
You’ve got a perfectly working software library to do just exactly what you want. Why aren’t you using it? Some of you are already yelling something about NIH syndrome or reinventing the wheel — I hear you. But at least sometimes, there’s a good enough reason to reinvent the wheel: let’s say you want to learn something.
Mike and I were talking about a cool hack on the podcast: a library that makes a floppy drive work with an Arduino, and even builds out a minimalistic DOS for it. The one thing that [David Hansel] didn’t do by himself was write the FAT library; he used the ever-popular FatFS by [Elm-ChaN]. Mike casually noted that he’s always wanted to write his own FAT library from scratch, just to learn how it works at the fundamental level, and I didn’t even bat an eyelash. Heck, if I had the time, I’d want to do that too!
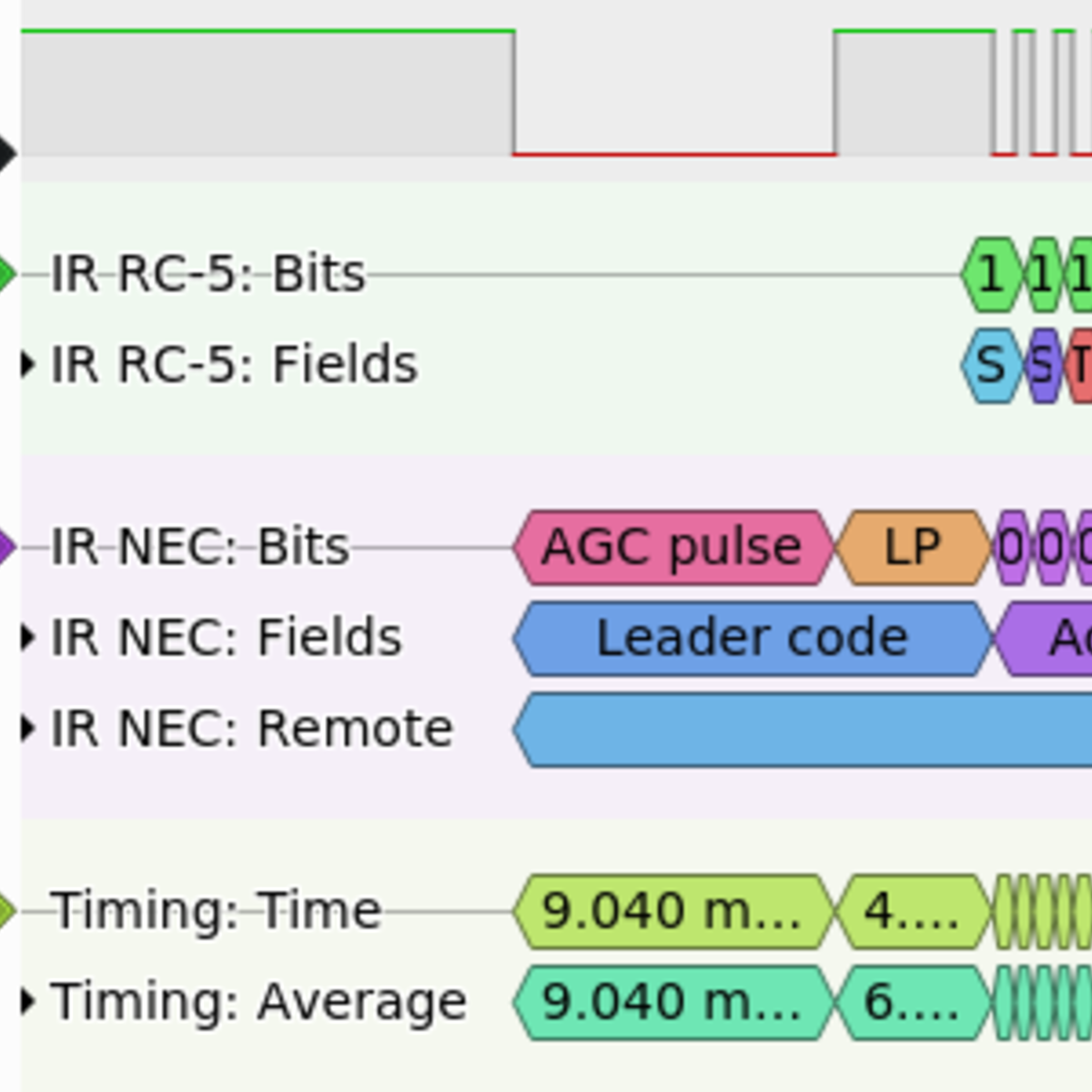 Look around on Hackaday, and you’ll see tons of hacks where people reinvent the wheel. In this superb soundbar hack, [Michal] spends a while working on the IR protocol by hand until succumbing to the call of IRMP, a library that has it all done for you. But if you read his writeup, he’s not sad; he learned something about IR protocols. This I2C paper tape reader is nothing if not a reinvention of the I2C wheel, but isn’t that the best way to learn?
Look around on Hackaday, and you’ll see tons of hacks where people reinvent the wheel. In this superb soundbar hack, [Michal] spends a while working on the IR protocol by hand until succumbing to the call of IRMP, a library that has it all done for you. But if you read his writeup, he’s not sad; he learned something about IR protocols. This I2C paper tape reader is nothing if not a reinvention of the I2C wheel, but isn’t that the best way to learn?
Yes it is. Think back to the last class you took. The teacher or professor certainly explained something to you in reasonable detail — that’s the job after all. And then you got some homework to do by yourself, and you did it, even though you were probably just going over the same stuff that the prof and countless others have gone through. But by doing it yourself, even though it was “reinventing the wheel”, you learned the material. And I’d wager that you wouldn’t have learned it without.
Of course, when the chips are down and the deadline is breathing hot down your neck, that might be the right time to just include that tried-and-true library. But if you really want to learn something yourself, you have every right to reinvent the wheel.














And do not forget that , sometimes, that wheel looks like a hexagon, and with some thinking and work, one can devise a better, rounder one.
In the venue of the article and code libraries, just because there is a library wouldn´t mean it is written in the best way. One may need to reduce size, complexity, etc, and so reinventing it may be necessary.
Hexagons are the bestagons
Yes!
Tabletop gamers know this to be true.
Very true. There’s an Arduino library (or three) for just about everything, but the quality is… variable. I find myself rewriting things myself with modern conventions and tests, so that I’m confident they work. Debugging poorly-structured libraries written like it’s the 90s is painful.
Re-inventing the wheel is the best way to learn about wheels.
Reinventing humanity is the best way to…
This is also true, and it’s what the human genome project is all about. Imagine when we start coding human DNA. I’m sure there will be libraries for eyes and noses and other body parts, even for the garbage that holds it all together. Then some people will want to go in and code a human all by hand from scratch.
And then they will, patent that “human” and market them as slaves or soldiers,.
And then realize they reinvented Philip K. Dick’s science fiction….
It would be easier and more profitable just to charge all the existing humans a licensing fee for using their own DNA. You know the drill: “If you don’t agree with our terms and conditions, you must immediately cease using DNA sequences covered by our patents.”
“Re-inventing the wheel is the best way to learn about wheels.” Hmmm. That is quite a claim. Wouldn’t inventing the wheel tell you that wheels suck without bearings and balance and strong materials and light weight and an understanding of friction? You are likely to wind up with a child’s toy and continue to use your wife as a draft animal dragging a couple of sticks.
“She great woman! Strong like bull!”
-Uncle Tanous
I almost always reinvent the wheel. That is because it is all about the journey and not the destination. For me. If it was about the finished project I would use short cuts such as existing libraries. Maybe even some prefab IDE, but probably not.
But it is really about what you enjoy spending your time doing. My goal is usually understanding all about what makes it work, not just making it work.
Sometimes I want to just get something done — and then I just buy a decent product and get on with life.
“What I cannot create I do not understand” – Feynmann
THIS
Excellent.
Indeed.
“If you want to make an apple pie from scratch…”
-Carl Sagan
for each project i always struggle with how much of the wheel to reinvent. like now i’m reinventing audacity. i feel pretty solid about that decision. but for the UI, do i want to reinvent SDL 1.2 and use libX11 directly? it’s a struggle.
for a lot of modern stuff (say, newer than SDL 1.2), i feel pretty good about reinventing the wheel. a lot of times if i’m frustrated with a library’s interface then when i look under the covers i see wrappers around wrappers around wrappers. endless sophistication to achieve simple results. so many libraries these days spawn a bunch of threads simply to avoid exposing a good interface to developers. you get two or three of those wrapped around eachother and you wind up with a single event that gets passed through 5 different semaphores in 5 different threads before it gets to you, and because of the kind of interface it is, you have no choice but to send it through another semaphore! if they could admit they mandated pthreads then the innermost layer could have just exposed its semaphore and i could have sem_wait()ed on that. but they want to pretend it’s an asynchronous event coming in to a callback magically from nowhere without defining the thread semantics of it, so we’ve got this nightmare.
but the real part that gets me comes down to Val’s feynmann quote. a lot of times not a single one of the layers is properly documented. if there’s no unnecessary wrappers then you can just read the code, and figure out what it does. but if you have a library that is undocumented, and it is just a wrapper, then you have to peel that back…and then the thing it wraps is not documented, and is itself just a wrapper, and you have to peel that back. you have to peel back 3 or 4 layers to find the code that does anything. unnecessary wrappers really increase the cost of poor documentation. so just to use the outermost library with any confidence, i have to peel so many layers of onion to figure out how it works…once i understand it, i really should reimplement it. i replaced tens of thousands of lines of code spread across multiple libraries with just a thousand lines that i wrote, and the advantage is, i can understand it.
+1
Yep. For sure
+1E5.
Here’s a hint: if you program your GUI using X11, you know how to make an application that runs in Linux or Unix. If you program your GUI using SDL, you know how to make an application that runs in Linux, Unix, MacOS, Windows, iOS, Android, and other programming environments. That’s just an example, though. I chose SDL2 because it only goes as far as finding a common environment that abstracts out all of the difference between systems. It’s kind of the “C” of user interfaces, in that it only abstracts as far as necessary to provide a common environment. And while I sometimes find myself wanting to re-invent C, I have an internal alarm that usually stops me. At one time (before SDL2 came out), I wrote a similar shim that made the three OSs I needed to work with (Windows, MacOS, and *nix) all look the same. Now I use SDL2, because OTHER PEOPLE are spending the time to maintain that. So when Apple comes out with a Retina display and does some weird scaling operation, _I_ don’t have to figure out how to work with it. As long as I’m not in a hurry. SDL2 still doesn’t seem to have that one quite right. Thanks, Apple.
Is this what you mean, or is there some other library with similar name ? http://www.libsdl.org
From the site/wiki, it seems it is mostly oriented at games ?
That’s the one I’m talking about. I rejected SDL 1.2, because it would only do one window, because it WAS designed specifically for doing games. But this didn’t even allow your program to create dialog windows, which was just not adequate. Sure, you can emulate dialogs by overlaying something on your one window, but that really IS reinventing the wheel. SDL2 is definitely suitable for writing any kind of application. https://www.libsdl.org/download-2.0.php
>that abstracts out all of the difference between systems
All of it? Like the different UI paradigms, screen shapes and resolutions….
I choose what I want to look like the platform’s customary way of doing things, and my own way. Look at what Firefox does: it does everything the Mozilla way, with the only platform-dependent things being things like file save dialogs. As for different screen shapes and resolutions, that’s not what I’m talking about. By “all look the same”, I mean that I can always use the same functions to determine what the screen dimensions are, and to resize my application’s windows.
oh yeah i agree if portability were a concern for this project i’d use SDL (or some other library). but i was just thinking about it, i’ve made probably a dozen programs that use SDL and not once have I run it on something other than xfree86/xorg and Linux. i’ve never even run it on a device that doesn’t support 24bpp. all of its generality is wasted on me. i do have some complaints about SDL but i am not denying its many valuable features!
but, you know, maybe someone can help me with this. i have only done a little digging (and the digging was frustratingly difficult, one of the strikes against SDL), but it seems like on linux it is very hard to get SDL2 not to try to use GL, even if there is no hardware accelerated driver. so while SDL1.2 would use X SHM for basically framebuffer-under-X, SDL2 would do the same trivial blitting operation but through MesaGL in such a way that it is dog slow if you don’t have the (often proprietary) hardware drivers. so in my experience, practically speaking, SDL2 actually runs well on a much smaller subset of platforms than SDL1.2 did.
but i don’t know if there’s a good way around that or not, i didn’t get to the bottom of it. and i’m curious about other opinions.
I have had uniformly poor results when using SDL 2’s preferred way of doing graphics – I think they bit off too much there. Sometimes it does strange things, and other times I just get nothing. The good news is, all of the 1.2 stuff is still there and still works, but you do get the 2.0 advantage of being able to open multiple windows.
@Greg A: Thanks.
Knowing when to “just use the library” and when to do it yourself is very hard, very important, and probably also very dependent on the project you’ve got, it’s timelines, and the state of the mythical library.
I usually find out halfway through the project that I should have done it the other way. :)
Heh. Heartbleed, for instance. “Oops, we used OpenSSL.” And that wasn’t even really the wrong decision for the affected software. Protip: do NOT roll your own encryption library.
Like you, Greg A, I don’t mind reinventing the high-level stuff, because sometimes that’s completely bloated, and not a good fit for my applications. Take Qt, for example. Yeah, they’ve already done everything for me, but writing a Qt application means subscribing to the Qt religion. Once you go down that path, you need a deprogrammer to ever get out. I don’t want a GUI toolkit that lays out my user interface for me, because I probably won’t like the way it arranges my controls and widgets. I DO want a toolkit that lets me use the same API, whether I’m writing for mobile devices or desktop machines.
I would probably write in assembler, if it weren’t for the fact that I would have to know a dozen different assembly languages, to handle targets from AVR and PIC and 8048 through x86, x64, PowerPC, 68k, ARM, and more. Which is why I write most things in C. Anything that’s beyond easy reach of BASH, gets done in C. So similarly, for user interfaces i want JUST ENOUGH abstraction to make all machines look the same.
” I don’t want a GUI toolkit that lays out my user interface for me, because I probably won’t like the way it arranges my controls and widgets.”
Writing for your desktop? Fine. Writing for everyone else? That’s what all those GUI guideline books are for. Look and feel.
Which would be a valid argument if Qt was following all those GUI guideline books.
Particularly aggravating is how Qt reinvents sockets. Idk, maybe they’re nicer than the old BSD model, if you get used to them. In my experience though, when your networking isn’t working, their wrappers just seem like more hindrance than help.
Definitely use Xlib. It’s a major fail of the Linux community to dissuade people from using this straightforward and perfectly good library. That’s the one thing that kept the Linux community from building quality desktop software and instead cursed the platform with slow, brittle bloatware. Xlib is simple and effective and unbelievably similar to WinAPI. You can write a wrapper for each platform in a few dozen lines and never have to worry about platform dependency.
HA! Yeah, sure you can. And spend the rest of your life dealing with edge cases. Don’t ask me how I know.
i agree with tetsuoii and BrightBlueJim!
i’ve used libX11 a few times and it’s not nearly as bad as its reputation. but also, it really doesn’t hide any edge cases from you…they’re in your face all the time. SDL1.2, for example, is easier to work with if all you want is a framebuffer. but also, if all you want is a framebuffer, it only takes a couple hundred lines of libX11 code to completely replace SDL (ask me what i did this weekend). so far, all my libX11-targetted programs are for myself so it hasn’t bothered me that i’m not sure how they’d work on other cromputers with other display drivers and window managers and so on. but i do have one libX11 program from 2007 that has worked effortlessly ever since. and another from 2003 that only has one flaw after all those years, the font library (Xft) has somehow drifted so all the fonts are scaled about 2x what they should be.
the few GUI programs i have written for other people have been javascript/HTML or java/Android. and those platforms have actually both given me a *lot* of trouble in terms of API drift and needless bugs from customization of local viewers. so i really think libX11’s acknowledged downsides are much less than the unacknowledged flaws in many of the supposedly portable / high level solutions.
fwiw i settled on xcb for this project. i’m pretty frustrated by its documentation but it’s easy to work with anyways. the thing that inspired me to avoid SDL turned out to be a non-issue so probably it was a mistake but the xcb part is 99% done and i’m happy with how it’s working.
@Greg A.
I completely agree with you. Things have been made unnecessarily complex by people out there. These days there are hardly any organizations not writing wrappers around core logic/features. This is precisely what sucks most of my energy and the intention to produce good and well-documented code.
Amen! I once had to dig all the way down to a hardware abstraction layer to discover that it was generating a fake PID by truncating the current value of the system clock. The e-mail application built on top of this abstraction layer was generating temporary file names based on the assumption that the PID was unique so not unsurprisingly, users periodically found themselves reading other people’s emails.
I often find that existing frameworks and libraries etc are very generalized. Sometimes I just want a very specialized case, and if it’s something easy to handle, it seems cleaner to roll an application specific implementation, than to wade through gobs of configuration steps in code, and/or messing with compile and link options. Nevermind when the 3rd party wants runtime .conf or .ini files.
And that is why I seriously hate C/C++. Messing with compile and link options to add a library shouldn’t be a thing.
The fact that it still is makes me think the devs don’t actually want you to use too many libraries and making it easy isn’t a priority.
Luckily it’s no trouble in Python and JS!
“I hate using apples to drive in nails, it’s much better to use a hammer”
Sure you have to know your compiler and linker, but that’s what it takes to build quality software, something only C can deliver. When the rubber hits the road, all other languages eat dust.
My philosophy has always been: Why re-invent the wheel, when you can steal a hubcap.
In more mundane terms: Copy the essence, not the product.
Because a hubcap does not make a very good wheel? You’re kind of arguing against your own point.
If everything in your project is a wheel, you might just have a pile of old tires.
Also, if you already chose your hubcap you probably now know exactly what wheel you need.
When something sounds wrong it often implies a lack of imagination. And of course, when something sounds just right it can also imply a lack of imagination; something I’m often reminded of when trying to use libraries in embedded programming.
What’s so bad about reinventing the wheel? You may discover the pneumatic tire.
I remember one of the pundit columnists (might have been Jeff Duntemann?) writing for Dr Dobbs Journal back in the 90s saying something like ‘If a program or library is not well-enough documented then a programmer will likely rewrite their own version’.
If more libraries were well-documented, I wouldn’t even have to try to read the code before deciding to roll my own!
If I want to deeply understand how something works, I’ll reinvent the wheel.
If I actually want to ship something before the next decade, I’ll use a library.
I used to be incredibly anti-NIH as a badge of honour (what kind of cretin has to use a library and can’t roll their own?) but reality beat that out of me.
Making wheels is one thing, making wheels more efficiently is something completely different. If you can make two wheels that look and behave exactly the same, but the reinvented wheel only requires less of the effort and/or resources to make, then that’s the better one. And the true beauty lies in the fact that in many cases nobody will ever notice, they just think you are a bit silly by reinventing the wheel.
Reinventing the wheel might be great as a learning tool,
the problem is when real projects and learning tools get mixed up.
It happens a lot in coding subreddits where pros and students share a space. You’ll get people arguing that C is a great language because of how much you learn.
That doesn’t make C an good language, it makes it a good set of dumbbells, and you might even hurt yourself and learn terrible ideas if you aren’t conscious of the habits you are picking up.
Standards are often better than anything you can do simply because they are standard and will be compatible, people don’t have to learn a new thing they’ll never use anywhere else, etc.
Simple and understandable doesn’t make it good. A lot of the time it means limited to one application and not reusable(And therefore does not benefit from large community support) and it often can’t handle real world edge cases.
I don’t care how beautiful the code is, if it segfaults on an invalid file, I’d rather have the 10 year old industry standard that I can treat as a black box, even though the code is probably repulsive.
Toy projects are great, as long as you don’t carry over that same kind of attitude to real ones. Scientists love original ideas. Engineers should be suspicious of them till they are have proven to be robust.
so many things to agree with phrased in a subtle way to make me disagree strenuously :)
you really should shape your decisions around the real needs of your project, but i absolutely disagree with the idea that real projects and learning are different. learning is just a project with different priorities.
C is a great language, but like any other it has costs and rewards.
standards are great, i agree with you there. when there’s a good standard i am extra hesitant to reinvent the wheel. the wheels i’m most interested in reinventing, the interface isn’t even documented, let alone standardized!
simple and understandable DOES make it good. there’s nothing else that makes it good. simplicity and undestandability are the only virtues in software. everything has bugs. the hypothetical example of dirty code that doesn’t crash and clean code that does is bogus. the dirty code crashes too. the difference is you can fix the clean code, but the bugs in the dirty code you just learn to live with. if you’ve already learned to live with those bugs, you can convince yourself they don’t even exist.
scientists and engineers both love new ideas and they are both skeptical of them at the same time. i don’t think differing attitudes towards new ideas is a difference between scientists and engineers. scientists can definitely fall victim to NIH causing them to ignore previously discovered truths, and once they invent something that same NIH can make them blind to newly discovered truths. scientists can be just as territorial as anyone else.
but i really do agree with your fundamental claim, you need to know your context. sometimes it’s acceptable to incur the costs of rewriting the library and sometimes it’s acceptable to incur the costs of using a bad library. and sometimes, the library is such a great fit that there aren’t really any costs. depends on what your goals and requirements are.
“…you need to know your context. sometimes it’s acceptable to incur the costs of rewriting the library and sometimes it’s acceptable to incur the costs of using a bad library. and sometimes, the library is such a great fit that there aren’t really any costs. depends on what your goals and requirements are….”
This.
I’m not so convinced that clean code is guaranteed to crash less than the dirty code.
Typically code gets uglier over time specifically because 100k edge cases get added, along with a million features. But the clean code is effectively “hiding” something, because all those edge cases have been moved into documentation, or worse, into undocumented requirements.
The dirty code knows that sometimes people use one specific API that returns bad data if you are on one obsolete OS. The clean code just trusts that you give it the right thing and might even silently corrupt data if you mess up bad enough. It knows that for some reason you can’t display one certain color of magenta when using one specific other program. It knows all kinds of dark knowledge that should not be needed, but were at one point, somewhere.
The clean code can be understood, but the price is that it *requires* you to understand not only the code itself, but all non-ideal parts of the system it’s attached to.
All abstractions are leaky, and making them mostly work requires a lot of effort, and that kind of dev effort only happens on really massive reusable one size fits all projects.
When you control everything, top to bottom, from the hardware right on up to the training program for the users and what tools the devs use, simplicity is really cool, because you can make it so there are “Obviously no deficiencies”.
When you don’t control anything, complexity seems to be way more reliable, and often way easier to understand than the usual approach of documenting limitations instead of adding special case code to fix them.
It’s like the GUI vs the CLI and how many disks have been wiped by a mistyped command, or the supposed robustness of ethernet over Wi-Fi which totally disappears if you can’t run a cable in a safe way that won’t get unplugged or trip someone or both.
Complexity is almost a prerequisite for anything to truly be a black box solved problem, and black boxes are a big part of division of labor in mega scale software.
But, I suppose a lot of people are working on things with real novel algorithms that aren’t largely just UI, so perhaps there’s a huge class of cases where simplicity is great that I just haven’t encountered.
But it does seem like a lot of practical things that haven’t already been done are either inherently insanely hard, or there’s really nothing to them except a few bits of UI code, and any wheel reinvention will double or triple the effort and half the portability and performance.
if your “clean code” ignores flaws in your underlying libraries then you’ve got dirty code in the libraries. clean code is a very lofty goal and can’t be achieved by sweeping things under the fridge. the trade offs we’re forced to make in practice are intense and can’t be ignored just because one component is readable. which i think is your point so i think we agree.
I’ll be blunt. Blaming C for programmer errors is stupid. Yes, there are bad habits that C won’t do anything to prevent you from developing. But programming languages that won’t let me do something efficiently because the developer of the language thinks I don’t have the self-discipline or maturity to be responsible for my own decisions is downright insulting. If you want to make a tool that I can use to examine my code for hazardous practices, go right ahead – I may even use it. But don’t tell me I can’t do something because you don’t think it’s safe. That is what many “modern” languages do. We have many, many devices that have inherent hazards. We don’t outlaw stoves because you can burn yourself on them.
I don’t really need to defend my use of C, but since I brought it up, I will: C is the language that does best, exactly the thing I want from a programming language: providing just enough abstraction that I can use the same language to program a wide variety of underlying hardware. I have used a number of other more sophisticated languages, and found that NONE of them gets the job of creating code done faster, or prevents me from making errors, and ALL of them produce slower-running code, often orders of magnitude slower.
If you want to use a hyperbolic variable-slope rowing machine with the built-in AI personal trainer module, knock yourself out, but don’t look at me when sits there unresponsive, declaring “error 63289” in flashing red comic sans on its high-definition screen. I’ll stick with my dumbbells.
i generally agree with you here, and personally use C for nearly everything. but i have a surprising counter example. i implemented something in ML (using an ocaml compiler) that i had previously written in C, and it was faster even though the ML implementation was *much* cleaner and simpler! ymmv but you will occasionally have an experience like that in a non-C language. some of the functional languages have really slick compilers and so long as you’re careful not to needlessly create and destroy lists (which they do, admittedly, make attractively easy) they really can have good performance.
but people sometimes say stuff like that about java, python, perl, etc., and it’s all rubbish. no matter how careful you are those languages will always have abysmal performance and the surprising thing is that it’s usable but it never comes close to parity with C :) even C++, you hardly ever find a performant program in the wild.
fwiw i haven’t tried rust yet. the limitations of its build environment overcame me.
We don’t outlaw C either. We may someday when Rust catches up, but for now… C is everywhere and nobody complains except when it is used for stuff other languages do better.
How many lives per year would be saved if stoves had auto shutdown with thermal cameras to catch unattended pots before they can burn? I would be all for that kind of tech.
In the real world, I don’t know who wrote every line of code I use. And for any application I actually have any interest in using, I most likely am not going to make time to read a bazillion lines of it myself.
Even within a company people can’t read all the code. And there are varying skill levels.
Basically no software that I want to use can be understood by one person, because only very minimal stuff can be like that.
If you are using C for something performance critical, or something so small you don’t need advanced features, that’s fine.
But OS bugs happen all the time. Clearly coders as a whole, including you and I, cannot be trusted with large projects and need as much help as possible from the language.
Or maybe you can be trusted, but… Job interviewers aren’t perfect. I don’t know that the people who make SW i use are as good as you. And I would much rather make an error impossible than have to constantly be on the lookout for it.
I wonder how many injuries could be prevented by adding AI to dumbells that gave you audio feedback to perfectly optimize your acceleration profile, playing an ugly noise if it detects the wrong kind of forces?
You might not need that, but the average person does.
I’ve reinvented the wheel many times when I only need a small portion (or single function) of a library for a quick script, and hacking my version together can often be quicker than learning the API of another library.