If you program using values that represent anything in the real world, you have probably at least heard of the Kalman filter. The filter allows you to take multiple value estimates and process them into a better estimate. For example, if you have a robot that has an idea of where it is via GPS, dead reckoning, and an optical system, Kalman filter can help you better estimate your true position even though all of those sources have some error or noise. As you might expect, a lot of math is involved, but [Pravesh] has an excellent intuitive treatment based around code that even has a collaborative Jupyter notebook for you to follow along.
We have always had an easier time following code than math, so we applaud these kinds of posts. Even if you want to dig into the math, having basic intuition about what the math means first makes it so much more approachable.
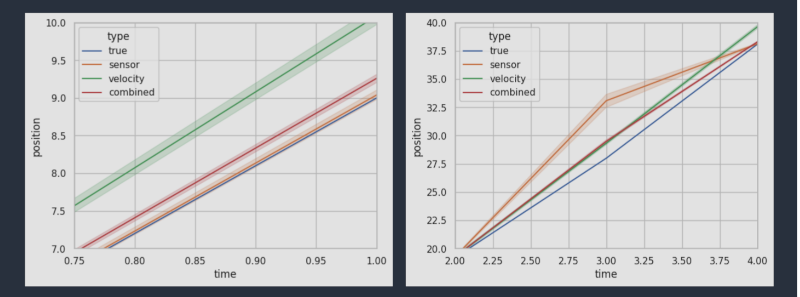
Of course, in the end, there is some math, but nothing complicated unless you count the Wikipedia screenshot showing the “real” math put there to show you what you are missing. The example is a boat with dead reckoning data influenced by random wind and tides and GPS measurements that also have some errors and are sometimes unavailable, just like in real life.
Of course, a simple average of measurements can help, but it can also throw off a good reading. The Kalman techniques use weights of the sources to mitigate this so that seemingly more reliable sources contribute more to the final answer than less reliable ones.
If you prefer a robotic example, we’ve had them, too. If you want something simple and, perhaps, less capable, there are other ways to clean up noisy data.














I feel like the book length docs to filterpy deserve a mention here if not a while article. They’re where I learned filtering theory and make a great complement even to a rigorous mathematical treatment. They are here https://github.com/rlabbe/Kalman-and-Bayesian-Filters-in-Python
Same, filterpy is great.
Why would you add some random estimated fluctuations to your measurements?
Depends.
IIRC, with many measurements you can use it to fight quantization error and actually extract values beyond the accuracy of your measurement tool.
Beyond that, if you have sources of radically differing precision, then I bet something like this can help you combine and reconcile the coarse/fine measurements, and even build off them! This works well for something like GPS/IMU, where one is high precision but drifts like a drunkard a 0200 and the other one can barely tell you what room you are in, but will give you the same answer a year from now.
Statistics is crazy – you can take two different data sources afflicted by different noise and basically polish them against each other until you have a (noticeaby) bettet result!
“Statistics is crazy – you can take two different data sources afflicted by different noise and basically polish them against each other until you have a (noticeably) better result!”
This.
Isn’t this purely to simulate noisy sensors in the example code?
I believe so. observed value = truth + noise — making simulated observations requires adding noise. Certainly the classical Kalman filter doesn’t have any clever noise shaping.
The basic premise that you combine different estimates in proportion to their reliability is 95% of the action of the KF.
The rest is just running linear regressions to get the estimates and a running estimate of their reliability.
I thought it might be referring to the simulation, but then this quote didn’t make sense:
“Now if these passengers actually had good methods for estimating wind and water speeds, they’d use it. But since they don’t, they are estimating the effects by using random numbers”
That’s certainly confusing, and maybe wrong.
It looks like they’re running the prediction step there (everyone is guessing where they’re going to be based on velocity). And that’s certainly done without adding in any extra noise.
E.g., to reflect the actual inaccuracy of the said measurements.
Instead of using normal distributions, they are simulating normal distributions by drawing 1000 random numbers from each. So they are not adding noise to the measurements, but sampling from a distribution they use in the model. The part you quote later is about the dynamic model of the Kalman filter: If you assume the noise to be zero there, you would not need to bother with the measurements and could calculate the position for any point in time exactly and in advance.
“Without process noise, a Kalman filter with a constant velocity motion model fits a single straight line to all the measurements. With process noise, a Kalman filter can give newer measurements greater weight than older measurements, allowing for a change in direction or speed.” See: https://se.mathworks.com/help/fusion/ug/tuning-kalman-filter-to-improve-state-estimation.html
What they mean in the quote is that since they don’t have a view of how the wind and water speeds actually affect the motion model, they give it a zero mean and wide enough variance that the dynamic model can at least somewhat agree with measurements so the fusion works. The filter tends to break down if you trust one or the other too much, as there is no sensible way to combine the results (from the dynamic model and the measurement model) if they disagree with zero practical overlap.
Ah good post, takes me back early 1980’s as cut my teeth on this in a 16 bit MPU product
Worked with an PhD grad (Indesa R.) from India who came over to Mt Newman mining co in Perth,
Western Australia to advise on filtering counts from two Cs137 (beta) sources spaced vertically
1m apart in line with falling iron ore passing radiation through the ore horizontally to scintillation
counters.
Once the system as a whole well calibrated the counters offered different rates well proportional
to iron mass flow overall all this on the first 16 bit MPU by National Semiconductor the Pace-16
with not just UV eproms (2716) but, paper tape backup – yikes.
The output calculation of mass flow went to Foxboro controllers to manage ore flow rates
onto screens of various grades prior to shipping…
Indesa’s Kalman based filter algorithm was programmed into a Forth like structure in assembler
ie the language primitives as subroutine calls for most part, hats off the the initial systems
designer Dave Gibson, the math of that calculation heady but, practical, worked to 2-5% accurate,
these days I think its a bit better with few areas of augmentation re beam geometry and much
faster processing…
Have been looking at Kalman filters in various forms since then and more so last year or
so on a very interesting niggle in electro-magnetics in conjunction with diverse usage
of conventional magnetic sensor hardware – so far not researched much if at all, odd that…
Thanks for post, nice to see this up for discussion on a practically oriented forum,
Looking forward to comments, cheers
You provided zero practical information. Your trip down memory lane was just that.
And that’s okay. I enjoyed reading it. Thank you, Mike!
Thanks Arya,
Much appreciated :-)
Imho we shouldn’t let ourselves be dissuaded or bullied by itinerant facile complainers who add absolutely nothing only, intending only to insult, criticise & thus displace others consideration of means to advance dialectic, whilst making false claims of “zero” when there are so many growing diverse areas of exploration grounded upon long time practical experiences.
Ive been on these sorts of forums a few times, I and others can bring perspective from decades of investigations which, with application to newer technologies can offer more than mere clues to progress and in so many areas too, especially my interest in food chemistry concerning declining minerals connected with “classic” western diseases…
Cheers
fexwey you betray your; intent, demeanor and “even more” rather overwhelmingly ;-)
Nothing whatsoever useful in your one liner, give it a bit more teeth, might get somewhere :D
Headline: “Kalman Filters Without The Math”
Article: “Of course, in the end, there is some math, but nothing complicated unless you count the Wikipedia screenshot showing the “real” math put there to show you what you are missing.”
This is a very confusing start of my day…
Previously on Hackaday: “The AI Engine That Fits In 100K”
Spoiler: It uses the enormous existing databases to do the real work…
Another one but less obvious: “Examining Test Gear From Behind The Iron Curtain”
Now is this one about examination of test gear that was build behind the iron curtain OR is it about observing any kind of testgear (that could be build anywhere around the world), but behind the iron curtain (which would be difficult since the iron curtain is gone a few decades now). So I’m betting on the first one, but since clickbait happens all the time I guess I’ve got to read the article to know fir sure, darn they’ve got me again. Although some people might even think this is about curtains made of iron, like chain mail.
I think I’m addicted to clickbait, as I keep coming back for more.
Definitely clickbait! There was no curtain!
Don’t agree. What i read \ think about the header:
“Examining Test Gear From Behind The Iron Curtain”
is going to be
“Examining Test Gear build in the USSR” (from before the split).
The real advantage of Kalman type filters (there’s more than one!) is that they predict the result rather than calculating the result retrospectively and so dont suffer from lag.
@Reluctant Cannibal said: “The real advantage of Kalman type filters (there’s more than one!) is that they predict the result rather than calculating the result retrospectively and so dont suffer from lag.”
That’s one reason Kalman filters are used so often in precision timekeeping.
Having maths expressed as code is such a great idea. Personally, I found that each mathematician has there own notation and even then it’s not consistent so can increase the confusion factor. Code can be compiled and run to produce graphs etc and the nomenclature is not ambiguous. Most students use Matlab now, so hopefully things will improve.
turns out it’s the same math..
It’s really only simpler because the type of application is simple. There’s no predictive model.
Measurement Noise Recommendation for Efficient Kalman Filtering over a Large Amount of Sensor Data
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6427546/