
You probably know about cron, a program that lets you schedule programs to run at various times. We’ve also talked about incron, which is very similar but instead of time, it reacts to changes in the file system. If you ever wanted to write a program that, say, detects a change in a file and automatically uploads it to a programmer, backs it up, e-mails it somewhere, or anything else, then incron might be for you. Although we’ve talked about it before, incron has some peculiarities that make it very difficult to debug problems, so I thought I’d share some of the tricks I use when working with incron.
I was thinking about this because I wanted to set up a simple system where I have a single document directory under git control. Changing a markdown file in that folder would generate Word document and PDF equivalents. Conversely, changing a Word document would produce a markdown version.
This is easy to do with pandoc — it speaks many different formats. The trick is running it only on changed files and as soon as they change. The task isn’t that hard, but it does take a bit to debug since it’s a bit nontrivial.
Incron Review
Setting up incron can be a bit of a pain. I’m going to assume you have a way to install it using a package manager like apt and that your system uses systemd to start and stop the service.
There’s more to it than that, though. You’ll need to be named in the /etc/incron.allow file (and not named in /etc/incron.deny). Once you are set up, it is pretty easy to use. Until it isn’t.
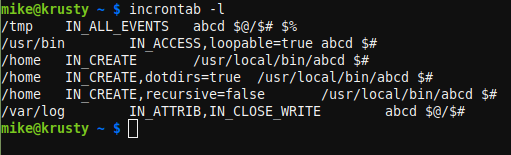
Each user has an incrontab. Use: man 5 incrontab to find out about it. To edit it, use this command:
incrontab -e
Each line has three fields and you must use a single tab between each field. The first field is the directory or file to watch, the second field has comma-separated entries to tell incron what kind of changes you are looking for and some other options. The final field is the command to run.
There are some special characters you can use in the command line. $@ gives you the directory name, for example. The $# macro is the file name while $% gives you the event type as a string ($& is a numeric code for the same). If you need a real dollar sign, just double it.
The events are things like IN_CREATE, IN_DELETE, IN_MODIFY, and many others. You can use any number of them together, just use commas between them. I’ll have more to say about that later. There are also some options like IN_DONT_FOLLOW which stops symbolic link dereferencing. You can also set recursive=false to stop monitoring subdirectories and loopable=true which is supposed to stop a common problem but doesn’t always.
You’ll see documentation on the internet that is sometimes out of date. The current development is on GitHub, but the main developer stopped back in 2012 and there was a two-year gap before someone picked it up for bug fixes. Sometimes it pays to read the source code of the version you have to understand exactly what’s going on.
What’s Wrong With It?
The incron service suffers from an identity crisis. Both by function and name, it must be similar to cron, right? Superficially, that’s true, but the details are quite a bit different. For one thing, older versions of incron don’t allow comments in the table. So you might think you’ve commented something out, but you haven’t really. On top of that, it is very difficult to get the output from your commands or even decent status. Not impossible, though, just difficult. Recent versions do allow comments, but it was a long time coming, and your version may or may not be up to date.
The other thing that is frequently a problem is that any action you take in your program that triggers a file system change might put you in an endless loop. You would think incron would figure this out and do something. Instead, your one line in your private incrontab can crash the entire daemon.
To further compound things, many programs do things you don’t expect that break some of the events. You might think, for example, that if you want to know when a file changes you should monitor IN_MODIFY. Makes sense. But most editors don’t work that way. If you edit the file, it will sometimes work on a copy of the file in /tmp and then the save operation is really a move. Sometimes programs with similar functions will have different event flows. For example, scp and rsync handle files differently and catching when a new file appears will require different handling depending on which program put it there.
The First Tip: Log as You Work on Commands
So that leads to the first tip. Write a temporary rule using the IN_ALL_EVENTS keyword and use a little shell script to just log what happens when you do things you think will happen to the file. You might find the results surprising and it is better to understand the event flow for your use case before you start writing real scripts.
Suppose you have a script called echoarg.sh:
#!/bin/bash fn="$1" shift echo "$@" >>"$fn"
Just a quick and dirty script, but you can use it with incron:
/home/user/tmp/itest IN_ALL_EVENTS /bin/bash echoarg.sh /home/user/tmp/echoarg.log $% - $@/$#
The file names ought to have quotes, of course, but since we are just printing them out, it doesn’t matter here. One thing to note: some installations will not allow incron to write to places like /tmp or even monitor files there. You are better off sticking to a directory you know you own (in this case /home/user/tmp). Here’s the result of running touch foo in the ~/tmp/itest directory:
IN_ATTRIB - /home/user/tmp/itest/foo IN_CREATE - /home/user/tmp/itest/foo IN_OPEN - /home/user/tmp/itest/foo IN_CLOSE_WRITE - /home/user/tmp/itest/foo
More Things to Worry About
Each distribution packages things a bit differently, so you may have to read some documentation. For example, on Debian-based systems, what little it does get logged by incron is written to the system log. But on some other common distributions, it reuses the cron log file.
The program is very finicky about spaces and tabs, too. So a stray space between the second and third fields will mess things up. So will a tab after the program name, the shell will take the tab and the next token as part of the program name.
Speaking of the shell, incron is very peculiar about finding shells and setting environments. Your version may vary, but the safest thing to do is assume you will need a path to everything and an explicit shell in the incrontab. If you need special things in the PATH or other environment configuration, do it in the script. Even if you are running a binary, it pays to write a little wrapper so you can set everything up the way you want. At the very least, when you run your test, dump the runtime environment out to a temporary log file so you don’t find out the hard way that you are missing a lot of your expected environment.
Using a command like $(date) is doomed because incron will eat the dollar sign. If you feel lucky, try using $$(date).
The Big Event
After you understand the events you want to process, you need to write your script and test it as much as you can without using incron. In my case, I wrote autopandoc with the idea that I’d add the PDF functions later:
#!/bin/bash
if [ -z "$1" ]
then
exit 1
fi
if [ ! -f "$1" ]
then
exit 2
fi
dir=$(dirname "$1")
ffilename=$(basename -- "$1")
ext="${ffilename##*.}"
filename="${ffilename%.*}"
case "$ext" in
doc*) newext="md"
;;
md) newext="docx"
;;
*) exit 3
esac
if [ ! -f "$dir/generated" ]
then
mkdir "$dir/generated"
fi
exec pandoc "$1" -o "$dir/generated/$filename.$newext"
This is simple to run from a command line with fake directory, file, and event arguments and make sure the logic does what you want. Trust me, that will be much easier than debugging during incron events.
My first attempt didn’t work well at all and there was very little explanation. By watching the logs, I could see that the file events were happening, but there was no evidence that my scripts — no matter how simple — were running. Turns out, adding an explicit /bin/bash to the table made everything work.
However, getting incron to stop retriggering if I wrote back to the same directory proved to be challenging. I wound up making a subdirectory which would trigger a change that would then make another subdirectory, triggering another change. Eventually, incron would die. Not just a worker thread for my user. Incron would die for all users. I suppose you could change systemd to relaunch it, but that isn’t really a solution.
There are a few options to inhibit incron from reacting multiple times to the same file, but making a new file still causes events and, honestly, if it didn’t that would be another problem if you were trying to handle multiple users. I wound up punting, but first, let’s see how you can peek inside of what’s happening during an incron run.
It’s Log!
As I mentioned, the log file can show up in a few different places. KSystemLog is handy if you use KDE since it can filter and show you events as they happen. You can also use tail -f, of course, but you might need a grep to cut down on the noise.
If you use systemd, you can try something like this:
journalctl -f -u incron.service
This acts like a tail -f for the incron log file. Watching incron repeatedly trigger events on /my_dir/subdir/subdir/subdir…. will tell you a lot about what’s going on in your script.
Other Tips: Run the Daemon Yourself, Use strace, and Max Your Watches
You can stop the incron daemon using your choice of methods (e.g., systemctl stop incron) and then run incrond yourself with the -n option. That shows you what the program is doing. Be sure to run it as root.
Another thing that makes possible is using strace to run the program. This will reveal all the system calls the program makes, so if you are wondering what files it opens and the results of those opens, that’s the way to do it:
sudo strace incrond -n
The -n option makes the program stay in the foreground. Just remember to kill it when you are done and start the service again. Of course, if you are on a machine you share with other people, this is probably a pretty rude idea.
If you do start making use of incron, you may find you run out of file system watches. If you do, try:
sysctl fs.inotify.max_user_watches
You can temporarily change the number allowed by using
sysctl -w fs.inotify.max_user_watches=1000000
Make it permanent by editing /etc/sysctl.conf or add a file to /etc/sysctl.d.
Does it Work?
Once you do get things working, it works well. For production, though, it worries me that one errant script can crash the whole service. There are alternatives. If you don’t mind systemd, there are path units. There are several possible alternatives on GitHub, although none seem recently maintained.
Like most Linux tools, sometimes this is the right choice, and sometimes you’ll want to use something else. But it still pays to understand all the tools you can have in your box.














I’ve always just used inotifywait and inotifywatch in scripts and oneliners directly.
hah when i’ve needed this i “use Linux::Inotify2” in perl, but *of course* there’s a commandline utility too – thanks for the tip!
It’s pretty incredible what can be done with bash. It just needs a good IDE :p
There’s also FAM (File alteration monitor).
I accidentally clicked report comment instead of reply…
> I accidentally clicked report comment instead of reply…
Lets start a club!
I got caught by this some times too…
Oh and you can you path unit files if you already have and use systemd.
https://www.freedesktop.org/software/systemd/man/systemd.path.html
Always provide the path to your binaries. Doing otherwise is a security vulnerability.
Well I would say this article successfully convinced me to never use incron
What kind of nightmare masochist software is this? I mean, it’s perfect for playing around with as a hacker, for a bizzare retro challenge, but I’m staying the heck away!
Systemd already has PathChanged triggers, kinda surprised that hasn’t been mentioned more. I don’t even use regular cron anymore now that systemd timers exist.
Well, almost the last line:
There are alternatives. If you don’t mind systemd, there are path units.
Not `incron` but I’m using `rb-inotify` to provide a crude live-coding environment where unit tests are automatically re-run when source files change.
… I am not sure I understand why you wanted incron in the first place – didn’t you want to regen output files based on changes to the source which you were already tracking with git? why not use git commit hooks?
Having spent a lot of time building a CI (continuous Integration) system based upon github, which did not use the completely bloated Jenkins or any of the other non free systems such as Travis, I can sympathise with the vagaries of incron.
I have used fam and ionotify etc to report upload of files or change to trigger files, but often found strange errors with both, never mind the arcane usage.
The simplest method I found was using github hooks over jsnode webhook service to write a trigger file on the server.
A cron job checks for existence of this file and actions ensue if found.
cron appears bullet proof (so long as you are aware of PATH issues and ensure each script sets PATH or specifies full path for commands) and the checks take split seconds.
This has been a robust and easily maintained system in use for several years.
Any debugging required can be included in the scripts called and output to a log.
why is it when a 3rd party hack is implanted in linux its a guru moment, but a core feature of the microsoft world its a sin?
Ah here is the Linux world I know.
One person sharing their experience and knowledge to help others attempting the same thing.
‘Ten’ people responding with “Why the hell are you doing it that way, this way would be much more simpler!”
‘One’ person making a “if Microsoft did this, you’d scream” comments.
Not one person saying “Thanks! this is exactly what I needed to know!”
there’s always multiple ways to do $thing … the question is how to reduce the moving parts of the solution. The implied problem for this solution was to recreate dependent files after they’d been modified … but git was already in the mentioned to be in the mix and the article didn’t explain _why_ these files to be regenerated the absolute instant they were modified which could have justified the extra pain …
I will definitely be looking at incron – I’ve used inotify-based lsyncd in the past for a poor-man’s web cluster and while that worked most of the time it had all sorts of janky behaviour in practice … which was why I asked about using git hooks (as others mentioned also)
bah – always happens
s/already in the mentioned/already mentioned/
s/files to be/files needed to be/
That tip about it being finicky about spaces just saved me hours of pulling my hair out. Thanks!