In a move guaranteed to send audiophiles recoiling back into their sonically pristine caves, two doctoral students at ETH Zurich have come up with an interesting way to embed information into music. What sounds crazy about this is that they’re hiding data firmly in the audible spectrum from 9.8 kHz to 10 kHz. The question is, does it actually sound crazy? Not to our ears, playback remains surprisingly ok.
You can listen to a clip with and without the data on ETH’s site and see for yourself. As a brief example, here’s twelve seconds of the audio presenting two versions of the same clip. The first riff has no data, and the second riff has the encoded data.
You can probably convince yourself that there’s a difference, but it’s negligible. Even if we use a janky bandpass filter over the 8 kHz -10 kHz range to make the differences stand out, it’s not easy to differentiate what you’re hearing:
After many years of performing live music and dabbling in the recording studio, I’d describe the data-encoded clip as having a tinny feedback or a weird reverb effect. However, you wouldn’t notice this in a track playing on the grocery store’s speaker.
Why Use Audible Frequencies?
Why in the world would you want to use an audible frequency to transmit information? The easy answer is that there are already audible transmitters and receivers everywhere. Specifically, cell phones. According to the researchers, this works better than ultrasonic because cell phone microphones have low sensitivity at high frequencies and attenuate faster than audible frequencies.
By encoding data into the audible range of music, coffee shops could broadcast their WiFi passwords inside their Sia-heavy playlists. (Why is it always Sia?) Cell phones could then detect the password and automatically connect.
Why it Sounds Fine: OFDM and Masking Frequencies


The original paper goes into more detail, but the system doesn’t wreck the music because it uses the music to mask the data. It detects the strongest frequencies in a track, and embeds data around the harmonics of the frequency. This way, the encoded data simply sounds like it’s part of the music.
Of course, it doesn’t just encode data on one frequency. It uses orthogonal frequency-division multiplexing (OFDM). OFDM essentially spreads the transmission out over multiple carrier frequencies to reduce the power of a single frequency. It’s used in technologies like 4G and 802.11a WLAN. OFDM allows a system to push more power in a band while minimizing the amplitude of specific tones.
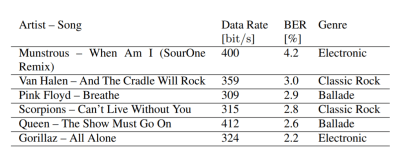 Unsurprisingly, the data rates are far from fiber speeds. Using low frequency carriers has its disadvantages. Researchers were able to reach 300 – 400 bits/s (yes, bits not bytes). The transmission distance and accuracy is respectable, though, at 24 meters with less than a 10% bit error ratio. The BER and data rate varies by song, with Queen and the Gorillaz leading the charge.
Unsurprisingly, the data rates are far from fiber speeds. Using low frequency carriers has its disadvantages. Researchers were able to reach 300 – 400 bits/s (yes, bits not bytes). The transmission distance and accuracy is respectable, though, at 24 meters with less than a 10% bit error ratio. The BER and data rate varies by song, with Queen and the Gorillaz leading the charge.
In the real world they expect about 200 bits/s, which is enough to send roughly 25 words per second. This is fast enough to transmit text info or simple data streams, but you won’t want to browse dank memes with this data link.
Thanks [Qes] for the tip!














So enough bandwidth to continually broadcast a frequently changing Wi-Fi password. Clever. It would provide nearly instant, automatic connections for in-store customers, and also block the upstairs neighbor from leeching off the coffee shop’s network for a month at a time. And the baristas wouldn’t have to constantly point out the sign with the password of the month.
Of course hooking it in to the sound system will take a technician and a thousand dollars, plus the license fees, but hey, capitalism.
Until the neighbour walks downstairs that is.
orr it will just exclude everyone not equipped with the tech.
Or it leaves the door wide open for hijacking tehe connection by merely playing a different audio track
Yesterday an article talks about hte end of passwords and a move to more secure double authenticated methods
This article talks about removal of passwords to make things easier
The Lord giveth and taketh away
No need to play a different audio track.
With just the information broadcast in the audio, an attacker can set up another network with the same password.
Current no common wifi auth technique prevents man-in-the-middle in the ‘coffee shop’ scenario, even if the customer reads a password from an official sign.
It is theoretically possible – if the sign contains the public part of a public-private keypair, then the network can’t be spoofed. I don’t know of any way way of achieving this with existing devices and software though.
Nielsen uses a similar technology in their Portable People Meters to do media audience measurement. They give broadcasters encoder boxes that insert a sub-audible watermark.
Yep! I didn’t dig into it, but I suspect there are some serious issues transmitting and detecting sub-audible frequencies with a standard sound system and a cell phone mic.
Cellphone mics are sensitive enough to map the room you’re sitting in.
Ah it’s similar to digital watermarking. Cinavia DRM embeds information into the audio. In that case it’s designed to survive lossy compression so the bitrate is a paltry 0.2 bits per second. The DRM doesn’t kick in for several minutes because of this. I remember my friend raging over his PS3 stopping playing about 10min into his pirated movies.
Interesting! 0.2 bits/s is rough.
I wonder how difficult would it be to add inaudible or nearly inaudible noise to corrupt it into not working, or conversely, spoof a DRM watermark to false trip the detector. The latter could be interesting to partially “break” audio recordings in public environments.
Wondering how well this would work in a mall setting?
I don’t consider myself an audiophile and I didn’t even have to get my MDR-V6 to hear the difference, my $20 PC speakers are enough, so yeah, it’s noticeable. And they even lowered the volume for the modified clip to help mask it.
Maybe if they encoded it at higher end of the audible spectrum, but then most speakers and mics are not that good near 20kHz too.
Yeah, I don’t know why they say it’s not noticeable. The screeching is not pleasant
The first clip has both the original and the version with data encoded. The audio is 6 seconds long. The second clip has a filter applied.
And can you not notice a difference in the first clip?
I’m not an audiophile, but I am wearing headphones, and I could notice immediate differences. The lower volume and slightly muted tone when the track repeats with data.
– yep, even with my bad laptop speakers, second half of first clip was quite noticeably bad. significantly different, at least to my non-audiophile ears.
So, what would my device do with the sound it hears? Not a darned thing unless before visiting said wifi-hostile establishment I have the foresight to somehow find and install software to decode the bitsream and feed the resulting password to my wifi device, somehow. A different app and binary for iOS, android, macs, ipads, windows, linux, and whatever my portable wifi repeater uses. Assuming my device even has a microphone.
My mom couldn’t do it. And install an app just to get a password via audio? Thanks, I would just go buy my coffee across the street. You know, the place with the free wifi.
Heck, if you’re going to have to install an app to do this, and you have wifi, there are lots of other ways to do this without having to install a pseudonoise generator in your ambient music system. Or maybe the business model is to feed the tagged music over the internet too.
What an awful idea.
How about just program the cash register to print the password-of-the-hour on a receipt? That way the wifi-sucking space-hogging in-potentia revenue stream (i.e., the slacker customers) actually have to buy something once in a while, instead of just hanging out and listening to the music.
Google assistant already listens for music by default. It wouldn’t be a stretch for them to work with businesses to serve content (ads, coupons, reminder to use app/points, identify location better than GPS, etc). Seems totally feasible to me
The way I see it, if a technology like this were to be deployed and used widely, it would end up being a new standard that device makers could choose to implement. A less elegant option would be in the form of an app or smart-assistant feature. You could also potentially embed the tech and license it to folks to use in their apps. For example, the Starbucks app could include it and deploy the tech into their stores.
+1 – There’s enough electromagnetic spectrum noise everywhere already, do we really need to add audio-spectrum garbage noise also? And agreed, if a coffee shop expected me to download an app to get a wifi password, let alone an app that wants permission to my microphone and wifi at that, they’d either move down my preferred coffee shop list, or I’d have no interest in using thier wifi. And phone apps are relatively easy, but what about people on laptops? Even less likely to want to install a IOS/window/linux executable and enable microphone just to grab a wifi password.
– Seems silly, but then again salespeople are persuasive…
– Not to mention how many people actually use coffee shop wifi from a cell? – Maybe I/we’re the outliers here, but I don’t make a habit of connecting to public networks… Maybe I’d risk it on my laptop if I was planning on using quite a bit of bandwidth, but I’d generally rather light up a private hotspot from my phone than join a public network.
Generally speaking, if I’ve got 4g I’m fine.
If it’s 3G then maps should cope, whatsapp is probably ok (dont download video anyway unless on wifi).
If it’s low grade connection then that’s why I have a map saved on my phone.
I have wifi set to update over wifi only.
TV etc would be downloded over wifi, or else copied to the phone from home network.
I too rarely need public wifi, unless travelling or no signal at all and desperation to get something from the intenret that really cannot wait – ie: emergency.
But then I’m not a millenial glued to my phone.
If the WiFi password isn’t clearly printed somewhere, I’m just going to use 4/5G. It’s probably faster than the coffee shop’s WiFi anyway.
Pretty sure 90% of their business past 10AM disappears completely if you put a time limit on WiFi.
Not like those barristas were busy anyway.
I don’t even know what you’re saying about revenue stream. What “revenue stream”??
Embedding WIFI password into music is not the best way. A QR-Code is way better.
Changed the password? Print another code and stick it on the wall. Any smartphone can decode it and connect. No smartphone? Print the password bellow the QR-Code.
Sounds like a good application for E-ink or just an LCD display or even one of those cheap micro-projectors. They would be much less of a hassle once set up. :-)
this is a perfect use-case for e-ink.
Or NFC.
Streaming audio is good enough for sonic wallpaper and your commute or jog, but still a step backwards from CD quality. Mess it up a tiny bit more with data? Sure. Why not. You won’t hear the data over the espresso machine anyway.
I do see the utility; audio is an interesting way to share data to just one room, and a frequent change will stop the perpetual leeches. Seems kind of a heavyweight solution. Would you load an app from every coffeeshop you visit? Would you trust one “global” app to work in all the coffeeshops you visit, and not track your ass everywhere?
Have they just re-invented the audio modem? Why not make it two-way with that lovely crash/scratch noise?
https://youtu.be/gsNaR6FRuO0?t=9
Excuse please.
Anyone here recall why IR networking was abandoned. Seems the same manner of issues.
Not necessarily. IR doesn’t work because you need additional hardware plus you need line of sight. This method works anywhere the sound reaches and requires hardware most portable devices already have – or at least more devices than can support reading IR.
I drew up a method of encryption using audio once. Never implemented it, but it would basically be unbreakable.
I say forget about a WiFi password all together. Make sure to set up VPN service for the whole store to an anonymous location so the customer’s activity can’t be tracked to you and then relax. You can still block the bad actors at the router. Also, if the customer doesn’t want to be broadcasting their data unencrypted on the WiFi they should be using their own VPNs tunneling through your connection. That’s the most secure way to go in an ideal world where everyone knows what they are doing, but no-one who shouldn’t know ends up knowing what you are doing. :-) (Go with WireGuard, Trisquel, and Libreboot if you really want to peg the paranoid-o-meter. :-) )
Arnie Ziff did a similar thing years ago in the Simpsons.
I can certainly hear the difference, the second one doesn’t make any noise at all on my computer. Is it April 1st already?
I am probably missing something but if there is only one way transmission, every device with the appropriate audio decode software could obtain the password, so this appears to be about as useful and secure as just having no password?
exactly. if anyone can have access to the password easily – and i guess this would be the point fo the whole idea – then why have a password there in the first place? almost all of your important comms go over tls anyways…
if you want to restrict access to the wifi infra only to the customers, just print the code on the receipt
I think the idea is that people are stupid, and keep asking the personnel for the password. This (theoretically) would be a new standard, so their phones would connect automatically.
A new standard? Oh, my good lord. Broadcasting high frequency screeching continuously just so phones can connect to wifi?
What a moronic idea. If it were not masked by the “music” it would be intolerable. What about quiet places that don’t feel the need to barrage patrons with muzak? The screeching would drive most people away, or straight ’round the bend.
Only devices that can hear the audio have the password, effectively a geographical limitation without having to use a Faraday cage. Then you can have the password change so often that it would be annoying to distribute otherwise.
Hey! Don’t dis Sia.
Um, check out the CHIRP project ( “Chirp is like an audio QR code” ) @ https://chirp.io/
Wavelet encoding, along with the observation that the Fourier Coefficients of most natural signals exhibit asymptotic decay wrt frequency would potentially enable identification of the bit stream in the higher harmonics +/- attenuation/cancellation. This would also be a way of extracting the bit stream.
why don’t they just add a tiny encoded mp3 between every N songs? Seems a lot simpler than embedding within the music
So, the audio system bleats like an annoying mosquito during quiet portions. I’d call that a bug.
Those in north america with older weather radios (ones without automatic blanking of the noise) will recognize the data burst embedded in the audio every few minutes. Pretty much ruined it for normal listening.
Sounds like a POC for audio steganography
AFAIK Shazam has implemented something VERY similar in their ads – back in the days I was making a little HTML single-page app that was supposed to be opened via Shazaming a very specific track, that was provided to us by Shazam guys themselves. Did not work with Spotify version of the track.
Also, I remember people in the office being annoying AF, playing “Jingle bells” in October, to shazam it to test the ad. Imagine hearing “jingle bells” every 10-15 minutes from different spots?
If we could get everyone on board, there would be an option for expanding the Passpoint network/Boingo system to all carriers and devices…
Sounds horrible. The first track sounded good. The second track sounded like it was played on vinyl with a broken needle and torn speaker cones. I’d cross the street to not hear this. Great way to drive your customers away.
Would definitely stop the neighbors from stealing wifi though. They’d be moved out.
Would be an interesting idea if it didn’t destroy the soundtrack.
P. S. I’m tone deaf and have significant industrial hearing damage from concrete mixers. I’m not an audiophile
The sound would probably drive an audiophile to unscheduled spontaneous disassembly.
Wowww!!These are some awesome musical instruments a great place for the music instrument lovers. Thanks for sharing this great article with us, I will definitely share it with my brother in law, he is a music player and will love it.