
A research paper from Dalian University of Technology in China and City University of Hong Kong (direct PDF link) outlines a system that automatically generates comic books from videos. But how can an algorithm boil down video scenes to appropriately reflect the gravity of the scene in a still image? This impressive feat is accomplished by saving two still images per second, then segments the frames into scenes through analysis of region-of-interest and importance ranking.
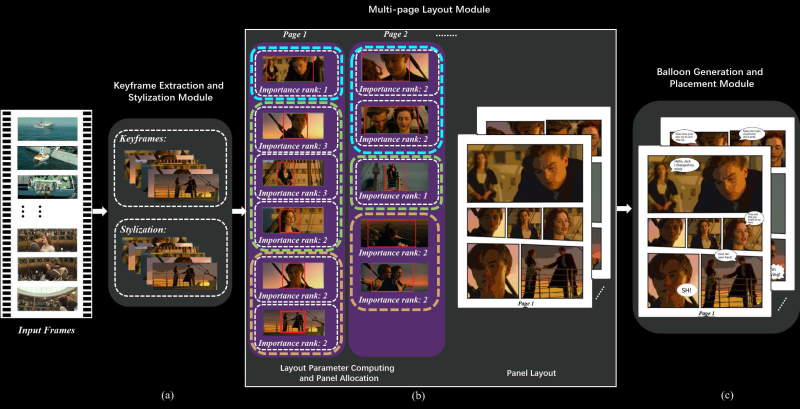
For its next trick, speech for each scene is processed by combining subtitle information with the audio track of the video. The audio is analyzed for emotion to determine the appropriate speech bubble type and size of the subtitle text. Frames are even analyzed to establish which person is speaking for proper placement of the bubbles. It can then create layouts of the keyframes, determining panel sizes for each page based on the region-of-interest analysis.
The process is completed by stylizing the keyframes with flat color through quantization, for that classic cel shading look, and then populating the layouts with each frame and word balloon.
The team conducted a study with 40 users, pitting their results against previous techniques which require more human intervention and still besting them in every measure. Like any great superhero, the team still sees room for improvement. In the future, they would like to improve the accuracy of keyframe selection and propose using a neural network to do so.
Thanks to [Qes] for the tip!














I could do without the posterize effect, but the layout and frame selection is incredible.
I could see this being used for meme generation.
I was wondering if there might be a neural style transfer technique that would be better. I don’t think there are, but certainly there should be some much better filters that could be used, à la “A Scanner Darkly” (2006)
The visuals from A Scanner Darkly would be rather difficult to recreate, as it wasn’t a filter.
Filmed frames were handed off to animators who rotoscoped every other frame and then a proprietary frame interpolation program (which, IIRC, was either developed for A Scanner Darkly or Waking Life) filled in the other 50% of the frames.
(I got some interesting details on A Scanner Darkly when I met Golden Army Trio, who did the soundtrack, at a concert which was improperly booked. I was the only person who showed up and they were kind enough to chat with me for a bit before packing up.)
I’m not sure how well ML methods could recreate it, but it’d be interesting to see.
maybe the posterize is to increase compressibility as much as possible.
This is impressive
Imagine using it for personal movies from your phone.
This is really impressive and could give another outlook on well known movies.
Might liven up a Zoom call.
Sounds like Microsoft Comic Chat on steroids.
but speech bubbles shall have comic sans everywhere.
There are plenty of action sequences with minimal speech, and a tendency to shake the camera (shaky cam) along with rapid editing of viewpoint. Several “Jason Bourne” action sequences are shot in this style.
Rapid cut scenes are similar to a stroboscope, and can be a problem for people with photosensitive epilepsy.
A paper reproduction of the scene might help people who find these scenes confusing, nauseating, or dangerous.
I think the description of “research paper” is a bit strong. One, the paper is not peer reviewed. Two, at whopping 19 pages this “research paper” is very light on actual specifics and data. It seems to be a lot hand waiving and resting only a few short examples that seem to demonstrate it works but could have just as easily been faked or cherry picked.
While I have some experience in AI/ML, my actual expertise is in electromagnetics, this “research paper” really does not seem any where on par with traditional academic research papers.
I am very skeptical as to how valid this paper actually is.
Hello – I would like to get in touch with the CEO or Director of this company. I own several films as well as a comic book company. I am interested in getting to know more and prices. Thank you.