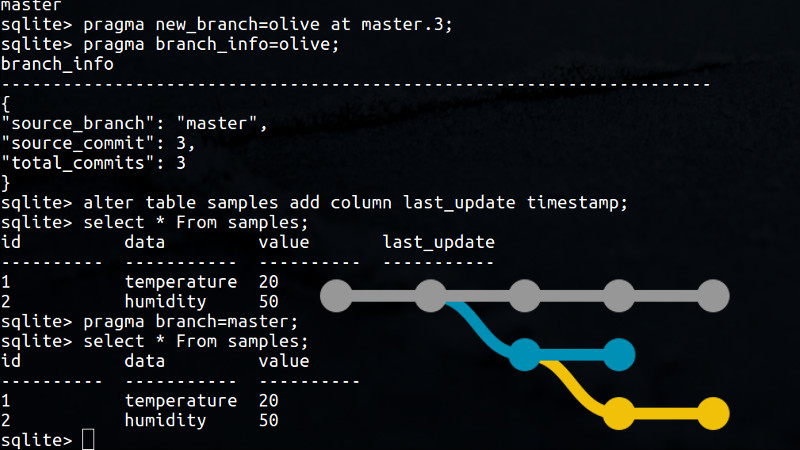
Whether you want some quick and dirty data storage, or simply don’t have that heavy requirements for your local database system, SQLite is always a good choice. With its portable single-file approach, bindings to all major languages, and availability on systems of all sizes, it is relatively easy to integrate a SQLite database in your undertakings. And if you tend to develop directly in your production environment, you may be interested to hear that the folks at [aergo] made this a lot more flexible (and interesting) by adding Git-style branching to the SQLite engine.
Similar to Git, each database operation is now stored as a commit with a unique id as reference point, and new branches will keep track how they diverge from their parent reference point. This essentially lets you modify your data set or database schema on the fly, while keeping your original data not only untouched, but fully isolated and functional. Unfortunately, merging branches is not yet supported, but it is planned for the near future.
In case you don’t see much use for git-alike functionality in a database, how about the other way around then: using Git as a database, among other tricks?














Fossil version control uses SQLite
http://fossil-scm.org
I got excited when I saw the heading, then disappointed with the details.
I’ve been wanting for years – and have never managed to have the time to write it myself – for someone to bring out a hierarchical database equivalent of SQLight.. Not every problem in the world is best done with a relational database – something most of the world seems to have forgotten – and I dream of an open source (much smaller) equivalent to IMS DB.. :-)
Something like a…registry?
SQLLite uses MVCC, so it basically already stores commits as branches with unique IDs. This doesn’t really seem to be building on that, though. It looks like they are instead working at the page level.
They are using the LMDB key value store (which also uses MVCC) as the SQLlite storage engine and, I guess, doing the versioning/snapshotting there. Maybe analogous to the difference between a filesystem with copy on write support, and an ordinary journaled filesystem running on top of a logical volume manager with snapshot support. The author of LMDB also
At least that’s the best I can do given my superficial understanding of DBMS architecture. It passes the test of not being yet another DADBMS (dumbass database management system) in that the author chose to build on two mature, well designed codebases. So, that’s good.
Ok. I don’t know if LMDB is well designed. Apparently some people have beefs with the design of the API. But pretty much anything has someone who doesn’t like it, so I don’t really know.