hide-by-signature pattern instead of virtual methods.
Also, for the ‘this’ pointer, I’d say it is not a problem. If you are only having one instance of your class, make it a static class. Otherwise if you are going to have multiple instances of the same class, the C equivalent would be passing a struct/pointer to the functions that would work on the item anyways, thus the performance would likely be exactly the same.
Overloaded operators are just completely ordinary functions with different calling syntax!
‘Matrix addMatrix(Matrix a, Matrix b)’ would be completely same in size as ‘friend Matrix operator+(Matrix a, Matrix b)’.
You can even choose if you call it by ‘Matrix::operator+(mat1, mat2)’ or by ‘mat1 + mat2’
You do not have to use malloc/free.
new and delete by the way are completely overloadable and you can use it to do anything!!!! From printing hello world to allocating shit on stack or wherever you want.
One of the arguments against C++ is what happens behind the scenes. If I use a std::string to build my string to print hello world, even if I put my string on the stack, the string class will dynamically allocate the storage for the string on the heap.
In my opinion, this doesn’t make C++ bad – you just need to know how it works.
Except in a very tight embedded system, you probably have your own versions of malloc and free that you do control. If you allow any semblance of dynamic memory, that is.
Referring back to the article – saying that 16 bytes per data structure isn’t worth worrying about. Really? At the level of embedded systems I work on, wasting that much will get you lynched. But then, when recruiting, it’s often amusing to find out what people think “embedded” resource levels are…
People dis C++ for dynamic allocation and virtual functions. But those features serve a purpose. Using C offers no advantages if you end up using ‘malloc’ and function pointers to accomplish the same thing C++’s ‘new’ and virtual functions give you.
please insert a *jump* or *break* scolling on slow devices is no fun with such a long post on the main page
thanks!
bufferRead’s reference parameter in “SOURCE FILES” is missing the ampersand which would make it a reference parameter. Trivial omission except that it IS the very point of the previous paragraph.
Thanks, it’s fixed. We’re trying to get WordPress to fix a bug that converts HTML characters in ‘code’ to their HTML equivalents. When fixing those conversions sometimes more gets ‘fixed’ than needed.
“their non-existent code bloat”
Your compiler results show the C++ version adds bloat. You then go on to pretend that it is so small that it is non-existent. Seems like the old “moving the goalposts” logical fallacy.
Why not admit the 3.2% increase in code size on the AVR is bloat, albeit small enough that in most cases it won’t be a problem?
Also it depends on the features used. If you use C++ like it’s just C with classes (i.e. no inheritance, virtual methods, templates, function overloading), then yes, the overhead is small. But pulling in just a few extra features leads to real bloat which moves towards unacceptable.
I think you’re absolutely right though that honest answer is: “if you need the features of C++, rather than trying to bend it wildly into the world of C: check if the overhead isn’t small enough for your application!”
If a 3.2% difference is important then don’t compile with -O2, use -Os. The difference between O2 and Os object code is greater than 3.2%. When comparing raw numbers the key word is “significant”; is a 3.2% difference REALLY significant?
Ralph, the increased size is not a percentage increase. I didn’t respond right away because I wanted to dig further into how the Uno code works to verify my assumption stated in the article. I verified that the 38 byte increase is when you use global / file scope object instantiations. This is the code CPP need to call the constructors for those instances. In other words, a small routine is added to the startup code that is executed before main(). It’s a fixed amount that won’t change.
I also looked at the Due code and can also see the initialization code. I think it is always there unlike with the Uno.
Even while writting C with classes you do not make stucts with pointers to functions, but functions in class – just that it is a hudge difference. When I see badly written code in C++ it’s actualy poorly written code in C with attempt to make a class. While puting C in class is practically harmless, badly written code in C is a real mess.
But! When writting in C++ why not to use STL, or use references and ‘new’ which are great? Time? Space? ARM M4 processors have enough of place for really complicated programs. Good code isn’t really slower too. And each time I see char* and badly done memcpy, goto, magicall numbers, badly done macro which fires in your face in least immaginable ways I cry to god: why?
C++ is really easier to read than C, code is more managable too, faster to write and more flexible. While writting in C++ you spend a bit more time on thinking how it will be used, not just writting so it will somehow work. Imagine a project with more than few thousands of average code in C and in C++ in my opinion, average code in C++ win. Code might be a 3% slower (but can be faster too ), can be much more easier maintanable, easier to understand and write.
I didn’t have much of experience in writting in C for embedded purposes, that’s mostly because when I applied for first job I joined embedded C++ team working with STM32F4 processors – a bit reprospective its only flaw was that guys didn’t use GCC. C is good… mostly for 8 bit Atmega, which is not cheaper than STM32F1, much slower, has much less memory, ( have no DMA, no interrupt levels as well )… isn’t ARM processor. You have ARM? So use it.
Readability and manageability has *far* more to do with your team and the coding standards you use than the language you use. That said, given all the features that C++ offers there is a *far* greater likelihood to come across spaghetti code in C++ than C.
It’s easy to write spaghetti code in both…
With no code quality control and weak programmers both are deadly. I once spend half a day disarming code I was given to fix just because it was written with goto “exceptions”, goto “switch case” (sic!), even goto “while”. In my opinion using just C is deadlier, people often neglects that memcpy, strcpy, atoi, atol, malloc (… others) can be hidden possibilities to kill program in least possible to imagine way. How many programmers care of atoi or atol which works in 99.9% of times in case these will cause trouble?
I think the ATMSAM3X8E is a little bigger than that… the last machine I coded for that had instructions so nicely expressed in Octal was the DEC PDP8.
“What sharp eyes you have, Grandma” Fixed.
Every once in a while I come across PICs that support HTC++. I’ve never actually used it.
My biggest gripe with using C++ in an embedded environment is building the cross-compiler.
A plain C compiler, sufficient for building a kernel with no external libraries, is easily produced. Compile binutils, comple gcc, you’re done. It’s not hard, and you can have that LED blinking rather quickly. Then you implement what you need. Code size is kept small, and there are no black boxes.
C++, you need to build the C library so you can build the C++ runtime. This can be a right pain in the arse.
About the one place where C++ really wins out in terms of coding efficiency is things like templates and inheritence, which cost in terms of code size/performance. The only metaprogramming in C is the C pre-processor, and it’s an ugly beast. Good enough for simple cases, but it has significant limits.
I’ve thought about doing some kind of pre-processor that would bring a variant of templates to the C language, but haven’t gotten that far. It’d probably be a bigger headache than just using C++, so the motivation hasn’t existed to do this.
Some time ago I put a C++ class wrapper around a few libraries I use often to make them fall in line with my newer C++ code.
After that I also had to update a few of my older projects I still use now and then.
C++ “forced” me to rearrange a few small parts of these old projects, and after a recompile the code (AVR m8) had actually shrunk by a few percent. I’m really beginning to like this C++ stuff.
Tip:
Putting an “avr-size” in your make files make’s it easy to track your code size/bloat.
The c++ exception handling adds ~55Kbyte plus code to the final on arm cortex M3 with g++. iostream adds 150Kbyte (so roll your own printf), std::string adds 2Kbyte.
Well, you don’t really want to use exceptions in an embedded environment (heck, I won’t use them even in a HPC environment, they are a terrible terrible idea, IMHO) and you probably don’t want to use iostream either (I prefer cstdio always, embedded or not, for many reasons I’m not going into). std::string might add size (I trust your word, haven’t really checked) but it also adds very interesting functionality, it’s not like that extra space comes from nothing and/or it’s for nothing.
I’ve been using C++ on RTOS-driven embedded systems for more than 15 years on Coldfire, MSP430, ARM7, ARM9, Cortex-M, and Cortex-A. I remember having an engineer tell me in 2000 that it can’t be done while standing next to an embedded device whose application was written in this language.
I’d like to suggest that if designing with objects is something that has value to you then prefer C++. You can design with objects in C but you’ll be able to express your ideas more readily with C++ and the technique for doing so in C is more work and harder to get right. If you don’t value designing with objects or are not particularly interested in software design then steer clear.
The problem with talk of bloat and performance is that it is not what should be driving your design choices. Code doesn’t have to be as small as possible but it must be small enough and execution time doesn’t need to be as fast as possible but it must be fast enough. If you try to spend your resources being as fast- or as small-as-possible you’ll never deliver your product. You design to a spec + margin and what is left over can be leveraged to save time, improve quality, or add features.
Now having said this, C++ can sometimes be a pain in the ass. I’ve never felt this way about C as it is wonderfully elegant and predictable. But I prefer designing with objects so my approach has been to use C++ in such a way that as my understanding evolves I use more of the nuances of the language.
This is a really interesting article. As I’ve been using C++ for years in embedded systems there is nothing really new to me, but I find it good to share knowledge about the usability of C++ for embedded and in particular microcontroller projects.
In some way I’d like to contribute to this, for now I’ll start sharing some examples of heavy use of C++ I’ve been doing. Maybe some of these can be added as an example to the hackaday.io project?
– Miosix (http://miosix.org) is the OS I’m developing, it’s written entirely in C++ and is currently focused on STM32.
– This article (http://www.webalice.it/fede.tft/stm32/stm32_gpio_and_template_metaprogramming.html) shows how template metaprogramming can be used for abstracting GPIO access without code size nor performance penalty, which then became the GPIO abstraction in Miosix.
– This is a simple 3D rendering engine (https://github.com/fedetft/mxgui/tree/master/_examples/teapot) written with heavy use of the STL containers. It’s designed to be readable. Writing it in C would have required to rewrite complex data structures from scratch (such as red-black trees) while in C++ they are readily available in the STL. It also got featured on hackaday (http://hackaday.com/2013/08/26/sony-smartwatch-hack-lets-it-tell-time-with-a-teapot-animation)
That GPIO template is awesome.
It seems like a degenerate comparison though – if GPIO_write were declared inline, and the optimisation level set realistically, the code would likely collapse down the same anyway. It certainly is with my own simple test case.
Yes, the code probably does come out the same. The question is which set of code is easier to use? Can someone 2 years from now, who may be you, understand what is being done?
The style has been deliberately chosen to make C look bad. An equally possible expression in plain C could be:
pinHigh(GPIOA, 15);
I’d argue it’s equally readable – moving parameters into a name via template magic doesn’t automatically confer greater clarity.
Nice work. I often find myself writing my own drivers for things like GPIO for readability. The vendor code is usually poor in this regard.
The C++ OS sounds interesting. Are there kernel-aware plugins for debuggers? Or at least the hooks to do so? I find this to be a differentiating feature when I’m evaluating them.
@Rud: thanks! I’d love to see it somehow featured here or in the hackaday.io project.
@raized4: when debugging I use gdb + openocd from a Linux machine. I haven’t thought of an OS-aware plugin before as I tend to simply put breakpoints in the “main” function of the thread I want to debug and start from there.
On the other hand Miosix has other nice features. Just to remain in-topic, the filesystem support is an example of embedded code that is object-oriented and makes use of inheritance, implementing a full abstraction including support for multiple filesystems with arbitrary mountpoints just as an unix-like OS. Imagine you have a FileBase class (https://github.com/fedetft/miosix-kernel/blob/master/miosix/filesystem/file.h) and then a derived class for each filesystem type. This is just internal stuff, externally it is fully integrated with C FILE*/C++ iostream abstraction.
Part of the reason why I did FastLED in C++ is because there are a number of things that C++ gives me, especially when it comes to template meta-programming, that allows me to both get a high degree of flexibility _and_ performance, at the same time. I can’t imagine being able to get both the performance that I get out of FastLED and the breadth of platform/led chipset support in just C (I know, I tried – and ended up taking/using a bunch of what I could in C++ to get the best of both performance and portability).
just a miss type but in C code , source file part :
LifoBuffer.c Snippet
*byte = buffer->data[buffer>oldest_index];
to >> *byte = buffer->data[buffer->oldest_index];
So, there is a garbage collector running on my UNO?
Why you use an enum instead of three defines?
For type safety. By using an enum the compiler will generate an error if you try to use an integer value with the status variable which is of the enum type.
One specific situation is if you were to use an enum in a switch-case construct you do not need to include a default case if all cases are otherwise covered.