
Most readers will have at least some passing familiarity with the terms ‘Unicode’ and ‘UTF-8’, but what is really behind them? At their core they refer to character encoding schemes, also known as character sets. This is a concept which dates back to far beyond the era of electronic computers, to the dawn of the optical telegraph and its predecessors. As far back as the 18th century there was a need to transmit information rapidly across large distances, which was accomplished using so-called telegraph codes. These encoded information using optical, electrical and other means.
During the hundreds of years since the invention of the first telegraph code, there was no real effort to establish international standardization of such encoding schemes, with even the first decades of the era of teleprinters and home computers bringing little change there. Even as EBCDIC (IBM’s 8-bit character encoding demonstrated in the punch card above) and finally ASCII made some headway, the need to encode a growing collection of different characters without having to spend ridiculous amounts of storage on this was held back by elegant solutions.
Development of Unicode began during the late 1980s, when the increasing exchange of digital information across the world made the need for a singular encoding system more urgent than before. These days Unicode allows us to not only use a single encoding scheme for everything from basic English text to Traditional Chinese, Vietnamese, and even Mayan, but also small pictographs called ‘emoji‘, from Japanese ‘e’ (絵) and ‘moji’ (文字), literally ‘picture word’.
From Code Books to Graphemes
As far back as the era of the Roman Empire, it was well-known that getting information quickly across a nation was essential. For the longest time, this meant having messengers on horseback or its equivalent, who would carry a message across large distances. Although improvements to this system were imagined as far back as the 4th century BC in the form of the hydraulic telegraph by the ancient Greek, as well as use of signal fires, it wasn’t until the 18th century that rapid transmission of information over large distances became commonplace.
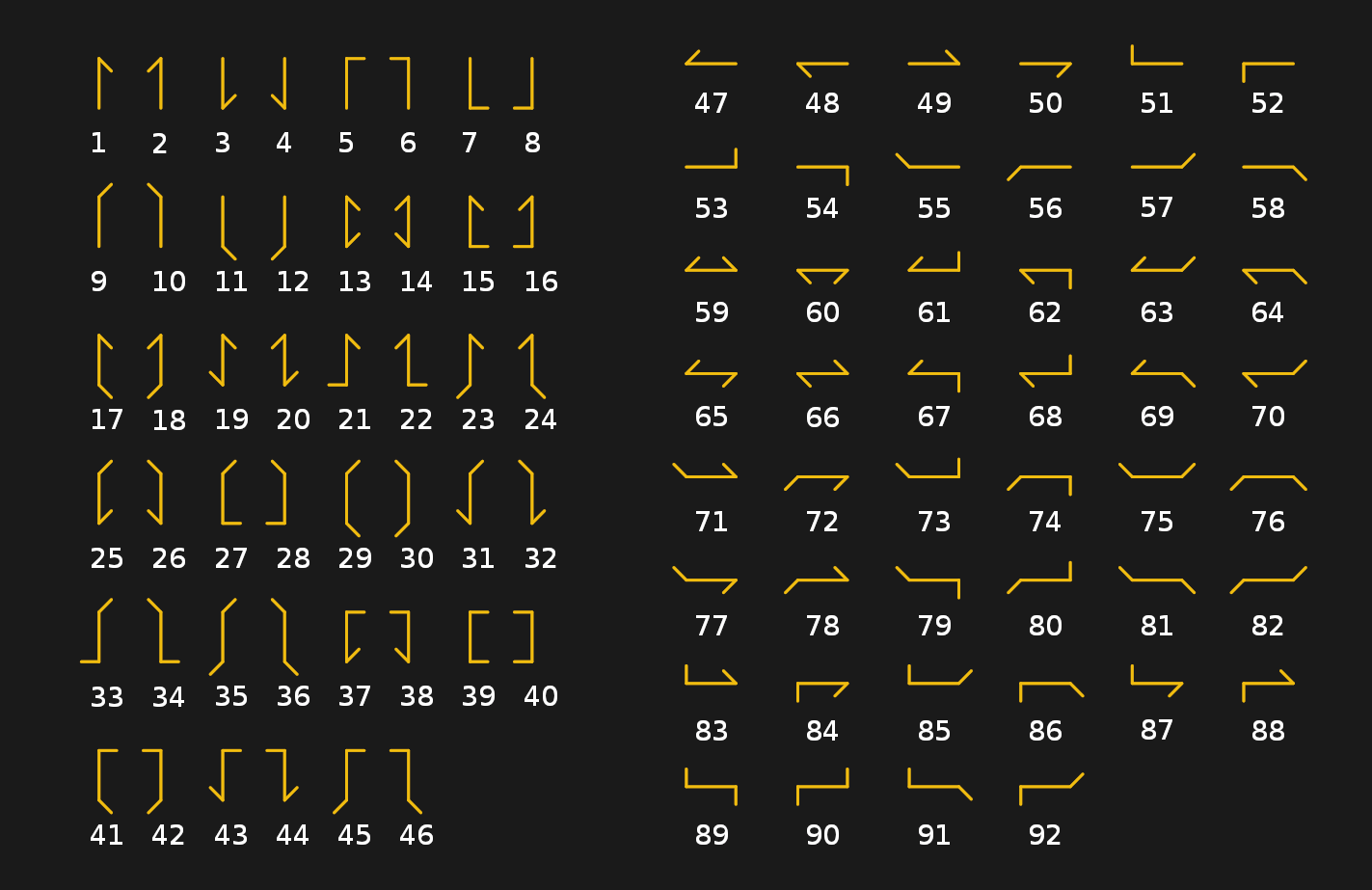
The optical telegraph (also called the ‘semaphore’) was discussed in depth in our recent article on the history of optical communications. It consisted of a line of relay stations, each of which was equipped with an elevated system of pivoting indicator arms (or its equivalent) used to display the telegraph code character encoding. The French Chappe system, which saw French military use between 1795 and the 1850s, was based around a wooden crossbar with two movable ends (arms), each of which could be moved into one of seven positions. Along with four positions for the crossbar, this made for a theoretical 196 symbols (4x7x7). In practice this was whittled down to 92 or 94 positions.
These code points were used not only for direct encoding of characters, but mostly to indicate specific lines in a code book. The latter method meant that a couple of transferred code points might entail the entire message, which sped up transmission and made intercepting the code points useless without the code book.
Improving the Throughput
As the optical telegraph was phased out in favor of the electrical telegraph, this meant that suddenly one wasn’t limited to encodings which could be perceived by someone staring through a telescope at a nearby relay tower in acceptable weather. With two telegraph devices connected by a metal wire, suddenly the communication medium was that of voltages and currents. This change led to a flurry of new electrical telegraph codes, with International Morse Code ultimately becoming the international standard (except for the US, which kept using American Morse Code outside of radiotelegraphy) since its invention in Germany in 1848.
International Morse Code has the benefit over its US counterpart in that it uses more dashes than dots, which slowed down transmission speeds, but also improved the reception of the message on the other end of the line. This was essential when long messages were transmitted across many kilometers of unshielded wire, by operators of varying skills levels.
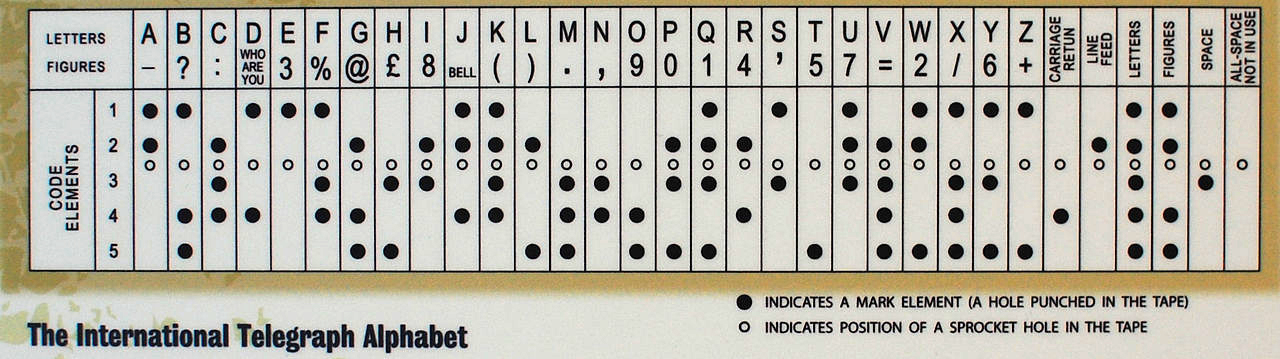
As technology progressed, the manual telegraph was replaced in the West by automatic telegraphs, which used the 5-bit Baudot code, as well as its derived Murray code, the latter based around the use of paper tape in which holes got punched. Murray’s system allowed for the message tape to be prepared in advance and then fed into a tape reader for automatic transmission. The Baudot code formed the basis of the International Telegram Alphabet version 1 (ITA 1), with a modified Baudot-Murray code forming the basis of ITA 2, which saw use well into the 1960s.
By the 1960s, the limit of 5-bits per character was no longer needed or desirable, which led to the development of 7-bit ASCII in the US and standards like JIS X 0201 (for Japanese katakana characters) in Asia. Combined with the teleprinters which were in common use at the time, this allowed for fairly complicated text messages, including upper- and lower-case characters, as well as a range of symbols to be transmitted.
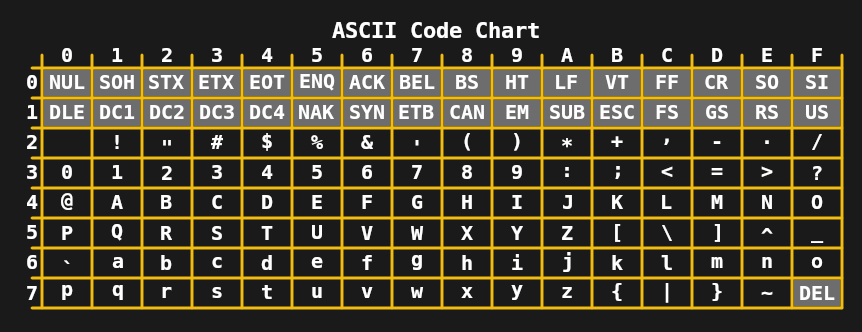
During the 1970s and early 1980s the limits of 7- and 8-bit encodings like extended ASCII (e.g. ISO 8859-1 or Latin 1) were sufficient for basic home computing and office needs. Even so, the need for improvement was clear, as common tasks like exchanging digital documents and text within e.g. Europe would often lead to chaos due to its multitude of ISO 8859 encodings. The first step to fixing this came in 1991, in the form of the 16-bit Unicode 1.0.
Outgrowing 16-Bits
The amazing thing is that in only 16-bits, Unicode managed to not only cover all of the Western writing systems, but also many Chinese characters and a variety of specialized symbols, such as those used in mathematics. With 16-bits allowing for 216 = 65,536 code points, the 7,129 characters of Unicode 1.0 fit easily, but by the time Unicode 3.1 rolled around in 2001, Unicode contained no less than 94,140 characters across 41 scripts.
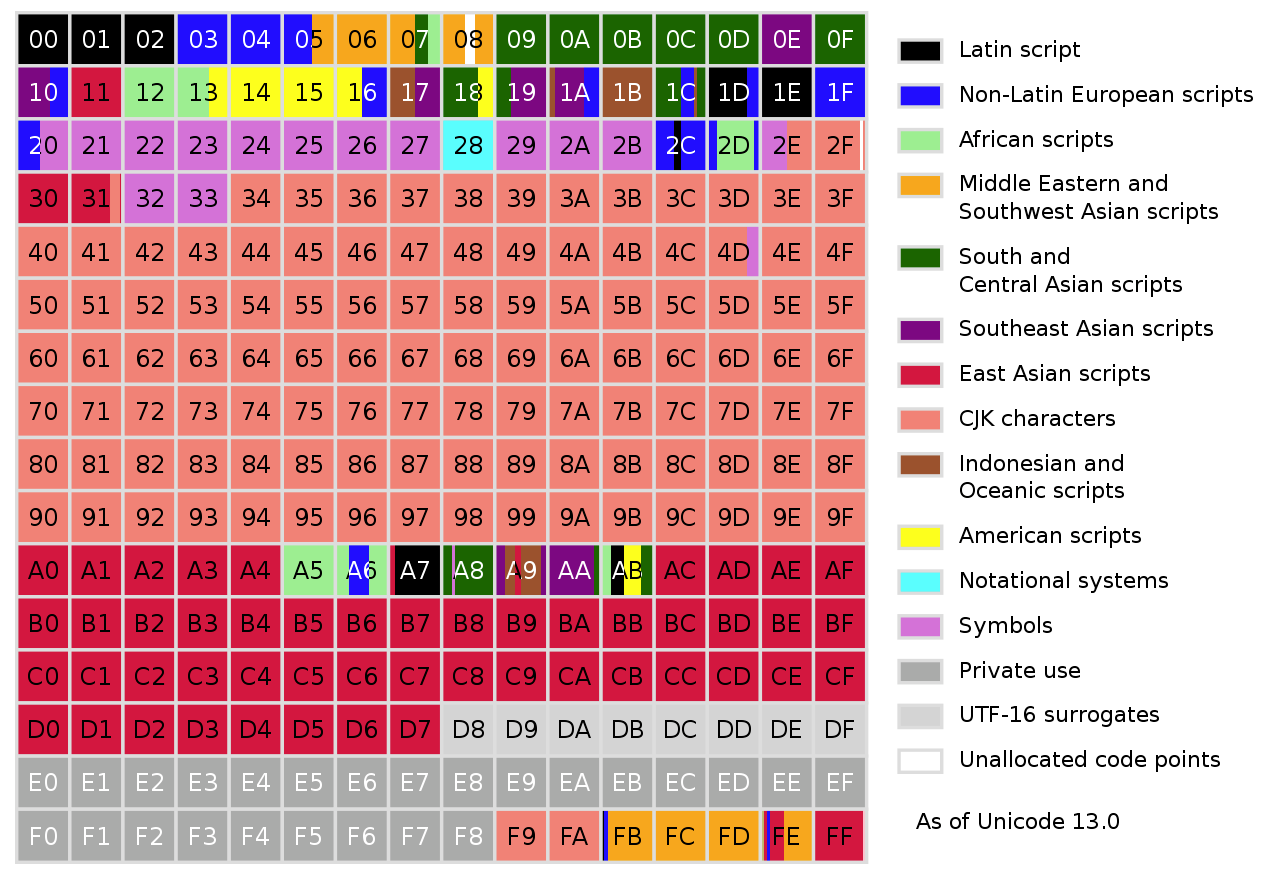
Currently, in version 13, Unicode contains a grand total of 143,859 characters, which does not include control characters. While originally Unicode was envisioned to only encode writing systems which were in current use, by the time Unicode 2.0 was released in 1996, it was realized that this goal would have to be changed, to allow even rare and historic characters to be encoded. In order to accomplish this without necessarily requiring every character to be encoded in 32-bits, Unicode changed to not only encode characters directly, but also using their components, or graphemes.
The concept is somewhat similar to vector drawings, where one doesn’t specify every single pixel, but describes instead the elements which make up the drawing. As a result, the Unicode Transformation Format 8 (UTF-8) encoding supports 231 code points, with most characters in the current Unicode character set requiring generally one or two bytes each.
Many Flavors of Unicode
At this point in time, quite a few people are probably at least somewhat confused by the different terms being thrown around when it comes to Unicode. It’s therefore essential to note here that Unicode refers to the standard, with the different Unicode Transformation Formats (UTF) being the implementations. UCS-2 and USC-4 are older 2- and 4-byte Unicode implementations respectively, with UCS-4 being identical to UTF-32, and UCS-2 having been superseded by UTF-16.
UCS-2, as the earliest form of Unicode, made its way into many operating systems of the 90s, which made a move to UTF-16 the least disruptive option. This is why Windows, as well as MacOS, window managers like KDE and the Java and .NET runtime environments use a UTF-16 internal representation.
UTF-32, as the name suggests, encodes every single character in four bytes. While somewhat wasteful, it is also straight-forward and predictable. Whereas in UTF-8 a character can be one to four bytes, in UTF-32 determining the number of characters in a string is as simple as counting the number of bytes and dividing by four. This has led to compilers and some languages like Python (optionally) allowing for the use of UTF-32 to represent Unicode strings.
Of all the Unicode formats, UTF-8 is however the most popular by far. This has been driven largely by the Internet’s World Wide Web, with most websites serving their HTML documents in UTF-8 encoding. Due to the layout of the different code point planes in UTF-8, Western and many other common writing systems fit within two bytes. Compared to the old ISO 8859 and (8 to 16-bit) Shift JIS encodings, this means that effectively the same text in UTF-8 does not take up any more space than before.
From Relay Towers to the Internet
Since those early years in humanity’s past, communication technology has come a long way. Gone are the messengers, the relay towers and small telegraph offices. Even the days when teleprinters were a common sight in offices around the world are now a fading memory. During each step, however, the need to encode, store and transmit information has been a central theme that has relentlessly driven us to the point where we can now instantly transmit a message around the world, in a character encoding that can be decoded and understood no matter where one lives.
For those of us who enjoyed switching between ISO 8859 encodings in our email clients and web browsers in order to get something approaching the original text representation, consistent Unicode support came as a blessing. I can imagine a similar feeling among those who remember when 7-bit ASCII (or EBCDIC) was all one got, or enjoyed receiving digital documents from a European or US office, only to suffer through character set confusion.
Even if Unicode isn’t without its issues, it’s hard not to look back and feel that at the very least it’s a decent improvement on what came before. Here’s to another thirty years of Unicode.
(header image: Punch card with the western alphabet encoded in EBCDIC)














A few corrections/notes:
* KDE gets it’s UTF16 from Qt which used 16bit character representation that mirrored the kernel.
* .Net also mirrored the NT kernel use of UTF16 strings.
* The C++ language (not compilers specifically) has supported UTF32 since the C++11 spec was passed.
* UTF32 isn’t wasteful if most characters are in a different code page.
* Unicode allows you to compose characters out of multiple characters which can lead to some ̷w̷e̷i̷r̷d̷n̷e̷s̷s.
related topics: Unicode in cookies, in domain names, in passwords, & the secure, sane handling of those.
or something “simple” like string comparaison. Unicode is a good thing but not fun AT ALL if you have to deal with it while writing code. In the Camelbook (Perl5) there is quite a lot of stuff about this.
Also Unicode might be “universal” but quite a few systems still don’t use it, at least thats what i guess looking at weird symbols on the recipt i got earlier today… Yeah…
Unicode is fundamentally broken and cannot be fixed. It will have to be replaced if we are ever to get out of Unicode hell.
One major issue is that Chinese, Japanese and Korea (CJK) support was botched, leading to low levels of adoption in those countries. The short version is that the designers tried to combine all three languages, and it didn’t work. For example airlines can’t rely on Unicode to properly render passenger names. Mixing C/J/K in a single document is impossible without metadata and special language specific fonts.
Oh, and yes that means that a single Unicode font that covers all language can never exist either.
The string handling issues you mention are another example of a problem that could easily have been avoided. It’s not just strings though, there are problems with special characters like direction indicators that have been used to hide malware.
Unfortunately there is a lot of inertia now, and things will probably remain broken for the foreseable future.
warning: layman question ahead:
…do you think it would help if you simplified unicode to only the graphemes, then created a series of language tables(or whatever the proper term is) for individual character sets/languages, then allowed fonts to chose the languages they wanted to support, supplying the proper characters based upon those tables? It might also make it easier for the computer to store custom fonts as combinations of graphemes
If you supplied a default ‘universal’ font that the system could fall back on when the character in question wasn’t supported by a particular font, that might act as a fallback to make things more functional for incomplete fonts.
I don’t really know what I’m talking about of course, so take this with a grain of salt, lol.
Each font contains whatever characters its developer wants to support. There is no requirement that all fonts have all characters, or any specific subset of them. Characters that are not included in a font just aren’t rendered, or depending on the application, may be represented by a hex code.
This reminds me of Tim Scott’s video on datetime handling: https://youtu.be/-5wpm-gesOY
His video on UTF-8 is also great! https://youtu.be/MijmeoH9LT4
Thank you
Re the last point, note that the preceding (and somewhat horrendous) attempt at a universal way of representing text (that’s not mentioned at all in this article for some reason), ISO 2022 aka ECMA-35, also did that, although in the opposite way (composing characters before base ones, like the “dead keys” method of typing diacritics on many Western European keyboard layouts). Given that one-to-one mapping of codepoints from legacy encodings was an explicit goal of Unicode, I’m not sure they could’ve solved that any better.
Even if we forget about legacy problems, already for the Latin alphabet precomposing all the letters needed for, say, Thai would hardly be better, and input methods would still need tables that describe how to tuck such-and-such diacritic onto such-and-such base (possibly already bearing some diacritics).
And we in the Latin/Cyrillic/Greek-writing world just have it ridiculously easy, objectively speaking, except for the bizarre affectation that is letter case. You simply can’t render Arabic or Malayalam character by character at all. Hell, the Unicode people had to completely throw out their initial attempt at Hangul (the Korean syllabary) and redo it from scratch, and it’s not like it’s a complicated writing system. That’s why the modern font stack (Freetype, Harfbuzz, et al.) is such a hot mess: the problem domain is much more complicated than it seems from the narrow Latin-using perch (even if it’s pretty cozy there).
I work on a game engine that renders text using Freetype and whatever fonts the person using the engine wants to use. Even figuring out how to do font fallback (that is, picking the right font to use if the primary font doesn’t include a character for a particular unicode code point) is something that proved to be impossible, let alone trying to render complex languages (although no-one has asked for any character support beyond stuff like Cyrillic that just draw each character individually so I think our current renderer should be good)
I don’t know how to do font fallback, but then I’ve never seen font fallback of typographical quality above “better than question marks”. Especially in a single-player game, where most of the text is known in advance, it might not be that important, I don’t know.
As for complex scripts, you’re having problems because FreeType is the wrong tool for the job: it doesn’t do font shaping (which is the term for most of what you’re trying to do), it only maps font files and glyph numbers (not necessarily codepoints) to vector outlines, that’s it. You either need to use a complete text rendering library like Pango (large and pulls in GLib, but can use native font shaping on Windows and macOS) or libraqm (seems lighter, but I haven’t heard of it much), or you can assemble the pipeline yourself from FriBidi (or ICU), HarfBuzz and FreeType (roughly: use FriBidi to segment text into single-direction chunks and figure out their order, then HarfBuzz to map codepoints to glyphs and positions, then FreeType to map glyphs to outlines and hint them, then your 2D renderer to display the result), though then you’ll still be out a line-breaking algorithm; for the latter approach there’s an example starting from the HarfBuzz stage on the HarfBuzz GitHub page and it’s not that complicated. See also: .
And yes, Cyrillic is even easier than Latin (simply because there’s less languages using it and so less cruft), with one exception: Bulgarian tranditionally uses slightly different shapes for some letters than most other Cyrillic-using languages, so technically you need to know which language you’re rendering and tell your font library to use the corresponding OpenType “locl” tables. Twitter misdetected some Russian tweets as Bulgarian a couple months ago (setting the HTML lang attribute accordingly), and let me tell you, they looked extremely funny (though Russians loudly wondering why their tweets looked weird was admittedly funnier). In principle the same also applies to Latin, as proper rendering of diacritics for Polish is different than for other languages , but the difference is much more subtle and not recognized in most fonts.
And therein lies my objection to so-called UTF-16: there are many applications and libraries that claim to do Unicode, in the form of UTF-16. However. Just as UTF-8 has a mechanism for encoding ALL valid Unicode code points, so does UTF-16. The difference is that many implementations of UTF-16 don’t include this mechanism. They just treat all characters as 16 bit.
Computerphile made a fantastic video about 7 years ago featuring Tom Scott about Unicode, it’s a must see about the topic:
http://youtube.com/watch?v=MijmeoH9LT4
“International Morse Code ultimately becoming the international standard (except for the US, which kept using American Morse Code” )
We´re there again with metric system.
You may have a point about Morse, but if you look at Unicode, it is basically the polar opposite of the metric system: instead of getting everyone to agree to use the same set of characters, we declare all character sets to be “standard”. All tens of thousands of them. I’m not saying this is a bad thing; before Unicode the world was saying, “if you want to use computers, you have to give up your customary written language.”
Which is an argument I hadn’t thought about before: the metric system is evil because it is eurocentric and destroyed the cultural measurement heritage of most of the world.
(Blowing on the flame before it spreads)
No. There’s a difference between character sets and scripts. Character sets are subject to engineering; while it’s possible to imagine a point in computing history where we’re stuck with a certain character set beyond any hope of change, we’re not (yet?) at that point. Scripts are subject to linguistics; you can’t get everybody to use the same script and you don’t really want to. Character sets don’t have to be memorable or human-friendly, but must be unambiguous; scripts are the other way around. (I can’t help but be reminded about Zooko’s triangle here.)
Script changes, often mandated by governments, did happen in some places—elimination of hiragana cursive in Meiji Japan, Arabic characters in Atatürk’s Turkey, Fraktur and Kurrent in Nazi Germany, Han characters in modern South Korea, whatever the copulation was done to various Near East languages under Soviet rule—but the result was that people were cut off from much of their literature; think the Latin–German–French–English language transition in 19th to 20th century scientific writing, only instead of Einstein’s or Schrödinger’s old papers, you can’t read your own grandmother’s correspondence.
Basically, unless you can solve Babel altogether, you are not unifying scripts any time soon. (Unless you can republish all historical literature in the new orthography, in which case you’ve eliminated copyright and are already a hero in my book.)
The comparison with measures is interesting when taken seriously, by the way. The difference, I think, is that most things expressed with measures are extremely transient, so the benefit of switching overcomes the drawback of losing access to historical material. Literature has much more lasting value, and at the same time the unconscious way writing is handled by our brain makes transitions much more painful. I can and do convert things to k = c = ħ = 1 electronvolt units without substantially lengthening my calculations, but like hell I’m going to read English written in hiragana even if I happen to know it.
“the metric system is evil because it is eurocentric and destroyed the cultural measurement heritage of most of the world.”
Um, okay.. I just know that here in Germany, we had tons (pun intended) of measurements in the past. Way too many, actual. And they differed in each village, not to speak of the many incompatible currencies and dialects. In these days we also used pound (Pfund), a dozen (ein Dutzend, 12) and so on. Both of them are/were used at meat counter still, even though the metric system became well established in the mean time. We also nolonger use acre (Morgen, not to be confused with the meaning of morning). So I guess I could also argue that we “lost” some of our heritage, despite being located so close to the heart of Europe. So even if we did, we gained a lot in exchange. In the daily life, we overcame many barriers that way. And in fairy tales, the old measurements still live on, also.
That being said, I’m speaking under correction here. I’m too young perhaps to remember the daily life before the metric system. :)
If you missed my tongue-in-cheek humor, my point wasn’t really that the metric system is bad, but that just as we had myriad different measurement systems, we also have myriad languages. Everybody is on board with throwing out all of the old measurement systems, but if you suggest throwing out all but an “agreed upon” language (as was done for measurement), there would be a huge outcry against this, as some form of ethnocide. Let me be clear, though: I DO support standardized measurement, I am NOT for expunging all but one standard language.
It’s just similar situations, with far different cultural repercussions.
Oh, I see. Makes sense to me now. My apologies for the long reply then and thank you very much for your response. English is not my native language, so I apparently wasn’t able to read between the lines in this case. 😅
Difference between American Morse (lol real Morse) and international is a bit more subtle than that. US was mostly land line telegraphy and as such did not suffer from interference much. Because of this, the dot-heavy American Morse was actually about 15% (IIRC) faster to send than equivalent international Morse.
But international, they tell me, is better for wireless when conditions are less than perfect. So it compromises speed for clarity.
From reading up on it a lot, it seems most US telegraphers rather easily picked up International easily and were fluent in both as needed. So it’s a bit disingenuous to say they refused- not only did they learn the newer International, they continued to use an arguably “better” (for their use case) American Morse.
I have used both International Morse (US Navy and ham radio CW) and American Morse (MorseKOB system), and chatting with an old railroad lightning slinger he told me that he couldn’t get used to International Morse – “too many dahs”… Here’s an example of some American Morse I put up: https://youtu.be/J2UzXz-adLg
I was just reading about this two days ago. I can honestly say that I prefer utf-32, because it’s 4 bytes for every character. Utf-8 as current most common standard just feels wrong, with variable width characters.
This is why some programming languages use utf-32 internally.
UTF-8 isn’t “wrong”, it is just a backwards-compatible format, because any pure-ASCII text is also an UTF-8 correct text.
Also, with UTF-8, all the string functions in C work fine without modification, while for UTF-16 and 32 they would require modifications.
Yes, they “work”, if you don’t care about things like strlen() counting the actual number of characters in a string.
Yes, strlen() and any function that depends on the character size won’t work, but that happens also with UTF-16 and UTF-32. But everything else, evne word sorting for example, works fine, thanks to the way UTF-8 works.
So I think that it is better to only have to reimplement only a small subset of the srtXXX functions than all of them.
While I agree with your sentiment in general (see a sibling comment to yours), the particular example of character counting seems unfortunate to me, because the notion of “characters” is not particularly useful, in any of its possible interpretations, without more extensive facilities for text handling, and at that point the particular internal encoding you’re using is the least of your worries.
Imagine you’re handling a text in Korean, for example. The script in question (Hangul) is not at all complicated (I shudder to think what the Arabic-speaking people must have to deal with), but still you might want to consider:
– Letters, which are what most closely corresponds to individual vowels and consonants of the language, also used for sorting,
– Syllables, which pack the letters in two dimensions into boxes of standard size, to align nicely with interleaved Han characterss,
– Unicode codepoints, which might correspond to the former or to the latter,
– Grid positions for a monospace font, of which two per syllable are consumed, but any embedded Latin text is usually single-width.
Oh, also, Korean is sometimes written vertically, and ruby text (Hangul glosses for Han characters, positioned above them) exists. But I can’t even say off the top of my head whether Unicode text segmentation uses or backspace on Korean keyboards deletes letters or syllables; neither can you, and that’s the point. None of those are of any use without carnal knowledge of UnicodeData.txt and possibly the input methods or fonts of the specific platform. So counting “characters” is mostly a red herring in the Unicode world, I think.
I only used character counting as the most obvious place where UTF-8 may not crash, but it certainly doesn’t work, at least in C. But language is messy, and I try not to mess with it. Which is why I use monospaced fonts wherever possible. For example, many, MANY fonts break applications that are just trying to keep numbers lined up in columns, for freak’s sake, because idiots.
But you can’t even count on monospaced fonts, because these also break when you have Unicode characters (or whatever you call them) that don’t take up any space, because they’re used to build characters from something like glyphs.
@BrightBlueJim, short answer (the site keeps eating my comments, argh):
Half a billion people use Arabic script, which is bidirectional (not RTL, numerals and embedded Latin are still LTR). Half a billion more use Devanagari, which is impossible to typeset without the epitome of invisible characters that is ZWJ / ZWNJ. Finally, a billion and a half use Han characters, which is unreadable in tall rectangular boxes, usually double-width and so requires at least wcwidth (hello, East_Asian_Width = Ambiguous). Monospace doesn’t work, it just appears to (on European languages) only to silently break (on others), which is the worst kind of breakage.
Competent font designers (who are not idiots) explicitly cater for aligning figures in columns, but also know that proportional figures look better in running text. Use U+2212 MINUS (&minusl) because no, ASCII, it’s not a hyphen. Use U+2007 FIGURE SPACE ( ) because an interword space is usually too narrow. Most importantly, use the OpenType tabular figures feature (tnum), because tabular figures aren’t guaranteed to be the default and increasingly aren’t. All of these distinctions are literally older than digital computing, and your text entry environment should recognize them or die.
Yeah. Like I said. Language is messy. I don’t need to accommodate 8 billion people’s needs.
They work for a pretty dubious value of “work”, unfortunately. You can handle zero-terminated blocks of memory pretty well, but you can’t do most meaningful text handling—you can’t even compare strings correctly (up to canonical equivalence) and reliably (locales, blech). Which is not to disparage UTF-8: it is indeed the least awful way to include useful Unicode processing without drastically changing how string processing is traditionally done in C. It’s just that text processing is still impossible in standard C and miserable in real-world C.
Point me to a non-bloated Unicode handling library for C that does character categories, normalization, grapheme clustering, and text segmentation (that being the bare minimum for a text editor, I haven’t even mentioned backspace), and I’ll sing you praises for a long, long time. Bonus points for integrating with system locales using encodings other than UTF-8, or perhaps even handling the Windows OEM vs. ANSI mess.
utf-8 just feels right :) . Or should I say the ASCII 7-bit code. Unicode just complicates things. Luckily programming in C and assembly I don’t have to deal with it. But, alas, I do in Python and have to use .decode and .encode which just adds ‘verbiage’ … when the baggage is really not needed. I remember when Delphi introduced it for strings.. Grrrr. Broke code for no reason.
I’ve never heard of anything using UTF-32 internally let alone a programming language. Everyone seems to stick with UTF-16 internally and UTF-8 publicly. Do you have any examples of UTF-32 being used to great extent?
CPython, for one. The modern implementation is a bit more complicated (it chooses the narrowest possible representation in UCS-{1,2,4} for every individual string), but the addition of UCS-2 (not UTF-16!) as a space optimization is a relatively recent addition IIRC. Lua can’t do proper Unicode because it’s limited to ANSI C library interfaces and JavaScript has UTF-16 leaking from the spec, but maybe mainline Ruby as well, I’m not sure.
Also almost any C program that uses a compliant (read: non-Windows) Unicode (read: non-Solaris, I think?) wchar_t. But there aren’t many of those as far as I know.
The Unix people seem to have standardized on using UTF-8 internally as well as externally, aside from the relatively isolated (and legacy-bound) worlds of Qt and ICU; one example of this ideology implemented consistently (by the people who invented UTF-8 in the first place) is the Go language, which got that from the Plan 9 system.
To me, UTF-16 as an internal encoding signifies that I’m probably dealing with something that is bound to one of Win32, Objective-C, Java, JavaScript, or ICU (exposing the fact that I’ve never had to seriously use Qt); it’s not “everyone” (even if it’s a pretty large amount of people). And if compatibility considerations are set aside (and you can more easily do that for an internal representation), I frankly just don’t see what technical arguments could drive me to UTF-16, specifically, and not UTF-8 or UTF-32/UCS-4.
Thank you Alex.
https://en.m.wikipedia.org/wiki/UTF-32
under Use.
UTF-8 is fine, if you think of it as a quick and dirty compression scheme for UTF-32. It is pretty easy to convert either one to the other. You’re pretty much forced to convert to UTF-32 internally, if you’re doing anything that has to treat characters as atoms.
For example, if what you need is to have all of the text in an application in many languages, but you only care about these as whole texts, UTF-8 is great, because it takes less space for more commonly-used characters, but if you actually need to render characters onto a raster, UTF-32 is better because [most] characters then translate into independent glyphs. Language complicates everything.
In the 80’s / 90’s spent many happy hours with EBCDIC / ASCII code pages trying to get text files sent back and forth between IBM mainframes and ASCII platforms in different countries. The worst were currency signs, we even tried adding the SI currency abbreviation / code to text files to limit ant misunderstanding. Hand coding translate tables / lookup tables kept me out of trouble for an hour or two each time a new country / platform appeared.
I wrote my translator in ‘C’ for translation on the fly from EBCDIC to ASCII, it was one of the shortest and ugliest programs I ever wrote, basically a lookup table that only looked for ASCII equivalents and ignored everything else. What I was doing was taking input to a printer and porting it into a PC, and there was no need to find or translate special characters and such. That was in the 80s, and I think my old com[any is still using it.
In IBM assembler (at least from System 360 through System 390), there is a single machine instruction, named TR, that will translate a block of memory at a time, given a 256-byte table of substitution values. I often used it to translate between ASCII and EBCDIC back in the day. Very useful for reading tapes written on a VAX or similar when you needed to process the data on an IBM mainframe. Or for writing tapes to be used by a non-blue computer.
If I could have used assembly, I would have, but I was basically presented with this scenario.
A daily report was sent from an older IBM based system to a Teletype DataSpeed 40 printer, in EBCDIC. A clerk was assigned to take the greenbar printouts and type the relevant data into a PC in Lotus for processing with dBase and porting back to 123 for a final scrub and formatting and then publication. The clerk had never been trained in using 123 and did not know that the program would do the math for her, and as a matter of fact someone had written a script where all she had to do was enter the figures, but never told her how to run the script, so she sat there with a calculator dutifully doing the math, for several hours each day, and even typing in the totals.
So, I had to do two things, find an electrical interface that would take the “Standard Serial Interface” output to the printer and convert it to RS-232 serial interface to input to the PC. That part was easy.
And I had to write a program in the PC to take the raw hex and extract the data we needed. I did that in two steps; I did the translation from EBCDIC (in hex) to ASCII (in hex) and output it into 123, where a script scrubbed out the data we did not need and output the final result for use in dBase and 123.
Eventually we switched to Excel and Informix SQL as both were easier to use.
And I pretty much worked myself out of a job. I even automated the report distribution.
I also had to translate EBCDIC/ASCII for some communication programs I wrote, and that included special characters. That’s when I discovered there were three different EBCDIC character sets in the documentation I was given.
That introduced me to the first of many lessons on text assumptions.
I once fielded a call from an elderly woman who was very offended that we printed MS SMITH on her receipt. “My husband passed away, but my name is still MRS SMITH!” Took some head scratching to realize her initials were M.S. but American Express has encoded them as MS on her card’s mag stripe.
That job laid the foundations for many hard lessons like “you can’t assume anything about names” and “duck typing is not just a lazy coder’s shortcut, but is downright dangerous.”
If we cannot fit the building blocks of language into 64,535 characters, the human race has a problem. We should instead be working to condense and simplify our language and find redundancies.
Read about https://en.wikipedia.org/wiki/Han_unification
and then cry
(TL;DR : there was a genuinely herculean effort to try to fit everything into 16 bits. The results are really bad.)
But the previous ones are still in scope as historic languages then, so no improvement. (And how would you represent characters in translation guides?) I’m pretty sure traditional Chinese has something on that order of characters just for itself, before any other languages. Also, people don’t really like it when you take away their language for simplification reasons: language is closely bound with culture. Anyway, that ship has sailed years ago.
Except that that’s not remotely the goal of Unicode, nor should it be. The effort being undertaken is to be able to encode texts in their own scripts, not to “condense and simplify” language itself.
(And condensed and simplified by whose standards, by the bye? Should you be writing your English messages in katakana?)
If you’re the kind of person who’d be comfortable with your own language and script — and not just the languages and scripts of other people — being abstracted away, I commend you to Lojban.
You would still need to retain all the historical code points, so this would be a pointless exercise really.
The wide variety of languages and alphabets and glyphs is good, I would not want to erase that.
For the common in-use characters we have UTF-16 – which does have a problem with emoji and using two characters for these, except you can’t tell when looking at the character if it’s the first or second. UTF-8 fixes all of this, is naturally compressed for alphabet based scripts, but does have the indexed character lookup problem.
I remember having to deal with UCS2 in the past. It’s used in SMS if there’s a single exotic character in the message (halving message length).
UTF-8 can have up to 6 bytes per character IIRC, but most implementations stop off at 4 (UTF8-mb4 is the MySQL column type). I’m not sure if any codepoints beyond the 22-bits encoded in the 4 byte UTF-8 range has ever been allocated.
No, because they can’t be encoded in UTF16, so unicode as a whole has been bounded to the same 17*2^(16) max encoded size.
“UTF-8 can have up to 6 bytes per character IIRC, but most implementations stop off at 4 (UTF8-mb4 is the MySQL column type).”
Which is utterly insane. The amount of extra code it takes to handle the extra two bytes is miniscule, so they save practically nothing, and pretty much guarantee that their code will break when many of those code points are eventually assigned.
Punch cards use Hollerith code, not EBCDIC.
What I came here to say. Not even the weakest correlation between the two.
There’s a strong correlation between the way letters are handled between the two! EBCDIC, like Hollerith, divides the 26 letters into three groups of nine each. Except that there’s an unused gap between R and S. Why? Look at the punched card. They didn’t want the S to have two adjacent holes punched, as it could compromise the structural integrity of the card.
Hmm, but then it seems they threw that rule away when encoding the symbols. I guess they just expected many fewer symbols than S’s.
I understand that about Hollerith. Look at the EBCDIC table: nothing like that.
Actual EBCDIC code: http://ferretronix.com/march/computer_cards/ebcdic_table.jpg
First time that was posted public, IBM armed a posse with Winchesters to find the mole…. fortunately he was able to elude them by maintaining a fast walk, because they were struggling to carry them at anything better than a fast shuffle between two dudes.
Things are going to get even more complicated when the Federation is established and they have to add Vulcan, Andorian Tellurite, etc. Of course, they’ve already declined to add Klingon – but then they’re not in the Federation, the Khitomer Accords notwithstanding.
This flame war raged in the 1990ies. Please choose a new one (how ’bout Wayland ;-)
That war ended in a truce, mainly due to Ken Thompson’s clever contribution, UTF-8, which allowed most users to pretend Unicode didn’t exist.
Also, not biting on your Wayland bait. Couldn’t care much less.
The major problem with unicode is memory leaks and the risk it causes for anything but “apps” and games. There’s a reason why things like TCP/IP stack or MINIX kernel are written with plain ANSI C.
Hm. Seems to me, like blaming Unicode for memory leaks is like blaming auto makers for medical malpractice. You do realize, many programs that support Unicode text are written in C, right?
And also that a GREAT many memory leaks come from programs written in C. Just sayin’.
Very cool! I taught Protocols and Protocol Analysis, along with other data communications subjects, at Bellcore in the 90s, and although we concentrated on ASCII and EBCDIC, we did “start at the beginning” with smoke signals and flags, and featured an hour or so on Unicode.
Thanks for the trip down memory lane.
Young people today have no idea how good they have it now….
I worked as a translator and technical editor for a linguistic scholarly publication in late nineties. Authors in my language alone could use three different code pages. Add to this several other languages and scientific symbols and a DTP package where you had to make most modifications in definitely non-WYSIWYG quasi-code text… A single error in the coding could make all special characters for a given language to be incorrect – but usually only the author would know (or us, if we scanned the prinouts character by character). If you had a two-word correction, you had to save it to a file and add as a zip attachment, because if you sent it in the body of the email it could arrive with characters quite different than what intended. Shoebox? Luxury!
Great writeup! I’d like to highlight the GNU Unifont project by Roman Czyborra and Paul Hardy — https://en.wikipedia.org/wiki/GNU_Unifont. I’ve used this from time to time over the years as a reference, as a source of bitmapped fonts, and for the simple text-based command line glyph manipulation tools.
The 5-Bit Baudot-Murray Code (ITA-2, 7-Bit with start/stop actually) is still alive in Amateur Radio and maritime weather forecast services (not to be confused with Navtex). For some reasons, Baudot outlived the 7-Bit ASCII in the realms of Amateur Radio RTTY.. There are many DIY projects related to RTTY decoders based on Arduinos, PICs etc. :)
“with International Morse Code ultimately becoming the international standard (except for the US, which kept using American Morse Code outside of radiotelegraphy) since its invention in Germany in 1848.”
There’s also that legend that the radio amateur’s “HI HI” (laughing) was a translation error. Originally, it meant to say “HO HO” (like Santa’s laughing), but because of the differences in wired morse (US continental) and modern wireless morse, the fine facettes of dih/dah/dash in continental morse were lost. Sorry, I don’t know how to describe it properly. I’m no native English speaker.
Except that modern digital modes all seem to use ASCII, and don’t support Baudot-like codes at all.
@Joshua said: “For some reasons, Baudot outlived the 7-Bit ASCII in the realms of Amateur Radio RTTY.”
The reason is that when 5-bit teleprinters fell into the surplus equipment realm, amateur radio operators happily snapped them up and nursed them along – forever. Back then a mechanical teleprinter was a very expensive device in the commercial market. Today of course making an electronic teleprinter of any type is inexpensive, and not very difficult.
That may have been a valid argument in the 1970s and early 80s, but since then, terminals that speak 7-bit ASCII have been far more available, and far cheaper. Today, I would venture to guess that even among those hams still using Baudot or other 5-bit codes, the vast majority are using electronic devices rather than teleprinters.
And who cares about lower case, anyway?
UTF is not the implementation, UTF is only the encoding of code points into a sequences of code units, for UTF-8 a code unit is a byte.
A Unicode implementation is a lot more than that, it will also handle things like sorting, casing, or word or line breaking rules.
UTF-X only deals with storing code points.
In the early days of piezoelectric dot matrix printers (https://en.wikipedia.org/wiki/Dot_matrix_printing), there was a small industry of replacing the original ASCII code table with some European code table. This was dome by replacing the original ROM DIP chip with an EEPROM containing the new code table.
I did that myself with some inexpensive dot-matrix printers, including some Epson models. But it was mostly to implement the APL character set without having to download a user-defined font every time the printer was turned on. And there were some we did for the University of Toronto Theology department for printing Ancient Greek texts.
The trick was in finding where in the original ROM the character set was stored. The format for user defined characters sets was the key – work out the pattern for an upper-case A, look for it in the ROM, and you had your starting point.
We had an IBM dot matrix color printer that was “Epson Compatible” but when the software drew a circle, it came out an oval. I disassembled the code and found where the aspect ratio was getting screwed up, dumped my correction to an Eprom burner where I worked (the printer’s original would not take he change) and swapped it out. Problem solved.
The IBM had a 9 pin print head, instead of 8.
If only I could add unicode support on my trusty old Blackberry phone beyond the few emoticons it got (I got a lot of black squares when people send me unicode chars/emojis)