
Every twenty to twenty-five years, trends and fads start reappearing. 2016 is shaping up to be a repeat of 1992; the X-files is back on the air, and a three-way presidential election is a possibility. Star Trek is coming back, again. Roll these observations back another twenty-five years, and you have The Outer Limits, Star Trek, and riots at the DNC convention in Chicago.
History repeating itself is not the exclusive domain of politics and popular culture. It happens with tech, too: the cloud is just an extension of thin clients which are an extension of time-sharing. Everything old is new again.
For the last few years, Soft Machines, a fabless semiconductor company running in stealth mode, released the first preview for an entirely new processor architecture. This new architecture, VISC, offers higher performance per Watt than anything available on the market. If you’ve been paying attention for the last decade or so, the future of computing isn’t 200-Watt space heaters that also double as powerful CPUs. The future is low power machines that are good enough to run Facebook or run some JavaScript. With servers, performance per Watt is possibly the most important metric. How will Soft Machines upend the semiconductor market with new processors and new architectures? If you know your history, it shouldn’t be a surprise.
All CPUs have some sort of Instruction Set Architecture (ISA), and whether it’s x86, ARM, SPARC, Power, or Alpha. Different ISAs can are faster at some tasks, and slower at others. The 6502, for example, makes for a beautiful stack machine, much more so than a Z80. This is why you’ll find most old Forth implementations running on 6502-based machines. That’s not to say the 6502 was designed to run Forth, it’s just a peculiar coincidence of history that made the 6502 a better stack machine than other architectures. This, in turn, made languages designed around a stack faster on the 6502.
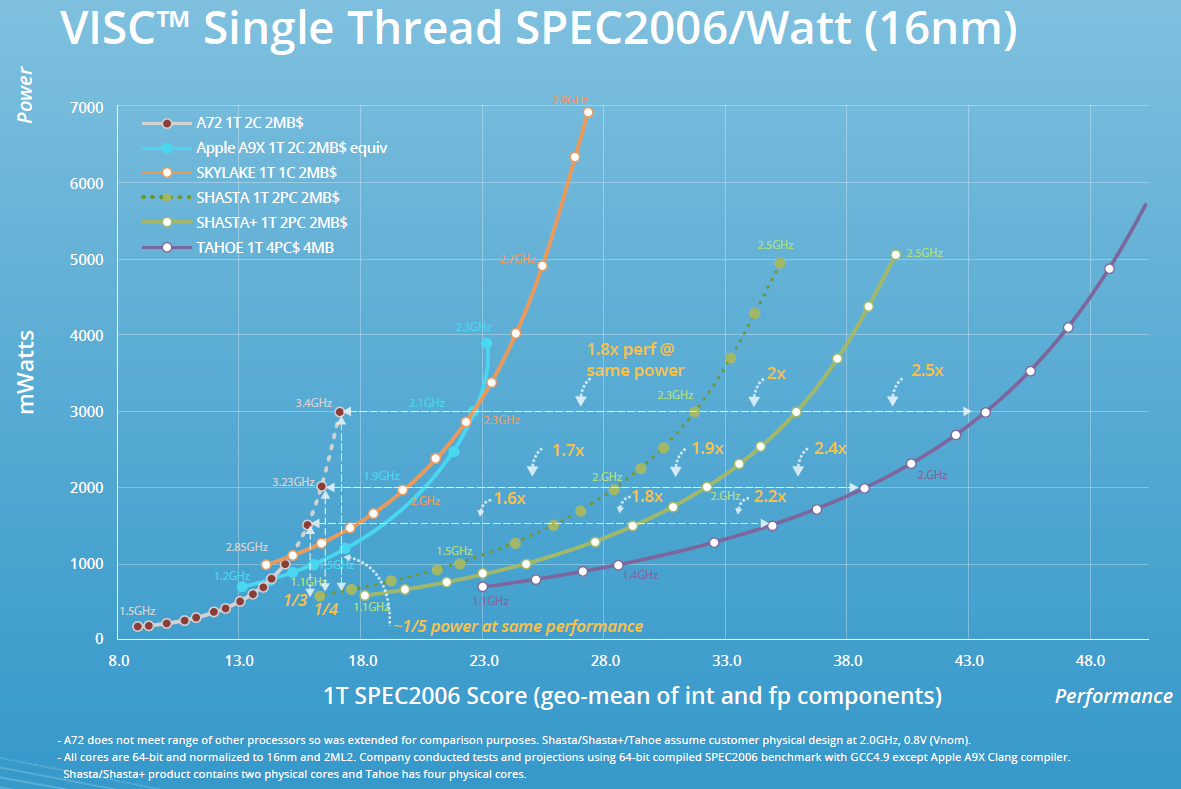
Different ISAs mean different performance, and this also means different power requirements for certain applications running on different processors. ARM chips are making inroads into the server market simply because of a key metric: performance per Watt. This is the key factor behind Soft Machine’s research: to produce a CPU with the highest performance per Watt. Their ISA is called VISC. That’s technically not an acronym for Variable Instruction Set Computing, but it’s descriptive enough to tell you what it is. VISC is a completely new ISA that translates x86 and ARM instructions into something else that offers much more performance per Watt.
Think of it as a video game emulator. When you play Pac-Man on your PC, the emulator converts your keyboard presses into joystick movements, and turns the CRT output into something that will run in a window on your desktop. Soft Machine’s chips do the same thing, only directly in silicon.
Yes, This Does Sound Familiar
Back in the early aughts, there was only a promise of low-power devices. While the chips of 16 years ago were low-power compared to the 100+ Watt monster CPUs of today, building an ultrabook, a tablet, or any other device that required a low power processor was hard. The industry found an answer to this problem in Transmeta, a fabless semiconductor company that developed low-power x86-compatible chips that would find their way into the subnotebooks and tablets of the day.
Transmeta’s Crusoe and Efficeon CPUs weren’t x86 chips. Instead, the x86 instructions would be converted via ‘code-morphing software’ into native instructions. These native instructions would run more efficiently in low power devices, but at a cost: an interpreter, a runtime, and a translator for x86 instructions was required. This would need to be installed on every device with a Transmeta CPU.
To be fair, the idea of an upgradeable CPU is an interesting one. New instructions could always be added, hardware bugs could be fixed in software, and the CPU could emulate other architectures in addition to x86. There were even rumors of a hybrid PowerPC and x86 processor from Transmeta in the late 90s, something Apple would have been very interested in. Unfortunately, Transmeta was a victim of the dot-com bubble, eventually shutting down their engineering division in 2007.
History Doesn’t Repeat Itself, But It Does Rhyme
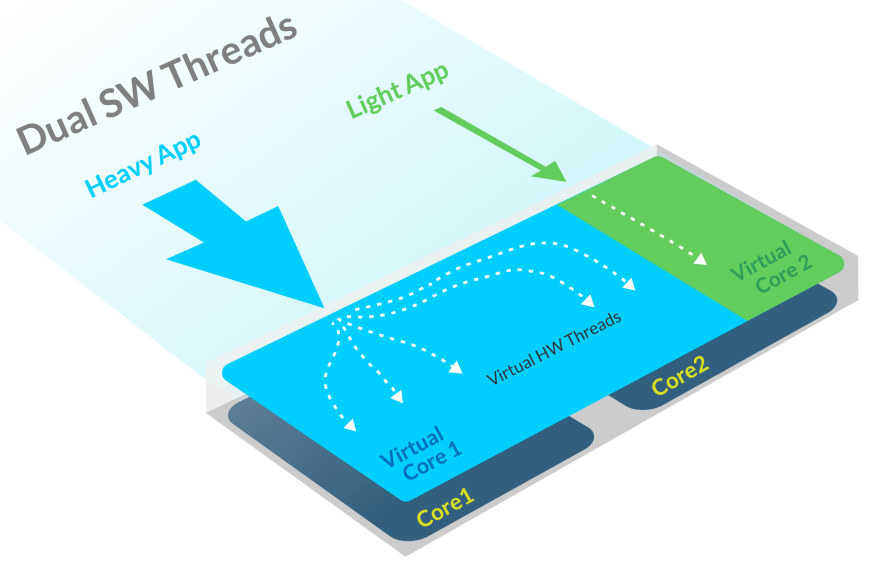 There are significant differences between Soft Machine and Transmeta. Soft Machine is doing everything in silicon, and not relying on software translators to turn x86 into whatever VISC actually stands for. There’s another trick up Soft Machine’s sleeve: multiple, virtual cores. This is a lot like how hyperthreading on Intel CPUs make a quad-core CPU appear as an eight-core CPU.
There are significant differences between Soft Machine and Transmeta. Soft Machine is doing everything in silicon, and not relying on software translators to turn x86 into whatever VISC actually stands for. There’s another trick up Soft Machine’s sleeve: multiple, virtual cores. This is a lot like how hyperthreading on Intel CPUs make a quad-core CPU appear as an eight-core CPU.
Again, Soft Machine borrows from history while taking it one step further. The Soft Machine CPU will best Intel by implementing multiple virtual cores across several physical cores. These cores will be able to scale at will, dedicating more resources to more demanding processes.
All in all, Soft Machine borrows randomly from the recent history of computing. It also doesn’t technically exist yet. The IP and design is there, but the only silicon produced so far is just test chips of single cores.
According to the company roadmap, these chips may be coming soon. An SoC designed around a 16nm process should be taped out by the middle of this year. It will, of course, be much longer before these chips make it into production and are stuffed into devices. When that happens, though, Soft Machine promises lower power devices that can perform just as well as the quad-core ARMs of today. That means more powerful smartphones, longer battery life, and very interesting teardowns when this device is actually released.














i’d be interested in see how it performs on a monster sized FPGA.
Very badly. Anything would, those things run at something like a thousandth the speed of a “real” CPU. But you’re right, it might be an interesting comparison to other CPU designs. I’m sure Soft Core does that, as well as Intel, AMD, et cetera.
Er, what?
With the Nios II FPGA soft CPU, I found the biggest constraint is fetching from the external DRAM.
Testing on the $60 dev kit shows one can approximate the performance of a 200Mhz x86 per core, but this is the main reason there are hybrids with ASIC based quad core ARM CPU and memory managers. Note, power efficiency on a FPGA is not what they were designed to accomplish.
While exotic architectures sound awesome, history showed that proprietary designs like the PS3 Cell microprocessor eventually became unsustainable as the developer base changes focus to meet market demands. Notably, the newer ARM+GPU SoCs cost under $5 now, and generally most LCDs will waste more power than the CPU.
These guys missed their market window by 8 years.
The power consumption problem in a mobile device isn’t really about when the LCD is on, but when the LCD is off.
Smartphones suck too much battery just on standby to replace a traditional candybar phone, because even if you don’t touch it it’s still going to die in 3-4 days. It’s the same sort of annoyance as wind-up wrist watches.
If that annoyance outweighs the use you get out of a smartphone, you don’t need a smartphone and shouldn’t buy a smartphone.
Ferraris use too much fuel to replace an econobox like mine, even if I don’t floor it it’s still going to run out of fuel in half the distance… But that’s ok because I don’t have a Ferrari because I don’t need one (literally the only reason, cough).
My Samsung Note 4 will stand by for 20 some odd days! In this mode, it can use a browser, play audio (for a few days straight actually), take calls, do SMS, and a few other basics.
I’ve tested this on long trips, and it does what it says on the tin. My candy bar phone wasn’t as good as the Note 4 is when in it’s ultra low power mode. No airplane mode to stretch battery needed. I get more features and they are usable too.
It’s obvious to me the biggest problem we’ve got on current phones is software. The battery, display, etc… are plenty good enough, and again, given my experiences with this phone, can easily beat what we had with the candy bar type phones.
Hmm – I think you miss-understand FPGA.
*Normal* CPU’s don’t *Run* as fast as the ridiculous GHz speeds they use for sales promotion.
Modern FPGA is probably a lot faster than you think.
With FPGA it can be like – well if 300MHz is too slow then just code in 500 cores.
And none of this matters when it comes to CPU power per Watt because FPGA is so power hungry that it’s never used when power consumption is a primary consideration.
Even though FPGAs are pretty powerful nowadays, they don’t even come close to ASIC. In addition, what matters in this situation is single core performance. So even if he codes 500 cores in the FPGA that wouldn’t give him much info about the actual performance as most software can’t really utilize more than a few cores.
Obviously ASIC is better for some things and FPGA is better for others.
But your comment – “most software can’t really utilize more than a few cores” … with good VHDL design the software would *NOT* be aware that there is more than one core – that’s what this article is about.
Adding more cores doesn’t help when you run place-and-route, and get thousands of timing violations. The layout within the FPGA is fixed in regards to dram blocks, flip-flops, etc, so the interconnects really start chewing up time.
>interconnects really start chewing up time.
1st rule of and 2nd rule FPGA club.
Granted we are all aware how picosec and nanosec timings affect stuff. Internally AND externally… AND the fact that all modern x86 boards have the memory right next to the CPU now. OR that new GPU’s have split core “cheats” to direct access specific mem blocks. Even though our 4 gigs of memory is only 3.5.
I understand your point but the reason fro this is not what you think.
You do know that dram is Distributed RAM.
The only reason you can’t do *ASIC like* optimization with FPGA is that the manufacturer is protecting their IP.
I’m *NOT* saying your wrong – for today you are right – there was a time when manufacturers gave out information right down to the fuse maps and you could optimize until your heart’s content.
What I am saying is that this problem is not an aspect of the technology – it’s a problem created by manufacturers policies. It *can* be minimized with good design so it’s not the end of the world but no one is taught these things anymore.
Er, the D in DRAM stands for Dynamic, not Distributed.
@[arachnidster]
RAM – Random Access Memory (ASIC)
SRAM – Static Random Access Memory (ASIC)
DRAM – Dynamic Random Access Memory (ASIC)
BRAM – Block Random Access Memory (FPGA)
DRAM – Distributed Random Access Memory (FPGA)
Personally I love raw FPGA’s, fact is mating them with a external DSP’s (to handle div and sqrt) and building direct AXI-ABI Master Slave bridges to other raw FPGA’s is monumental. If you need read/write to memory I’d go for Cortex-M7… Now if they only got the M7F’s out the door.
If your “war-dialing” an algo sure you want ‘le jiggahurtz’… If you are collecting sensor data that is emitted below 200 Mhz a FPGA is rocking especially if you are looking for something like gravity waves or reading cosmic rays.
Not to mention FPGA’s don’t limit any ML or GenAlgo to instruction sets; it is only die space and Memory & DSP distribution. Not weird tweaky microcode bypasses. Or mal-rounded floats.
I’ll believe it when I can buy a chip and it is better than anything Intel sells. The spin is so strong one can hook up a generator and power a small city, actual demonstrations and facts are strangely missing.
+1. Chances are high they will follow the same path as mill.
The Mill isn’t really comparable. It is done by a small team, is not sponsored (AFAIK) by anyone but themselves, have no plans to sell anything yet and actually tells people what is unique (or uncommon) about it.
VISC have burned through a lot of cash, is a multi-year design project using a lot of engineers and tells no-one but (I assume) people that give them cash how they actually think makes their design better than earlier attempts of similar systems.
I hope the Mill succeeds even though I don’t think it will be a huge improvement of the state of art it would improve an important subset of e.g. technical computing. VISC? I believe it when I can run it.
It won’t be main stream until you get the development tools to take advantage of the new architecture and software guys to figure out their part. There is usually a very long learning curve for weird video game hardware and that’s with competitive coders with high budget. I would expect the main stream coders will have a even slower adoption rate than learning to deal with multicore.
Intel now owns Xilinx, so they’ll have a way of doing programmable hardware if/when that market is ready. They also has the full set of patents and lawyers.
Intel does not own Xilinx, but rather Altera.
I think the point is that it behaves like an ARM or x86 CPU, so there’s nothing new to learn. There is a translation layer which converts from those ISAs to its own internal format, then runs on those at lower power and competitive speed.
That’s the theory anyway. I’ll believe it when I see it.
One of the big reasons that AMD isn’t competitive with Intel is that the “best” compilers only produce code that is optimized for “GenuineIntel” CPUs. If this company can’t produce a compiler that can churn out highly optimized code for its VISC CPUs, Intel chips will still end up running apps at a higher performance rating, just like they tend to beat AMD’s x86 chips in performance.
There would have to be a huge difference is performance, or a huge difference in power used to also overcome the compiler optimizations that your processor will not benefit from in comparison to Intel CPUs. It seems as if they are shooting more for “use less power” than “provide excellent performance”, which means that if your only concern is power usage, they might be perfect. If you want great performance, you will likely still end up going with a battery-sucking Intel x86 or Samsung/Qualcomm ARM SoC.
Soft Machine is only novel because it is dynamic. Intel processors have not directly run x86 instruction for a long time. Intel translates the instructions into a more efficient intermediate “ISA” before executing them (microinstructions aka microcode).
Indeed, microcode architecture has been around for over 50 years.
Longer, arguably. The Analytical Engine featured instructions which called subroutines built into the “mill” (ALU) for complex tasks such as multiplication. Essentially the instructions on the punched cards were the outward-facing instruction set, and the “barrel controllers” which they called contained lower-level instructions which amounted to microprogramming. Consult Sydney Padua, probably the greatest living expert on that marvellous machine, for more detail:
http://sydneypadua.com/2dgoggles/the-marvellous-analytical-engine-how-it-works/
But that (x86 -> µops) translation is also dynamic – done at run time. Most processors use an internal instruction format even if they aren’t microcoded BTW.
Sounds like a chip with replaceable microcode (https://en.wikipedia.org/wiki/Microcode). Given that most CPU’s are microcode architectures, not a bad idea.
Writeable Control Store:
https://en.wikipedia.org/wiki/Control_store
That’s what I was looking for!!!
No most processors aren’t microcoded. One can argue that most desktop/laptop processors are (being x86) but that is just a small subset of processors used today.
Remember too, there were CPUs where you could load your own microcode, if you *needed* something special and fast. Not just CPU chips, but going back to even older architectures, pre bit-slice etc.
Like they say, nothing is new.
73
programmable microcode was included in the x86 chips from the p4 onwards
but that only allows you to edit the instruction set, not the cores physical configuration (like a FPGA) to make that instruction complete faster and use less power per instruction ,
sounds like he’s talking about semi reconfigurable cores ,
Back in the late ’80 there was some buzz over WISC (Writable Instruction Set Computer) that claimed considerable flexibility in system configuration. However, as I recall these were never realised on a single chip.
What changes is the underlying tech, sometimes for the better, sometimes not. I remember when example-based translation was a great idea but infeasible because source and target texts would require gigabytes of storage.
Maybe now the Moore’s law is officially winding down we’ll get new stuff, or at least more interesting old stuff. Because it will be worth implementing something weird rather than just waiting for next year’s conventional system.
Philip Koopman in his book Stack Computers writes a bit about MISC – they were 16bit and 32 bit home brew computer built from from AMD Bitslices. Essentially you could write your own instruction set with them.
If such a thing would work, Intel would have already done this in their own chips.
It took five paragraphs of fluff just to reach the description, apparently.
“Transmeta Crusoe” – who do I send the bill to for my PTSD treatments?
Transmeta was a victim of their own hubris, not the dot-com crash.
Transmeta was also how Linus Torvalds got into the US…his first “real” job IIRC
Which is good for him, I guess. But news of his employment there along with the Segway-esque secrecy theatrics made the fall hurt even more when they failed to deliver something competitive.
The problem is you need the whole ecosystem for it to perform well. Having the greatest, most flexible architecture means nothing if you don’t have great optimizing compilers for it, which gets harder to do the more flexibility you have.
“The Soft Machine CPU will best Intel by implementing multiple virtual cores across several physical cores. These cores will be able to scale at will, dedicating more resources to more demanding processes”
Now you need not only great compilers but also OS support as well.
not gonna happen. nvidia wanted to do the same few years ago, but the x86 ip explicitly forbids non licensed companies from producing hardware that can run x86 code, so they just dropped it and tried to go with arm (project denver anyone?)
if nvidia couldn’t, sure as hell these guys won’t too
If you haven’t licensed x86, how can you be bound by it to not make compatible hardware?
See also AMD.
ROFL … “See also AMD”
https://semiaccurate.com/2011/08/05/what-is-project-denver-based-on/
It is not so much the ISA that is the problem, it is the patent portfolio that Intel have that if it went to court you would loose. You could provide 8086, 80186, 80286, 80386 support with little issue, but any modern cores still covered by software patents and process patents held by Intel (and AMD) would be the downfall.
No one will throw millions at a product where your competitors can nobble you before the first fence. Intel do not even need to win, all they need to do it tie you up in court for years and drain all your resources.
exactly
NVIDIA’s switch away from x86 in Project Denver has to do with a patent settlement. Other companies are not bound by such settlements and can still do x86 without licensing it from Intel. But it’s a real patent minefield and most of the players have x86 licenses through one obscure way or another.
If anyone is interested… Check out the path AMD took to implement 32 to 64-bit and the “workaround” that Intel had to duct-tape and zip tie to get 32-64 compatible. We won’t count Itanium’s because they come with they own PTSD afflicted coders.
Mehh, I will pass and wait for the Mill CPU :)
The z80 however, is a better cpu for forth than a 6502. Consider the basic next operation in dtc forth ( from http://www.bradrodriguez.com/papers/moving2.htm):
The Z80 Forth register assignments are:
BC = TOS IX = RSP
DE = IP IY = UP
HL = W SP = PSP
Now look at NEXT for the DTC Forth:
DTC-NEXT: LD A,(DE) (7) (IP)->W, increment IP
LD L,A (4)
INC DE (6)
LD A,(DE) (7)
LD H,A (4)
INC DE (6)
JP (HL) (4) jump to address in W
So, this is 31 cycles for next. The 6502 forth from the 6502.org topic “Is this the optimal 6502 next”? Is 25-33 cycles.
http://forum.6502.org/viewtopic.php?f=9&t=1619
This means a z80’s basic forth execution cycle is nearly 2x faster than a 6502, given that a z80 traditionally ran at twice the clock rate. If we were to look at arithmetic operations etc we’d find the same held true, because the z80 has a 16-bit stack pointer you can push and pop 16-bit values and enough registers to store important forth registers.
Add is:
Pop hl
Add hl,bc
Ld b,h
Ld c,l
Jp dtc-next ; 39c, 70c total, 28Forth Kips on a 2Mhz z80.
But it is true there are more 6502 forths than z80 forths. And the reason isn’t because the 6502 is better at handling stacks, but because the 6502 is so poor at handling pretty much any kind of high-level compiled language, forth is pretty much the only recourse left to 6502 programmers.
Thanks for calling this out in a constructive way. I was pretty much ready to go on a huge rant about 6502 vs Z80 forth.
Now the 6809, that’s a nice cpu for FORTH…
I quite like the 6502, it’s an easy processor to construct a DIY computer from. Generally it’s pretty efficient and far more deterministic than the Z80. There’s a slight error in my Z809 calculations, the basic Next cycle is 38 cycles not 31, but overall it doesn’t change the argument.
The 6809 is pretty much the ideal general purpose 8-bit Forth CPU since it has so many pointer registers at least two of which can operate as stacks, and it’s possible to implement a single instruction DTC Next:
JMP [X]++ ;X=IP.
Enter is then hard-coded into the CFA as:
JSR Enter
which does, e.g:
Enter:
PSHU X ;save old IP on return stack.
PULS X ;get new IP from data stack.
VarDoes:
JMP [X]++
Exit is:
PULU X
JMP [X]++
DoDoes in a definer defined word is a JSR to the does> part of it’s (Being the designer of FIGnition, I still think in FIG Forth) and then the compile-time execution of does> compiles JSR Enter into the definer word (which causes the Forth execution to resume immediately after the JSR Enter).
Very fast, very efficient, 6809 totally rocks!
My question is will a raspi-esq device be made that implements this “fabulous new technology”
Is anybody else waiting for the return of the 36-bit variable byte size computer? (Dec 10/20)
You can only save power by using 8, 16 or 32 bits of logic where you would otherwise by default use 64 etc.. If you can partition your logic pool into various bit depths you could have threads running on cores that are only as complex as the task requires. I suspect that this will require very constrained and typed functional programming to ensure that you have an unambiguous finite state machine that you can be certain will fit into the reduce parameter space of the custom logic. Any logical function can be defined in a look-up table so that all instructions (of different bit sizes) execute in the same number of steps, but at the expense of chip surface area. Obviously a thread that uses a smaller bit slice is going to use less bits of instruction cache too.
Is that the sort of thing they are talking about?
PS. Anyone get that artwork? I really like the subtle, out-of-focus Jolly Wrencher in the doorway to the Chinese room.
Maybe I’m biased b/c I work here, but [Joe Kim] really hit that one out of the park, IMO.
Concur, hackaday has great looking art. Bravo to you, hackaday artists.
> and the CPU could emulate other architectures in addition to x86.
That is not entirely true. Back in the nineties, I worked at the computer architecture group at the TUDELFT. We had designed a fancy new CPU and would write an 8086-emulator for it! (or a Just In Time Compiler, something like that.) The problem turned out to be the “flags register”. The actual operations would emulate usually in one instruction, but keeping the (simulated) flags in sync takes three or four more instructions.
So, for the simple stuff like the flags register you need “hardware support” for the target architecture: Just implement in hardware a superset of the emulated CPU. Then things can become efficient.
Yes, this tech sounds interesting. but will it run SICP? Sorry I mean crysis?
I don’t know much about the inner workings of a computer, just the basics. However, assumed that cpu’s were editable and that they had virtual cores and not physical ones. I guess what I am saying is this; if I thought of this shit (and I am just a normal person) then shame on the geeks for not getting this stuff on the production line sooner, or better yet shame on their bosses.
The only cables which can be required to get
a system including this are definitely the main power cable which is plugged into an area socket.
It boasts EEBD kept inside for usage, in addition to a
pulley and rope system to evacuate injured or unconscious personnel.
Laredo alarm Gives you time – You ought to have the perfect time to decide when creating a bid decision like
what security alarm is best for your family members.
Neither systems must cost a big amount of money and
also the peace of mind how they bring are worth
every penny. They also have for being fitted with a NACOSS approved Alarm Company if police callout is required.