In our first part on pointers, we covered the basics and common pitfalls of pointers in C. If we had to break it down into one sentence, the main principle of pointers is that they are simply data types storing a memory address, and as long as we make sure that we have enough memory allocated at that address, everything is going to be fine.
In this second part, we are going to continue with some more advanced pointer topics, including pointer arithmetic, pointers with another pointer as underlying data type, and the relationship between arrays and pointers. But first, there is one particular pointer we haven’t talked about yet.
The one proverbial exception to the rule that pointers are just memory addresses is the most (in)famous pointer of all: the NULL pointer. Commonly defined as preprocessor macro (void *) 0, we can assign NULL like any other pointer.
// regular referencing, ptr1 points to address of value int *ptr1 = &value; // regular pointer, ptr2 points to address of value as well int *ptr2 = ptr1; // uninitialized pointer, ptr3 points to unknown location int *ptr3; // NULL pointer, ptr4 points to (void *) 0 int *ptr4 = NULL;
While it looks like NULL is just pointing to address zero, in reality, it is a special indicator to the compiler that the pointer isn’t pointing to any valid data, but is quite literally pointing to nothing. Dereferencing such a pointer will most certainly fail, but it will fail predictably. If we kept the pointer uninitialized, anything could happen when we dereference it, with a segmentation fault being one of the better outcomes.
It is always good practice to initialize otherwise uninitialized pointers with NULLto let the compiler know, but it helps us too. Checking if (ptr != NULL) lets us easily determine whether a pointer has a valid value yet or not. And since any value other than 0 is evaluated as true in C, we can write it even shorter as if (ptr).
Pointer Arithmetic
Other than NULL, the concept remains that pointers are simply memory addresses — in other words: numbers. And like any other number, we can perform some basic arithmetic operations with them. But we wouldn’t talk about it if there wasn’t more to it, so let’s see for ourselves what happens when we add 1 to a couple of different pointer types.
char *cptr = (char *) 0x1000;
int *iptr = (int *) 0x2000;
struct foo *sptr = (struct foo *) 0x3000;
printf("char 0x%02lx %p %p\n", sizeof(char), cptr, (cptr + 1));
printf("int 0x%02lx %p %p\n", sizeof(int), iptr, (iptr + 1));
printf("struct 0x%02lx %p %p\n", sizeof(struct foo), sptr, (sptr + 1));
We have three different pointer types, and we print each type’s size as a hexadecimal number, its pointer variable’s current address, and the pointer variable’s address incremented by one:
char 0x01 0x1000 0x1001 int 0x04 0x2000 0x2004 struct 0x10 0x3000 0x3010
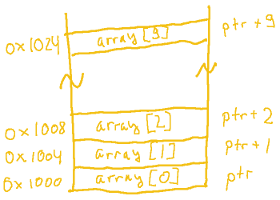 Unlike regular numbers, adding
Unlike regular numbers, adding 1 to a pointer will increment its value (a memory address) by the size of its underlying data type. To simplify the logic behind this, think of pointer arithmetic the same way you think about array indexing. If we declare an array of ten integers int numbers[10], we have a variable that has reserved enough memory to hold ten int values. With int taking up 4 bytes, numbers is 40 bytes in total, with each entry 4 bytes apart. To access the fifth element, we simply write numbers[4] and don’t need to worry about data type sizes or addresses. With pointer arithmetic, we do the exact same thing, except the array index becomes the integer we add to the pointer, (numbers + 4).
Apart from adding integer to a pointer, we can also subtract them, and as long as they’re the same type, we can subtract a pointer from another pointer. In the latter case, the result will be the number of elements of the pointer’s underlying data type that fully fit in the memory area between the two pointers.
int *iptr1 = 0x1000;
int *iptr2 = 0x1008;
printf("%ld\n", (iptr2 - iptr1));
printf("%ld\n", sizeof(iptr2 - iptr1));
Since an int was four bytes, we can fully fit two of them in the 8 bytes offset, therefore the subtraction will output 2. Note that the The result of such a subtraction will be of type sizeof operator is one exception that doesn’t follow pointer arithmetic rules, but only deals in bytes. As a result, the second output will show the full 8 bytes of the offset.ptrdiff_t, a platform dependent integer type defined in stddef.h. The sizeof operator will output its size accordingly, for example 8 bytes.
That’s pretty much all there is to know about the basics of pointer arithmetic. Trying anything other than addition with an integer, or subtraction with either an integer or another pointer of the same type will result in a compiler error.
Pointer Cast and Arithmetic
The beauty of pointers is that we can cast them to any other pointer type, and if we do so during an arithmetic operation, we add plenty of flexibility in comparison to array indexing. Let’s see how the rules apply if we cast an int * to a char * and add 3 to it.
int value = 123;
int *iptr = &value;
char *cptr1 = (char *) (iptr + 3);
char *cptr2 = (char *) iptr + 3;
printf("iptr %p\ncptr1 %p\ncptr2 %p\n", iptr, cptr1, cptr2);
For simplicity, let’s pretend value is located at address 0x1000, so we will get the following output:
iptr 0x1000 cptr1 0x100c cptr2 0x1003
We can see a clear difference between those two additions, which is caused by C’s operator precedence. When we assign cptr1, iptr is still an int * at the time of the addition, resulting in an address offset to fit three ints, i.e. 12 bytes. But when we assign cptr2, we don’t use parentheses, and the operator precedence leads to a higher priority for the cast operation. By the time the addition is performed, iptr is already a char *, resulting in a three byte offset.
Keep in mind that we don’t have any allocated memory beyond value‘s size, so we shouldn’t dereference cptr1. Dereferencing cptr2 on the other hand will be fine, and will essentially extract the fourth byte of value. If for some reason you wanted to extract whatever resides 11 bytes into a struct array’s third element and turn it into a float, *((float *) ((char *) (struct_array + 2) + 11)) will get you there.
Incrementing While Dereferencing
Another typical thing we do with pointers is dereference them. But what happens if we increment and dereference a pointer in the same expression? Once again, it’s mostly a question of operator precedence and how generous we are with parentheses. Taking both prefix and postfix increment into account, we end up with four different options:
char buf[MUCH_BYTES]; char *ptr = buf; // increment ptr and dereference its (now incremented) value char c1 = *++ptr; // ptr = ptr + 1; c1 = *ptr; // dereference ptr and increment the dereferenced value char c2 = ++*ptr; // *ptr = *ptr + 1; c2 = *ptr; // dereference current ptr value and increment ptr afterwards char c3 = *ptr++; // c3 = *ptr; ptr = ptr + 1; // dereference current ptr value and increment the dereferences value - now we need parentheses char c4 = (*ptr)++; // c4 = *ptr; *ptr = *ptr + 1;
If you’re not fully sure about the operator precedence, or don’t want to wonder about it every time you read your code, you can always add parentheses and avoid ambiguity — or enforce the execution order as we did in the fourth line. If you want to sneak subtle bugs into a codebase, leaving out the parentheses and testing the reader’s attention to operator precedence is a good bet.
A common use case for incrementing while dereferencing is iterating over a “string”. C doesn’t really know the concept of an actual string data type, but works around it by using a null-terminated char array as alternative. Null-terminated means that the array’s last element is one additional NUL character to indicate the end of the string. NUL, not to be confused with the NULL pointer, is simply ASCII character 0x00 or '\0'. As a consequence, a string of length n requires an array of size n + 1 bytes.
So if we looked through a string and find the NUL, we know we reached its end. And since C evaluates any value that’s 0 as false, we can implement a function that returns the length of a given string with a simple loop:
int strlen(char *string) {
int count = 0;
while (*string++) {
count++;
}
return count;
}
With every loop iteration, we dereference string‘s current memory location to check if its value is NUL, and increment string itself afterwards, i.e. move the pointer to the next char‘s address. For as long as dereferencing yields a character with a value other than zero, we increment count and return it at the end.
As a side note, the string manipulation happens and stays inside that function. C always uses call by value when passing parameters to a function, so calling strlen(ptr) will create a copy of ptr when passing it to the function. The address it references is therefore still the same, but the original pointer remains unchanged.
Pointers and Arrays
Coming back to arrays, we’ve seen earlier how pointer arithmetic and array indexing are closely related and how buf[n] is identical to *(buf + n). The reason that both expressions are identical is that in C, an array decays internally into a pointer to its first element, &array[0]. So whenever we pass an array to a function, we really just pass a pointer of the array’s type, which means the following two function declarations will be identical:
void func1(char buf[]); void func2(char *buf);
However, once an array decays into a pointer, its size information is gone. Calling sizeof(buf) inside either of those two functions will return the size of a char * and not the array size. A common solution is to pass the array size as additional parameter to the function, or have a dedicated delimiter specified like char[] strings.
Multi-dimensional Arrays and Pointers
Note that the array-to-pointer decay happens only once to the outermost dimension of the array. char buf[] decays to char *buf, and char buf[][] decays to char *buf[], but not char **buf. However, if we have an array to pointers declared in the first place, char *buf[], then it will decay into char **buf. As example, we can declare C’s main() function with either char *argv[] or char **argv parameter, there is no difference and it’s mainly a matter of taste which one to choose.
Note that all this applies only to already declared arrays. Once an array is declared, pointers give us an alternative way to access them, but we cannot replace the array declaration itself with a simple pointer because the array declaration also reserves memory.
Pointers to Pointers
As we have well established, pointers can point to any kind of data type, which includes other pointer types. When we declare char **ptr, we declare nothing but a pointer whose underlying data type is just another pointer, instead of a regular data type. As a result, dereferencing such a double pointer will give us a char * value, and dereferencing it twice will get us to the actual char.
The other way around, &ptr gives us the pointer’s address, just like with any other pointer, except the address will be of type char ***, and on and on it goes. As stated earlier, C uses call by value when passing parameters to a function, but adding an extra layer of pointers can be used to simulate call by reference.
Double Pointer Memory Arrangements
Return to main()‘s argv parameter, which we use to retrieve the command line arguments we pass to the executable itself. In memory, those arguments are stored one by one as null-terminated char arrays, along with an additional array of char * values storing the address to each of those char arrays. To illustrate this, let’s print each and every address we can associate with argv.
int main(int argc, char **argv) {
int i;
for (i = 0; i < argc; i++) {
printf("&argv[%d] %p with argv[%d] at %p len %ld '%s'\n",
i, &argv[i], i, argv[i], strlen(argv[i]), argv[i]);
}
// print once more to see what is stored after the arguments -- better not dereference it
printf("&argv[%d] %p with argv[%d] at %p\n", i, &argv[i], i, argv[i]);
return 0;
}
Along with argv, we get argc passed to main(), which tells us the number of entries in argv. And as a reminder about array decay, argv[i] is equal to &argv[i][0].
Simplifying the addresses, the output will look like this:
$ ./argv some arguments &argv[0] 0x1c38 with argv[0] at 0x2461 len 6 './argv' &argv[1] 0x1c40 with argv[1] at 0x2468 len 4 'some' &argv[2] 0x1c48 with argv[2] at 0x246d len 9 'arguments' &argv[3] 0x1c50 with argv[3] at (nil) $
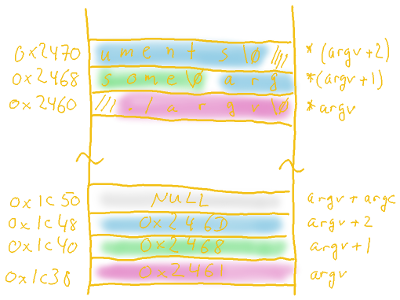 We can see that
We can see that argv itself is located at address 0x1c38, pointing to the argument strings, which are stored one after another starting from address 0x2461. Since incrementing a pointer is always relative to the size of its underlying data type, incrementing argv adds the size of a pointer to the memory offset, here 8 bytes.
Another thing we can see is a NULL pointer at the very end of argv. This follows the same principle as the null-termination of strings, indicating the end of the array. That means we don’t necessarily need the argument counter parameter argc to iterate through the command line arguments, we could also just loop through argv until we find the NULL pointer.
Let’s see how this looks in practice by rewriting our previous example accordingly. To leave argv itself unaffected, we copy it to another char ** variable.
int main(int argc, char **argv) {
int i;
char **ptr = argv;
for (i = 0; *ptr; i++, ptr++) {
printf("&argv[%d] %p with argv[%d] at %p len %ld '%s'\n",
i, ptr, i, *ptr, strlen(*ptr), *ptr);
}
printf("&argv[%d] %p with argv[%d] at %p\n", i, ptr, i, *ptr);
return 0;
}
Whether we access argv via array indexing or pointer arithmetic, the output will be identical.
To Be Continued
To summarize our second part on pointers in C: pointer arithmetic happens always relative to the underlying data type, operator precedence needs to be considered or tackled with parentheses, and pointers can point to other pointers and other pointers as deep as we want.
In the next and final part, we are going to have a look at possibly the most exciting and most confusing of pointers: the function pointer.














Wonder if the comment section is going to be as lively as last time?
Let’s start :)
regarding NULL: “it is a special indicator to the compiler”
There is nothing more wrong than this.
The compiler makes no assumption that NULL (ie address 0) has any special meaning
It is only a coder’s convention rule to use NULL to represent an invalid address.
And it is up to the coder to EXPLICITELY test that a pointer has the NULL (or not) to determine in his coding if the pointer’s value is correct.
int *ptr = malloc(100);
if ( ptr != NULL )
// I can use ptr
else
// I can’t use ptr
No compiler will prevent to dereference a NULL pointer.
There are even systems where address location 0 is a valid address where you may want to read/write.
Another wrong one:
// dereference ptr and increment the dereferenced value
char c2 = ++*ptr; // *ptr = *ptr + 1; c2 = *ptr;
the text is partially exact but not the equivalent code. It should be:
char c2 = ++*ptr; // char temp=*ptr ; ++temp ; *ptr = temp ; c2 = temp;
As the ++ applies to (*ptr) it also increments the value pointed before assigning the value to c2
char c2 = ++*ptr; // char temp=*ptr ; ++temp ; *ptr = temp ; c2 = temp;
could also be written:
char c2 = ++*ptr; // *ptr = *ptr + 1 ; c2 = *ptr;
A good rules : A good C coder is NOT the the one who knows operator precedence by heart. He’s the one which makes his code highly maintainable by somoelse, assuming the other doesn’t know the operator predecedence by heart.
USE PARENTHESIS.
Writing crypting code line doesn’t makes sense. compiler’s optimiser are (most-)always better than you are. Use your high priced time to make code maintainable.
Agreed. Nicely structured and clear C code is much easier to grasp.
Will you marry me? :-)
Not just C – any language.
It’s the compiler’s job to make it machine-readable, it’s the programmer’s job to make it human-readable.
If you are coding in C and you don’t know these VERY SIMPLE precedence rules by heart, you shouldn’t be coding in C.
There are basic rules for every language. These simple pointer-operator precedence rules should be readable by EVERY C Coder.
The reason that I would give for so many programmers who leave out notes, and poorly code, fail to provide much evidence of testing, JMP Label: Spaghetti style code (<-this is my offense, I used to go crazy not knowing enough about creating my own data types or return(Other-than NULL), so I’d just JMP Label, and hope it wasn’t ever caught by anyone I wanted to impress), the reason I would cite is…
… JOB SECURITY. How are YOU (my employer) going to let me go, if no one else can read this crap? Or better yet, He w are you going to afford to undo the mess I’ve made, without MY help?
I definitely disagree with the idea you should memorize precedence rules, or be expected to, or make use of such knowledge.
I take it a step farther than many here; not only do I reject the concept of Virtue in remembering the precedence rules, I reject the idea that there is Virtue in believing that I remember them, and then typing out code that relies on that perception of having knowledge. Instead, I try to re-write the code so that I don’t rely on precedence, and if I still think it might be nice to make use of precedence, I consult the chart every time.
C is my main programming language, but not everything in life or in programming is C code. Thinking you remember stuff is a basic logical fallacy; it leads directly to preventable bugs. Usually the bug isn’t because you remembered wrong, but because since you presumed your memory to mean you got it right, you then wrote an excessively complex construction where it is easy to slip and write it out wrong. And then you don’t blame yourself for the bug, or see what caused it.
In other languages there might be better arguments for writing the code in a particular way, such as efficiency, but in C you would never really get that sort of advantage because the compiler re-wrote your code the same way if you used a lot of parens, or if you used none; or in many cases, if you wrote it out as 10 clear lines, or 1 big monster of a line! In Perl maybe the one-liner had some advantage that the expert can attest to, but in C that is unlikely.
And when people use memorization of precedence to save keystrokes, they usually could have saved more by using a preprocessor macro instead, and increased clarity at the same time. Then, I can consult the precedence chart when writing the macro, and not having memorized it then has O(1) cost. And as they taught me in school, O(1) ~ 0.
I also like to keep the .h files that I’m using open, to make frequent reference to the API. Saves so much time compared to writing macho “of course I remember, I’m a pro-fe-shun-ul” style bugs.
Beware ! NULL is 0, which is the null pointer constant, but the null pointer isn’t necessarily 0.
As you said, in some systems, address 0 will be valid, and the null pointer will not be 0, since the null pointer should not be equal to a valid pointer.
See http://c-faq.com/null/varieties.html
The language definition says that but I never seen any system/compiler where NULL is not of value 0
Whatever the hardware platform, I can’t remember any where a value could represent an invalid memory address.
However this doesn’t change the point that it is a coder’s convention and nothing that the compiler may detect or take advantage of. C is not C#
Even if you write :
int *ptr = NULL;
int c = *ptr;
I don’t see any comipler will catch this as an eror. Some may issue a warning.
Lint should catch it I believe (but that’s a long time I’ve not use Lint)
The C standard requires that the C-language visible representation of the null pointer is 0. The hardware implementation can have some other encoding, but your code is always allowed to compare with 0.
Uh, yeah and this is a C article.
Which is where the first bit of knowledge in this article already goes wrong. NULL is not (void*)0. It’s 0. nullptr (in the newer standard) is a proper pointer. This is especially tricky in C++ with function overloading: NULL is a relic of the past, and should die.
void f(void* a);
void f(bool a);
f(NULL); //the bool variant will be called! As a bool is a type of integer, and NULL is 0, also an integer. And thus may be implicitly casted by the compiler.
Not really… In the definition of glib it is #define NULL (void *)0. I know it because this summer I worked in a C analyzer and found that detail.
But yes, at the end it is zero.
https://developer.gnome.org/glib/stable/glib-Standard-Macros.html#NULL:CAPS
Nope.
Ok, NULL is 0L or ((void*)0L) depending on where you find it. Even worse. Pretty sure it can be non-pointer on Windows in C++.
This is a C vs C++ difference. NULL is defined differently between the two languages.
Well, that partially true, depending on context. Back in the 90’s, the old MIcrosoft C compiler had a post mortem check to see if data at address zero was corrupted during execution, if you set the right compiler/linker switches (I’m not sure about now). It even could generate “some” code check for stack crashes and “maybe” even to validate a pointer as not being null. Ada did that from its inception, but that can really slow down code, so it’s generally disabled “after testing” for production code. (My bad if this already came up — just too much to read.)
From http://blog.llvm.org/2011/05/what-every-c-programmer-should-know.htm
“Dereferencing a NULL Pointer: contrary to popular belief, dereferencing a null pointer in C is undefined”
Since it is undefined, your compiler is free to optimize it away (or do anything it likes, really).
Let’s try–
If you think that the pointer construct is supported by any assembly language, you don’t truly understand the basic concept of assembly language, or assembly-language programming.
I’m just glad that very very little of this is ever done in my own C code :) I also really liked the casual explanation of pointer arithmetic and casting, with no warnings or comment about if it is something to learn because people want you to know how to do it, or something to learn because you’re supposed to understand how horrible it is, and that the compiler won’t protect you from yourself.
>int *iptr1 = 0x1000;
>int *iptr2 = 0x1008;
>printf(“%ld\n”, (iptr2 – iptr1));
>printf(“%ld\n”, sizeof(iptr2 – iptr1));
>
>Since an int was four bytes, we can fully fit two of them in the 8 bytes offset, therefore the subtraction will output 2. Note that the sizeof operator is one exception that doesn’t follow pointer arithmetic rules, but only deals in bytes. As a result, the second output will show the full 8 bytes of the offset.
It’s not 8 bytes of the offset! It is 8 bytes which are taken by the type of the result of pointer subtraction (most probably size_t)
The type of (iptr2 – iptr1) is an int. So sizeof(iptr2 – iptr1) should be equal to sizeof(int).
Are we saying the same thing ?
I am saying that it will sizeof((int *)0x1008 – (int *)0x1000)) is 8, but sizeof((int *)0x1001 – (int *)0x1000)) is 8 as well. 8 here is not “the full 8 bytes of the offset” as the author says, but the sizeof(ptrdiff_t).
Phil is correct. “sizeof” is a constant operator that takes a single operand and is evaluated at compile time. The compiler determines the type of the operand, in this case “ptrdiff_t” (the difference of two pointers) and determines the size of a value of that type, which is 4 on machines with 32 bit addresses, 8 on machines with 64 bit addresses, and 2 on machines with 16 bit addresses. Sometimes sizeof(int) == sizeof(size_t) == sizeof(ptrdiff_t), but not always.
It should be noted that any expression used as the operand of “sizeof” is not evaluated at runtime, so something like “uint64_t* ptr3 = NULL; printf(“sizeof(uint32_t) = %u\n”, (unsigned int)sizeof *ptr3);” will print 4 on any CPU (64 or 32 bit); it doesn’t matter that ‘ptr3’ is NULL, since it is not accessed in that “printf()” statement. The compiler replaced the expression “sizeof *ptr3” with a constant value that, due to the typecast, will be an unsigned integer with the value 4.
You are right. I used the worst possible example to verify my false assumption. It’s corrected now, thanks for pointing it out.
Sorry to say that, but your edit did no good:
>Subtracting two pointers will result in another pointer of the same type, so the sizeof operation will print the size of a regular pointer, 8 bytes in this case.
This is totally untrue. Subtracting two pointers will result in a value of type ptrdiff_t which is an integer type with size dependent on the platform, 8 bytes in this case.
Well, it is safe to say that at least one person learned something from this article. You are right once more and I adjusted my initial correction. Thanks again, and sorry about that.
As suggested above, on my system, my complier has 64 bit pointers but size_t and ptrdiff_t are 32 bits. So when two 64 bit pointers are subtracted, the complier will use a 32 bit subtract instruction. All legal programs can only be subtracting pointers which point into the same variable. Since such a variable cannot be larger than 32 bits in size, the difference must also fit into 32 bits.
Of course in reality, some user comes along and writes illegal code and assumes a 64 bit result. We’ve even added a message to the compiler but that often just confuses more people.
Are there really people who have this much trouble with C? At 32, I’m not *that* old, am I? What are universities teaching students these days that such a series is actually necessary?
OK, well I am about double your age, so fly right and listen up.
I’ll tell you what the CS department at the university here is/was teaching. It used to be Pascal, but now it is Java. There you are since you asked (this is the University of Arizona in Tucson). There is a course much later, perhaps for graduate students that tries to teach them C. I am told that many students have big problems with it.
Learning a second language is always hard, because you think every language should be like the first you learned. The third, fourth, ninth, etc. are much easier.
One of the local community colleges required the students learn Pascal, then C, then C++ then Java as the 101 course (they kept moving the graduation requirements and part time students would get burnt). Left for a proper University …
I’ve never had problems with most computer languages. But I started with BASIC and then learned assembly. C seemed like a gift after that. Then came then came the rest of the languages. The only difficult thing with multiple languges is recalling which syntax or format you’re using. BASH, C, Python and Javascript are the languages I use most now. But I expect to get back to Java soon. I’m always working in assembler when I really get deep into debugging.
Yes, there are people, professional software engineers, that fail to grasp this basic stuff. I’m your age. I learned myself C and later C++. I got C during my bachelor’s degree, but the classes where bad at teaching anything. So at least half my class didn’t actually grasp C concepts, but where good enough to pass the tests without actually understanding anything.
Now I work in a team of ~10 engineers, and about half of them can do C/C++ on a workable level. The rest isn’t even allowed to touch that code anymore, as they fail to grasp memory management and pointers. That’s the sad reality of these days. Of the 40 software engineers that we have, only about 5 really have a perfect understanding of C/C++, and I would call experts. And then we have done some very careful selection to get those guys.
A lot of programmers who have worked 10 years have 1 year of experience 10 times.
In the 98/99 school year I was taking first year programming at a community college and it was the last year that they taught it using C/C++; the next year all the same classes were Java, and the only C class was a 300-level Operating Systems class where you wrote your own simple OS.
They did that because the local University had already switched to Java a couple years earlier, and most of the programming students were intending to transfer.
So yeah, I would expect all University-trained programmers, at least in the US, to know little to no C at all, unless they learned it outside of school. The only people graduating Universities who I would expect to know C would be people with EE degrees. :)
I’ve always regarded pointer arithmetic more as an unfortunate consequence of C’s design, rather than as an important development tool. That is to say, I’ve never encountered a problem where the only tenable solution was to do something clever with pointer arithmetic. Simply using array operations on the pointer, with some explicit control logic, is in my experience just as good, and I’m willing to trade a few LOC in source to not have to puzzle out what I was thinking six months later.
I agree.
Compilers/optimizers have been intelligent enough for years now to make readable code as much efficient as cryptic code.
But that’s still something that stay in the C coding community…
I’ve worked with a number of 8-bit embedded systems and their C compilers where using clearer expressions (e.g. arrays) produced worse binary code, and using stupid pointer tricks compiled to the fastest implementations that you would have written were you programming in asm in the first place.
Same as mjacobs. If you don’t know what the compiler is doing, you really need to read up before using it. Also, checkout godbolt.org.
I strongly disagree. All array subscription operations in C get decomposed to pointer arithmetic anyhow; and when dealing with either multi-dimensional arrays or arrays of structs, where you want to access an individual member *that is only specifically known at run-time*, pointer arithmetic is way more intuitive. You can always cast your memory access to a char pointer and have it raw, using offsets. Pointer arithmetic is, IMHO, one of the greatest strengths of C pointers. Take that away, and you end up (almost) with reference types, which, while having some advantages, are way less powerful than raw pointers.
0 is evaluated as false, not true. you might want to fix that.
While we’re on the subject of pointers, what’s your preferred style:
int *p;
or
int* p;
I’ve always been fond of the second one, with the asterisk next to the datatype. The asterisk denotes that this variable is a pointer, after all, which is type information, and should thus be associated with the datatype.
It should always go with the variable, because:
int *p, *g;
is two pointers
int* p, g
is a pointer and an integer.
Just about every codebase I’ve worked on has had policies discouraging the declaration of multiple variables per statement. Honestly, it’s kind of weird that the C spec allows it. As a general rule, C doesn’t go far out of its way for syntactic sugar. That’s one of my favorite things about it.
Where do stupid policies like that come from? I was reading recently that some organization (maybe Facebook) enforces a javascript style where you write if ( false == x ) rather than if ( x == false). There is a reason of sorts for this, but ultimately these kinds of rules are just stupid. But if we are talking about style rules, go read the Torvalds coding style guidelines for the linux kernel. I agree with the bulk of it. And contrast the coding rules for the Gnu project. As Torvalds says in his writeup, everyone should print a copy, read it, then burn it. Or something of the sort.
Forget all the nitpicky detail rules. Just strive for clarity — and whatever you do don’t invent some offbeat style, read enough good code that you can adopt the style used by the masters.
> Where do stupid policies like that come from?
MISRA?
A lot of companies encourage (false == x). Or (7 == i).
I understand it because:
a) it’s strange to see it that way so you pay more attention to the expected value
b) you can’t make mistakes of forgetting the second ‘=’ (eg. to do this “if (false = x )”)
Is it good? Not really, a good static code checker will warn about it.
As to discouraging the declaration of multiple variables per statement: it doesn’t cost anything, but increases readabilty and lowers the probability of VCS conflicts.
The only reason for such a policy is because people get stung by thinking that the * goes with the type instead of the variable.
In other words, by being tempted to write “int* p” you set yourself and other people up for thinking they could just add a “,q” and get two pointers. But if you attached the * to the variable instead then that confusion is averted.
Yes, I am totally with you on this. Write your statements:
int *p, *q, *r, *another_pointer, *andAnotherOne;
I have no problem with this, and this is what I do. What I was saying was stupid was
a rule to only define one variable per line. That is arbitrary and as I have been saying; stupid.
Of course if you write int* p; then maybe you should add the stupid rule to compliment that style
which does tempt you to think that int* p, q; would give you two pointers.
I disagree. The “*” is part of the type, not the variable name.
People get stung not by thinking the “*” goes with the type, which it does, but by the fact that C allows declaring variables of multiple types with a single statement. I understand why, and know the history well, but that doesn’t change the fact that both “int *t;” and “int* t;” define a variable named “t” with type “pointer to int”.
How you choose to cuddle the asterisk for pointer types is your own affair, and is one of the nearly religious issues that make no real difference to the quality of the code. It’s a style thing; if you are on a project with a coding standard that requires a particular style for pointer declarations, you follow that, otherwise, follow your heart.
On the other hand, people who insist on cuddling “if” with the open paren and putting extra space inside the parens, as in “if( expression )” should be shunned. For some crazy reason, a lot of the younger programmers I work with persist in that practice along with putting spaces between function names and the open paren, so code ends up looking like:
“`”if( argc == 5 ) { strcpy ( buffer, argv[4] ); }”“`
The latest version of Visual Studio insists on “int * i”, which is like the worst of both worlds…
One of my philosophies for evaluating opinions on this stuff; the people blaming the C language are always wrong, and the people blaming the programmer are often right; but sometimes they blamed the programmer for the wrong thing.
Clearly if I’m using the C language, then the C language is Just and Wise. And I know that C doesn’t try to protect the programmer from themselves. So if it compiles to the same code, but there is a difference is the likelihood of mistakes, then that is an easy decision.
Strict rules may be bad, but that includes strict rules against strict rules! C is a lot like English; the language allows you to do almost anything, and very little of what people consider harmful is actually a literal “mistake;” instead, people adopt various style guides to try to keep themselves in line. There is a lot of value in knowing what style guide you’re using, and following it, and that remains true even when you remember that it is a “style guide” not a “rule book.” And obviously, at work you write the code using the style that the BOFH declared Virtuous, rather than trying to analyze what a good style would be.
Yep. And any code that does int * p; is to regarded with great suspicion as it indicates the programmer really didn’t understand what the * means.
People get stung by the precedence of *. [] and . and () have higher precedence than *.
For example, *p.f is the same as *(p.f) as opposed to *(p).f
Also, int *q[] is int *(q[]) as opposed to int (*q)[]
This is from “Expert C Programming” by Peter Van Der Linden which also makes a deep dive into the differences between pointers and arrays at the nuts and bolts level. The author wrote the very readable book while employed at SUN Microsystems to work on compilers.
That’s what -> is for.
Nobody uses the second style you have adopted, so you should dump it and get with the program.
No, I’ve definitely seen code in both. The majority of people do seem to use int *p; but it doesn’t seem to be overwhelming. Textbooks, in particular, seem to be an even split. I’ve even seen some code that uses the cursed style:
int * p;
I, and a lot of fellow programmers use it. A pointer is part of the type IMHO. You can make it part of a typedef, so it’s clearly part of a type. It’s just some strange syntax rules that make it sort of part of a type. Multiple variables defined on 1 line is pretty much a no-go except for simple primatives.
Else you get this shit: https://github.com/Davidslv/rogue/blob/master/rogue.h#L470
That code is an extreme example, but I have no problem with it. Clean and readable. You could argue that it reads better than having a thousand “int” declarations one per line.
I’d have preferred not to have chars, pointers to chars, arrays of chars, and pointers to arrays of chars all mixed up in the same declaration.
I would consider agreeing, except that they took the time to alphabetize the list and it is presumably the most stable of the declarations and won’t change. Notice that at the end of the file are a bunch of one-line declarations of various types that appears to be how less-stable declarations are being written.
I deal with some really awful legacy code, and I’d be quite pleased to be working on code like in that link. Not all written the way I’d do it, but it doesn’t even disgust me. And disgust is a mild emotion for most of the code that makes it my way!
“Dereferencing such a [NULL] pointer will most certainly fail, but it will fail predictably.”
Except it won’t. Especially on most microcontrollers, it will just happily read memory at address 0, which on e.g. all ARM Cortex-M processors is a valid address and contains the vector table. Which in turn has a bunch of valid memory addresses so accidental NULL dereferences can go a long way before triggering a hardfault.
This was a nice accidental feature with the Beaglebone Black. No memory at address zero, so dereferencing null pointers would always yield a processor exception. But with many memory layouts (or MMU configurations) the processor will quite happily fetch or store to address zero for you.
AIX has the 0 page mapped and readable so you can always read from NULL (but never wrote).
This issue is on any “Real Mode” processors.
I just want to lift my hat and cheer at a series that promotes C language programming. I use many other languages for many different things, but for down and dirty hardware hacking, C is the language of choice.
C is PDP-11 assembler with macros
today’s computers are far more advanced than PDP-11 but even today our “smartest” developers (see above) can’t even figure out what a pointer is.
C is a truly miserable language for practical development because it is literally impossible for humans to write a C program that is not chock-full of bugs. The proof is in the pudding. Even trivial program like beep are infested with grave security bugs that languish for decades before any of those “many eyes” ever bothers to look.
If you believe that it is impossible to write a non-trivial C program that isn’t “chock-full of bugs”, I recommend never getting on a commercial aircraft, driving a modern car, or doing anything remotely safety related that has any sort of automation attached to it.
I write provably correct code. I do it in C. I know what I’m doing, and have been doing it for many many years. There is no language that guarantees bug-free code; that is the responsibility of the engineers who design, write, and test the code. Assuming the compiler and the rest of the toolchain is stable and trusted, it is quite possible to write very solid, bug-free, secure and robust code in just about any language.
There are a lot of people who never learned to program in C, even though they program in C++ all the time. A lot of the new-hires I’ve mentored have had limited to no experience with pointers because the Java based courses they took in college did not teach them anything about them, and then when they got some stuff in C++, templates and “smart pointers” hid the details. Pointers are good, powerful, and whether you like them or not, used extensively in every object oriented language, even those that hide them from you. I believe that this “pointers are too hard so let us pretend they don’t exist, or if they do, they’re always harmful and dangerous” attitude is short-changing the students and creating problems for the software industry. If you don’t teach how to use pointers, they won’t get used correctly.
Floridn, What? Maybe for some people…
You’re at least the second person to insist that I’m Nietzsche’s Uberman, but I’m not really convinced.
It just seems so much more likely that you wrote the word “humans” instead of “me.” Or that you have an impossibly-small value of “chock-full,” perhaps even so small as to be equal to the mean of bugs in software generally.
The proof indeed is in the pudding, but most of the pudding was in fact written in C. Even programs that claim to be written in other languages often have the majority of their actual functionality handled by C libraries, or even by parts of the operating system written in C.
I doubt a program that generates a beep is going to be trivial! The only trivial cases I can think of are where you used a library that actually did it for you, in which case you only wrote an beep interface, or if it is a microcontroller generating a beep using a PWM peripheral. But in that case, it is probably a lot more trivial in C than in other languages, unless you used a library. I mean, what does it even mean to beep?! It isn’t math, so how do I know if it would be easy for a computer?
First off, please change the word “integral” to integer — integrals are part of calculus, and I’ve never seen it used to also mean an integeger.
Second, if you really want to see pointers-to-pointers in use, take a look at the Macintosh API — at least the early versions. Pointers to pointers were called “Handles” and allowed their memory management routines to move things around in not-quite-virtual memory without losing track of them: the first dereference was to the memory map, the second to the current location of the block of memory. I’m not sure if they still work this way with true VM — I haven’t programmed on a Mac since the early 90s.
For a more modern and relevant example of how to effectively use pointers to pointers on modern hardware, check out the OpenSSL API
Fixed. Thanks.
All of this “discussion” makes me wonder if it is worth the bother to learn C.
Don’t let the nit picking discourage you. The payoff is huge. People here like to bicker and squabble.
Every language has things you can bicker and squabble over. Imagine if this discussion was javascript?
(I find javascript to be a fine language by the way, but boy do people get worked up over things that
never matter to me).
Not as much as Java. You’d think they’d been touched inappropriately, or something.
Ha ha — Well, if it wasn’t for Android making it the only game in town I would never use Java.
As a well seasoned software engineer, who as done a lot of C, C++ but also loads of Python.
It depends. What do you want to make/do? Doing anything is C/C++ is generally 3 to 10 times harder then in a protected language. However, it also makes things possible that are otherwise slow/impossible to do. Like direct hardware access, tiny code sizes and high performance code. Don’t need any of those? Use something else.
FORTH. :-D
Every few years I entertain thoughts of screwing around with forth. Whenever these strange urges come along, I visit with my old pal Alan, who has done a lot of Forth programming in his career and get him going down memory lane. This always cures me. Just remembering that everthing is RPN is usually enough to clear my mind.
Try Win32Forth. The OOP model is pretty cool and just reading the tutorials is enlightening. https://sourceforge.net/projects/win32forth/files/
You are on the money here. C is the language to use when you are writing bare metal code, device drivers, things that need to talk to the hardware. If I have unix running and ruby or python at my fingertips, there are few things I would ever do in C. It is all about picking the right tool for the job. If just having fun and challenging yourself is your goal, go with Haskell.
C and C++ are different languages. Sure, you can write C in C++ if you want to, but you could also use the modern high-level language features.
Yes it is, there are still places where C is the best choice. Lots of microntrollers use it and it’s a nice step up from assembly language. I still use it with some of my application development when I want speed. I’m not overly thrilled with C++ but I also haven’t kept up with it.
C++ works great for writing microcontroller code too, even for 8 bit devices with only a few dozen kb of program + data memory. Most of the usual objections in the vein of “you can’t have dynamic allocation” “OOP intrinsically bloats compiled code size” “virtual calls are slow” “C++ object code is slow” etc. are old wives tales that may have been true with respect to the microcontrollers available in the 1980s and 90s but not so applicable to modern devices and recent compilers
It all depends on how you write the code. What language are embedded RTOS written in?
C
It really is true; C++ works great on microcontrollers! As long as you only use features that are cosmetically different, and don’t use anything substantive, you’ll even get the same code size! And as an added benefit, anybody else that wants to reuse your code would have to port it back to plain C, so you won’t get pestered with a bunch of email questions or pull requests.
I saw this article and was expecting some pointers about learning C. Guess I was wrong– seems all the pointers are going everywhichway.. I just want to point my finger at something and say, “It’s mine!”
In that case I highly recommend getting a boxed set of The Art of Computer Programming series, because you can point right at it, and say, “it’s mine!” and many people will be impressed, not only by the size of the volumes, but by the author’s name, and the obvious gravitas of the binding.
And theoretically it would benefit the process of learning C, if you were read it.
typo in this one in the box in the article
“char c3 = *ptr++; // c3 = *ptr; ptr + ptr + 1;”
I’m sure they meant to put an equals sign in it..
I’ve been using C since the day it came out (on the PDP-11..). It was a vast improvement of fortran IV, and was still much better than fortran 77 when it came out..
I’m still using it in embedded programming today – and I have the opposite to some of the views above as I find it’s easy to write very quickly and have work first time! :-)
However, on the PC etc I’ve gone to C++ a few decades ago, as it really is a great leap forward.
The other languages are still not that useful from my point of view apart – from small simple applications, or something specific ie php is great for web sites and scripting, ruby has uses as well. etc etc The main thing I HATE about people writing ‘production’ systems in some other languages (ie java) is that you pretty need one machine for each application, and sometimes even that isn’t enough…
I learned C on the PDP-11 as well, but at that point I was already considered an expert at PDP-11 Macro-Aassembly, and had been using BLISS-11 (later “BLISS-16”) for a while. For the first 10 years or so of my C programming career, I still thought in PDP-11 assembler when writing C. I worked for a company developing a C compiler and tools in the later 1980s (Mark Williams Co.) for the Atari-ST (M68000).
Java was originally intended for set-top boxes and similar things where apps would be loaded in a protected sandbox defined by a byte code interpreter that always checked its pointers before accessing them and used descriptors with reference counts so that it could perform garbage collection. The sandbox prevented bugs from affecting the main function of the thing it is running on, and to make sure the interpreter had full control of the objects, pointers were hidden from the language at the source level. Java is fine for some things, but I think it’s being used places it isn’t really suited for. Originally, the goal for Java was “write once, run everywhere”; this never really panned out. Now there are lots of programmers who never learned anything else except maybe Python or Ruby, and those programmers may be quite competent, but they are limited in their understanding of the underlying structure of the data they work with and are generally unaware of the efficiency, or lack thereof, of the data either at rest or in flight. More and more I’m faced with having to somehow shoehorn CORBA IDL generated datagrams, with their alignment padding and endian-flexibility, with safety critical functions that have fixed endianess and different, unpadded or minimally padded field alignment. Embedded real-time systems are not the place for Java, though having a Java interpreter in a non-critical partition is ok at times.
C does have some problems, but they’re not disqualifying. My biggest gripe about the language is the preprocessor; the macro facility is not very powerful compared to what’s available in most macro-assemblers – multi-line function like macros that are able to analyse and even decompose their arguments and construct code based on them. This is what I was used to in Macro-11 and Bliss. C’s “#define” is not sophisticated at all, even with __VA_ARGS__; but I still love the language and use it most of the time.
That was indeed a typo and supposed to be an equals sign. Fixed now, thanks.
Advanced C Programming De Anza College Cupertino, CA. Pointer challenges galore so that all you C is memory.
I appreciate this series of posts, not because I’m learning new things about C pointers, which I’m not (see my other replies), but because it’s good to see both C advocacy and a desire to take the mystery out of pointers. All too many articles and posts I see advocate the avoidance of the direct use of pointers. Text books and curriculum that focus on OO languages that hide the pointers such as Java generally avoid covering how to handle pointers and dynamic memory objects directly, which I believe is leading to a bit of bloat. Python is a fine language for some things, but as an interpreted language, also does not encourage understanding the organization of data and code in memory. I think a basic understanding of pointers should be required as part of any computer science curriculum even when it’s not part of day-to-day programming for a large percentage of professional programmers and software engineers.
I have a few suggestions for where you could go with this series…
As you get past the basics of pointers in C, it would be nice to get into examples of problems that are best solved with explicit use of pointers, and contrast the pointer based solutions to how the problem is handled in other languages that don’t provide pointers (or in C++ using templates that hide the use of pointers). Other advanced topics, like how to support poymorphism in C by following some simple rules when defining data structures also involve an understanding of pointers.
Dynamic memory allocation (malloc(), free(), calloc(), realloc()), and the safe ways to use it so that memory leaks and security problems are prevented could be a blog post of its own. The allocation function “alloca()” and the pitfalls inherent in using it, and maybe some guidelines of how and when it can be used safely would be a public service. Personally, I dislike “alloca()” because it makes static stack analysis useless, but I’ve used it on some projects anyway.
C has been in use and under development since the ’70s. It is still the BEST, fastest method for getting closest to the hardware, except for assembly language. The best, most efficient solution is probably a very good optimizing C compiler plus coding in assembly language those modules identified as ‘time-critical’.
“By understanding a machine-oriented language, the programmer will tend to use a much more efficient method; it is much closer to reality.”–Donald Knuth
”Simplicity is a great virtue but it requires hard work to achieve it and education to appreciate it. And to make matters worse: complexity sells better”–Edsger W. Dijkstra
”…We are still trying to undo the damage caused by the early treatment of modularity as a language issue and, sadly, we still try to do it by inventing languages and tools.”
–David L. Parnas
“Originality is no excuse for ignorance.”–Fred Brooks
The best description of C I ever heard was ” machine independent assembly”. If you’ve put in a couple of years of assembly, C is clear, simple and you are greatfull for that.
I only ever heard, “Assembly with semicolons.”
Yours is much more apt; almost 100%–elegantly–correct.
+1 to you.
******************************************************
Any school which is serious about producing competent software engineers and scientists should teach assembly language first, and C next; both taught in-depth, and by experts in the languages. The
survivorsstudents will then be well-equipped to handle ANY language, and to critically evaluate the relative merits of any other language.The problem as it stands now is that even some of most prestigious ‘computer science’ programs, by chasing the latest Language Du jour, are turning out dilettantes who themselves keep chasing, and forever; why not?–that’s the example that’s been set for them.
“…When language designers caught on to the idea [that modularization is a design issue, and not a language issue], they assumed that modules had to be subroutines, or collections of subroutines, and introduced unreasonable restrictions on the design. They also spread the false impression that the important thing was to learn the language; in truth, the important thing is to learn how to design and document. We are still trying to undo the damage caused by the early treatment of modularity as a language issue and, sadly, we still try to do it by inventing languages and tools.” –David L. Parnas
Or at least if not teaching assembly first, then teach BASIC with heavy utilization of PEEK, POKE, and GOTO, since that combination is basically the same as assembly.
“That’s pretty much all there is to know about the basics of pointer arithmetic. Trying anything other than addition with an integer, or subtraction with either an integer or another pointer of the same type will result in a compiler error.”
Meh.
I think if you try it, you’ll find that some other mathematical operations are both allowed (i.e. don’t give compiler errors) and have defined semantics.
You can’t really call yourself a C programmer until you’ve had to multiply a pointer. I had to do it once. (Actually, I had to instruct a programmer how to do it – he was initially very much against such a bizarre concept.)
(Simplified explanation) The hardware had a 32 bit DRAM controller that could operate in two (software-selectable) modes: ECC off, which caused all 32 bits of the memory word to be mapped directly into the CPU’s address space, and ECC on, which caused the 32 bit words of the memory to be split into two 16 bit halves, one of which was mapped into the CPU’s address space, with the other half being used to store data to allow the errors in the first 16 bits to be corrected.
Typically the ECC mode would be selected at the start of boot and left that way forever, but we wanted to test the robustness of the ECC, which meant turning ECC-on, writing a known 16 bit data value to somewhere in memory, switching to ECC-off mode, toggling a bit or two in the 32 bit word (made up of the 16 bit data word and its 16 bit ECC info), then switching back to ECC-on mode, and reading the 16 bit value to compare against its original value.
The CPU address (as opposed to the location in the actual DRAM) of our data word changed as we toggled the ECC mode; with ECC-off, the CPU address was twice what it was with ECC-on. Hence, the need to multiply a pointer in our test program.
(BTW, the test program ran in a different physical memory with a different memory controller that wasn’t affected by the ECC switch.)
Great????
This blog has questionable quality. I spot 3 cases of undefined behavior, 2 silly ones and 1 serious. In addition various conceptual mistakes.
There is nothing called NULL pointer. C has three related terms: null pointers, null pointer constants and the NULL macro. A null pointer constant is either 0 or (void*)0. Any pointer assigned to a null pointer constant is henceforth a null pointer. NULL is a macro guaranteed to give a null pointer constant.
ptrdiff_t is printed with %td, not %ld. The result of the sizeof operator is type size_t which is printed with %zu not %ld. Both printf examples invoke undefined behavior.
“The beauty of pointers is that we can cast them to any other pointer type” is incorrect. In most cases this results in strict pointer aliasing violations. With a few exceptions: we can always cast to/from void* and we can always cast from pointer-to-type to char*. All other pointer casts are most likely severe but subtle bugs that violate strict aliasing. In addition, care has to be taken about alignment.
*((float *) ((char *) (struct_array + 2) + 11)) looks fishy and is likely a violation of strict aliasing. Don’t teach this to newbies, it is plain dangerous code, especially in the gcc era we live in. At the very least actually mention strict aliasing!
“char buf[][] decays to char *buf[]” is plain wrong, it decays to char(*)buf[], which is an array pointer to incomplete type (and therefore can’t be used). When failing to understand the difference between an array pointer and an array of pointers, you shouldn’t be writing C programming blogs.