Here’s something fun. Our hacker [Willow Cunningham] has sent us a copy of their homework. This is their final project for the “ECE 574: Cluster Computing” course at the University of Maine, Orono.
It was enjoyable going through the process of having a good look at everything in this project. The project is a “cluster” of 5x Raspberry Pi Pico microcontrollers — with one head node as the leader and four compute nodes that work on tasks. The software for both types of node is written in C. The head node is connected to a workstation via USB 1.1 allowing the system to be controlled with a Python script.
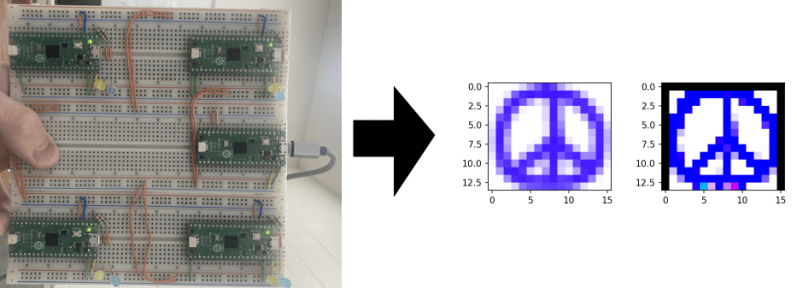
The cluster is configured to process an embarrassingly parallel image convolution. The input image is copied into the head node via USB which then divvies it up and distributes it to n compute nodes via I2C, one node at a time. Results are given for n = {1,2,4} compute nodes.
It turns out that the work of distributing the data dwarfs the compute by three orders of magnitude. The result is that the whole system gets slower the more nodes we add. But we’re not going to hold that against anyone. This was a fascinating investigation and we were impressed by [Willow]’s technical chops. This was a complicated project with diverse hardware and software challenges and they’ve done a great job making it all work and in the best scientific tradition.
It was fun reading their journal in which they chronicled their progress and frustrations during the project. Their final report in IEEE format was created using LaTeX and Overleaf, at only six pages it is an easy and interesting read.
For anyone interested in cluster tech be sure to check out the 256-core RISC-V megacluster and a RISC-V supercluster for very low cost.














“It turns out that the work of distributing the data dwarfs the compute by three orders of magnitude.”
An excellent project and an excellent learning exercise. Nice work. :) And this experience will inform his work for years. This is why doing these projects are so important, to learn. Core principled of science is reproducibility and not taking someone’s word for it. Detractors of these kinds of project say “what is the point, just get a cheap PC” and they are missing the point and the fun in building these mini clusters.
Good work Willow Cunningham. :)
+1
Now you know why PCIe 7.0 is going to be so fast.
Seems that another student could use this project as a springboard to implement faster data transfers via less conventional means.
hahah yeah my heart was exploding with “that the work of distributing the data dwarfs the compute by three orders of magnitude!!!” but then there it was right there on the page
As is so often the case, it’s quicker to do the job yourself than to delegate it to someone else…
But why waste time on hardware when the entire project could be done with QEMU on a single 8-core CPU. It’s not like it’s still 2008 and dual-core Wolfdale is the duck’s guts.
You’re no fun! :)
12 and 20 core CPUs are cheap. 14700 is around $200 if you go looking. Tough to beat for raw compute. Did a BMW Blender render in 24 seconds on the one I built. 14400 is probably the price/performance leader though. Although when I see a $154 12700KF (Amazon) or $170 Ryzen 7700 (SZCPU) it gives me pause.
The point is the challenge, not the result.
I was just saying if you are going QEMU why stop at 8 cores?
8 is midrange, soon to be entry level.
Also a modern $80 6 core like 8400F can probably do 8 cores worth of work.
Power to run them, though is not cheap.
Is it convolution or deconvolution in the image ?
I am not an expert but I do believe convolution is the correct term. https://en.wikipedia.org/wiki/Convolution#Discrete_convolution
looks like deconvolution since it’s deblurring, but since deconvolution is convolution with the inverse point spread function, then I guess you can also call it ‘convolution with a kernel for sharpening’
Maybe he shouldn’t have used I2C for inter node communication? Its all about the learning
I was thinking the same. I hate I2C with a passion. Slow and unreliable. SPI would have been better. I think you can even implement QSPI with the PIO blocks.
There’s enough (in this case unused) I/O to make an extremely high bandwidth custom communications channel between these chips, but I somewhat understand the desire to go with something standard, to reduce complexity of the overall project.
Yes I was thinking the same thing. It would be interesting to run the experiment again using SPI. Just for fun, naturally. I would be that the system would still be IO bound even if we used SPI or QSPI.
Eyup
QSPI, or even better if the project allows it, shared RAM module.
Granted, one have to order the access, but that shouldn’t be too hard to do.
But kudoes anyway to him, that’s a very nice project as is!
I think a Pico can be used as a virtual RAM chip, so it’s possible that could handle the accesses.
Also if the project scales up it might be better to use bare RP2040 (or the new chip), and share the power lanes. Imagine a SBC size device with 10-20 RP2040 chips on it 😂
I think SPI with DMA would be nearly ideal for moving image rows between devices. Or maybe a 4 or 8 bit parallel with DMA. I did not see DMA in the docs but the M0 can do it.
Might be fun to use the cluster to run some machine learning stuff.