If you’ve ever worked on a large project — your own or a group effort — you know it can be difficult to find exactly where you want to be in the source code. Sure, you can use ctags and most other editors have some way of searching for things. But ClangQL from [AmrDeveloper] lets you treat your code base like a database.
Honestly, we’ve often thought about writing something that parses C code and stuffs it into a SQL database. This tool leverages the CLang parser and lets you write queries like:
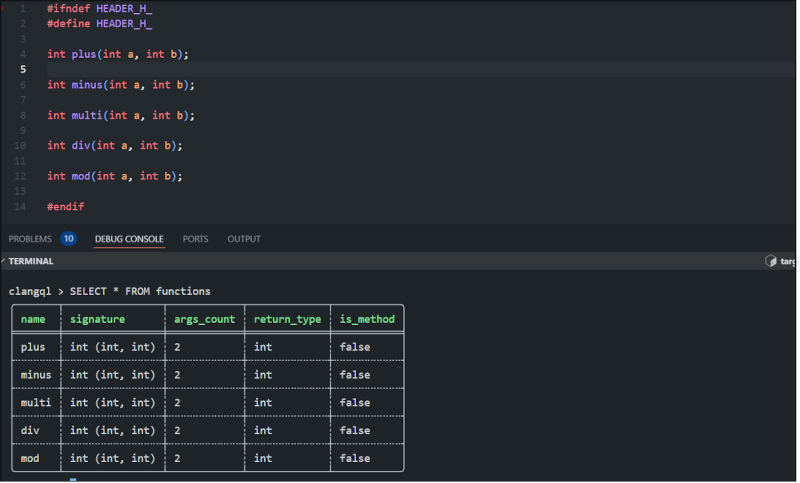
SELECT * FROM functions
That may not seem like the best example, but how about:
SELECT COUNT(name) FROM functions WHERE return_type="int"
That’s a bit more interesting. The functions table provides each function’s name, signature, a count of arguments, a return type, and a flag to indicate methods. We hope the system will grow to let you query on other things, too, like variables, templates, preprocessor defines, and data types. The tool can handle C or C++ and could probably work with other CLang front ends with a little work.
This would be great for estimating the difficulty of tasks. Imagine asking for how many functions return a float when trying to decide how long it would take to switch to fixed point. We plan to try it on a source tree for the Linux kernel and give it a spin.
Truthfully, we’ve long been surprised databases haven’t taken over as file systems and source code anyway. A lot of what we do in git could be done in a database. And vice-versa.














FIND bug TYPE memory_leak WHERE all
Don’t use dynamic mEmoRy.
Select optimized code from spaghetti
Reverse engineering software packages like JEB, JADX, Ida Pro and Ghidra actually saves decompiler code in a database like format, actually. It’s noting new. Until someone decides to implement an open source version
Update private_vars set (select irrelevant_vars)=concat(function,’_’,irrelevant_var) where vars_make_no_sense_or_are_too_long with ai_query(best_prompt);
So I was very interested in this and the author’s similar *QL projects and after drilling down into the code I found it to be yet another poorly implemented database. I like from scratch implementations as much as the next programmer but small in memory databases are a solved problem! Seriously, just use sqlite, it’s a small efficient library that is absolutely bulletproof.
Fair comment from a practical standpoint. But sometimes it’s more about the journey than the end product, and doing it all yourself is interesting/fun. Still an interesting idea, either way.
SQLite is shit if you don’t want to write your code in strings or if you just want unstructured data. Saying something is a “solved problem” means nothing.
Except it does. Not to insult this project but I worked at a place 20 years ago that had something like this, except you didn’t write sql. And to give a better example than what’s in the article, you’d use it for stuff like “we’re adding a new field to a database table. Show me every program that references that table” so you knew the entire list of source files you’d need to look at to see if they needed updates, and could compile all of them for testing. Iirc we also integrated our source control so you could check them all out in one go.
This was all stored in a database, updated at each code check in. The database was the same commercial product or application used (think something like MSSQL, although that wasn’t the specific product. ) saves a ton of time.
Sounds like a fit for DOP.
https://www.manning.com/books/data-oriented-programming
It’s funny to see that it’s implemented in rust.
Hammer looking for a nail disease. *QL is not the way, young padawan. Let it die in peace.
Does C not have a LSP compatible thing like every other major language?
“A lot of what we do in git could be done in a database.”
Which is what Fossil does. No coincidence it was created by the same guy as SQLite.
Also, Git is already a bloody database… NoSQL, but a database nevertheless.
Git noobs.
Yes, of course. So is your plain old file system, a spreadsheet (just puked a little), a drawer full of papers, or a pile of mail on the floor.
git rekt: Git is already a database, always has been. If you didn’t already know that, and have been wishing it were this whole time, I genuinely suggest you learn more about Git.