When you’re restricted to ASCII, how can you represent more complex things like emojis or non-Latin characters? One answer is Punycode, which is a way to represent Unicode characters in ASCII. However, while you could technically encode the raw bits of Unicode into characters, like Base64, there’s a snag. The Domain Name System (DNS) generally requires that hostnames are case-insensitive, so whether you type in HACKADAY.com, HackADay.com, or just hackaday.com, it all goes to the same place.
[A. Costello] at the University of California, Berkley proposed the idea of Punycode in RFC 3492 in March 2003. It outlines a simple algorithm where all regular ASCII characters are pulled out and stuck on one side with a separator in between, in this case, a hyphen. Then the Unicode characters are encoded and stuck on the end of the string.
First, the numeric codepoint and position in the string are multiplied together. Then the number is encoded as a Base-36 (a-z and 0-9) variable-length integer. For example, a greeting and the Greek for thanks, “Hey, ευχαριστώ” becomes “Hey, -mxahn5algcq2″. Similarly, the beautiful city of München becomes mnchen-3ya.
As you might notice in the Greek example, there is nothing to help the decoder know which base-36 characters belong to which original Unicode symbol. Thanks to the variable-length integers, each significant digit is recognizable, as there are thresholds for what numbers can be encoded. A finite-state machine comes to the rescue. The RFC gives some exemplary pseudocode that outlines the algorithm. It’s pretty clever, utilizing a bias that rolls as the decoding goes along. As it is always increasing, it is a monotonic function with some clever properties.
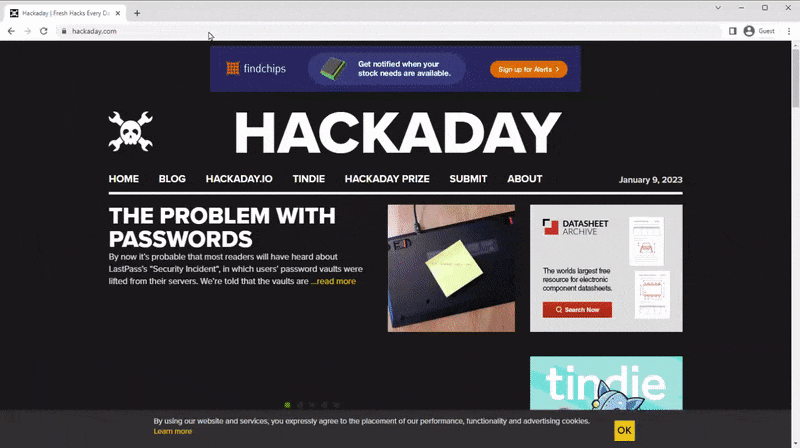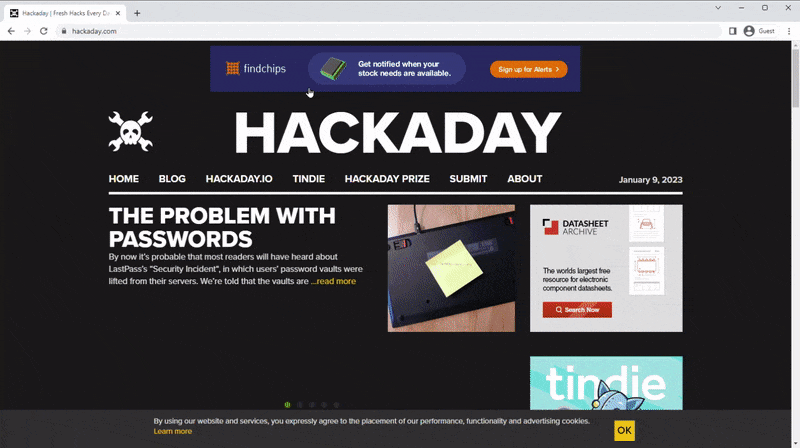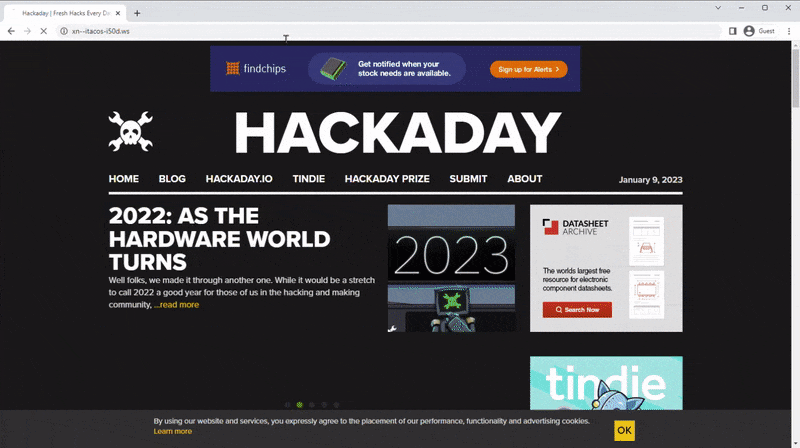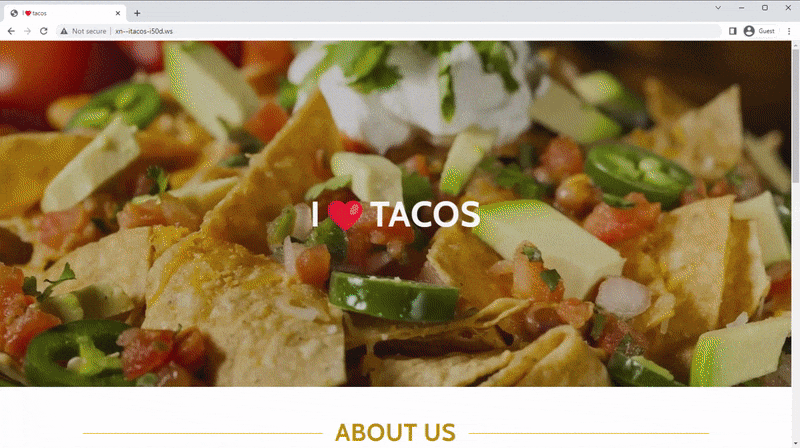
Of course, to prevent regular URLs from being interpreted as punycodes, URLs have a special little prefix xn-- to let the browser know that it’s a code. This includes all Unicode characters, so emojis are also valid. So why can’t you go to xn--mnchen-3ya.de? If you type it into your browser or click the link, you might see your browser transform that confusing letter soup into a beautiful URL (not all browsers do this). The biggest problem is Unicode itself.
While Unicode offers incredible support for making the hundreds of languages used around the web every day possible and, dare we say, even somewhat straightforward, there are some warts. Cyrillic, zero-width letters and other Unicode oddities allow those with more nefarious intentions to set up a domain that, when rendered, displays as a well-known website. The SSL certificates are valid, and everything else checks out. Cyrillic includes characters that visually look identical to their Latin counterparts but are represented differently. The opportunities for hackers and phishing attempts are too great, and so far, punycodes haven’t been allowed on most domains.
For example, can you tell the difference between these two domains?
Some browsers will render the hover text as the Punycode, and some will keep it as its UTF-8 equivalent. The “a” (U+0061) has been replaced by the Cyrillic “a” (U+0430), which most computers render with the exact same character.
This is an IDN homograph attack, where they’re relying on a user to click on a link that they can’t tell the difference between. In 2001, two security researchers published a paper on the subject, registering “microsoft.com” with Cyrillic characters as a proof of concept. In response, top-level domains were recommended to only accept Unicode characters containing Latin characters and characters from languages used in that country. As a result, many of the common US-based top-level domains don’t accept Unicode domain names at all. At least the non-displayable characters are specifically banded by the ICANN, which avoids a large can of worms, but having visually identical but bit-wise different characters out there leads to confusion.
However, mitigations to these types of attacks are slowly being rolled out. As a first layer of protection, Firefox and Chromium-based browsers only show the non-Punycode version if all the characters are from the same language. Some browsers convert all Unicode URLs to Punycode. Other techniques use optical character recognition (OCR) to determine whether a URL can be interpreted differently. Outside the browser, links sent by text message or in emails, might not have the same smarts, and you won’t know until you’ve opened them in your browser. And by then, it’s too late.
Challenges aside, will Punycodes get their time in the sun? Will Hackaday ever get ☠️📅.com? Who knows. But in the meantime, we can enjoy a clever solution proposed in 2003 to the thorny problem of domain name internationalization that we still haven’t quite solved.














I wonder what smart hackaday reader first claims xn--h4hw230o.com
xn--vr-gnna-gv-y-7yibjt9b6c5bk.xn--p-lmb
Article is about why you can’t.
A simpler solution is to simply prohibit the registration of domains that mix linguistic codepages.
Is a dot in every code page(or however that works) or could you no longer use the domain possessive of a subdomain notation of dots?
A simple solution for most of us would be to block any puny code domains. Most of us will never need them.
Those who do, should block all but their character sets, so a Korean user would allow only Korean characters, and still can’t be tricked by a Cyrillic a.
It’s not 100% foolproof for everyone, but probably would protect well over 90% of global users.
I have my punycode domain for aesthetic reasons, it’s http://citrastructuræ.net (but http://citrastructurae.net works as well)
Notifying when the punycode is mixed within a link is pretty good. Or you could ask the user which languages/encodings they want to see, right?
I’d wager that 50% of all global user may find domain names in their native script, which is not covered with [a-z0-9], appealing. As a German I find that substitution of umlauts awful (e.g. the French don’t do that).
Yes, but as a German you still don’t want a Cyrillic ‘a’. So only German should be enabled for you.
I see the Cyrillic a differently in Firefox on Windows 10. The center stroke angles up to the right while the actual a curves. But in this text field as I’m typing it’s showing the a with the up-slanting middle. When I copy and paste both versions of the displayed text, what’s pasted is the same.
Yet another “Can We” rather than “Should We” problem.
Followed by hundreds of cobbled together workarounds.
And the vulnerability fixes have made it impossible to post certain information in pretty much every comment section on the internet…yay.
Example:
This could be a post talking about how random posting systems will aggressively turn anything resembling a URL into a clickable link. People are obviously too lazy to copy/paste this sort of thing. And doing so also let’s advertisers normalize the idea of putting links to products into every block of text.
You could then give an example like ThisIsNotAValidURL.com
Except some sites will simply scrap the entire comment if you do.
The solution? Make it NOT a valid URL, by putting 1 or more zero-width spaces in there.
Problem solved!
…until the zero-width space is now somehow valid, and now an exploit.
New solution? Just ignore zero-width spaces.
Suddenly Fake[zero-width space]URL.com becomes valid. And is now a link. And will likely cause the comment to be deleted.
Congradulations! Now every URL posted on the internet will be valid! Even if you were talking about hypotheticals.com , examples.org , OrEvenWritingAStoryThatHappensToHaveURLs.local
When you talk about URLs, they become real…
Some simply don’t allow URLs for abuse reasons. Maybe that’s why we don’t have post edit because people will abuse it.
I have never used a site banning URLs more than once. Any site that doesn’t allow links* is obviously not unterested in grown-up discussion or evidence to back up opinions. Life is too short to waste time in such cesspools.
*Moderation is fine. Sensible blacklists are fine. But a blanket ban on URLs? Not worth your time to hang out there.
And yes, you can from there find the regulations for domain names (like IDN) under .se and .nu top domains.
UTF 8 with variable width characters created all kinds of problems. UTF 32 and ASCII use fixed width characters, and many things were/are much simpler.
Or use a modified UTF-16 like JavaScript and get the worst of both worlds!
🌈✨.to here :)