
Once upon a time, computers were very expensive and you were lucky to have shared access to one computer. While that might seem to be a problem, it did have one big advantage: all of your files were on that computer.
Today, we all probably have at least a desktop and one laptop. Your phone is probably a pretty good computer by most standards. You might have multiple computers and a smattering of tablets. So what do you do to keep your files accessible everywhere? Why not run your own peer-to-peer synchronization service? Your files are always under your control and encrypted in motion. There’s no central point of failure. You can do it with one very slick piece of Open Source software called syncthing. It runs on Windows, Linux, Mac, BSD, and Solaris. There are also Android clients. We haven’t tested it, but one caveat is that the unofficial iOS support sounds a little spotty.
The joke about the cloud — that it’s just other people’s servers — is on point here. Some people don’t like their files sitting on a third-party server. Even if your files are encrypted or you don’t care, you still have the problem of what happens if you can’t reach the server — may be on an airplane with no WiFi — or the server goes down. Sure, Google and Microsoft don’t go dark very often, but they can and do. Even if you build your own cloud, it runs on your servers. Syncthing is serverless: it simply makes sure that all files are up-to-date on all your end devices.
Enter Syncthing
Syncthing is written in Go — not that you care — and efficiently syncs directories across many devices with a number of options. The simplest setup syncs all files in a folder, on all machines, with no versioning. But there are several flavors of version control to select and you can also make folders that only publish changes or where changes will not propagate to other devices. By default data is encrypted, and optionally compressed, when synchronizing. What’s more, the block exchange protocol gains efficiency as you add devices — think of it as a private BitTorrent between your devices.

Setup
Setting up Syncthing is easy. For Debian-type Linux you can follow their instructions to add a repository and install it using apt. There are other options for other operating systems. The only negative to the install is that it doesn’t set up Syncthing as a service, which is probably something you want.
They do provide examples of how to do this on GitHub. In my case, I had to use the linux-systemd files and put them in my /etc/system.d/system directory. The file syncthing@.service indicates that the service will run on behalf of a user. You can enable the service like this:
systemctl --user enable syncthing.service
The program does a good job of traversing NAT and firewalls, so I didn’t have to set any of that up. Speaking of setup, the default method of running setup is to open a web browser on the localhost. By default, you must be on the local machine to access the web page, but you can change that if you want to remotely configure the system. You can also use an ssh tunnel to pop out on the local machine. There are some third-party GUIs and programs that can control syncthing through its API.
Coupling Devices
Devices have to know about one another. The program generates a long ID or a QR code you can use to set up one machine on the other. You really need to do this on both sides — that is, you have to give computer A the code for computer B and give computer A’s code to computer B. When you accept another computer into your device list, you can mark it as an “introducer”. This will add all the computers they know and trust to your list as well.
This scheme means you need some sort of access to both computers, which is a good thing for security. If you are setting up on a headless server, though, you might need to use an ssh tunnel. I did this:
ssh -L 9876:localhost:8384 my-remote-host
Now a browser pointing to my localhost on port 9876 will appear on the syncthing administration port (8384) on the remote server. I didn’t use 8384 on the local side because, of course, I was running syncthing there already.
Sharing Folders
When you create a folder you can give it a display name and a location. Those can be different on every machine or they could be the same. What ties them together is the folder ID. Any folder with the same ID that is shared between two machines will synchronize. So, for example, you could have your local ~/Documents directory sync with a server directory called Desktop-Backups.
When you set up a folder you can turn on versioning. This keeps versions of files when a remote computer makes changes to it. It does not make versions for local changes. There are several options for versioning. The trashcan model just keeps a single copy of the old file. Simple versioning keeps a configurable number of old copies with a time stamp. There are several other choices, but those are the easiest ones.
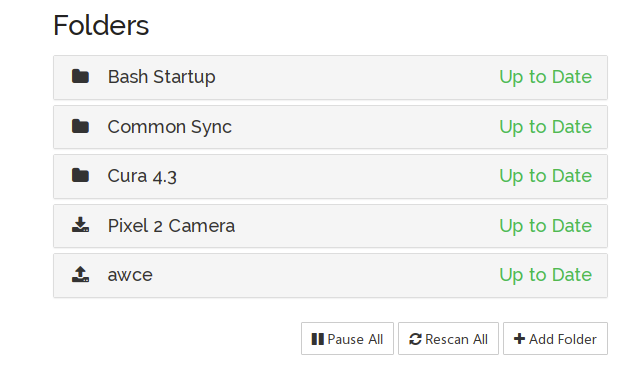
Another feature allows you to set up folders that only send changes to remote computers or only receive them. Of course, the default is that folders both send and receive changes. You might, for example, have a master set of configuration files that you only want to change locally, but you want other computers to incorporate those changes: set the folder to only send. You’ll notice the folder icons change based on your selections to include an arrow that points up or down depending on your choice.
What to Sync
Once you have things set up, it is pretty addictive to start syncing directories. Sure, pictures and other documents are a no brainer. But what about 3D printer configurations? Or even your system startup scripts. It is true that the system isn’t necessarily the best solution for backups, but you can use it that way, too.
When we’ve mentioned Syncthing to people, they often reply they would use OwnCloud or NextCloud. Each has its advantages, of course. While setting up your private cloud gives you the ability to install applications, you now have a dependency on a central server, even if it is your own.
Speaking of startup scripts, I wrote something to do that and it used Git to synchronize and version control your bash startup. That system would work well with syncthing instead of Git. If you are interested in such things, you might also want to check out chezmoi.














Syncthing is pretty good. Note that it doesn’t handle situations where a file is edited by two writers at the same time very gracefully – you’ll have to manually resolve the issues. This shouldn’t be a problem for photos, but can be for scripts or documents.
Syncthing shines super well with huge files too.
“The joke about the cloud — that it’s just other people’s servers ”
Joke? What do you think the cloud is?
Well, it’s still a cloud if the servers are mine.
Or am I a “other people” then?
I definitely need a mirror AND a pink couch now!
But from an end user never running own servers, ok…
There are lots of not perfectly exact statements out there that hurt me a lot more.
I will always insist that cloud is not a good name for this service. A fog or a mist would be more informative accurate term.
thanks Al ! These Linux Fu articles are really interesting!
Interesting. I believe you can also do the personal cloud thing with Resilio Sync, formerly Bittorrent Sync/BTSync https://en.wikipedia.org/wiki/Resilio_Sync
But this looks potentially better.
While I’d normally agree, this one is a little puzzling. The first thing that you think of on the subject of syncing, would be rsync. These articles tend to also be written to target the low standard stuff. This is a relatively advanced high-level tool modern tool. Not bad in itself of course … Also, waddabout nextcloud?
I wasn’t impressed when I upgraded my nextcloud installation to the next major version, and it completely stopped working. It has all the disadvantages of a LAMP application: complexity, built out of lots of separate scripts, requires a server, requires time for sysadmin activities, requires a database… and upgrading means upgrading the database schema, which I think is where I screwed up, and then gave up. Whereas syncthing is written in Go, thus compiled to one monolithic binary, only does one thing well… and just keeps working, even across all 4 OSes that I use. Even when the versions of syncthing itself are out of sync on different devices.
My conclusion is that first-gen “cloud application” technologies like nextcloud, and cloud-first filesystems like dropbox, have an obsolete architecture, and in fact we have been thinking completely wrongly about how the internet should be leveraged for this purpose. I don’t want a magic server holding all the data out of my control and hiding mostly behind web front-ends; what I want instead is discrete files organized on the filesystem in a way that I understand and control. E.g. my notes are now held in discrete markdown files, not in some database table that I didn’t design, or (worse) on evernote.
My passwords are stored in discrete gpg files managed by the classic pass script, and I’m not afraid to let syncthing sync them, because they are already encrypted before it gets to see them. I use a yubikey for the gpg key: the password files cannot be decrypted without it. Each individual password is in a separate file, so there’s no database to get corrupted. (You wouldn’t want to use syncthing on a database because there’s no easy way to resolve conflicts. Discrete files are the way to go; that way there are never any sync conflicts.) I never tried using any of the cloud-based password solutions because I never trusted them; so before pass and syncthing, it was a royal pain to have separate passwords for separate accounts: I kept some in a plain text file, some in other encrypted password databases that I was trying out. There were those browser extensions that could take a master password and use a hash to generate a unique password for each web site; but those are incompatible with each other, also incompatible with command-line tools that use the same technique to generate passwords for other purposes, and don’t give you a choice in case the web site has stupid rules about what the password should look like (mix of uppercase, lowercase, numbers and only certain symbols, etc.) Even better: on Android, I can read the same passwords with an app and the same yubikey that I always use for gpg: https://github.com/android-password-store/Android-Password-Store ; syncthing makes sure that passwords I created on any of my computers will be available on my phone too. Password management just can’t get much better than that.
I want to get to the point where each email I receive is also stored in a discrete file (preferably markdown) with a human-readable name, instead of in a maildir. Email has always been overly complex: one ancient special-purpose protocol for sending, three choices for receiving (your own smtp server – likely insecure; pop or imap – slow and probably out of your control, depending on who provides the server). If you want to read the same emails on multiple devices, each of them ends up fetching from the same server, which means the server works harder than it should, and the fetching is slow on every device. Using file sychronization directly between devices sounds like a good fix for this problem. But maildir is not designed for that. I want to come up with a new standard and modify one of the mail-fetchers (perhaps isync, or cook something up with some Rust libraries) to store my emails in files that are named deterministically and human-readable, so that even if multiple devices are each trying to fetch some of the emails at different times, and also syncing with each other, all the devices end up having all the emails (within some time-span at least), even though no individual device got all of them from the server. Beyond that, the next step would be for the multi-user SMTP server itself to dump incoming emails into files in users’ home directories, and each user could use syncthing, so there would be no more need for pop and imap. But syncthing is not multi-user, yet; it would require a separate process for each user, at least a temporary process.
I use it to sync work-related files between home and work computers too, so that I can work from home. (But now I work full-time from home because of the virus. I was already used to doing it occasionally, so that was no big deal.)
The same idea could be applied to more things, and thus more protocols could be made obsolete.
I used to be a fan of rsync, and sometimes still use it; but that’s a unidirectional sync, only from one machine to one other, that you typically execute when you realize that you need to (unless you automate it with a cron job). Whereas syncthing is a daemon that keeps running all the time, uses inotify to detect that files changed instead of polling, and therefore can sync almost instantly; and it can sync an arbitrarily large cluster of machines, not just two.
The fact that it works even on Android is pretty amazing too. All photos that I take on my phone get sent to the computers of my choice pretty quickly. Android never really had a solution for that: they want you to be locked in to Google-provided cloud services instead. You don’t like that, want to use USB instead? ADB is terrible. MTP doesn’t work on Linux. I had no convenient way to get the photos off my phone before syncthing, and now it’s completely effortless: by the time I want to look at them on Linux, they’re already there. Once I even dropped a phone so badly that it never booted again, on a trip. But some of the photos from that trip had already gotten transferred before then, so I didn’t lose them.
If I find an ebook or technical paper online and think maybe I want to be able to read it on-the-go, I add it to a synced folder ~/online/books. Syncthing makes sure it will be on the phone by the time I get around to that. Same thing with music. Same thing with gpx files for hiking trails that I want to try. Same thing for tickets, boarding passes and such (PDF files with barcodes, or passbook files for PassAndroid). Same thing for shopping lists (todo.txt files – yes there’s an app for that on Android, SimpleTask).
The cloud is a racket: it enables service providers to invent and manufacture “need” for lots of individual little dumbed-down “services” which we’re expected to pay for individually, but also taking away control and compromising security at the same time. Syncthing makes the whole concept obsolete, because it fits perfectly with the aspect of the Unix philosophy that everything should be stored in human-readable files.
agree 100% all said here. i am an early adopter of syncthing and use it a lot. it has the occasional hiccup but it works much better than anything else i tried. i was on btsync before but dropped it like a hot potato when it changed scheme to paid service, not because i had to pay, but because it started to suck.
i have syncthing running on several platforms and OS, also using it for synchronizing phone data to a RPI based backup server. fantastic little piece of sw.
What app on the phone? I’ve tried at least one on a Galaxy S9 w/o much success. Works great between a RPi, Kubuntu & Win10s. I switched over to SyncThing when Dropbox changed their free policy to allow only 3 devices, and am still using it to get photos/GPX from the phone.
> The program does a good job of traversing NAT and firewalls, so I didn’t have to set any of that up.
And everybody finds it normal?
Actually, the network requirements are a bit obscure to me.
First, I don’t want Syncthing to contact the official relay by default . Second, what flow does what?!
I wasn’t blown away by speed in a LAN, neither.
> And everybody finds it normal?
Yes, I do. As a sysadmin for a living for the last two decades or more, I know how painful is to traverse NAT and share things on different networks. On corporate networks, it’s ok to clamp down everything, but on my private network and my private phone it’s more a hassle. Automatic NAT traversal speeds up everything, so I can take one laptop with me to a cofee, edit a document, get back home and the home computer have that copy, no need to remember to copy it manually.
> First, I don’t want Syncthing to contact the official relay by default .
You don’t have to. You can have your own private relay server if you want. It’s just a parameter on the start script or configuration file. Rent a VPS, install syncthing there, configure it as a relay, done.
> Actually, the network requirements are a bit obscure to me.
They are pretty simple. You need a relay to set up NAT traversal, all devices will connect to each other and things get transparent after that. If you only use a private LAN, no need to traversal, no need to external relays, just add the private IP of each computer and it’s done. It can even scan the network for peers, if you want.
> I wasn’t blown away by speed in a LAN, neither.
Me neither. But when I need to copy large files on my LAN, I use rsync. I use syncthing to keep things in sync between my computers, not to file transfer. Having two computers and making sure I am editing the last version of whatever report I am writing is way more important than transfer speed. And a 4MB document is copied “instantaneously,” so no worries.
“one very slick piece of Open Source software called synching.”
Shouldn’t that be Syncthing?
Link has label “synching”, should be “syncthing”.
Over here is `/etc/system.d/system/` just `/etc/systemd/system/`.
I currently see no alternative to syncthing.
Unluckily syncthing is so resource intensive that I only start it on demand on some systems.
But it does its job.
Have backups!
Shit happens and syncthing happily will multiply it.
Look through its forum for oceans of tears.
And I dislike GO.
But that’s a different rant… for somewhen… I won’t wake you up for it… promised!
;-)
Try unison. Cli executable, working on linux, wndows and mac. Never checked windows. In my setup works over ssh ans syncs three machines. Listens to exclude lists and is low on resources. Conflict resolver included.
https://www.cis.upenn.edu/~bcpierce/unison/
Rsync is my best friend.
Rsync just works, it’s scriptable, can use SSH as it’s transport and doesn’t have an annoying web GUI to get in the way of automation. And it’s blessed by the powers that be at work. Something Syncthing will likely never be.
I love rsync too, and with pull backup over SSH to ZFS with snapshots I have the version of that file as it was last Saturday too, but I’m tempted to try syncthing for photos on Android if it’s easier than setting up rsync on Android.
Despite its name, rsync is not a sync tool. It’s great for deployments or backups, but not syncing.
Try using it as one, and enjoy the pain. Was the file removed deliberately or not copied? What happens when two people edit the file? Not to mention it’s not a daemon.
It would be nice if the author had explicitly spelled out what is the problem this solves. If as mentioned I’m on an airplane and can’t get access, this doesn’t help me.
Be best!
Well, actually t does solve that problem. Presumably, at some point you were connected and you will have the latest version on the plane. Later, when you reconnect, it will sync automatically.
Syncthing… I tried it two times, but I never really became friends with it. Seems I’m to stupid to set it up or understand that peer2peer concept.
I go with Nextcloud for most of the stuff or just rsync. Nextcloud will keep a copy on each instance running it – so I do not quite understand that “offline” argument in the article.
But Syncthing is now several years old and people still write about it, so… whatever floats your boat ;)
I just tried it and it is very impressive. The .apk is available from F-Droid, the server can run as an unprivileged user on a VM, the Getting Started documentation has everything you need and nothing you don’t. Security and privacy look good. Everything looks slick and discovery works well. I had to restart it on Android (using it’s UI) before shared folders began to sync but otherwise flawless.
I had been thinking lately about how to backup photos on the phone and this made it easy.
Thanks Al!
I use nextcloud. my server occasionally goes down as the internet where it sits is a bit spotty, but if it does my devices already have all the files locally and up to date up to time of outage. very simple to setup. android andnios clients. not tried this but nextcloud seems a nicer solution?
Why not using normal git and normal rsync or git push/pull ?
I have used syncthing to keep different machines at work (Windows, Mac and Linux) with different users all synchronizing the same files (~30GB). The goal was to have a cloud-less shared folder available offline that worked over the internet but is still fast to synchronize in LAN environments. These are my notes from my experience:
– The app was not designed to be used by multiple users sharing the same folder (unlike services like dropbox). It’s not easy to manage users from a centralized point of view.
– Syncing large files is very fast (when compared to stuff like Dropbox, etc.). However, syncing is extremely heavy on resources. It also does a rescan periodically which is very heavy as well. It’s currently using around 120MB of RAM as a daemon on my Windows machine (when not syncing).
– Sync conflicts are very common in my experience. I have had some machines get corrupt databases over time and this led to several sync conflicts, which simply would not have happened if I had a centralized sync system like Dropbox or OwnCloud. If you don’t resolve the sync conflicts correctly this will lead to loss of data.
– There is no user-friendly way to exclude subdirectories. This means that users are forced to sync the entire folder even if there are subfolders that they don’t need.
For the most part the app did do the job however, and I really can’t seem to find an alternative. I would recommend it for single users bearing in mind the limitations.
I have had a moment of sheer terror upon looking through packages that are installed on my Synology NAS – I had installed SyncThing a couple of years ago thinking I would use it for backup but never got around to setting it up. Today, while uninstalling packages I haven’t been using, I looked at the interface of SyncThing, which says at the top in red letters, “Danger! The Syncthing admin interface is configured to allow remote access without a password. **This can easily give hackers access to read and change any files on your computer.** Please set a GUI Authentication User and Password in the Settings dialog.” Does this mean that SyncThing has been serving up my NAS files since I installed it because I never got around to setting up a username and password?