We are big fans of using SQLite for anything of even moderate complexity where you might otherwise use a file. The advantages are numerous, but sometimes you want to be lean on file storage. [Phiresky] has a great answer to that: the sqlite-zstd extension offers transparent row-level compression for SQLite.
There are other options, of course, but as the post mentions, each of these have some drawbacks. However, by compressing each row of a table, you can retain random access without some of the drawbacks of other methods.
A compressed table has an uncompressed view and an underlying compressed table. The compression dictionary is loaded for each table and cached to improve performance. From the application’s point of view, the uncompressed view is just a normal table and you shouldn’t need any code changes.
You can select how the compression groups data which can help with performance. For example, instead of chunking together a fixed number of rows, you can compress groups of records based on dates or even just have a single dictionary fixed which might be useful for tables that never change.
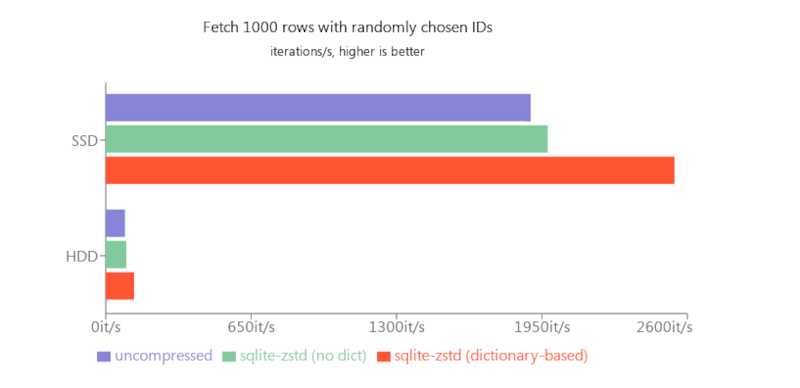
Speaking of performance, decompression happens on the fly, but compression and dictionary building is done in the background when the database is otherwise idle. Benchmarks show some performance hit, of course, but that’s always the case: you trade speed for space. On the other hand, for random access, it is actually faster to use compressed tables since there is less data to read. Random updates, though, were slower even though compression doesn’t occur at that time.
If you want a quick start to using SQLite, there’s a Linux Fu for that. You can even use versioning with a Git-like system, another advantage over traditional files.














interesting. the WSPR spots (from WSPRnet) db for 2021 in SQLite is 340 GB, but 37 GB when 7zip compressed. It will be interesting to see if this helps a bit. A lot of that are indices I added, and the rows aren’t that big.
I think the problem is that phiresky is using wrong tools for the job. Instead of patching, change tools / methods. For example store the raw data to binary fiel generate summaries from the raw data into SQLite for later analysis.
I think SQLite is fine as a tool even for this purpose, but the database structure could be implemented differently than just dumping 30 kB of JSON into a column. For example a table with (program, start_time, close_time).
I have a similar time tracking system that just logs the foremost application each minute into a text file. The text files for 5 years uncompressed are just 124 MB so far.
The most common reason for a json or xml data field that stores gobs of data is a fossilized DBA that takes months to ‘approve’ of adding a new data field.
It isn’t a terrible solution for DBAs with sticks in uncomfortable places and control issues. But how common are those? (very) They all think they are in a very high volume transactional environment requiring 125th normal form databases.
Very few databases are actually 3rd normal form. 3rd normal form means no redundant data, so no totals on invoice, just sum up lineitem every time…er not lineitem either, that needs to join to product price history to get the price at time and place.
Unless you are on a db that process millions of transactions/day, ignore anybody who ever refs any normal form higher than 3rd. They aren’t likely to be fans of SQLite though.
Indeed, the great thing about a relational database such as SQL is that it is very efficient and structured. For example for this use case you would have a table with App names:
1: Telegram
2: Whatsapp
etc
Then you would have a table with device types:
1: Smartphone
2: Windows
etc
Finally, the entries table would look something like this
App: 1
Device: 2
It would only take ut 2 bytes of storage per row since the column names are fixed.
It would then be possible to do very efficient queries. Much faster than what was shown in the testing above.
Instead he makes his entries like this:
{“device_type”:”Smartphone”,”app”:{“pkg_name”:”org.telegram.messenger”, “app_name”:”Telegram”, “app_type”:3}, “act_type”:200, “act_type_flag”:0, “pid”:35,…}
The reason being “it is too much work” to make a proper database structure.
99% of the data in each row is redundant. This is why a dictionary based compression makes such a difference.
I noticed this too but here’s the thing: I would not be surprised to find that a large number of SQLite databases are used by people who don’t understand database normalization so this is probably pretty prevalent compared to structures in major database products. So while one answer is to say “Go read Codd and Date” but this is another answer and more likely to be followed ;-)
please compress a ELF format too
and whole system linux
Lookup: “zswap” and “zram”
For filesystems (unless the filesystems are read only) the best options are:
OpenZFS (archiving: gzip ; realtime: lz4)
Btrfs (supports zlib, LZO, ZSTD)
If it gets down https://src.fossil.netbsd.org to a manageable size, I’m all in!
this sentence “We are big fans of using SQLite for anything of even moderate complexity where you might otherwise use a file.” kind of triggered me :)
i mean, everything has its right place. but this project in particular makes me uncomfortable because it’s un-lightening sqlite…explicitly-managed off-line data compression is a lot different from the kind of usage scenarios i’ve considered for sqlite, or the scenarios i’ve found in the wild. it sounds a lot like they’ve got a scenario where sqlite isn’t really the right tool for the job and instead of making the right tool they’ve hacked sqlite to become something different. i’ve always seen sqlite as useful for datasets where you don’t care about the size & speed performance benefits of doing it yourself, and you don’t need the kind of features that something bigger like mysql adds. of course, gotta respect a hack that’s actually hitting their goals in their exact scenario.
but i think it kind of shows actually a big weakness of pervasively using sqlite… it reminds me of when i was on a host where i was forced to build nvi from source (side story, you probably don’t know this, but nvi is way better than vim). it has a dependency on some variant of berkely database (libdb), and i don’t have any idea why…maybe they use it to parse the config file, for all i know. but the libdb they’re using is simple, and the subset of its functionality that they’re using is even simpler. it truly didn’t save them any effort using the library instead of rolling their own. but today, decades later, coming across it just as a chore…man! they really didn’t do me any favors! none of the maintained versions of libdb are still compatible with how nvi uses it, so you have to track down the old version or patch nvi (or both). it turns into a real unforced dependency nightmare.
already, all of their code that uses sqlite is going to be a nightmare for anyone coming at this project in a decade. they’ll have to fight the drift in the SQLite API (though i have no idea how bad that truly is…i only know how bad it is to try to use an SQL program that was written a decade ago with mysql). but that’s not enough, now they’re doubling it by adding this dependency on a bespoke add-on. maybe it’s a golden idea for their actual requirements but i’ve been bit by this often enough that i am always seeing the argument for simply rolling your own file access methods. it is true that it’s a little redundant code but it’ll probably be much more performant for your needs, and it won’t have this maintenance nightmare.
what i’m saying is, whenever i care this much, i care enough to roll my own.
To be fair, mysql is the worst non standard pig-Fing database on earth. Anybody who uses it deserves a kick square in the crotch (see how non sexist this old coder has become).
Use a database that supports ANSI SQL and don’t use non ANSI extensions unless you really need to and understand the costs of lockin.
I’m all for XML or JSON datastores when it’s just a small disorganized adhoc mess anyhow. When the data becomes too big for that, it’s time to refactor.