With performance optimizations seemingly having lost their relevance in an era of ever-increasing hardware performance, there are still many good reasons to spend some time optimizing code. In a recent preprint article by [Paul Bilokon] and [Burak Gunduz] of the Imperial College London the focus is specifically on low-latency patterns that are relevant for applications such as high-frequency trading (HFT). In HFT the small margins are compensated for by churning through absolutely massive volumes of trades, all of which relies on extremely low latency to gain every advantage. Although FPGA-based solutions are very common in HFT due their low-latency, high-parallelism, C++ is the main language being used beyond FPGAs.
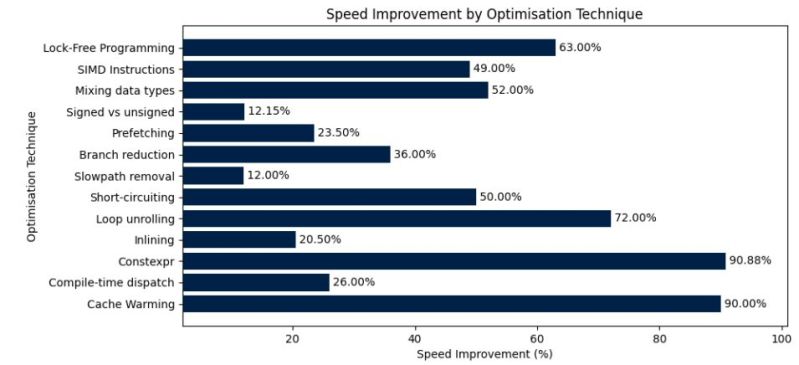
Although many of the optimizations listed in the paper are quite obvious, such as prewarming the CPU caches, using constexpr, loop unrolling and use of inlining, other patterns are less obvious, such as hotpath versus coldpath. This overlaps with the branch reduction pattern, with both patterns involving the separation of commonly and rarely executed code (like error handling and logging), improving use of the CPU’s caches and preventing branch mispredictions, as the benchmarks (using Google Benchmark) clearly demonstrates. All design patterns can also be found in the GitHub repository.
Other interesting tidbits are the impact of signed and unsigned comparisons, mixing floating point datatypes and of course lock-free programming using a ring buffer design. Only missing from this list appears to be aligned vs unaligned memory accesses and zero-copy optimizations, but those should be easy additions to implement and test next to the other optimizations in this paper.














Moore’s law may not have run out quite yet, but it’s slowing down, while software bloat isn’t, so I think software performance is going to become a much hotter topic.
I mean, it always was at a very low level (compilers, game engines etc.), but no one wants to talk about the serious issues with high-level performance, like, how come opening a Word document was faster in 1997. IMO we’re due for radical rethinking of how software is made.
PS:
it’s just Imperial College, no “the”.
single thread performance have barely increased in a decade
Brother the 14th gen i9 has 58% faster single thread performance than the 10th gen i9 which came out in 2nd half of 2020
How did you come to that conclusion? Single threaded performance increases with almost every new processor generation just like IPC, clock speed, RAM speed and other things.
I think the proliferation of accelerators will, in effect, extend Moore’s law for at least another decade. It just requires a complete rethink of compiler architecture for reasonable implementation, a la Mojo.
I agree with your conclusion, but that’s not technically what Moore’s law is.
In common parlance, Moore’s law seems to be “hardware gets faster”, while true, that’s an incorrect formulation. It’s technically the transistor density of transistors increasing (doubling) every 18 months to 2 years. That is what is slowing down/becoming not economically viable. Moore’s law allows performance improvements by just throwing more transistors at problems. Accelerators are a more focused method to eek out more performance wins.
This is about latency, not performance.
Some even regard C++ an abuse of computing power, however (very) skilfully it may be used. Nowadays they teach Python!?!?
Python is great, until it takes 10 hours to run some code that in C++ takes 30 minutes.
However, it might take you 10 hours to write that C++ code and only 30 minutes to write Python?
> ahah le funny word swap!! 1! 1!
Ever heard of recurring costs?
Despite the smugness, the word swap is accurate. There’s a reason most data science tools are wrapped with Python.
Recurring costs are negligible when factoring in maintenance costs, y’know that phase software spends 80% of its life in.
It’s a balancing act.
Why are data science tools wrapped in python and not written in python? Python is effectively used as a scripting language to coordinate running tasks in much faster compiled languages. Someone has already spent the time to write the code in a faster language, just not the person using the code.
You example doesn’t prove your point like you think it does. It proves that in data science they think faster languages wth longer development times are generally better they just wrap it in something easier to use at the end.
In this case it took a few weeks to write Python code to compute full period Xorshift coefficients for arbitrary integer sizes, and then 2 days to port over to C. Mildly anecdotal, but I did find that Python is much much slower at most tasks. I had to un Pythonize my Python code after bc thr C code revealed all the extraneous parts of my design.
It just depends. Heavy compute-level stuff actually isn’t hurt by Python much so long as the Python code is basically playing traffic cop to the compute portions coded in C (e.g. numpy). But threaded stuff/UI/etc. that require lower latency just dies hard.
I had a DAQ system coded in Python pushing ~100MB/s of data throughput (limited by I/O) where the data was calibrated on the fly (in chunks) and I benchmarked pure C vs Python and the overhead was negligible (10-20%) and unimportant due to the I/O bound.
For code some of my colleagues used, it was *faster* because they didn’t understand the importance of minimizing copies and using numpy/transpose does it for you.
It just stresses the importance of knowing where the bottlenecks are. It’s the age old problem of someone optimizing a function to make it 10x faster when it takes zero percent of the effective runtime.
I attended a code club introduction session at my university. They started off with a leetcode problem and we had to solve it in python. My first attempt was to try to solve it logically and sequentially like you would in C, my result was very slow. It was so unintuitive to get a fast result using all kinds of abstract concepts like maps or hash tables for what should have been a simple logical and arithmetical problem. So I decided to try it in C, first try I got a fast time just doing it logically with a for loop. Much simpler, much more basic concepts, just basic maths and so much faster than even the fastest python results.
I understand why people use python. I use it too for certain things but if you have to go and learn the “pythonic” way of doing things and add a lot more complexity then why not just learn C and solve it simply and get faster results?
“It was so unintuitive to get a fast result using all kinds of abstract concepts like maps or hash tables”
In some sense this is like saying “why does math use all this complicated notation, it’s more intuitive to just use basic arithmetic notations.” Yeah, the first time you come across certain concepts, sure, but once you use them more and learn *why* things are useful, it becomes more intuitive that way as well.
A leetcode test isn’t exactly a good example, though. Python gives you a lot of things “for free” – extensibility, portability, etc. – that just don’t matter in the slightest in an example like that.
https://xkcd.com/1205/
still just as true today..
Yeah, that will be true till the end of time, unless time changes pace …
If you need to run the code once then that may be fine, if you need to run it many times then a longer development time but much faster run time is generally much better.
” how come opening a Word document was faster in 1997. ” ?
In 1991, MS released Visual Basic (classic).
In 1993, MS incorporated VBA into MS Office.
VBA can/does utilize ActiveX and COM dlls for interaction with Office Applications.
And it continues to “grow” from that time as the sales group needed “more, more, more” to justify the price.
MS == Mighty Slow
Vba is for the most part abandoned by Microsoft. Sure it’s still there, I use it quite a bit at work. But MS are now pitching Power Automate and such which is terrible. Or python.
Vba is great at getting stuff done. I get it’s long in the tooth, but I still use it all the time.
Finally, a worthy and very relevant article!
I’ve often wondered, if code was written today, with as much skill as it was when every byte and clock cycle counted, how powerful could a moder computer be. I’m reminded of some of the incredible things that came out of the DOS demo scene and things like the inverse Fourier transform shortcut, we probably wouldn’t see anyone do that now outside cryptographic agency work. Imagine the amount of 8080 processors that could be crammed into an i7 or some larger server die, even with a small pool of memory each and some interconnects, that’s still a huge amount of parallel processing capability, if it could be kept cool.
If it was the case, Crysis would actually run decently at max setting with fully optimized code. But that would be “too much work” so they just went “runs without crashing, good enough”
I’d heard that each core in an Nvidia gpu is about equivalent to an original z80, so we are there already. The challenge comes in finding them all something useful to do, which is why they are only used for massively parallel tasks like graphics, machine learning or bitcoin mining.
On one hand you would end up with very efficient code and resource usage, but on the other hand everything would take so much longer and we wouldn’t have most of the systems we have today.
There needs to be a balance, code needs to be well written but still fast to develop, unfortunately people have gone far too far towards the fast and cheap to develop side, if it works then they have done their job, it doesn’t matter if performance is nowhere near where it should be.
I wish older systems and older software being faster and more responsive than their modern successors was a joke but it really isn’t.
Another upside of better optimised and better performing code is that it is generally better thought out which leaves lower potential for bugs or instability.
I feel like I’m missing something here. If it’s solvable with a simple for loop, what precluded you from just using a loop in python? 🤦🏼♂️
I don’t want to be impolite, but they should have compiled with optimizations enabled… yes I can do that, but it also means the results don’t make sense.
As expected most major improvements are compiler related and not really that related to the actual code, not to say code optimisations are not important.
Welcome to the embedded world, boys. We’ve been doing this forever. When you get a new setup:
Always check the output of the compiler to see if it’s optimal and whether you can promote certain code patterns (loops are a common one here) or whether you need to dive into assembler.
Always look at the output of library code to see if you can do it better. Unaligned copies are usually low-effort/low-efficiency implementations.
High frequency trading is an economic parasite that will no doubt contribute to the next economic collapse.
Engineers really need to think more closely about what they’re working on sometimes.
This is the real issue. Might as well teach writing malware
Totally agree: from a fundamental perspective there’s no benefit to it. Economic situations can’t change that fast. I have no idea why trading isn’t done in lockstep atomic chunks of time.
Really frustrating because I’ve got the skillset to do well in it but I can’t ethically bring myself to do it.
Although high frequency trading is parasitical, there aren’t many people doing it. Also, it involves margins so low that it doesn’t impact the value of the main trade that it’s leeching off. It just doesn’t matter.
Economic collapses are almost entirely the effect of government action: wars, regulations, taxes, corruption, watering the currency — they all cripple production. Even the private activities of a destroyer like George Soros require a government to work.
Frauds and Ponzi schemes can cause great damage, but cannot cause economic collapse, and they can do more damage than high frequency trading.
As for engineers needing to think more closely about what they’re working on, remember that not all engineers are ethical, a property they share with all other professions.
> Even the private activities of a destroyer like George Soros require a government to work.
Keep your conspiracy theories off of Hackaday. Thanks.
It’s symptomatic, though: HFT isn’t big enough to cause collapses, but the basic idea of trading being a technology/math battle rather than investment is. Your definition of collapse might be different, but plenty of damage has been done by that mindset.
Same patterns in all the other real-time domains – telecom, robotics, etc.
my 2002 copy of excel is WAY faster than the current bloatware version and is great on modern hardware.. And there isn’t a single feature I need from the current bloatware mess…
Or you could use “C”.