Perhaps rather unexpectedly, on the 14th of March this year the GCC mailing list received an announcement regarding the release of the first ever COBOL front-end for the GCC compiler. For the uninitiated, COBOL saw its first release in 1959, making it with 63 years one of the oldest programming language that is still in regular use. The reason for its persistence is mostly due to its focus from the beginning as a transaction-oriented, domain specific language (DSL).
Its acronym stands for Common Business-Oriented Language, which clearly references the domain it targets. Even with the current COBOL 2014 standard, it is still essentially the same primarily transaction-oriented language, while adding support for structured, procedural and object-oriented programming styles. Deriving most of its core from Admiral Grace Hopper‘s FLOW-MATIC language, it allows for efficiently describing business logic as one would encounter at financial institutions or businesses, in clear English.
Unlike the older GnuCOBOL project – which translates COBOL to C – the new GCC-COBOL front-end project does away with that intermediate step, and directly compiles COBOL source code into binary code. All of which may raise the question of why an entire man-year was invested in this effort for a language which has been declared ‘dead’ for probably at least half its 63-year existence.
Does it make sense to learn or even use COBOL today? Do we need a new COBOL compiler?
Getting The Punch Line

To fully grasp where COBOL comes from, we have to travel back all the way to the 1950s. This was a time still many years before minicomputers like the PDP-8, never mind home computers like the Apple I and kin became a thing. In these days dinosaurs stalked the depths of universities and businesses, with increasingly transistorized mainframes and highly disparate system architectures.
Even within a single manufacturer series of mainframes such differences existed, for example IBM’s 700 and 7000 series. Since each mainframe had to be programmed for its intended purpose, usually scientific or commercial tasks, and this often meant that software for a business’ or university’s older mainframes would not run on the newer hardware without modifications or a rewrite, adding significantly to the cost.
Even before COBOL came onto the scene, this problem was recognized by people such as John W. Backus of BNF fame, who proposed the development of a practical alternative to assembly language to his superiors at IBM in late 1953. This resulted in the development of the FORTRAN scientific programming language, along with the LISP mathematical programming language, both targeting initially the IBM 704 scientific mainframe.
FORTRAN and other high-level programming languages offer two benefits over writing programs in the mainframe’s assembly language: portability and efficient development. The latter is primarily due to being able to use singular statements in the high-level language that translate to an optimized set of assembly instructions for the hardware, providing a modular system that allowed scientists and others to create their own programs as part of their research, studies or other applications rather than learn a specific mainframe’s architecture.
The portability feature of a high-level language also allowed for scientists to share FORTRAN programs with others, who could then run it on the mainframes at their institute, regardless of the mainframe’s system architecture and other hardware details. All it required was an available FORTRAN compiler.

Whereas FORTRAN and LISP focused on easing programming in the scientific domains, businesses had very different needs. Businesses operate on strict sets of rules, of procedures that must be followed to transform inputs like transactions and revenue flows into payrolls and quarterly statements, following rules set by the tax office and other official instances. Transforming those written business rules into something that worked exactly the same way on a mainframe was an important challenge. This is where Grace Hopper’s FLOW-MATIC language, formerly Business Language 0, or B-0, provided a solution that targeted the UNIVAC I, the world’s first dedicated business computer.
Hopper’s experiences indicated that the use of plain English words was very much preferred by businesses, rather than symbols and mathematical notation. Admiral Hopper’s role as a technical advisor to the CODASYL committee that created the first COBOL standard was a recognition of both FLOW-MATIC’s success and Hopper’s expertise on the subject. As she would later say in a 1980 interview, COBOL 60 is 95% FLOW-MATIC. The other 5% coming from competing languages – such as IBM’s COMTRAN language – which had similar ideas, but a very different implementation.
Interestingly, one characteristic of COBOL before the 2002 standard was its column-based coding style, that derives from the use of 80-column punch cards. This brings us to the many feature updates to the COBOL standard over the decades.
Standards Of Their Time
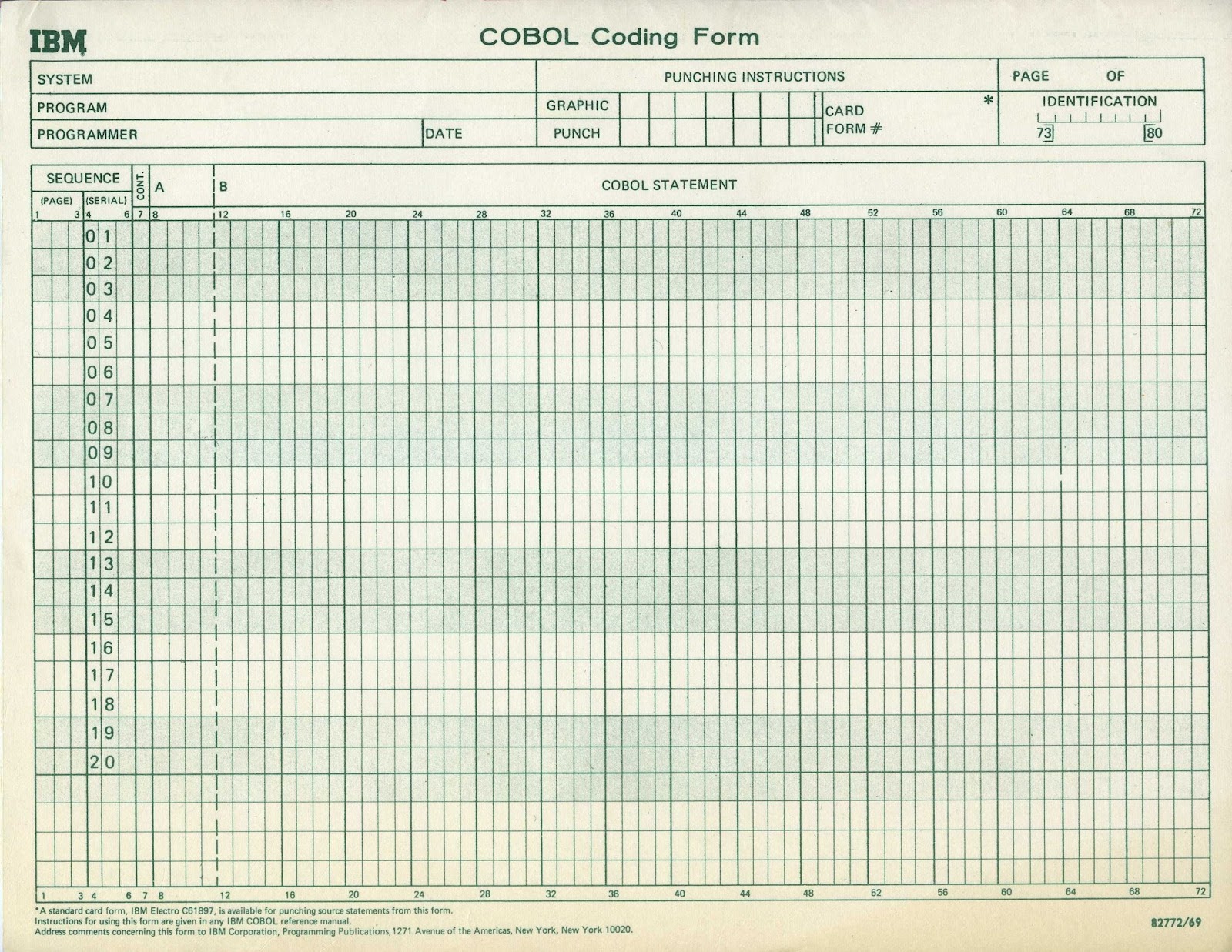
An interesting aspect of especially domain-specific languages is that they reflect the state of both said domain as well as that of the technology at that time. When COBOL was put into use in the 1960s, programming wasn’t done directly on the computer system, but usually with the code provided to the mainframe in the form of punch cards, or if you were lucky, magnetic tape. During the 1960s this meant that ‘running a program’ involved handing over a stack of punched cards or special coding form to the folk wrangling the mainframe, who would run the program for you and hand you back the results.
These intermediate steps meant additional complexity when developing new COBOL programs, and the column-based style was the only option with the COBOL-85 update as well. However, with the next standard update in 2002, a lot of changes were made, including the dropping of the column-based alignment, adopting free-form code. This update also added object-oriented programming and other features, including more data types to the previously somewhat limited string and numeric data representations.
What did remain unchanged was COBOL’s lack of code blocks. Instead COBOL source is divided into four divisions:
- Identification division
- Environment division
- Data division
- Procedure division
The identification division specifies the name and meta information about the program, in addition to class and interface specifications. The environment division specifies any program features that depend on the system running it, such as files and character sets. The data division is used to declare variables and parameters. The procedure division contains the program’s statements. Finally, each division is sub-divided into sections, each of which are made up out of paragraphs.

With the latest COBOL update of 2014, the floating point type format was changed to IEEE 754, to further improve its interoperability with data formats. Yet as Charles R. Martin pointed out in The Overflow in his solid COBOL introduction, the right comparison of COBOL would be to another domain-specific language like SQL (introduced 1974). One could add like PostScript, Fortran, or Lisp to that comparison as well.
While it’s technically possible to use SQL and PostScript for regular programming and emulate the DSL’s features in a generic (system) programming language, doing so is neither fast nor an efficient use of one’s time. All of which rather illustrates the raison d’être for these DSLs: to make programming within a specific domain as efficient and direct as possible.
This point is rather succinctly illustrated by IBM’s Program Language One (PL/I) – introduced in 1964 – which is a generic programming language that was intended to compete with everything, from FORTRAN to COBOL, but in the end failed to outperform any of those, with neither FORTRAN nor COBOL programmers convinced of the merits of PL/I to switch to it.
It’s important to realize that you don’t write operating systems and word processors in any of these DSLs. This lack of genericity both reduces their complexity, and is also why we should judge them solely on their merits as a DSL for their intended domain.
The Right Tool
An interesting aspect of COBOL was that the committee that produced it was not made up out of computer scientists, but rather by people within the business community, driven strongly by the needs of manufacturers like IBM, RCA, Sylvania, General Electric, Philco, and National Cash Register, for whom a good experience by the business owners and government agencies with whom they did business was paramount.
As a result, much like how SQL is shaped by the need to efficiently define database queries and related, so too was COBOL shaped over decades by the need to make business transactions and management work smoothly. Even today much of the world’s banking and stock trading is handled by mainframes running code written in COBOL, largely because of decades of refinement to the language to remove ambiguities and other issues that could lead to very costly bugs.

As attempts to port business applications written in COBOL have shown, the problem with moving statements from a DSL to a generic language is that the latter has none of the assumptions, protections and features that is the very reason why DSLs were made in the first place. The more generic a language is, the more unintended consequences of a statement may occur, which means that rather than the verbatim porting of a COBOL or FORTRAN (or SQL) statement, you also have to keep in mind all the checks, limitations and safeties of the original language and replicate those.
Ultimately, any attempt to port such code to a generic language will inevitably result in the DSL being replicated in the target language, albeit with a much higher likelihood of bugs for a variety of reasons. Which is to say that while a generic programming language can implement the same functionality as those DSLs, the real question is whether this is at all desirable. Particularly when the cost of downtime and mistakes tend to be measured in millions of dollars per second, as in a nation’s financial system.
The attractiveness of a DSL here is thus that it avoids many potential corner cases and issues by simply not implementing those features that would enable those issues.
Where GCC-COBOL Fits In
There’s currently still a severe lack of COBOL developers, even though demand is strong. Although GCC-COBOL is – like GnuCOBOL – not an officially validated compiler that’d be accepted anywhere near an IBM z/OS-running mainframe at a financial institute, it does however provide the invaluable role of enabling easy access to a COBOL toolchain. This then enables hobbyists and students to develop in COBOL, whether for fun or for a potential career.
A business could also use such an open-source toolchain for replacing legacy Java or similar payroll processing applications with COBOL, without having to invest in any proprietary toolchains and associated ecosystems. According to the developer behind GCC-COBOL in the mailing list announcement, this is one of the goals: to enable mainframe COBOL applications to run on Linux systems.
Although financial institutions are still highly likely to jump for an IBM Z system mainframe (the ‘Z’ stands for ‘Zero Downtime’) and associated bulletproof service contract, it feels good to see such an important DSL become more readily available to everyone, with no strings attached.














In 1974 while in the Air Force, I used COBOL to write an 8080 assembler for my Altair 8080. One of the things it included was free form input instead of the fixed fields normally used. It ran on a Burroughs B-3500. After I got out of the Air Force I ported it to a GE 415 and then to a IBM 360.
I used several ideas from it in various jobs. The free form input scanner was very useful.
I used COBOL for many years until I became a BIOS programmer.and started programming on the bare metal.
Many fond memories of COBOL.
I forgot to mention that I also wrote an 8080 emulator in COBOL.
That was my start as a hacker/maker.
COBOL, PL/I oh those were the days. Oddly one can still buy punched cards.
Hopefully you mean unpunched cards? :)
Actually, you can buy *punched* cards on Ebay. Punched paper tape, too. Kids these days….
But why would you? Test a verifier you found?
The Burroughs medium systems, such as the B-3500, instruction set was designed to run COBOL.
Yes, your post highlights exactly what went wrong with COBOL. The committee that managed COBOL’s development was hardware manufacturer owned and dominated. Between them, they made sure that COBOL was allowed to stagnate for decades. This crippling prevented COBOL – and the millions of programmers familiar with it – moving forward other than at a snail’s pace.
MicroFocus and other 3rd parties did their best to keep COBOL moving but what the manufacturers did to the language was a sin if not a commercial crime.
I’ve seen posts here almost bragging about the number of languages, compilers, run time systems and application control languages (JCL etc) their site uses. Posts that should strike fear into the heart of anyone running those companies and paying for their IT.
Unlike in society, their is no commercial value in IT diversity, there is only risk and cost.
Just say no.
On the other hand, if a person had to choose between COBOL and Java — it would be time to consider a career as a forest ranger.
Replace “Java” with “Javascript” and leave out the COBOL and you’d have it right.
I’d pick to write code in COBOL over Javascript all day long….
I’m not in that position, but perhaps picking COBOL and collecting fat checks on the side while working as a forest ranger might be the way to go.
This!
In the mid-late-90s, with the Y2K bug looming, I worked at a company in Shanghai that was _mopping up_ because they had a slew of young programmers who knew COBOL when all of the world’s banking infrastructure was facing an oncoming tsunami.
All the C++ programmers in the world couldn’t help Macy’s out. It took COBOL.
Not saying you’d want that job, necessarily, but they made out like bandits. Good times! Strange times.
I was a freelance COBOL and Assembler analyst/programmer for Swiss banks and pharma companies for many years.
Those Y2K ‘bugs’ allowed me to retire almost 10 years earlier than expected!
You are suggesting that people program in Oak instead?
Only if you use pine as an email client
I can cedar humor in this thread.
You’re having to go pretty fir for these.
I walnut listen to this madness any more
If they change it’s name to BOLOC, it will immediately get a huge following. Like BRAINF*.
Business Oriented Language on Computers?
Business Oriented Language of Commoners ;)
It is to bad this did not appear when Linux came out many years ago. There was large demand for COBOL on Linux in the 90s and early 2000s. But the only options, if available, cost thousands plus you had to pay a seat fee for the runtime. So the individual COBOL programmer was really SOL without corporate backing.
Also, IIRC GNU/FSF had a “thing” against COBOL, so coming out with a Free alternative was not encouraged. Too bad, I think the world would be a far different place these days if a viable cheap/free COBOL was available back then.
GNU/FSF has been most welcoming. This is the second official try at a COBOL front-end for GCC AFAIK.
Apparently most people here don’t work in a file intensive financial environment using obsolete equipment.
The case you need to make for COBOL is about 6ft or so long and is something like an irregular hexagon in horizontal section….
;-) …. sorry couldn’t resist.
Thanks for a trip down memory lane. There was nothing quite like starting a day with a bunch of coding sheets and freshly sharpened pencils and writing down the words IDENTIFICATION DIVISION. So much hope and promise that for once I wouldn’t miss a full stop and piss off my systems analyst, and, worst of all, endure the walk of shame past the rows of data prep girls to their boss to plead for the corrected program to be converted into cards again.
Four years I stuck at it before moving into mainframe support.
Even now, forty years on, I can still add a full stop at the end of a line of C++ or Python if I’m in a bit of a rush.
I too remember the “walk of shame”. Hideous experience, everybody knew. But – many years of it being a pleasure to come to work.
Even as Keypunch Supervisor I did the walk of shame when my coding sheets sucked.
Our the embarrassment of dropping your stack of cards on the way to the card reader.
Leading to the marker trick down the side.
Or the card sorter; if your dept had one and you had been diligent enough to number your cards/statements.
It seems like whenever I read an article on “OMG people still use [COBOL/Fortran]”, there’s usually discussion about all the modern additions to the languages, and yet any examples are clearly using 1960s syntax. I’d be interested to see some modern code in context, especially as the author does a great job of making the case for DSLs, but it would be interesting to see more detail on the specific problems it solves in a modern environment.
You might enjoy reading : http://www.moreisdifferent.com/2015/07/16/why-physicsts-still-use-fortran/
A right tool for the job situation.
https://thenewstack.io/nasa-programmer-remembers-debugging-lisp-in-deep-space/
I read FORTH lives on in space too.
yeah – because in space nobody can hear you scream
Thank you for the kind words!
Here’s the SO Blog article Maya mentioned. https://stackoverflow.blog/2020/04/20/brush-up-your-cobol-why-is-a-60-year-old-language-suddenly-in-demand/
Never used COBOL professionally. As CS Majors, we did have to write a few simple programs with it … same with Lisp, Prolog, Fortran, Assembly and others. Pascal was the data structures learning language at the time. I just see COBOL as another programming language neither good nor bad. Obviously can’t be to bad as there are millions of lines of code written in it :) . It didn’t fit my real-time systems programming career, so never saw it again… Other than I’ve dabbled with it a bit at home as a nostalgic thing in the past few years for kicks. Never wrote anything that I actually ‘used’. Glad to see it is still kicking.
Thinking of cobol as a dsl I think is informative. Of course we hadn’t invented the term at the time but from the start cobol was meant for the read some records, do some computation, write some records model on which most data processing was based.
The proper title, or prefix, for Grace Hopper is ‘Admiral’.
+1
Shouldn’t it be “Your”? As in Your Grace …
I see what you did there. Nice :-}
Too right!
COBOL was dead right from the start. Look up COBOL Tombstone. 😉
A good COBOL compiler is step 1 of a bunch in setting up a correct and perfomant Linux alternative. Getting legacy EBCDIC data working on an ASCII / UFT-8 system is a big challenge. Then there’s the mainframe flow control environment which glues hundreds of COBOL programs into a system, probably using JCL or something on top of it. That glue resembles dynamic make + cron + pubsub and really needs its own DSL. If you’re going to do this in tandem with a live system then the first step will be a way to automatically translate from legacy source + data (COBOL, JCL, EBCDIC, flow control) to the new system.
nothing magical about EBCDIC — bits is bits. It’s all the non-COBOL tools that expect ascii or utf-8 that would be the problem. Even Fred Brooks agrees JCL was a bad idea, but you can do the same thing with Python or even bash. But if you have 50 million lines of COBOL running on something like a Z system, or even an AS/400, there’s an awfully big energy barrier to moving to a new platform, a new architecture, and rewriting a lot of working code.
EBCDIC is magical because there’s so many encodings to choose from, many of them not invertible with ASCII. Plus the tooling has to be absolutely correct on which bytes to translate — a lot of EBDCIC data is interlaced with binary data. The energy barrier is why I mentioned automatically translating from the original source, not just as an initial step, so you can keep lockstep with the live system you are trying to replace. That makes it easy to track legacy system changes as the conversion progresses.
Finally, my sophomore professor is right lol. I guess I wished I had paid more attention during our COBOL sessions. Pretty neat to include it. I need to look and see if prolog is making a comeback anytime soon. I wasted soooooooooo much time with that language but loved the projects I made with it.
https://github.com/lanl/QA-Prolog
;-)
Just be careful a languages seductive powers doesn’t derail you.
http://coding.derkeiler.com/Archive/Lisp/comp.lang.lisp/2006-04/msg01644.html
I thought by “making the case”, you meant “casket”!
B^)
You didn’t happen to write those first simple programs sitting in front of a Volker-Craig terminal connected to a Prime 750 by any chance?
That’s nothing. I wrote my first cobol programs on punchcards for an IBM 360/30
In the mid 1990’s I worked at a student loan processing company where a massive database was manipulated by a set of very large and complex MS-DOS batch files, ported from COBOL. DUEDILIG.BAT did the due diligence and printed out bills and late notices. REORGER.BAT then reorganized the database for faster processing the next day. I don’t recall the names of the others but IIRC there were 4 or 5 batch files that had to be run in a sequence.
The batch files were hosted on a Netware 4.11 server but executed on Windows 95 workstations. The speed, or lack of it, of the workstation governed how quickly the processing got completed.
This was all complicated by their previous CNA. The company had sent her to Salt Lake City for Novell’s two week course. Part of that included being sent some ‘goodies’, which was the worst thing Novell could have done. Among those was a beta version of Netware 4.11, boldly printed NOT FOR USE IN A PRODUCTION ENVIRONMENT on the CD.
So of course she used it to “upgrade” Netware 4.1 to 4.11 on their production server. It was definitely not ready for prime time.
Good luck getting a job writing COBOL. It’s the first language I learned in college, and I’ve always been told the barrier to entry is 10 years experience. The only way to get it is internships, which are few and far between. 28 years later, I write in a dozen different languages, never having landed a job writing COBOL.
Not true. I know many companies hiring now. In fact, we pay to train people on mainframe toolchains and then hire them away to customers. The idea is to keep the platform viable. You’d be amazed at how you can access mainframe tools without a terminal session. There’s even an open sourced project for it, zowe.org. It’s part of the Linux Foundation.
I’ve recently been working through Jay Moseley’s extensive tutorial on installing (or sysgen’ing in mainframe speak), MVS 3.8j on an emulated IBM 360/370 using Hercules. I’m not sure why. Just wanting to play with something more arcane than Unix maybe? I’ll probably play around with COBOL on it when I get it going. One thing I remember about COBOL from the one class I had on it in college was it looked really good for generating complicated printed reports.
My contribution to COBOL: https://codegolf.stackexchange.com/questions/167962/cobol-y2k-redux. I was the OP user15259, before quitting the forum. Essentially introducing a date format PPQQRR backwards compatible with YYMMDD but extends the maximum date to 4381-12-23.
Ahh, so it’ll be your fault when we all get unfrozen from cryo-sleep in 4380. Thanks a lot.
I figured there had to be an LLVM project as well
“Yes, we have our Digital legacy COBOL frontend hooked to LLVM. That
frontend generates our legacy GEM IR which is then converted to LLVM IR.
It is currently an Itanium-hosted cross-compiler but we’re bootstrapping
our compilers to native OpenVMS x86 right now (we have clang “working”
on OpenVMS x86 on Virtual Box today).
The frontend (and much of the companion library to process the DEC4/DEC8
datatypes) still has Digital copyrights which are own owned by HPE and
licensed to us. I would be unable to opensource it without their
permission. And you’d get a nice vintage COBOL 85 compiler written in
BLISS. :) :) :)
As for the DIBuilder COBOL support, since our cross-compilers are based
on an ancient LLVM 3.4.2 (due to the ancient Itanium C++ we have on our
host systems), we have to refresh all of that with our native
bootstrapping before I could even consider upstreaming any of that. And
we are just starting on our symbolic debugger so I don’t know if
anything we’ve done even works yet. And I haven’t even explained level
88 condition names to the debugger engineers yet. :)
For those keeping score at home, what we have so far is our legacy
compilers for BASIC, BLISS, C, COBOL, Fortran95, Macro-32 VAX assembly,
and Pascal. All but BASIC are in good shape. BASIC and its RTL do some
un-natural acts. And now we just bootstrapped clang 10 (we had to pick
something to start) by compiling on Linux using a mixture of OpenVMS and
Linux headers and then moving the objects to OpenVMS for linking (using
the OpenVMS linker of course).”
May 2021
https://groups.google.com/g/llvm-dev/c/DQdhnjwfWe0
So, it’s important to note that when people talk aobut COBOL, they really mean IBM COBOL + JCL, because that’s what “COBOL” really is. There is no use for COBOL outside of the IBM mainframe environment, because COBOL and it’s associated JCL is designed around the unique mainframe hardware, especially when it comes to data storage. The JCL component of “COBOL” is the most painful part of this language, and the most hated. COBOL is an easy language. It doesn’t do much. It reads files line by line, modifies them, and creates a new file. That’s what 99% of COBOL programs do. Integrating the COBOL program with JCL to run properly on the mainframe is what people hate so much. Learning or implementing COBOL on a PC or any other computer is pretty much worthless. The hardware doesn’t match, and there are much easier ways to manipulate files on a non-mainframe computer with a different language or script. You’re not going to learn enough using COBOL on linux to be able to use COBOL in the real world (i.e. on a mainframe machine). It’s the mainframe environment people don’t like when they say they hate COBOL, not so much the language itself.
True. I don’t have any stats but I’d be prepared to risk a small wager on more rum time being lost due to errors in JCL than in coding. I was always half convinced that JCL was invented by hardware engineers just so they could test their stuff and only released into the wild when IBM realised they didn’t have anything else. In the 70s IBM didn’t even have a JCL training course (in the UK). IT departments paid a heavy price for the myth of device independence.
I’ve worked with COBOL for 30 years. Mostly CICS, what you described was just the batch side. We now are developing web services using COBOL/CICS. No other languages I’ve worked with handles real world data better, there’s no reason it for it to be replaced.
What nonsense! I have been around COBOL since 1969. I have never used IBM systems and never used JCL. It was used for online transaction processing in banks I worked with in UK, Europe, North America, Latin America, The Far East, ……
All of ‘The Bunch’ manufacturers provided COBOL, and all used it in banking and commercial applications.
Was that a wind up? Or just ignorance?
It doesn’t take long for stories about COBOL to accumulate comments of derision and scorn.
I look at it this way – COBOL, or a xGL descendant of it, is or has very likely been looking after many people’s bank account balances for a very very long time, and reliably. Perhaps yours and perhaps mine, and I thank COBOL for this.
I learnt it at Uni and at my first job as a C programmer/system admin supported COBOL devs and apps on Unix/Xenix/DOS without any dramas. It just worked.
“It doesn’t take long for stories about COBOL to accumulate comments of derision and scorn.”
What language doesn’t? See Javascript.
“A business could also use such an open-source toolchain for replacing legacy Java or similar payroll processing applications with COBOL”
Gee, not toolong ago we called the COBOL code “legacy” and were told that the future was replacing the legacy code with Java. 😄
Class HelloWorld {
public static void main(String[] args) {
System.out.println(“Hello World!”);
}
}
IDENTIFICATION DIVISION.
PROGRAM-ID. HelloWorld.
PROCEDURE DIVISION.
DISPLAY “Hello World!”.
Java VS COBOL
SOURCE GnuCobol Programmers Guide
“hello world” programs say very little about what a language is like. Demo programs that actually have some control flow, variables, etc will give a much better sense of the language. All languages have their boilerplate which is not very interesting. When you are writing a big program nobody cares if you have to add some gratuitous stuff to make the compiler happy.
Shortest hello world program (with lax syntax checks) in COBOL:
DISPLAY ‘Hello World!`.
I do not want to offend anyone. COBOL is a good business and mostly the rates are better than for modern programming languages.
However, my experience is completely different to what is described in the post:
Reliability:
– Complex Access/VBA/ORACLE Application: <1 application related production issue per year for 21 years.
– Application Server (GUI) Java/HTML/CSS: 50 application related production issues per year (!) for 19 years.
Productivity:
– Complex Access/VBA/ORACLE/PL-SQL Application: <6 months, 2 developers.
– First version of Mainframe Application COBOL/SQL/JCL: 10 developers, 1 year.
– Same (full!) functionality using ACCESS/VBA (only for political reasons called "prototype"): 1 developer, < 1 month.
– Application Server (GUI) Java/HTML/CSS: 2 developers, 6 months.
Maintenance:
– Complex Access/VBA/ORACLE/PL-SQL Application: <1 month, 1 developer per year.
– Mainframe Application COBOL/SQL/JCL: developer team has grown from 10 to 20 developers in the last 18 years.
– Application Server (GUI) Java/HTML/CSS: <1 month, 1 developer per year.
As always, your milage may vary.
Counting lines of code:
The typical way COBOL programs are written is to copy one that does something similar and change it. Yes, this way you quickly produce millions of lines of code (aka legacy).
Migration:
My impression is that migration is so difficult because the logic is hidden in many programs containing mostly boilerplate code and nobody remembers what the intention once was. From the COBOL developers I know, less than 2 out of 10 know a modern programming language and even less have knowledge concerning patterns, practices, and software architecture.
Imagine how helpful the majority is during a migration.
COBOL as well as developers for modern languages are rare. For a migration you need developers that know the old and the new environments and these are unicorns.
But most important, a big migration does not pay out within a quarter or even a year.
Instead of the number of companies that use COBOL it would be interesting how many of the successful companies founded in the last 10 to 20 years started to use COBOL.
“A business could also use such an open-source toolchain for replacing legacy Java or similar payroll processing applications with COBOL.” The funny thing is, I think that Java was seen as a replacement for COBOL. MicroFocus does/did sell a Cobol compiler that translated Cobol into Java, because that was somehow thought to be better. Cobol was the legacy, Java was the bright new thing. Seems that the positions have reversed. From the shire to Mordor and back again. Oh how we laughed.
Cobol has proper decimal arithmetic, something even C/C++ doesn’t have as standard. Also Cobol seems to lay out records in memory, and it looks like Cobol can run very fast. It does a simple thing in a simple way. Unlike Java.
I played with GnuCobol a few years ago as an experiment, and my general conclusion was that it was absurdly painful to use. There were issues with code formatting, and the records that I had didn’t have a layout that would really work with Cobol. There were other inconveniences, too. The issues could be addressed, but my dislikes were obviously not what the standards committee thought to be important.
On Sourceforge there’s a project called ACAS (Applewood Computers Accounting System). It seems that there was a version released earlier this year. I was in touch with the author a few years ago. It seemed that he still used the system, possibly even commercially (although maybe not now). I think his accounting system has been around for some time, possibly the 80’s. It’s fascinating to think about.
Somehow people talk about “COBOL is only IBM (and include JCL and CICS)”.
Fujitsu, RM/COBOL, ACUCOBOL-GT, Micro Focus and a bunch of other vendors made a fortune by providing COBOL compilers for the PC since at least the 90s, so that statement is definitely only an opinion.
GnuCOBOL provides a robust and performant alternative to those and GCOBOL possibly will also (while its main target currently is IBM compatible COBOL code).
And fun fact: before IBM finally made a 64bit version of their compiler available those “PC based” COBOLs running on GNU/Linux on the Mainframe was the only option to have a 64bit COBOL compiler there.