
Today, Nvidia announced their latest platform for advanced technology in autonomous machines. They’re calling it the Jetson TX1, and it puts modern GPU hardware in a small and power efficient module. Why would anyone want GPUs in an embedded format? It’s not about frames per second; instead, Nvidia is focusing on high performance computing tasks – specifically computer vision and classification – in a platform that uses under 10 Watts.
For the last several years, tiny credit card sized ARM computers have flooded the market. While these Raspberry Pis, BeagleBones, and router-based dev boards are great for running Linux, they’re not exactly very powerful. x86 boards also exist, but again, these are lowly Atoms and other Intel embedded processors. These aren’t the boards you want for computationally heavy tasks. There simply aren’t many options out there for high performance computing on low-power hardware.

Tiny ARM computers the size of a credit card have served us all well for general computing tasks, and this leads to the obvious question – what is the purpose of putting so much horsepower on such a small board. The answer, at least according to Nvidia, is drones, autonomous vehicles, and image classification.
Image classification is one of the most computationally intense tasks out there, but for autonomous robots, there’s no other way to tell the difference between a cyclist and a mailbox. To do this on an embedded platform, you either need to bring a powerful general purpose CPU that sucks down 60 or so Watts, or build a smaller, more efficient GPU-based solution that sips a meager 10 Watts.
Specs
The Jetson TX1 uses a 1 TFLOP/s 256-core Maxwell GPU, a 64-bit ARM A57 CPU, 4 GB of DDR4 RAM, and 16 GB of eMMC flash for storage, all in a module the size of a credit card. The Jetson TX1 runs Ubuntu 14.04, and is compatible with the computer vision and deep learning tools available for any other Nvidia platform. This includes Nvidia Visionworks, OpenCV, OpenVX, OpenGL, machine learning tools, CUDA programming, and everything you would expect from a standard desktop Linux box.
To put the Jetson TX1 to the test, Nvidia compared its deep learning performance to the latest generation Intel i7 processor. This deep learning task uses a neural net trained to differentiate between objects; pedestrians, cars, motorcycles and cyclists if the TX1 will be controlling an autonomous car, or packages and driveways if the TX1 will be used in the first generation of delivery drones. In this image classification task, the TX1 outperformed the i7, while drawing far less power.
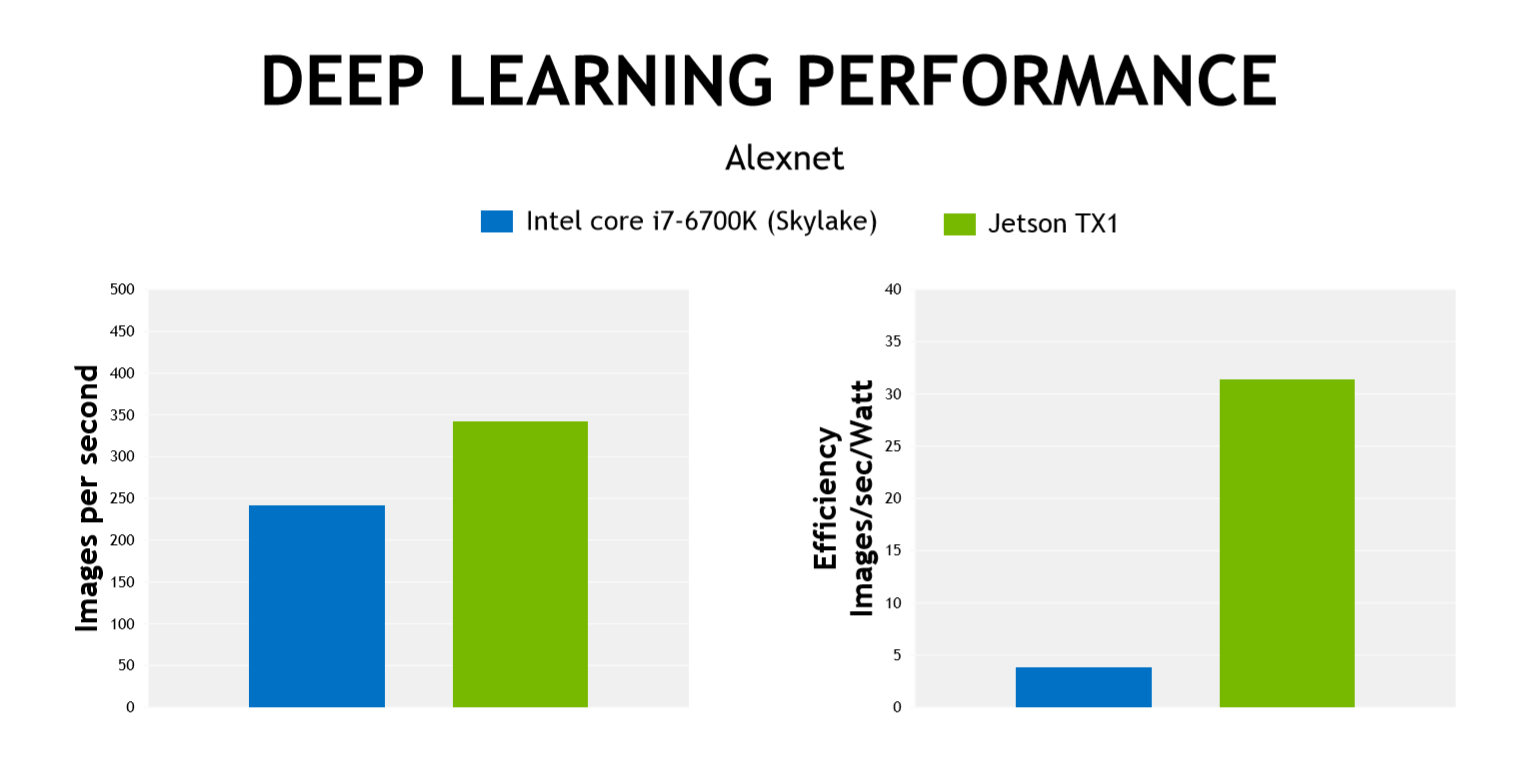
It’s important to note the power efficiency Nvidia is going for here. To put this much computational performance on a robot with a modern CPU, you would have to use a part that draws 65 Watts. This requires a large power supply, a big heat sink, and simply more mass than what Nvidia is offering.
Availability
So far, the core of the Jetson TX1 has already found its way into commercial products. The only slightly creepy Jibo social robot uses the TX1 for face tracking and image classification. The newly announced DJI Manifold also uses an Nvidia Jetson.
The Jetson TX1 Developer Kit will be available from Newegg, Amazon, Microcenter, and the Nvidia store on November 12th for $599 retail, or $299 with an educational discount. The TX1 module itself – with a 400 pin board-to-board connector I can’t source at the moment – will be available for $299 in 1000 unit quantities through worldwide distributors. There is no pricing yet for single modules, although I would expect a group buy to pop up somewhere on the Internet shortly.
While a $600 retail price for a development board is a big ask for the kind of products we usually see hitting the Hackaday Tip Line, comparing the Jetson TX1 to a $30 Raspberry Pi does it a disservice; by no means is this a general purpose device, and apart from a few outliers who are still mining Bitcoins on their GPUs (and on Nvidia cards, at that), doing anything besides playing video games with a graphics card is specialty work.
As far as developments in embedded computing go, this is a big one. Over the last 10 years or so, the coolest parts of desktops and servers has been the raw power a GPU can throw at a problem. Putting a module this capable in a package that draws only 10 Watts is a huge advancement, and although it’s not really meant for the garage-based tinkerer, the possibilities for the advancement in the field of computer vision on embedded platforms is huge.














Keep in mind that what costs $599 now will drop in price significantly in the next few years due to Moore’s Law and competition. Another cool thing about needing only 10 watts power (Qmax) is that the unit can run silently in a completely waterproof enclosure using solid state heat-pumps.
Why does everyone always feel compelled to mention Moore’s Law? It’s not even a law, it’s a hypothesis that only is valid when you twist it’s definition. You refer to it like Moore’s Law is what’s governing the activity of these companies when really it’s the other way around. It doesn’t mean anything.
It is relevant to anyone studying AI now because it gives you a clear idea of what sort of solutions you should be able to afford to implement in the near future.
5 years from now you will have a supercomputer on your wrist for less than the cost of a big night out with your friends.
You can thank the accuracy of Moore’s law for being able to predict that. Accurate laws describing phenomena are very useful tools because they allow us to position ourselves to take advantage of the changes, and that is the difference between myself and a monkey.
Back in the Old Days, before Moore’s Law was broken, Intel, AMD, and others planned their future releases on Moore’s Law remaining consistent. If it takes 2 years to develop a processor and bring it to market, they reasoned, our design goal is to produce one that matches that outcome, if we fail, our competition may succeed, and our product won’t sell.
Moore’s law is not broken, there are a always going to be transitional bumps but the law is, when applied to $/flops/watt/time, true enough. How is this for a game changer? http://www.cqc2t.org/ I could give you a big list of recent developments, but you know how to find stuff yourself, right?
Moore’s law wasn’t about money, or power consumption. It was simply that computing power was increasing by some factor every so many units of time. Those were the only factors.
BTW the cqc2t thing you mention, is basically the same as this board here, except less powerful.
Oh, no it isn’t. Wrong link! Ignore me.
Okay guys, the “before it was broken” was meant to be tongue-in-cheek, but also as a pre-emptive strike for those who would comment “But Moore’s Law has been brokien since 2005!”.
Greenaum: moore’s law wasn’t about computing power but about the number of transistor in a die.
So call it Kurzweil’s Law if you like but the phenomena stays the same. Honestly I think Moore deserves to keep the law in his name, the fundamental insight was his after all, wasn’t it?
Ah man, Ray Kurzweil’s gonna be so pissed off in a few years, when he dies. He’s way too late for his magic AI to save him, and he takes more pills than… complete that yourself.
So far I believe the number of computers doing research on designing better computers is approximately zero, and silicon’s hit a speedbump.
Ahhhh bullshit, Intel have publicly acknowledged that their new 3D computing process could not have been designed if they did not have the previous generation of super computing technology to work out the materials science issues. And humans stopped doing chip layout a long time ago.
Yeah but chip layout, like PCB layout, isn’t research. It’s not open-ended, it can’t produce new information, only optimise existing plans. Same with simulation, it’s the humans who do all the work creating the sim.
Computers can help make research faster, but the speed at which we can think stuff up is the bottleneck. That’s not going to get increasingly faster. That’s what “The Singularity” seems to rely on. The exponential growth is what leads to the effectively infinite computing power that Kurzweil equates with intelligent AI. Which is also an assumption not merited, and relying on human invention.
Face it, Ray, you’re fucked! Enjoy the cold, cold ground.
All we learned by that rant is that you are a spiteful and resentful person. Time to stop and think about what you are really telling the world, about yourself.
Moore’s Law has slowed down in recent years, and will continue to decline. Why? Because you can’t break physics. Quite simply, the advances made in earlier decades in silicon wafer technologies where comparatively easier than those needed now to make the next big leap. The theoretical limit for the smallest logical block would be at the atomic scale (as in, to make an AND gate for example would require X number of atoms, minimum). This discounts quantum computing. So we might see a temporary sharp rise when significant breakthroughs in processes come along or QC becomes practical on an industrial level. But immediately after see a sharp decline again. You simply cant get any smaller.
Notice that CPU frequencies have not increased much in the last 10 years according to Moore’s Law. Instead, we just pile on more cores.
Going smaller and smaller is like going faster and faster. The increase in difficulty is non-linear.
The next big phase in the short term will be 3D stacking of gates. Not simply stacking wafer on wafer, but actually building gates directly on top of (and interacting with layers above and below) other gates within the single wafer. This technique is already close to being mass fab ready, and will give us another momentary leap.
But in the end, Moore’s “Law” is becoming less predictable every day.
I think that you mean that CMOS has slowed down. Silicon is not the only semiconductor material. We can make the transistor channels out of InP. The added advantage of InP is that once it is there, we have access to a semiconductor with a direct bandgap and we can make optical interconnects on the chip. Now, that is awesome.
Exactly there is a plethora of alternate technologies that offer multiple paths forward. For example graphene, if you cut holes and specific pattern on the edges of the lattice you can control the local behaviour so that it ranges from superconductor to semiconductor to insulator. Imagine the devices that will be possible when we can grow or etch graphene with atom level precision? Imagine if we then take that to the next level and have the graphene fold into complex 3D surfaces that are like a computing “membrane” such as a Schwarz P-surface.
i.e.
Make devices such as these:
http://www.sciencemag.org/content/320/5874/356.abstract
Into a citcuit configured like this:
https://en.wikipedia.org/wiki/Triply_periodic_minimal_surface
Using something like this:
http://onlinelibrary.wiley.com/doi/10.1002/smll.201502048/full
And hey guess what, there is nothing stopping it happening within the next ten years because all of the above is solid applied science not theory.
Moore’s Law is on it’s way out anyway. Transistors are approaching the minimum possible size to be able to get any sort of signal without being overwhelmed by noise, and clock speeds have been stuck around 4GHz since leaping forward through the ’90s and 2000s. I’m not saying progress has stopped, but the unbelievable speed things were advancing at a while ago isn’t something to rely on in the future.
That is so not correct. What is a computer anyway? It is a self interacting pattern that is Turing complete. You can implement that in many different ways and the resolution of the universe, in terms of hosting said patterns, is so vast that the total current computing power on Earth could fit into a space that is smaller than a hydrogen atom.
Moore’s law will be on track one way or another for longer than Humans v 1.0 exist.
That is sooo not correct.
Moore’s Law is simply the observation that the number of transistors in a dense integrated circuit doubles approximately every two years.
He made no mention of any of the other factors commonly misattributed (here and elsewhere) to Moore’s Law. Moore’s observation did (often correctly) support predictions about power consumption, processor power, or even alternative computing paradigms, but none of those items were mentioned in his original prediction.
So while your predictions may in fact turn out to be accurate, grouping them under the aegis of Moore’s Law is incorrect.
As far as it being broken, when his paper was originally published 50 years ago, he predicted a one year interval for each doubling of components, in 1975 he revised this to two years. He may have revised it again fairly recently (yep, he’s still around at a ripe old 86 years)
anyway, just sayin’
csw
Yeah I’ve read wikipedia too, but my point was that the law/observation is still relevant as it does predict the acceleration of technology, and it will continue to be “correct”. To transfer your argument for the sake of abstracting it, since when did Ohm’s law actually give you the exact value that your instruments measured? :-) See what I mean? There is a point at which nitpicking really is just monkeying around.
your argument is poor, but it effectively is just an another expression of compound growth. There is no need to be mysterious about it or use some bizarre futurist thinking and jargon to express exponent math. in fact, you lose most of your audience with this choice, and the rest of your audience with Kurzweil-like misrepresentations
Interesting claim, now demonstrate it instead of just making it. Because I can demonstrate my claim.
I’m not sure if the TX1 exists. The TK1 may be the same product (or the correct name). Here’s a link with a serious discount:
https://developer.nvidia.com/embedded/makejtk1/
I think the “TX1” is a lot different (way more powerful) than the “TK1”. Below are links for each.
http://nvidianews.nvidia.com/news/tiny-nvidia-supercomputer-to-bring-artificial-intelligence-to-new-generation-of-autonomous-robots-and-drones
http://www.nvidia.com/object/jetson-tk1-embedded-dev-kit.html
the tk1 is the previous revision (not x86, more like a raspi in terms of performance)
Note that the TK1 (“K” not “X”) is available for $99 http://makezine.com/2015/11/05/exclusive-50-off-nvidia-jetson-tk1-devkit-for-just-99/
You are a beautiful person. I just spent $99 dollars thanks to you :P
Except they are backordered to all hell. I assume they were just clearing out stock right before announcing a new board, which turned out to be the case. I wonder if they will even make new boards to fill the orders?
Hello Board-I’ve-Wanted-To-Exist-For-3-Years!
It’s still a hefty chunk of change, but this should be a wonderful boost to mobile robotics with embedded neural networks. I hope it finds a UK/European distributor.
Embedded neural networks? Is this like the Intel board that has a hardware-implemented nueral network? Or just a gpu/software based neural network?
This is just a shitload of CPU cores on one little circuit board. Sci is talking about using this board to run a software neural network, embedded into a robot. Not a hardware NN embedded into this board.
I hate to be Mr. Meticulous, but the cores that were mentioned are anything but CPU cores :) Graphics processors are able to get such HUGE performance out of them (Compare i7 5th gen to Titan Black in terms of FLOPS) because they do not operate like CPU’s. I don’t have my reference book on hand, but most GPU’s can scrape… 50-90GFLOPS. Whereas yesteryear’s low end graphics card (think gtx480) can get close to 1TFLOP. Frankly, GPU computing is really terrible for a lot of applications, but when an application can be done with a GPU, there’s really nothing better in terms of FLOP/watt or raw computing power.
Yeah OK, they have a lot of limitations on what they can do. But out of all the circuits that they might resemble, a CPU is closest. They do follow instructions and manipulate data, stored in RAM. Sure they’re not as general-purpose as a real CPU, and some jobs they don’t do well. But it’s still a CPU core. As you mention, if you can bend an application to fit the hardware, they do very well. Same thing applies to traditional supercomputers.
It actually (sort of) has existed for the last 3 years…
At Tokyo Maker Faire a few years ago, I met up with some of the hardware guys from NVIDIA. ONE of the many projects and demos on display had a much smaller board than the others (everything was running on Jetson boards except this one). It was about half credit card in size, like a double wide pack of gum. Naturally I asked a lot more questions about that somewhat hidden board than anything else.
Turns out it was a product they were working on which had originally been intended for space applications (there were plans for all sorts of shielding). Essentially image computational power for GIS satellites. Performance wise it was somewhere above the Jetson, but likely below TK1. Im only making an educated guess, based on what chips were available at the time.
I asked about availability and pricing, and it was WAY out of any normal person’s league. Something like 8-10K USD. But that they had plans of eventually releasing it or some version of it for the open market, IF they could justify a use-case for it (read “when the market is ready for lots of small machines needing big embedded processing power”)
My guess is the TK1 is the results. They have certainly respun it, as I dont remember, for example, it having wifi onboard.
I thought the Intel board with the built-in neural network was cool. For executing a deep neural net, seems like a dedicated chip would be cheaper that this $600 board.
Note that while NVIDIA quotes 1 TFLOP/s performance, this is for FP16 math, not FP32 as the standard (for many apps, incl. the DNN training they suggest) goes. A bit sneaky, as I was initially very impressed by the perf/W ratio… I guess we’ll have to wait and see how the actual performance stacks up.
I think fp16 would be fine for weights and training (but I’m not an expert). But the real question is, why do you need a gpu to execute a NN?! Won’t training always be done on a supercomputer with lots of test cases?! I mean, one little robot is not going to observe enough to make a data set for training. You’d need lots of robots to upload to a central repository and do the training offline. Then download the results/weights into you little cheaper robot with a hardware NN chip.
Depends what you’re trying to learn, having independent autonomous robots learning stuff is certainly a popular idea. While you don’t need a GPU, they’re full of massively parallel processing units, they have a lot in common with supercomputers. Indeed lots of supercomputers already use GPUs, and Nvidia produce special versions of their GPU chips that are tweaked for supercomputing instead of graphics.
The idea of having robots learning independently, in the field, without the vast bulk and cost of a supercomputer, without needing a super at all, is surely a field that’s gonna find a lot of application. We’re now in the days of the pocket supercomputer!
Yeah I’ve been noticing that sneaky figures are becoming more common across the board as of the last few years :/
Goddam hard drive manufacturers! And what mental defective thought people would start saying “kibibyte”?
need for high precision for neural networks is a common misconception
http://arxiv.org/abs/1502.02551
They seem to be using 16 bit fixpoint though. 16fp is more like 12 bit fixpoint in the same application.
“The Jetson TX1 uses a 1 TFLOP/s 256-core Maxwell GPU”
Lest anyone misunderstand the importance of that simple statement, there was a time not too long ago when the thought of a computer of ANY type, supercomputers included, running at 1 TFLOP/s was such a revolutionary thing that even just the prediction of it made big computer news.
No we have that much computing power in a tiny 10W board…
Very true, now an individual can afford buy 10 of these units to have more computing power than the largest super computers had back around the year 2000. See, IBM ASCI White
That is a mind-boggling advance in affordability in such a short time which indicates that we can expect as big a jump again in the next 5 years due to the exponential nature of technological progress.
It’s bonkers, innit?
http://blogfiles.wfmu.org/KF/2014/03/12/rocket_sled.gif
“Lest anyone misunderstand the importance of that simple statement, there was a time not too long ago when the thought of a computer of ANY type, supercomputers included, running at 1 TFLOP/s was such a revolutionary thing that even just the prediction of it made big computer news.
No we have that much computing power in a tiny 10W board…”
Quite true, but how many individuals can make solid use of it on their own? I mean REALLY use it..
The power efficiency should really be reflected upon. Other small boards in this class (but at a lower cost) will burn about the same amount of power, like an ODROID board, or a RasPi or one of the many clones (Banana, Orange, etc).
This runs on the same 10W, but can do 10-20x the performance for select applications, for the same power budget.
*tsk,tsk* HaD Avertisement Monday’s…
Let’s just ignore the fact that CUDA isn’t OpenCL/SPIR/SYCL…
You want CHEAP NVIDIA TEGRAS? They are produced in BULK.
http://www.nvidia.com/object/automotive-partner-innovation.html
http://www.kitguru.net/laptops/mobile/anton-shilov/nvidia-50-car-makers-are-using-drive-px-platform-to-develop-self-driving-cars/
The rub is now the black boxes now get even blacker.
BUT FOLKS! WTF! We’ve had Google Nexus 7 (2012) Motherboard – 8 GB $19.95 (Product code: IF235-019-3)
$19.95 for a Tegra K1
An NO ONE is even interested in fuzzing the chips and getting to work parallel?
Not every thing has to be open source in order to be good.
Hmmm. Yes and no. The lack of available cheap components combined with closed/proprietary code and tools, turns into a stagnant sandbox.
Feels very akin to Apple IOS/Xbox/PS4/Nintendo; are they good tech? Yes, are they super limiting to developers and end users alike? Yes as well.
So, In our case here, lack of documentation and support. Stacked with NDA clauses to everything vs Raspberry Pi and Arduino mindset.
Anyway, nvidia is trying to retain some cred in the ARM / Embedded space. They imagine faster is better BUT unless you are a corporate customer; end-users are treated like crap.
A Tegra K1 (with closed CUDA) board is $19.95.
What IS it about HaD advertising mondays.
On Mondays, most people are in a fog, easier to slip stuff past them.
B^)
Really, $19.95? Where do I get one?
ifixit google nexus 7
Google sources say the Nexus 7 (2nd edition) uses a Qualcomm part. The 1st generation used an nvidia tegra 3 part, which is vastly different than the K1.
https://en.wikipedia.org/wiki/Tegra
The tegra 3 CPU is 32b quad core ARM processor running at 1.2 GHz, vs K1 being a 64b dual core ARM processor running at 2.3 GHz. The GPU (the part most relevant to the neural network stuff) is entirely different and more capable too — it is based on the Kepler GPU architecture (derived from the desktop GPU family) instead of the lower end GPU designed specifically for the older tegra parts.
[Jimmy Barf] Are you tarded? That’s okay had a gf that was tarded. She is a pilot now.
Listen here. What part of $600 dollars did you not listen to? What part of CUDA did you not hear? What part of Closed Drivers did you NOT HEAR? Are you deaf or blind?
So, Let me understand you. You want to validate this “New” $600 product for hackers/hobby makers when in fact. No one has resolved, worked on or experimented on the “OLD” 2012 chipset?
Please. Do tell. You rather have a $600 sh1t board or 19 shares of nvidia stock?
Sheesh, DD, you are an abusive twit.
You said, “A Tegra K1 (with closed CUDA) board is $19.95.” I asked “Where”. You said “Google Nexus 7”. I showed that the Nexus 7 doesn’t have a tegra K1. Then you heaped abuse on me and brought up questions that I didn’t ask. You were wrong. You can’t admit you were wrong. You try to obfuscate that you were wrong by being insulting and diverting the issue to points I didn’t bring up. In summary, I’m sure your ex-girlfriend is happy to be such.
Jim B, His name says it all. He digs. Deep. Like a Lemming.
“I proved that you’re wrong, and if you’re wrong I’m right.”
http://www.funcage.com/blog/wp-content/uploads/2013/04/12-Inspirational-Quotes-From-The-Wisest-Fake-Politicians-011-550×822.jpg
People know 4 things about nVidia hardware:
1. Proprietary CUDA compilers make for a horribly expensive code base for developers
2. Anyone who is responsible for reliable systems has seen their hardware catch fire 2 or 3 times (the warranty states you need to keep your original receipt). We will never include their stuff in anything valuable again…
3. Memory copy-to-gpu models are inherently a bottle neck for large linear data streams like video, so only a few cases will one see a problems performance improve. However, other types of operations which avoid overlapping subset of gpu memory resources can be accelerated if your C++ code isn’t garbage. For AI learning, 4GB of RAM is nowhere near the 16BG per CPU core minimum most people end up using, and in most research code the library will simply crash instead of thrashing disk io.
4. The only people who will seriously want these are Bit Coin miners
Bitcoin mining is long past what GPUs can do. Now it’s all ASIC farms running in China on power they somehow don’t have to pay for.
Meanwhile sharks and conmen have long since spotted a market full of geeks with spare money, who know everything about algorithms, but very few of the classic financial cons. Running cons and fraud is where the money is in Bitcoin now.
Either some really major changes are gonna have to be made with Bitcoin, or they’ll have to start the concept over again, and this time get some finance experts in on it. It’s a shame cos the idea of digital currency is certainly needed, and has been for a long time. It’s just apparently hard to get it right. Or else the banks would have had a go at it ages ago, with some centralised system that gives them an advantage, but at least gives the customer some security. Actually that’s credit cards, isn’t it?
What do you mean by “expensive” code base? Parallel programming does require all sorts of special skills, semantics, and API’s, absolutely. There is no reason that it shouldn’t.
There are *tons* of accelerator paradigms out there now. Thrust, OpenACC, ArrayFire, OpenCL, and CUDA, just to name a few.
Many problems can just be done with libraries that already exist, or in terms of primitives that are very accessible through things like Thrust.
Tegra has shared memory. Zero copy. Point 3 is null. Read the docs.
As for your point 4, well, this deserves a bookmark, because in 12-18 months time, you will be shown to be *very* wrong. This board and other Tegra modules that are making their way onto the market are going to be THE next thing in robotics. Stereovision, mapping, feature recognition, online learning, and so forth. Nvidia already has a ton of usefull acceleration in place in OpenCV and cuDNN, and other libraries built on top of them.
Especially when it slips into Wednesdays… XD
No, seriously any attempts to take a Nexus 7 motherboard or similar and attempt to fuzz the pins?
@ $600 you could have 2 GeForce GTX 970.
@ $600 you could OWN 19 shares of NVIDIA STOCK.
@ $600 you could have a incredible evening of dinner and rub elbows at a fancy dinner function.
@ $600 you could easily have a 10 hours of massage or 2 escorts of your preference service you.
WTF, nvidia, closed drivers, cuda BS, deep learning.
Well WE have learned Deeply you are better off getting a Audi Assisted Driving Computer from a salvage/scrap AUDI.
A Nexus 7 motherboard doesn’t have remotely the same amount of power as an X1 chip, you utter fuckwit. At $600 you could buy several therapy sessions to help you become less of an insufferable tool.
I think his point was that we people have access to significantly cheaper parts that while not as fast are in a similar performance class and would work just fine as proof of concepts (and likely for many projects), but apparently no one has done this? If that is true, is the availability of this board, especially at its price point, that important for hackers?
insufferable.
It really isn’t in a similar performance class. The tegra 3 is not a GPGPU device, it’s not CUDA compatable and never can be. The hardware has dedicated pixel and vertex shaders with a maximum of 24bit fp and very very limited documentation. It also only has 12 cores, not 256 cores. I chased the very similar Tegra 2 with the hope of doing ‘proper’ computation on the GPU and nothing that turned out to be possible was remotely worth the effort. Tegra 3 has NEON (Tegra 2 does not) and if you have to use this chip, this is the best it has to offer a typical hacker.
OH BOO HOO. He was off by one model number. Nexus 9 vs Nexus Nexus 7.
https://www.ifixit.com/Store/Parts/Google-Nexus-9-Wi-Fi-Motherboard/IF286-003-1
And THAT one is 29.95.
You can skip the nvidia shield portable, As nvidia won’t and doesn’t sell replacement parts. https://forums.geforce.com/default/topic/744332/replacement-parts-/
Finally, If you really want to get up in it. https://www.ifixit.com/Store/Parts/Google-Nexus-10-Motherboard/IF305-001-2
Really what is puzzling is defending a company that only sells components to companies and not end consumers.
And as you and Dan luv to point out https://en.m.wikipedia.org/wiki/Tegra#Tegra_X1
Either one of you indicate logic boards for phones or tablets for US. The HaD community. AKA END-USER/HOBBYIST/HACKER to play around with? No?
Well enjoy your $600 closed source/closed supply channel paper weight. Nvidia NEEDS CUDA and ARM developers to code for and prove to the 50 or so auto makers that support and skill for their mobile platform is viable.
We can say “Fine, New product, Protecting IP, etc.” but not offering Tegra 2 or 3 for us to work with?
Maybe DeepDigger is a blunt and caustic person. But I hate to admit it. He is right. Split hairs over the small details but these new boards are overpriced and crappy in the grand scheme of things.
Very attractive price for a K1 board and the nexus 9 is rootable, but those parts are second hand and the site says they only have one of each. The nexus 10 uses a Mali GPU and they don’t have any anyway.
I’m not seeing the goldmine of cheap high performance parts that would underpin and validate your post but if someone is smart and very very careful there is a hack to be had.
The entirety of your moral argument about price is outlandish and baseless. This is what development boards cost. Look at any Zynq board that is built out to the same specs as this module, with a camera, 4GB RAM, and plenty of IO expansion, and you will pay the same or more. And you will still have to use the Xilinx tools.
And if you want actual, published head-to-head comparisons, check out SlamBENCH. A standard SLAM workload is run on a number of different boards, and the performance is reported. The Jetson board, using OpenCV code that was was contributed to by Nvidia, which uses the CUDA library, blows everything clear out of the water:
http://arxiv.org/abs/1410.2167
I did look at the Zynq. And found it REALLY lacking. (I’d prefer a Spartan-6 LX150 with a STM Cortex-m7f).
2003, 970 3.5 not clean 4 gb and most recently http://www.se7ensins.com/forums/threads/nvidia-once-again-cheating-benchmarks.1353515/
Not saying SlamBENCH is wrong but trust nvidia? I couldn’t care less.
>you utter fuckwit.
I really enjoy these sessions we have together. Unfortunately, we have plateaued in personal growth. I think a real personal growth therapy for me would come from hiring some morally flexible individuals for $600 to beat you with socks filled with sand or bags of oranges for the lulz. Witcatcher. Good day.
Well hello, sailor! This ought to speed a few projects up…
http://www.nvidia.com/object/automotive-partner-innovation.html
Do you happen to work with one of these guys? Hell yeah Rider of Brohan! I’m certain the boss of the R&D will mostly… probably… kinda… sign off on buying a bunch of these units.
Also, The “She” has sailors in every port. So, make sure loose lips don’t sink ships. 0 / by 0.
Fuck off you annoying cunt
Hah, marketing shill detected.
I don’t have any experience in computer vision or neural networks, but especially for the latter I’d think FPGAs would be more appropriate. GPUs seem to me best suited for complex processing on independent data, while an FPGA can do simple processing on lots of interrelated data. GPUs can of course a execute a simple program and output the results to a buffer (‘render to buffer’ in graphics programming), ‘synchronize’ their cores, and then operate on that buffer, but that context switching could be quite expensive in terms of both time and memory. Programmable logic wouldn’t have to do that, and in some cases could even begin processing before all the input was received (ex. object recognition before the rest of the image had been received).
I know Altera has been advertising machine vision applications for a while, and some chips have ARM cores built in (Xilinx’s Zynq has some HaD fans). It’s still proprietary, but Nvidia is also notorious for that.
Quick re-hash of good HaD posts. FPGA’s excell at Floating Point Calc. DSP/ARM’s are good a Fixed Point.
Not going to get into the technicals as I don’t feel like it but if you have a chance look up a thesis paper based on a hybrid fpga and dsp based system.
tl;dr – If you know the right steps and build out the correct system: you can build your own desires from reality because you’d be the storyteller and writer.
Here is a freebie since I pitched to a former PRC Lt. who in turn was a greed piece of garbage…. What about a partnership where your phone idle is part of a massive computational cloud to solve world problems and you earn real world credits for participating on contribution?
like 20 year old BOINC (@home) but with battery/connectivity/heat problems?
Battery would be the big one, phones spend most of their time with everything possible switched off, to be usable at all. Communication too, cellular data must be one of the most expensive ways of sending bytes.
Still, there’s probably plenty of idle CPUs sat around in people’s houses. But again they’re probably idle for a good reason. For the cost and effort of getting data into the CPU in someone’s high-tech fridge, you’d be better just buying the CPU yourself.
If one day IOT and cloud computing come together, maybe that will be something somebody could exploit, in the 15 minutes we have left before the world ends. And I really can’t imagine anyone virus-scanning their fridge more than once, before they go back to using the old-fashioned stupid kind.
Ideally it was designed to make use of ram and cpu in corporate office environments thus lowering the amount of space/cooling/maintenance required from a data-center. A dash of SpiderMonkey/torrent/pgp keypoints yeah. Primary architect target for desktops/laptops and thin-clients. It also had load balancing for AWS and Azure based on off peak calculations.
Sure. Kinda like @Home. Also highly applicable 2nd marketspace was to have pieces small enough of non-infringing encrypted data chunks available for Triple Play between clients in the subscriber network. Less servers, less latency, more content, more affordable services, happy customers, better profit margins and lower cost to customers.
Of course I didn’t (nor still would ever give) the “secret sauce”. I gave a long discussion about the merits of javascript, python and LLVM but *meh*.
Bottom line was this project would be complete in 2 years, including QA and testing a specified city either HK or Shaghai. Without me the tech would not be viable or available for approximately 10-20 years.
Basically I listened to a 2 hour slide show how they would apply “Enhance image” meme (the Faststone sharpening filter) to existing cameras. They didn’t like their bluff called.
“FPGA’s excell at Floating Point Calc. DSP/ARM’s are good a Fixed Point.”
I think you got that backwards, unless you’re referring to fixed point only DSPs of course.
No. Have to give it to DeDigger. spend anytime on the BitCoin hardware design forums and you see all out battles in implementations.
Here is a quick read. https://hal.inria.fr/ensl-00174627/document
FPGA’s are unbeatable at Floating Point. It’s FIXED point they have trouble with. Hence embedding DSP slices inside the grid array. You want a FPGA, if you want massive amounts of entropy generated. Tons of Benchmarks on the subject.
The design bottle neck is performing square root and division.
Is there a reason you can’t do fixed point well in an FPGA? It’s all just logic. Fixed point seems simpler, hardware-wise.
A bunch of Zynq boards are hitting the market, but I don’t know if Xilinx has an answer to this, yet. There are applications for which an FPGA is a fine solution; Tesla has them all over their cars, because they had to be pressed into service, the product was not mature, and field upgradability is a hugely useful piece of flexibility to have. (as an aside, Tesla is operating so far on the bleeding edge of things that they are pretty much continuously re-engineering cars that are already on the road, and the vehicles are patched up under the guise of “service”).
On a Tegra chip, you can simply install Ubuntu, install OpenCV, and compile and run demos right away that are super accelerated. You can write Thrust code in plain C++, and you will get some acceleration. Zynq … afaik, the picture of how that is going to be useful to tinkerers or even the average engineer is just really not clear. HDL is more of a mess of unsolved technologies than parallel programming, and has an insanely steep learning curve.
Still, research is being done. Every single project you see these days is now a RasPi + Arudino, for linux + realtime. Zynq has the possibility of making that very easy, and flattening the interface way down, by just memory mapping independently clocked microcontroller-like peripherals, and automatically making linux /dev nodes for them for dead easy access. Except … I don’t think anyone has written a very high level language to actually do that for you yet, and you have to be an EE superstar to put it all together.
Chisel is trying to be the answer to that, but still suffers from being a research-focused tool with a tiny userbase.
+1 Excellent contrib.
Not to get persnickety Tesla motors S model uses 2 nvidia VCM’s (Jetson – TK1).
http://arstechnica.com/gadgets/2014/05/nvidia-inside-hands-on-with-audi-lamborghini-and-tesla/
In the vision system, yes. *Many* other part of the car have modules with FPGA’s in them somewhere.
Also, the article says right in it the article that the Tesla is using the Tegra 2 and 3 chips, which are predecessors to the K1.
BUT, I am fairly certain that the the auto-drive units do have X1’s in them, dual X1’s, as this was talked up a lot at CES at a big Nvidia talk, with boards and modules explicitly shown:
http://www.anandtech.com/show/8811/nvidia-tegra-x1-preview/4
and
http://wccftech.com/nvidia-drive-px-dual-chip-tegra-x1-revealed/
I wish someone would give me a job based on knowing all this junk :\
The old Jetson TK1 is plenty powerful for what’s described in this article. It’s 55$ Lot cheaper.
Where can you get it for 55$?
See this :(jetson tk1 devkit for just $99)
http://makezine.com/2015/11/05/exclusive-50-off-nvidia-jetson-tk1-devkit-for-just-99/
Unfortunately I live in South Africa and it is verry expensive to get it here….
But would Linus Torvalds approve?
Probably, as far as he’s concerned, he doesn’t really care what people do with their invention/product, so long as it’s not explicitly hostile to the end user, like most current forms of anti-piracy.
He only used open source because it was the model that he felt worked best for Linux. He has no real philosophical connection to it.
Richard definitely wouldn’t.
As a physicist: images per second per watt cancels out to images per joule.
Thank you. People on this site really need to get back to the fundamentals.
I thought I saw a link somewhere saying that the new Jetson would be available starting at the beginning of 2016 via various distributors (I’m guessing Digikey, et al.) for $299 apiece.
10W doesn’t seem like embedded to me. That’s just like a laptop.
Maybe if you’re talking about laptops from the 80s. The Raspberry Pi 2 uses about 4.6 Watts maximum, and an iPad uses about ~7. 10 Watts is quite low compared to most devices in its use case; thus, embedded.