
If there’s one thing C is known and (in)famous for, it’s the ease of shooting yourself in the foot with it. And there’s indeed no denying that the freedom C offers comes with the price of making it our own responsibility to tame and keep the language under control. On the bright side, since the language’s flaws are so well known, we have a wide selection of tools available that help us to eliminate the most common problems and blunders that could come back to bite us further down the road. The catch is, we have to really want it ourselves, and actively listen to what the tools have to say.
We often look at this from a security point of view and focus on exploitable vulnerabilities, which you may not see as valid threat or something you need to worry about in your project. And you are probably right with that, not every flaw in your code will lead to attackers taking over your network or burning down your house, the far more likely consequences are a lot more mundane and boring. But that doesn’t mean you shouldn’t care about them.
Buggy, unreliable software is the number one cause for violence against computers, and whether you like it or not, people will judge you by your code quality. Just because Linus Torvalds wants to get off Santa’s naughty list, doesn’t mean the technical field will suddenly become less critical or loses its hostility, and in a time where it’s never been easier to share your work with the world, reliable, high quality code will prevail and make you stand out from the masses.
To be fair, it’s a different story with some quick-and-dirty hacks, or one-off proof of concept projects put together over the weekend. We can easily get away with a lot more in those cases. But once we step out of the initial prototype phase and aim for a longer-term development with growing complexity, we shouldn’t have to worry about the fundamental, easy preventable quirks and pitfalls of either the language or programming itself. Static code analysis can help us find and counter them, and again, since it’s such a common problem, not only with C, we have a large variety of tools at our disposal.
The one tool that gets often overlooked here, however, is the compiler itself, in particular its warnings. With open source in mind, let’s see how we can utilize gcc and clang to increase our code quality by listening to what they have to say about our code.
Compiler Warnings
Unlike compiler errors, which indicate actual language violations that prevent the compiler from fully processing the source code, warnings indicate that something doesn’t seem quite right with our code even though it may be syntactically correct. Compiler warnings are like a good friend eager to give us well-meant advice. Sometimes they warn of a deeper problem, but sometimes they’re superficial. We have essentially three options to deal with warnings: ignore them, hide them, or fix the actual issue in place.
Based on the introduction to this article, it may seem like this won’t be about the first two options, but the reality is a lot less black-and-white. With C running on anything from tiny microcontrollers to large server farms, not every warning is relevant or applicable to our situation, and while focusing on the right warnings can save us from misery, others might just waste our time.
Compiler Flags For Warnings
By default, compilers may not be too talkative about warnings, and mostly worry about immediate code problems such as division by zero or suspicious pointer conversions. It’s up to us to enable more warning options that we pass as flags to the compiler, and both gcc and clang offer a long (and mostly compatible) list of such flags.
To enable a given flag, we pass -Wflag , and to disable a warning, we pass -Wno-flag. If we are particularly serious about a warning, -Werror=flag turns a warning into an error, forcing the compiler to abort its job. Enabling every possible flag on its own seems like tedious work — and it is. The good news is that both gcc and clang offer additional meta flags -Wall and -Wextra that combine two separate sets of common warning flags. The bad news is, these are misleading names. gcc -Wall is far from enabling all warnings, and even gcc -Wall -Wextra still leaves out some of them. The same is true for clang, but it offers an additional -Weverything flag to fully warn about everything, giving us both an opt-in and opt-out approach.
But enough with theory, time to look at some bad code:
#include <stdio.h>
enum count {NONE, ONE, OTHER};
int main(int argc, char **argv)
{
int ret;
enum count count = argc - 1; // [1] signedness silently changed*
switch (count) {
case NONE:
printf("%s\n", argc); // [2] integer printed as string
ret = 1;
// [3] missing break
case ONE:
printf(argv[1]); // [4] format string is not a string literal
ret = 2;
break;
} // [5] enum value OTHER not considered
// [6] no default case
return ret; // [7] possibly uninitialized value
}
Style and taste aside, depending on your own definition and philosophy, we could address around seven issues in these few lines, with passing an int parameter to a %s format possibly being the most obvious one. Let’s take a closer look.
Some of these issues may not cause any harm in our specific case, for example turning a signed integer into an unsigned one ([1]), but in other scenarios it might. Printing an integer when a string is expected on the other hand is undefined behavior and most likely ends in a segfault ([2]). The missing break statement ([3]) will continue to pass argv[1] to printf() also when there’s no value set for it. Looking back at pointers to pointers arrangements, argv[argc] is NULL, causing another undefined behavior here. Accepting unsanitized user input is a bad idea on its own, passing it to printf() opens the door to format string attacks ([4]). Not handling every enum value ([5]) and leaving out a default case in the switch ([6]) results in ret being returned uninitialized when we have more than one command line argument ([7]).
By default, on x86_64 clang 7.0.0 warns us about three of them ([2], [4], and [5]), while gcc 8.2.1 waves us happily through without any warning whatsoever. We clearly have to step up our warning flag game here. Let’s see how the meta flags -Wall, -Wextra, and clang‘s -Weverything handle it. Note that -Wextra rarely makes sense on its own and is better considered as an addition to -Wall.
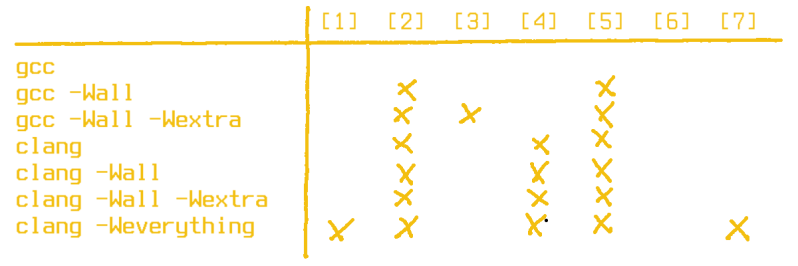
These are some sobering results. Unfortunately, clang doesn’t care about implicit fall through (i.e missing break inside a switch) in C, only when compiling C++ code, and it generally prefers complete enum handling over default cases. With gcc on the other hand, it’s obvious we need to take a closer look in the manual. Here’s how we can get almost all warnings:
$ gcc -Wall -Wextra -Wformat-security -Wswitch-default
Well, now that we finally have the warnings printed, it is time to get rid of them again.
Fixing your Warnings
After eliminating all the warnings, our main() function could look like this:
int main(int argc, char **argv)
{
int ret = -1;
enum count count = (enum count) (argc - 1);
switch (count) {
case NONE:
printf("%d\n", argc);
ret = 1;
break;
case ONE:
printf("%s\n", argv[1]);
ret = 2;
break;
case OTHER:
// do nothing
break;
}
return ret;
}
Careful though, assigning an integer unchecked to an enum is usually not the best idea, even more so when it’s argc. Also, in this example, the missing break in the switch was a real mistake, but in other cases you might want to purposely fall through a case. Replacing the break with a /* fall through */ comment (or similar spelling variations) will keep gcc happy — and will remind you and fellow developers that this is intentionally.
Sometimes it’s a bit trickier to get rid of the warnings though. Take the following example that involves a function pointer:
// callback function pointer
void (*some_callback)(int, void *);
// callback implementation
void dummy_callback(int i, void *ptr)
{
// do something with i but not with ptr
}
With -Wall -Wextra, the compiler will complain that the ptr parameter is unused. But what do you do if you simply have no use for it, yet the callback declaration insists on having it? Well, you can either cast the parameter to void, or dive into the world of compiler attributes. Here’s what either one looks like:
void dummy_callback(int i, void *ptr)
{
(void) ptr;
// do something with i but not with ptr
}
void dummy_callback(int i, void *ptr __attribute__((unused)))
{
// do something with i but not with ptr
}
Which one you choose is up to you, the compiler will generate the same code each time. But let’s stick with the attributes for now.
Compiler Attributes
We just saw that we can use special compiler attributes to individually suppress warnings without disabling them completely. At the risk of sounding indecisive, we can also use attributes to get new warnings from the compiler. Yes, we just got rid of them, so why would we want to get new ones? Simple: once we have a warning culture established, we can use it to inform other developers (including our future selves) how we want certain functions or data treated.
Let’s say we write a module for a bigger software project where one specific function returns a value that decides the fate of the whole module. We’d want to make sure that whoever calls that function won’t get away with ignoring that value. Using __attribute__((warn_unused_result)), we can let the compiler be the messenger.
int specific_function(void) __attribute__((warn_unused_result)); ... specific_function(); // compiler warns about unused return value (void) specific_function(); // nice try, still a warning though int ret = specific_function(); // now we're good
In a similar way, we can use two attributes to control our pointers, especially when it comes to possible NULL pointers, and generate even more warnings.
// declare that the first parameter mustn't be NULL void some_function(char *, int) __attribute__((nonnull(1))); // declare that return value can't be NULL char *another_function(void) __attribute__((returns_nonnull));
While this allows some compiler optimization, it also defines a contract for the developer: NULL is not a valid option for this parameter, and you don’t have to worry about NULL being returned.
some_function(NULL, 0xff); // warning that parameter is NULL
if (another_function() == NULL) {
// warning that check is always false
}
At the same time, if we actually returned NULL in another_function(), we’d get a warning about it, too. Not that we can really enforce anything with it, in the end they are just warnings without any consequences.
Adding Consequences
If you are really serious about warnings, you can decide to turn all of them into errors with the -Werror flag. You might want to reconsider that though, not every warning is fatal and needs to be addressed immediately. Sometimes you just want to get your idea out of your head and into the editor, and see how that turns out, and leave the clean-up for later. A useful approach is to separate your build environment to leave warnings as warnings during development, but once you build a release or merge to master, tighten down the rules.
Whether it really has to be -Werror is for you to decide, and there’s also the option to turn only individual warnings into errors. Let’s say we want to be strict about our NULL related attributes: -Wnonnull will enable the warnings, -Werror=nonnull will enable the warnings and treat them as errors. Note that -Werror=flag implicitly sets -Wflag, so we don’t need to worry whether a warning will be enabled or not, as soon as we turn them into errors, they’ll be there.
Where to go from here
Unfortunately there are some shortcomings in our last examples. While the compiler will detect the NULL scenarios demonstrated above, they are easily circumvented, whether purposely or by accident:
int ret = specific_function();
// return check ends here
// whether you actually use its value doesn't matter
char *ptr = NULL;
some_function(ptr, 0xff); // only explicit NULL parameters raise warnings
ptr = another_function();
if (ptr == NULL) { // no more warning that it will always be false
...
}
Does that make listening to warnings futile? Absolutely not, and we almost always end up with better code if we actively eliminate them. However, don’t let the absence of warnings give you a false sense of security, either. Compiler warnings are our first line of defense, and they can help us to improve our code quality, but they are no magic bullet. Making your code stable and reliable takes more than one tool. But then again, we have plenty more available for C, and next time we will have a look at more static code analysis using lint and its friends.














Why is division by zero such a big deal? When I made an 8 bit computer it just returned 255 and went on with it’s day. That’s a whole lot nicer for many things than having to stop and deal with a special condition.
(treating this as a serious comment…)
Integer case:
Because, even when it is not an actual process-breaking problem, which it often is, the desired result will likely depend on the problem at hand. Therefore, it is generally good to catch the issue and handle it appropriately, rather than equating 1/0, 2/0, 42/0, and 255/1. If you don’t care, ignore the warning or flag the compiler not to warn you. If you do care, then you can handle it, either by explicitly testing the denominator, using appropriate library tools, or trapping the hardware response.
Floating point:
This is a bigger issue. It is nice when a/b*b == a. If b=0, the result will be NaN, Inf (or -Inf), or 0, or, possibly even the expected result of a, depending on compiler, language, options, and hardware.
That would’ve not worked for me. For example, i’ve calculated stuff based on remaining time, so having x/0 = max value would have no worked. It needed to be 0.
It may become an issue when the output of said division drives something like pwm controller high power fets or the state of a safety cricital valve or any number of other mission critical actuators or sensing. Of course a good programmer should always enforce limits on any input/output which would catch such an error, but catching the error before it causes any discontinuities in something like a control loop will increase end performance and save a lot of headaches.
Fundamentally because division by zero doesn’t mean anything, so the behaviour very much depends on the environment that the code is to be used and the resulting unpredictability is the big deal.
Depends if Black Holes bother you.
Not personally :-) Unpredictability in C code is a completely different matter.
That’s not true. It means something very specific. “Undefined” doesn’t mean it is impossible to define it, it just means some humans agreed not to define it. But those humans work do their work by drawing symbols, not using computers. In engineering, they did define it, both for integers and floating point, and as above, they defined the standard differently for both. In floating point math on computers, 1.0/0 means infinity. -1.0/0 means negative infinity. 0.0/0 means NaN. In integer math, it means the computer does some non-math work instead. Modern languages follow IEEE standards on this.
IME, the vast majority of software wants the answer “0” anyways. In high level software on ints you can just catch the exception and return 0. In low level software testing it is usually faster. But remember, that exception isn’t nothing; it is something! The operation is defined; it means the computer is supposed to cause an exception or some other type of “error” state. But error states happen, they’re states just like all the other states the computer represents. The “error” part is just human perspective, it isn’t any sort of actual failure.
In old mechanical hardware, division was performed by counting the number of times you could subtract the divisor from the numerator before you hit a zero / negative value. If you divided by zero, you would be counting the number of times you can remove zero from something, which would run indefinitely and lock the calculator in an infinite loop
https://youtu.be/7Kd3R_RlXgc
Mostly because computers are based on math I guess.
Can we haz article about writing portable C?
Ahhh portable C, the ultimate pipe dream. It wasn’t portable 40 years ago when I started using it and it still isn’t to this day. If you narrowed down the systems that you wanted it to be compatible across then it might be possible to take a stab.
Portable C is easy to write, though.
That’s why an article would be useful; lots of people are doing it successfully, but others still don’t even believe in it!
I have a test that can give me an approximation of if somebody knows how to do it, though: Do they make an attempt to learn the whole language and memorize the standard? Do they know lots of detailed differences between different versions of the C standard? If so, then they probably can’t write portable C anymore. If they don’t even know those details, it means they were likely writing clean, portable code all along, and they didn’t hit the edge cases that lead to memorizing the standard.
But if they follow what is in this article and they understand warnings are important, not something you ignore, then just be not writing code that generates warnings they’re already much much more likely to be writing portable code.
Portable build systems are a way way tougher practical problem than getting the C part to be portable!
All good “in theory” but in reality we have to use libraries whose authors do not follow your rules. And your rules all fall apart when you have to interface with code that doesn’t follow your rules.
Can you write a portable program that runs on Linux, OSX and FreeBSD that uses the sendfile90 function? I am curious if it will meet your standards.
“Portable” is an overloaded word. What do YOU mean by “portable”? Is it something that compiles on different compilers, or 8 vs. 16, vs. 32, etc CPUs, or run on different CPUs (e.g. AVR, PIC, ARM, MIPS, x86, etc.) or CPU variants (ARM M0, M0+, M4, Ax, etc), or runs with different libraries, different IDEs (e.g. Energia, Eclipse, MS Visual Studio, etc.)? Portability is even an issue with different versions of the “same” compiler, and sometimes different host platforms (e.g. Apple, PC, Linux, etc.). It’s “complicated”.
“A useful approach is to separate your build environment to leave warnings as warnings during development, but once you build a release or merge to master, tighten down the rules.”
No, no, no! This just results in a world of pain – people check in ‘working’ code and go home. Everything on the automated CI explodes shortly thereafter. Repeat ad infinitum.
Do it right the first time, expend a few moments extra effort and save everyone else vastly more.
Exactly! Leaving everything till the last moment and having to fix many problems at once is a nightmare. Fix issues as the pop up to keep your project on track and not have any last minute crisis.
OTOH it’s nice to be able to just bang some ideas against each other while looking for a solution and NOT have the compiler be a complainer during that time. I agree that code that enters CI should adhere to the same rules no matter if it’s a dbg or rls build, but for the love of god, leave me the option to not run lint & co on everything WHILE I’m developing.
Make it a commit hook maybe?
If you’re ‘banging ideas together’ then keep it local. And locally, you can change whatever flags you like. Clean it up before submitting, or suffer the walk of shame to the donut shop…
Sort of the difference between while writing a book, correcting errors along the way, as opposed to leaving everything to an editor at the end.
+1. We had a policy of removing all warnings (and not by setting the ignore flags). They are either trivial and are simple to eliminate or they are serious and it doesn’t matter how hard they are to remove, they need to be gone.
The worst for us was signed/unsigned mismatches in library functions (our house banned the use of signed chars) but it was never a problem.
Ditto here. No warnings allowed. Loads of warnings flashing by on your screen tends to make you miss the important ones.
All team efforts I work on are on a strict develop-on-a-branch. So your branch might be with warnings, but as long as the CI reports warnings (possibly as errors) it cannot be merged. Sounds like a sound method to me.
Personally, I won’t even do anything with a warning. If there is a warning, that is a blocking problem that stops all other development work. Warnings are errors that have a different name merely for legacy reasons. :)
Many times I thought I needed to port some code, but it turned out the only reason that it wasn’t portable was that some knucklehead was ignoring warnings about types that can be ignored on one platform, but become errors on another. By the time the types are fixed and the warnings are gone, golly, everything else was already correct!
I learned my lesson after the umpteenth time I spent a day chasing a difficult bug only to find that the compiler warning I was ignoring because it seemed trivial/irrelevant ended up being the root cause. Now I won’t even bother testing a build or debugging it until it compiles with zero warnings.
had –pedantic -wall -wextra -o comments
:)
No, comments here is like Perl, write only ;)
Just a note, your first example has the comment “// [5] enum value MORE not considered”, but your the value in your enum that’s not considered is named ‘OTHER’.
Ah, I renamed the value and forgot to adjust the comment. Fixed now, thanks :)
Ugh I hate “__attribute__((warn_unused_result))”. According the gcc developers, it’s intended for cases where “not checking the result is either a security problem or always a bug”. As a result, unlike unused function parameters, casting the function return to (void) doesn’t suppress the warning.
I’d be ok with all of that, except that glibc went absolutely nuts adding warn_unused_result to things like “fwrite”. So now I have to either pass “-Wno-warn-unused-result” and negate any usefulness of that feature, or I have to spend my time making scratch variables, assigning to them, and casting them to (void) to make gcc shut up. gcc refuses to fix this because “It’s a glibc bug” and glibc refuses to fix it because they think the overzealous warnings are called for.
[1] https://gcc.gnu.org/bugzilla/show_bug.cgi?id=25509
[2] https://gcc.gnu.org/bugzilla/show_bug.cgi?id=66425
[3] https://stackoverflow.com/questions/7271939/warning-ignoring-return-value-of-scanf-declared-with-attribute-warn-unused-r
if fwrite fails, no data ended up on disk (if you are writing to disk, generally the case with fwrite) which is something you should account for, not silently ignore. If you don’t you end up with buggy software for someone, somewhere. Hench, the warning.
hence*
Are you saying you can’t do this:
(void) fwrite (<insert your parameter list here) ?
This warning in particular falls directly inline with MISRA rule 17.7 and it's a lot easier for devs to fix the build error rather than wait for a static analysis tool to find the error and flag a submitted change.
Why MISRA is a topic for a longer discussion.
But if you are curious about coding guidelines to help make C more secure, check out the SEI CERT C coding standard at https://wiki.sei.cmu.edu/confluence/display/c/SEI+CERT+C+Coding+Standard
Someone should make the Arduino IDE authors read this, several dozen times, at least.
Tattoo on the inside of their eyelids.
I guess you haven’t used a modern version. Yes, there used to be a lot of warnings years ago and that was horrible. However, the code is now largely warning-free. You might encounter some still in the less actively maintained libraries.
Casting an integer to an enum in the corrected example is also a potential source of problems if used with something that doesn’t have a defined range like argc, so it is a practise I would not use.
g++ won’t even compile it, as it needs an explicit cast. And it is indeed a really bad example.
Fair point, argc was definitely a bad choice for the example, especially after stating that you wouldn’t want to use unsanitized user input. Shows that eliminating warnings really isn’t a guarantee that the code is all peachy I guess ;)
I’ve added a note about it after the example now.
Don’t forget about the #warning macro!
I’ve found that getting into the habit of prepending any debugging code with a “#warning Doing X to debug Y” statement is a HUGE help later on.
Anything from extra debug printf statements, all the way to changing the behavior of a certain function to test how it handles certain cases, that #warning has saved me multiple times from accidentally including a long-forgotten debugging code change into a release build.
I make it a point to remove all warnings in our company C code. We found different compiler versions generated different warnings which we cleaned up each time. The warning we did turn off was unsigned vs signed. We always defined strings with unsigned bytes, but library routines expected just byte arrays. We decided that was not a warning we should be hassled about. Always checked for divide by 0 before the divide if there was ANY possibility and took appropriate action for the scenario.
For Windows I use mingw. For Linux gcc . So in my case the code is portable (x86 and x86_64). Runs across all Linux distros I tested and of course Windows. I designed a library for multi-threading and sockets, so the same API on both platforms and for x86 and x86_64. I modeled the thread system after VRTX which is a very easy RT API. Used VRTX on all our RTU/IED platforms, so it was a natural fit. Also made a portab.h file that was specific to platform and 32 vs 64 bits. So no need to change any code, just recompile and go. Anyway worked for us.
BTW, We felt C was a much better fit that C++ for our work. I still do.
“…we can use it to inform other developers (including our future selves)…”. Ain’t that the truth, a lesson difficult for the young to learn before it’s too late!
Good article! The problem i see is nowadays there is a “Lazy” factor in this new generation of coders. They seem to think I compile and tried it and it works so we are good to go. The Arduino rage has worsened this by magnitudes. So many people try to light leds, control relays, talk to I2s and SPI devices and dont even own a meter, or scope, let alone understand how to use them but yet hope for the best Just pure insanity and a clear lack of common sense. How do you know your driving the led properly, are your I2C resistor pullup values proper for the length of wire your using, or the voltage your running at, and the list goes on and on. They seem to think because the led flashes or the relay clicks all is ok.
Coders today are so dam focused on the quick satisfaction of getting it to work. They dont spend the time trying to make it fail. They pull in librarys and don’t even bother looking at what that coder did in the source to see if he was a dork or actually knows how to write code. They just assume, because it works they can ship product. They need to spend the time trying to make it fail. Thats where the bulk of the code comes from, preventing issues that could arise like if your reading a sensor and for whatever reason it stops talking, does your code hang, or crash? What if you were expecting a value of 0-255 from a sensor, but because you used 200′ of wire and some other device that started up caused a EMI onto your wires caused your system, to read back 1322, does your code account for that, or will it cause you to move your stepper motor to spin in the wrong direction breaking something. Ya, this generation of coders doesn’t have a clue anymore….
Not to generalize or anything lol. I do agree that a lot of younger coders have these shortcomings, but to generalize that your assumptions cover all of “them” is as ridiculous as it is dismissive (unless you happen to know every one of this new generation of coders and write flawless, bugless code yourself). And to even disparage the arduino/maker movement and its effect of proliferation of STEM outside of a once niche hobby is kind of silly. Would you prefer if only those ordained by blind nude virgin nuns be allowed to program, being raised above the plebian “non-programmers”? Sounds like you need to look at your need to compulsively bash those you feel are beneath you more than you need to worry about this generation of coders …
“The problem i see is nowadays there is a “Lazy” factor in this new generation of coders.”
I can’t say if that is true or not, but ‘maybe’ that is why you have ‘new’ languages that try to ‘hide’ memory alloc/free from you for example :) . And basic data structures that we all had to learn to use/write… The use of ‘exception’ handling when you could just check a return code… I guess someone is trying to bring ‘coding’ to the masses without any formal training? Hack it, if it runs/works… run with it.
Anyway, I just missed the punched card era (I was freshman, and seniors were the last using the card reader at the school). But there you ‘really’ had to check for quality of your Fortran code before you even submitted your set of cards to the computer center for processing! Some of that rubbed off on me I suppose as it was ‘stressed’ heavily in the lectures and tests back then even though we were writing Pascal on green/white terminals on the Vax where turn around time was much faster!
Hiding things in modern languages can improve code quality – if something is done automatically, you can’t do it wrong! Of course, that won’t teach you how it would have to be done in C, but C isn’t the measure of all things (anymore).
For example, exceptions are meant to unify and simplify error handling, make code more readable, more correct, and sometimes even more efficient. With classic return codes, it is very difficult to handle every single error case and if you do, your code will be cluttered with checks for errors. Exception-based code automatically checks for every error while avoiding the clutter. Properly combining this with RAII/destructors makes writing correct (i.e. better) code easier. I’d rather have compact and correct code (with some things done automatically) than overly verbose code where nothing is hidden.
Flash memory has also played a role in making programmers lazy. It is too easy to just reflash. I learned my lessson when a bug was found in 80 OTP 8051FA MCU’s and they all had to be binned. Boss was not very happy with me at the time lol.
This “some quick-and-dirty hacks, or one-off proof of concept projects ” is one of the key problems – as projects often don’t stay in that status, or even you come back and look at it again years later..
It’s actually FASTER to write correct code in the first place, on every project or even a 5 line script, once you get the hang of it. The it is easier to make sure it is working, easier to modifiy, easier to reuse, and easier to come back to much later..
And warnings are a really good way of helping that process..
– I’d say prove it. I’ve had to deal with much of this line of thinking lately of “It’ll save time/money in the long run to do it the long and overkill way now, even for this one-off project’…. Or the more extreme ‘we should rewrite this to a more trendy format; it’ll payoff in the long run’. For one, it’s not that hard to modify ‘quickly done’ code if you actually come back to it someday, negating 90% of any extra time put into it up front ‘just in case’ you ever revisit the code. Also I’ve rarely ever come back to a ‘one off’ projects in the first place (over the course of years, most of which one-off’s are still functioning in a production environment.
So I worked ar a grocery wholesaler once upon a time and the audit manager, who knew nothing about programming, had a SQL query that he cobbled together in an hour or two to calculate audit results. This code was used in a “production environment” for years to move around millions of dollars, The phrase “production environment” has no practical meaning. The reason it stuck around is because nobody else could figure out what “magic” thing he did in Microsoft Access to get the query to do what it did.
Maybe HaD can discuss things like MISRA, AuroSAR, and SEI CERT coding guidelines next. They can be very pedantic. But even if you are not working on a safety critical or secure product, the guidelines can still help you avoid a number of bugs.
A number of the warnings discussed here fall inline with a number of MISRA and CERT rules. It can be very helpful to let the compiler do the work of first line checking when programing to one of these rule sets.
The argc variable really should have a range check performed on it. The code will have a problem is 0 < argc < 3 is ever untrue. The C99 spec allows for argc to be 0 and if the enum is examined according to the C99 spec, it'll be { 0, 1, 2 }.
There are further subtleties where an enum could be a char, unsigned it, or sighed int depending on what the compiler chooses (and the compiler doesn't even need to be consistent within the program).
Just to make sure your comment still makes sense now: I’ve added the note that assigning enums unchecked isn’t a good idea after the comment above was written. It was a valid point at the time.
I see that note now. I also see a number of comments here concerning the use of an enum.
If you’re interested, I can discuss some of this from point of view of a group conforming to the MISRA C guidelines. My experience at work is that enums are a real minefield.
I work on a fairly large C++ project over 2000 source files as things stand with who knows how many lines of code and we always have “warnings as errors” enabled with specific warnings switched off via preprocessor directives where we know the warnings are red herrings (either globally or in specific instances)
There’s one problem with -Werror though. You cleaned up the code, you have no warnings-turned-errors and BAM! new version of a compiler or some library introduced new set of warnings and your code is broken all of the sudden. It’s nice if your build environment is set in stone and you’re still building your product with GCC 2.95.3, otherwise expect your nightly builds to blow up occasionally.
How is it a problem when a better compiler finds new problems? Warnings are not just gratuitous things to be cleaned up, they indicate actual problems in your code that have been there all along. If you really care about your code quality then you will compile with the latest versions of as many compilers as you can get access to. Even the Solaris compiler will find problems that other compilers don’t.
You see, warnings are, well, warnings. The compiler warns you that something _might_ be off, but that does not mean there’s an actual problem with your code. Just like the “unused return value” mentioned in the article. Do I really need to clutter my code with dummy conditions or unused temporary variables because the author of some library added an attribute to the function declaration?
I’m not saying that -Werror is bad. All I’m saying is that it may cause problems under some circumstances and that it needs to be taken into account. Where I work we do. But someone happily slapping -Werror all over the Makefiles in all the projects might have a bad day once things break.
This is especially problematic for open source projects, where you have a bunch of randos building your code constantly instead of just distributing the result. A good compromise is to enable -Werror during development but leave it off for releases. I’ll treat some specific warnings as errors always (format=2, format-security, implicit-function-declaration, init-self, missing-include-dirs, missing-prototypes, pointer-arith), but blindly adding -Werror is definitely asking for trouble.
If you’re requesting specific warnings be treated as errors, you also need to properly test that the flag is supported by your compiler; I see lots of projects where builds are broken on non-GNU-compatible compilers, or older compilers, just because of a compiler flag to enable or disable a warning isn’t supported.
The problem you mention has been well documented enumerable times. That’s why anyone who is concerned about the integrity of their embedded code, an absolute must in the commercial world, must fully document and maintain a baseline of not only their source code, but also the COMPLETE tool set as the specific compiler version, development platform (specific PC, OS version, memory configuration, etc.), and all debug/testing tools used too.
The release build should replicate easily, which is verified by a binary comparison of its the preliminary release run-time image with the “production” build. That way, you can demonstrate that the the code is indeed identical to what you did before. If it’s not, then examine the ENTIRE tool set for changes that may have produced unintended side-effects. If you want to “port” the code to another platform, then a binary comparison match ensures that there was no corruption of the released code and THAT version can be maintained (e.g. for a later branch with new functionality).
A “new” platform may be something as innocuous as a change from Windows 10 version 1803 to 1809. Why? Because you don’t know what got changed behind the curtain, nor what side-effects any changes may have had. Don’t think that this is overly cautious, because its not. It’s been demonstrated so many times in practice. Say for example, the code you build calls an OS function that has changed, which in turn changes the built code. It can be the most difficult problem to fix if undetected, especially over a few generations.
In my experience, we had this happen in the “good old days” all too often. Microsoft C 6.0 had serious issues with the versions of MS-DOS (or Windows) used. With the same level of optimization, it would produce different output depending on how much lower memory it had (some may remember the old 640KB limit), whether it had extended or expanded memory and how much. Some of the memory allocation calls would behave differently for different OS versions. It was a nightmare, which continues to today, albeit in other forms. Even variants of Linux are not immune. In one case, an Italian division acquired by the corporate “expansion” needed to send us code that we needed to modify. But when we tried to build the code, the compiles failed. We were told that we had to “ignore the errors and keep restarting the build until it works”. We tried that and it ALMOST worked after restarting about a dozen times. But our version quit at the same step so we knew it was broken. When we asked our Italian colleges about this, they confessed that they too only had ONE PC that could successfully build the code! We got them to send us a snapshot of the PC’s OS and memory configuration, and once all of that was replicated, the build “worked” (the compiles finished, but there was no binary comparison of the final result as the “pass” indication, so it was still suspect).
The only thing that might work is if one created a static “virtual machine” (in the Donald Knuth sense – MMIX is his latest generation) then never deviate from its use. Port the virtual machine to any architecture and reproduce your production build to validate it. Crazy? Maybe, but it should work close to 100% of the time (assuming EVERYTHING is bug free!). We come close to this with a some of the most rigorous levels of the numerous software safety standards out there. We need this for critical mission work (avionics, automotive, space, nuclear power, etc.), but the most extreme safety versions are too “expensive” for everyday use. So, we implement a decent subset of the effort and it pays off when we really need it.
One more thing: in the past, we were also screwed by an updated CPU. The manufacturer said this was only a process change, but they were wrong. The same code no longer worked with the new CPU. Another issue happened when we used an “enhanced 2nd source” for a CPU that was “guaranteed to work” with our code. It didn’t, but since it had better performance, lower cost, and the original was no longer available, we “fixed” our code.
All in a days work.
Thanks for expanding on the topic, that was a great read. I assumed that while this is very well known in the industry, we’re on Hackaday, not Enterprise-High-Availability-Aviation-Public-Safety-Nuclear-Plant-Software-a-Day, so I skimmed over the subject.
I know I’m a bit late here (catching up on my feed), but one of my projects, Hedley [1], is relevant here so I wanted to plug it ;). The primary purpose of Hedley is to make it easier to provide compilers with more information, which helps them generate better warnings/errors (and sometimes faster code), while retaining portability.
Basically, instead of a bunch of compiler-specifc tricks to silence (or add) warnings, you can use a macro provided by Hedley. The macros are defined differently depending on the compiler, compiler version, language (C or C++), and language version. For example, `HEDLEY_FALL_THROUGH` may be `[[fallthrough]]` (C++17), `[[clang::fallthrough]]` (clang, tested with `__has_cpp_attribute`), `[[gnu::fallthrough]]` (g++ 7+), `__attribute__((__fallthrough__))` (gcc 7+), `_fallthrough` (MSVC in analysis mode), or nothing at all (for platforms which don’t support anything). And, of course, it’s not just for falling through a switch; there are lots of other macros which are even more useful.
It’s all implemented in a single public domain header which is safe to expose as part of your public API (if you want to). It supports GCC, clang, MSVC, ICC, PGI, suncc, IAR, armcc, IBM XL/C, TI, Cray, TinyCC, Digital Mars, and shouldn’t cause problems in other C/C++ compilers (it falls back on standard C/C++).
Hopefully this post wasn’t too spammy; I think people who liked this article will like Hedley, too, but if you don’t think it’s appropriate and want to delete it I understand :)
[1] https://nemequ.github.io/hedley/