
Personally, I’m a fan of trains. They’re a nice, albeit slow, way to get around the country. Canada isn’t the best candidate for rail transit, given the rather large space between coasts, but Via Rail does operate regular train service in their corridor between Windsor and Quebec City.
Unfortunately, passenger rail has to yield to commercial rail in Canada which often causes delays. After noticing that some trains have very frequent delays, it seemed like it would be useful to know the average performance of each Via train. Via does not provide this data publicly.
However, they do provide some data about arrival and departure times. Digging into the data available through any browser viewing the Via Rail site, it was possible to query for past scheduled/actual arrival data. The result is TrainStats.ca, a display of Via’s on time performance. Join me after the break as I discuss how this all works, and how to pick a winner when buying your next train ticket.
Getting the Data
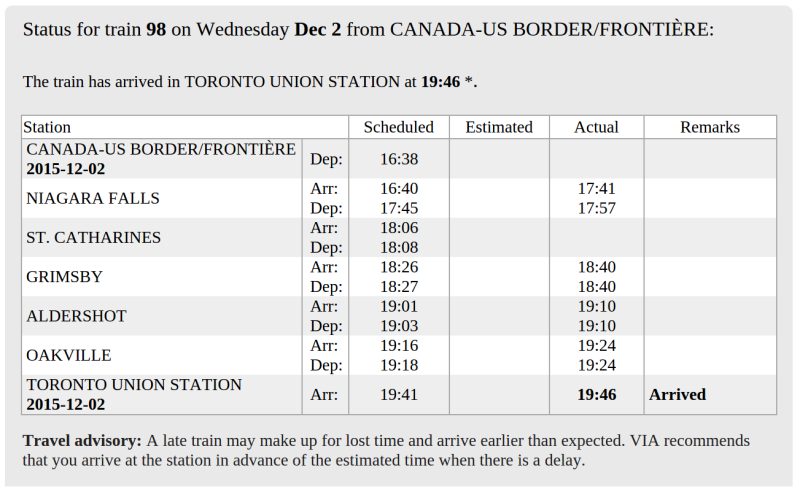 Via does provide schedule data for the previous, current, and next day on their status page. This would let us build up a set of trip data, but only one day at a time. Fortunately, we can fire up Chrome’s inspector and find this get request:
Via does provide schedule data for the previous, current, and next day on their status page. This would let us build up a set of trip data, but only one day at a time. Fortunately, we can fire up Chrome’s inspector and find this get request:
There’s a few juicy parameters here. TsiTrainNumber is obviously the train number we’re looking at. DepartureDate is the date the train left, and ArrivalDate is when it arrived. TrainInstanceDate also appears to be set to the date the train left. With this in mind, it’s time to jump into Python and use the fantastic requests library to forge some requests.
https://gist.github.com/ericevenchick/ed74c8128c8122dd2876
This code allows us to fetch data for any train number on any date. After some testing, we found that Via’s data goes back to April 2015, which gives us over 6 months of data. For each trip, we get the scheduled and actual arrival and departure times for every station. With that information, we can easily calculate how delayed the trains are.
With the page data fetched as HTML, a script was hacked together using BeautifulSoup to extract all the values. This script then creates objects for the trip data and stores them in a PostgreSQL database using SQLAlchemy. This makes it easy and efficient to access the data later.
The last step was to iterate over all the train numbers and days to pull the data. This script just uses some nested loops to grab the data and store it. Another script grabs the previous day’s data and stores it in the database. This is set up on a cron job, so the database stays fresh.
Building a (cheap) Website
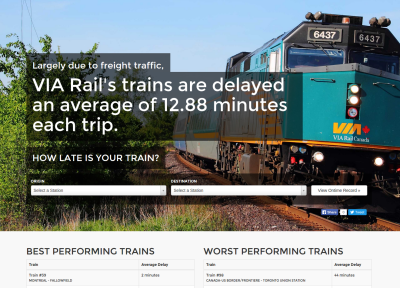
At this point, we have arrival data on over 12,000 trips. While we can manually run queries and write scripts to generate plots, it’s far more fun to put the data online. That means it’s time to build a website. Making things look good on the internet is not my forte, so [Phil Everson] jumped in to do some web development.
To add a constraint, we wanted to make the site as cheap as possible to run. Platform as a Service offerings like Heroku ran about $20 a month. A Virtual Private Server from DigitalOcean would cost at least $5. The cheapest option was to make a static site.
A static webpage is a trip back to the days of Geocities. You can host files, but cannot do any processing on the server. Fortunately, this worked well for the type of data we were providing. All the aggregated trip data could be exported to JSON files, and Javascript on the client side can load the data and display plots.
The TrainStats site consists of some HTML, CSS, and Javascript that runs in your browser, and a collection of JSON files with the data. The dataset gets generated daily by another cron job, which allows all the processing to happen in one go on a local computer. Then the Amazon Web Services Command Line Interface is used to push the data to S3, where it can be retrieved by users. Since the datasets are small, and S3 is cheap, this makes the costs lower than typical hosting.
The Results
This hack was mostly built for fun, but it has a few interesting findings. On my usual Ottawa to Toronto route, I’m more likely to opt for the train that’s on time 84% of the time, versus the one that only rolls into the station without delay on 28% of trips. Some other travellers might find the stats useful as well. Either way, it was an interesting exercise in scraping up a dataset and providing a web service on the cheap.
If you’re interested in the source, it’s all up on Github for the taking. We kindly request that you don’t DDoS Via Rail with it.














Hello there fellow Canadian, I live in Ottawa!!!
Nice little work you’ve done there!
I am not convinced that they are delayed by freight train, b’coz everything “should” be planned, even the wait time required to yield for them.
Would be curious if you could pull out more detail regarding delay causes.
Also keep track if there is a tendency to get worst which could means the system is weakening.
Keep the good work!
VIA and I believe Amtrak railroads don’t own their own trackage, they buy operating rights on existing railroads, and yes they often have to yield to freight traffic (which is complete bullshit, I think.) And alot of North American track is poorly maintained and barely adequate.
I love trains and train travel. We spent over 3 weeks in Europe, getting around on a Eurail pass, and it was spectacular. In Switzerland and Germany, they were all apolegetic if a train was more than a minute late. Here in Canada, they’ll cancel a whole morning of commuter trains because of one switch malfunction.
VIA has bought a lot of track this decade, especially between Brockville – Ottawa, and Ottawa – Montreal. This is why the best on-time performance tends to be on these routes. That track has also received over $1B in upgrades the last few years, aimed at reducing travel time and increasing reliability (this includes adding track between Kingston and Toronto).
Meanwhile, delays and reliability worsen on the rest of the corridor VIA doesn’t own, because all the North American freight mainline railways are completely congested.
Nice piece of work on bending big data to the needs of the public, but I have to say the first line of your article could be better “They’re a nice, albeit slow, way to get around the country.” That would be your country Canada and probably the US also, but I hasten to point out not every country is saddled with the Freight over Passenger dichotomy.
Many other countries have fast efficient passenger rail systems that in many cases are much faster than road or even air transport (if you include all the wasted time in traffic and security checks). For example, if I were to travel from Central London to Central Paris by Train it would take about 3 hours including metro/taxi rides at each end. To do the same by Car including the channel tunnel would take around 6 hours and to do so by air including travelling to and from the airports, security checks and flight time would take upwards of 5 hours plus.
Perhaps he was referring to instantaneous vs average velocity.
nice, I like stuff like this. how long before they step into 2002 and use hidden post variables?
You should submit this to the CBC, I saw a story on there about how Via is pushing to get separate rail lines in order to make the service faster.
You can probably get really fancy about it and probably just pick up rail traffic via SDR.
nice front end on the website btw, looks really good. I did notice horizontal scrolling under 1200 px wide, may want to make it more responsive than that.
Note that via does not post the arrival data for their cross-country trains, like train #1 and #2. I’d be really curious on what an average delay for those trains would be. On those trains a 3 hour delay is considered normal, and a delay > 24 hours happens somewhat regularly…
Actually VIA does post the data. You just need to finesse the search. For instance, open: https://m.reservia.viarail.ca/en#/trainstatus/search , and type, as the arrival station, “Vancouver” for “Today”. Leave everything else blank. It will tell you (as of typing) that it was nearly 1 and a half hours early arriving into Kamloops.
Obviously the code would have to be significantly finessed to do these queries, and make sense of them given that Trains 1 & 2 (and 5&6) are overnight. In the case of Trains 5 & 6, there is a deliberate overnight stop in Prince George which would also need to be dealt with in the reporting.
As for Train 1, last time I took it, it was 7 hours delayed and the VIA call center people were pretty clueless. When I got to the station, the station agent actually showed the computer and noted that the operations center staff weren’t even bothering to log the positions of the train properly. The organization is a real gong-show internally in terms of its IT and pretty much everything it does. Kind of scary when you think of it.
Looking forward to get something similar in France for SNCF, coz thanks to our government, the (open) data is readily available here: https://ressources.data.sncf.com/explore/
Amtrak in the US is subject to the same delays from prioritization of freight traffic. It’s not uncommon for trains to be delayed by several hours. Service is so poor outside the east and west coast corridors, you have to really want to take the train as an end in itself–and sometimes Amtrak will transfer passengers to buses to make up the delay, so you don’t even get the trip you paid for!
Yeah, but there is still something innately fun about hopping on a train in Reno NV, switching in Chicago IL, and stepping off in the mountains of Virginia. The only thing I disliked about that family trip was that we got delayed and went through the Rockies at night, so I couldn’t sit in the view car and take pictures. The 3 hour delay just a few stations outside of Chicago, because of some freight that couldn’t move? That was just time for us kids to sit in the empty dining car at 4 am playing poker.* I don’t know if the sleeper cars are economical enough to make that a worth-while trip anymore; at the time it was a good deal cheaper to take the train back since we flew to San Francisco and drove to Reno (two one-way flights versus a one-way flight and a sleeper car).
Why 4am? Was supposed to be in Chicago at about 11, I think, to hop off, stay at a hotel for a day and see the city, then keep going east. Long delays in the mountains and a 3 hour full stop because of freight meant the best chance to sneak out of the sleeper cars and just chill out.
That’s a great find! We need something like this with OC Transpo in Ottawa to get a better mapping for that too.
fraphost vps is $25 a year if you’re interested.
http://lowendbox.com/blog/fraphost-25year-1gb-openvz-vps-in-las-vegas-nevada/
Cloudatcost pricing starts at $12/yr for a VPS.
I remember sitting on a siding somewhere in northern Ontario waiting for a freight train to pass… The other big thing working against rail travel in Canada (that the USA doesn’t have to deal with) is that our population is mostly hugging the southern border (brrrrr! Canada cold!!!) So, all of our traffic runs mostly along a line, whereas the US can route trains in more of a 2D system.
There is no capability of re-routing traffic in the US. Nor is there in Canada for logistical, customer service, and operational reasons. US freight railways do not divert trains along different paths to help Amtrak be on-time. The key difference between Canada and the USA is that Amtrak trains have legal priority in the US while VIA is subjected to the constant abuse of CN dispatchers who naturally extend no special consideration to VIA’s needs. There are many areas in which the sidings simply are inadequate for the length of the CN trains so VIA gets sidelined by default.
Railway has only seen basic sustaining investment for much of the past 100 years in Canada since the great railway boom/bust of the 1910s. Its actually ironic that passenger trains had much better on-time performance in the 1950s than they do today.
Rail, IMHO, has always been the poor red-headed bastard step-child of transportation funding in N/America. It isn’t glamorous you see, but no one wants to publicly consider the pollution one single turbofan engine pumps into the atmosphere let alone the others hanging on the wings. Trains aren’t fast enough for today’s folks.
One it’s own an average of 13 minutes seems hardly worth bitching about. Much more interesting to read how long the longest delay was, as well how short the shortest delay was.
Last time I traveled by train for a long distance was approaching four years ago, but…. Largely that’s still factual. Amtrak administratively owns the rails covering th distances between Baltimore and DC, and from DC to Miami its all the problems of CSX. Maintenance by Metro North has greatly improved since that big storm several years ago, and NJ Transit’s has declined…… So all of the comments made and statements made might also be factual.
*the —- silly keyboard on a five year old laptop acting like a five year old human,
Wow, fascinating website. I wonder if you could include stats for Trains 1 and 2, and Trains 5 and 6; the Canadian and the Jasper-Prince Rupert trains respectively? Because they span multiple days and even include prolonged planned overnight stops (ie: Prince George for Train 5 and 6), its more of a programming challenge. But good data is something the public needs to have if they’re to write to their Members of Parliament and demand that something be done, in terms of policy changes, investment, etc. Everyone in VIA knows that they have abysmal performance, but I’m not sure “Joe Public” really appreciates how bad the problems are, particularly on the Canadian that was 9 hours late last time I rode it.