
2020 is a year of reflection and avoiding regret, and one of the biggest practices we all know we should do better is back up our data. Inevitably there will be a corruption or accident, and we mourn the loss of some valuable data and vow to never let it happen again, and then promptly forget about good data retention practices.
I believe life is about acquiring memories, so it makes sense to me to try to archive and store those memories so that I can reflect on them later, but data storage and management is a huge pain. There’s got to be a better way (cue black and white video of clumsy person throwing up arms in disgust).
Nice Cloud You Have There; Shame if Something Happened to It
The teens of the century saw a huge shift towards cloud storage. The advantages of instantly backing up files and using the cloud as the primary storage for all your devices is appealing. It’s now easier to transfer files via the cloud than with a cable. With Google Docs and WordPress we have our most important documents and writing stored as database blobs on someone else’s servers. Facebook and Google and Flickr record all of our memories as photo albums. Unlimited storage is common, and indexing is so good that we can find photos with a vague description of their contents.
These things are instantly accessible, but lack permanence. Gone are newspaper clippings and printed photos discovered in a shoebox. When we aren’t in control of those services, they can disappear without any warning. Even some big offerings have packed up shop, leaving people scrambling to back up data before the servers were shut down. Google Plus is closed, Yahoo Groups is closed, MySpace lost all content created prior to 2016, GeoCities closed in 2009, and Ubuntu One closed in 2014. It’s safe to say that no online content is safe from deletion. It’s also safe to say that cloud storage is a difficult location from which to extract your data.
With the risk of data leaks and privacy violations occurring daily, it’s also safe to say that some of your files should probably not be stored in the cloud in the first place. So, how do we do it well, and how do we get in the habit of doing it regularly?
Mantra: One Local Storage Backup to Rule Them All

I think the solution is a single backup strategy for all content, where everything is coalesced into a single location at regular intervals, and the backup process is performed on the agglomeration. To that end, most of my files are organized by subfolder and stored on an external hard drive connected to my local router. This is known as a NAS (Network Attached Storage) scheme and has been around for about 40 years. It was a great idea then and remains so today.
This is accessible to all my devices, essentially giving me the benefits of a cloud (well, more like a fog since it’s so close), but stored on my own hardware. I have folders for projects, work, taxes, and photos, among other things, with subfolders extending many levels below that.
Are Those Thumb Drives Current?

We still use thumb drives all the time, and make quick changes to the files, but then don’t delete the files, and now we’ve got a bowl full of thumb drives with folders of things that are slightly different from their originals, but we don’t have the time to reconcile the differences. If I assume that anything on a thumb drive already exists on my other devices, and that the thumb drive is only a temporary storage medium for file transfer, then I don’t feel so bad about wiping the contents any time I need a thumb drive. They do not get backed up because they are not the original source of the document.
I recommend you follow my lead. Thumb drives lack a sense of permanence by their very nature and should be considered a scratch pad for data, not a stone slate for archives.
Gathering Your Flock of Devices
I have a laptop, desktop, tablet, and phone, which means four distinct streams of devices that all need backing up. Some may have project files stored locally for when I’m not on my network, and synchronizing those projects with my main NAS storage is sometimes tricky.
At the new year I take everything that’s in my local desktop profile, and copy it onto the NAS. This leaves a vulnerability as the year end approaches and a year’s worth of work is not backed up, but it’s better than nothing. It’s hard to decide what gets put into the NAS; does everything in the user’s profile get moved, including installers for applications, the downloads folder, bash history? What about settings for services that are running on my computer?
I’ve been lazy here, as I figure if a catastrophe were to happen it would be an opportunity to restart from scratch rather than recreate an environment with years worth of entropy and old applications. For a business backup where running services and configuration may be critical this is a bad idea, but for a personal server where things are more experimental and temporary, it’s not so important.
Email: Preserving Contacts and Correspondence
Backing up mail is debatable, but important to me. So many attachments and writeups are sent through this medium, and saving the threads for passive-aggressive “see this email from last year in which I answered your question already” is satisfying, but there is also a lot of useless garbage that doesn’t matter within days, and dedicating any additional time or energy or storage to it is counterproductive. I use Thunderbird for all my accounts. This has the benefit of having local storage of all the email, including all my Gmail and other accounts. This Thunderbird profile is stored on the external hard drive, so backing up my mail requires no additional effort.
Domains, Repositories, and Social Media
For each of the web domains I own I can go to the control panel and download zip files of all of their file contents and databases. This isn’t as easy with complicated AWS setups where data and settings are stored across multiple services. I imagine it would be possible to set up “wget –mirror” to copy contents from the remote location, but I’d still need to capture the database contents.
 In an ideal world all my projects would be in versioned repositories, backed up to a git server, and the local copy would be complete. This makes it part of the local storage that is already saved. If you don’t have copies of those repositories, maybe cloning them locally would be prudent. Since all my projects are in my projects folder on my NAS, I don’t have any additional work here, either. It is, however, a good idea to make sure that across all your devices your repositories are up to date before backing up your system.
In an ideal world all my projects would be in versioned repositories, backed up to a git server, and the local copy would be complete. This makes it part of the local storage that is already saved. If you don’t have copies of those repositories, maybe cloning them locally would be prudent. Since all my projects are in my projects folder on my NAS, I don’t have any additional work here, either. It is, however, a good idea to make sure that across all your devices your repositories are up to date before backing up your system.
When Europe passed the GDPR, one of the requirements around the law deals with data portability, specifically calling for people to be able to download data concerning them. This has led to many sites making it easy to get a zip file with everything. Facebook allows you to download your own data, which works pretty well. You can only download your own photos, however, not photos of you taken and uploaded by other people. I wish there was a better solution for that. I want to save photos other people took of me; not to violate copyright but to preserve memories. I also wish there was a way to save my Hackaday.io projects. While all my original files are stored in my local project folder, the writeups and logs are not. Still, this is another category where the goal is to download a zip file of all the content and save it to the NAS.
Photos
Between Facebook, Instagram, Flickr, Google Photos, and iCloud, among others, we probably each have a good number of photos spread around the web. The trick is not just in downloading those photos, but also making sure you don’t have duplicates stored elsewhere. Fortunately, each has methods available for downloading your content. Tools exist to find and remove duplicate files, but with terabytes of storage on my drives, the effort of pruning the data so far has exceeded my need.
Aggregation and Storage
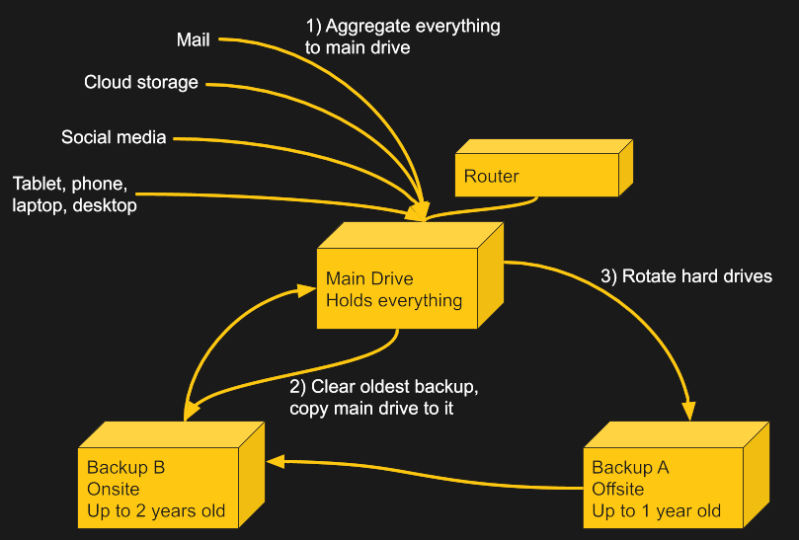
I have a total of three 5TB hard drives. One is for daily use, and two are the backups. One of the two is the most recent year, and is stored at a friend’s house. The other is from 2 years ago and is stored at my house. At the new year, I take the old one and erase it, then copy the daily one over to it and rotate the drives, moving the current one offsite, bringing the offsite one back, and turning the oldest one, which now has the newest copy, into the main drive. This way I always have a backup of my files that is a year or less old stored somewhere else in case of a local emergency like fire or flood, and one that is less than 2 years old in case of catastrophic failure of the daily and the external backup. I verify my backup by making the backed up drive my primary, which also serves to more evenly wear all of them.
Better Options?
They say a backup isn’t a backup unless it’s been tested, and I have only needed to look back on backups a couple times for missing files. But my solution isn’t the best. I know that even though I’ve captured everything (I hope) in the backup there are valuable things locked in a database file that would take a data archivist a long time to discover. My solution isn’t indexed or cataloged, and there are all kinds of duplicates, and things stored in strange places. It’s also time consuming, which is why I only do it once a year, and the later in the year before the next backup the greater the risk of data loss.
Some people swear by RAID for data redundancy, but that is NOT the same as data backup. We covered NAS options a little more than a decade ago, but things have changed a lot. What software tools or automation scripts make the process of downloading your special data easier or more efficient?
Creating a Legacy
A friend died recently, and there was a scramble to find photos and highlights of his life. It made me wonder what will happen with my legacy, which is primarily scattered across servers, condensed onto 3 hard drives, and difficult to search. I probably won’t be studied by historians in future generations, and curating my life’s digital content really only matters to me and a few people immediately close to me, so there’s a question of how much effort to put into this endeavor. Thus, in the beginning of the new decade, with so many more options available than when I started this pattern, I ask the community for suggestions on personal data storage and curation.














My backup solution is a 2TB external Western Digital portable USB disk and a tool to do backups onto it.
Periodically I plug the drive in and run a backup onto it. If I had the money I would buy more disks and rotate things through an offsite location to deal with fire/flood/disaster wiping out my entire apartment) but that would also require me to have an offsite location to store the data in (no family who live close enough, no friends I trust enough and the cost of paying someone to store something is probably prohibitive)
It’s pretty easy for me to grab my external drive in a hurry though even in an emergency.
I have problematic family and friends for offsite also. If I lend them something I need to ask for it back well inside 30 days or it’s gone, IDK where, thrift store, re-lent, garbaged, just gone. So I don’t hold much hope of a backup surviving either. My wife actually put just a few of her records on a CDR and asked one of her side to file it, a few months pass, asks her about it to replace it with an updated one “Oh I got rid of it with the rest of my CDs” great, lovely, smashing, thanks.
I have a fairly simple rule. One harddrive means one raspberry pi.
I have 11 rpis with 11 8TB harddrives.
There are things which do not really need redundancy, like ~~movi~~ linux isos.
There are things from which i like double copies, like family photos and videos.
And there are things which are work related and would *financially* hurt to loose them: triple copies.
Thrifted a solution with an old laptop with a 500 GB HDD. I installed Debian on it and I copy stuff to and from it with rsync via ssh. Long term data, archived videos, important documents, etc. It acts as my Minecraft server, Pihole and SSH server.
Keeping data on one place even if you have a million copies..
Keep your data in different locations. Preferably different cities countries or even continents.
I keep a HD in my office as well AND carry a 1tb drive with the essential data.
Maybe being a DR specialist made me cautious…
For all the next cloud people, what hardware do you run it on?
I find the performance to be very poor on large file syncs, very slow, often restarting or locking up.
I simplified years ago: a QNAP nas and Time Machine, plus an external HDD to backup the QNAP once in a while. I get a versioned, corruption-resistant bundle hosted on a 4 drive RAID 5. Oh, don’t forget to put the NAS on a good UPS. No need for a big battery, just a minute ortwo to do a clean shutdown and protection against brownouts.