Before the past year, many of us took computer memory for granted. It was one of the lower-cost parts of a PC build and was usually available in whatever quantity one desired. As its cost has skyrocketed, a lot of PC builders and other users of computers in general are taking a deeper look at memory, how much is really needed, and what its functions truly are. [Igor] is working on a drum sequencer project which needs a small amount of memory, and has built this dynamic RAM from discrete components.
The first video goes into the construction of the memory array and how its addressed. It’s only eight bytes total, and using fairly large electrolytic capacitors to store data means that a gigabyte of this memory would take up well over a thousand acres, but it’s still enough memory for [Igor]’s needs. In addition to the capacitor, each bit uses a pair of diodes to determine if a read or write is occuring, and a set of transistors on the read and write busses to perform those actions. Worth noting here is that dynamic RAM like this needs to be refreshed because the capacitors lose charge over time, but these large capacitors can hold charge sometimes overnight, as [Igor] has confirmed experimentally.
There’s a followup video to the construction of these modules as well, where [Igor] demonstrates a number of ways this module can be used, from controlling LED arrays, 7-segment displays, and then installs it into his drum machine. With 64 bits available it’s capable of creating up to eight beats with eight samples available per beat. Although there are complete machines available for all of this, we appreciate his goal of not buying any pre-manufactured hardware and instead constructing it all from the ground up. There are analog drum machine options available in this same style as well.
Modern computers use dynamic RAM, a technology that allows very compact bits in return for having to refresh for about 400 nanoseconds every 3-4 microseconds. But what if you couldn’t afford even such a tiny holdup? [LaurieWired] goes into excruciating detail about how to avoid this delay.
But first, why do we care? It once again comes down to high-frequency trading; a couple nanoseconds of latency can be the difference between winning or losing a buy order. You likely miss all the caches and need to fetch data from the remote land of main memory. And if you get unlucky, you’ll be waiting on that price for a precious 400+ nanoseconds! [Laurie] explains all the problems faced in trying to avoid this penalty; you try to get a copy of the data on two independent refresh timers. That’s easier said than done; not only does the operating system hide the physical addresses from you, but the memory controllers themselves also scramble the addresses to the underlying RAM!
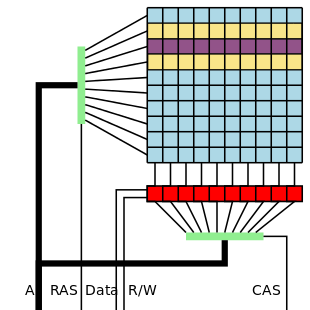
The technique is deceptively simple. Dynamic RAM is organized into a matrix of rows and columns. By performing fast reads on addresses in the same row, bits in adjacent rows can be flipped. In the example image to the left, fast reads on the purple row can cause bit flips in either of the yellow rows. The Project Zero team discovered an even more aggressive technique they call “double-sided hammering”. In this case, fast reads are performed on both yellow rows. The team found that double-sided hammering can cause more than 25 bits to flip in a single row on a particularly vulnerable computer.
Why does this happen? The answer lies within the internal structure of DRAM, and a bit of semiconductor physics. A DRAM memory bit is essentially a transistor and a capacitor. Data is stored by charging up the capacitor, which immediately begins to leak. DRAM must be refreshed before all the charge leaks away. Typically this refresh happens every 64ms. Higher density RAM chips have forced these capacitors to be closer together than ever before. So close in fact, that they can interact. Repeated reads of one row will cause the capacitors in adjacent rows to leak charge faster than normal. If enough charge leaks away before a refresh, the bit stored by that capacitor will flip.
Cache is not the answer
If you’re thinking that memory subsystems shouldn’t work this way due to cache, you’re right. Under normal circumstances, repeated data reads would be stored in the processor’s data cache and never touch RAM. Cache can be flushed though, which is exactly what the Project Zero team is doing. The X86 CLFLUSH opcode ensures that each read will go out to physical RAM.
Wanton bit flipping is all fine and good, but the Project Zero team’s goal was to use the technique as an exploit. To pull that off, they had to figure out which bits they were flipping, and flip them in such a way as to give elevated access to a user level process. The Project Zero team eventually came up with two working exploits. One works to escape Google’s Native Client (NaCL) sandbox. The other exploit works as a userspace program on x86-64 Linux boxes.
Native Client sandbox escape exploit
Google defines Native Client (NaCL) as ” a sandbox for running compiled C and C++ code in the browser efficiently and securely, independent of the user’s operating system.” It was designed specifically as a way to run code in the browser, without the risk of it escaping to the host system. Let that sink in for a moment. Now consider the fact that rowhammer is able to escape the walled garden and access physical memory. The exploit works by allocating 250MB of memory, and rowhammering on random addresses, and checking for bit flips. Once bit flips are detected, the real fun starts. The exploit hides unsafe instructions inside immediate arguments of “safe” institutions. In an example from the paper:
Viewed from memory address 0x20EA0, this is an absolute move of a 64 bit value to register rax. However, if we move off alignment and read the instruction from address 0x20EA02, now it’s a SYSCALL – (0F 05). The NaCL escape exploit does exactly this, running shell commands which were hidden inside instructions that appeared to be safe.
Linux kernel privilege escalation exploit
The Project Zero team used rowhammer to give a Linux process access to all of physical memory. The process is more complex than the NaCL exploit, but the basic idea revolves around page table entries (PTE). Since the underlying structure of Linux’s page table is well known, rowhammer can be used to modify the bits which are used to translate virtual to physical addresses. By carefully controlling which bits are flipped, the attacking process can relocate its own pages anywhere in RAM. The team used this technique to redirect /bin/ping to their own shell code. Since Ping normally runs with superuser privileges, the shell code can do anything it wants.
The TL;DR
Rowhammer is a nasty vulnerability, but the sky isn’t falling just yet. Google has already patched NaCL by removing access to the CLFLUSH opcode, so NaCL is safe from any currently known rowhammer attacks. Project Zero didn’t run an exhaustive test to find out which computer and RAM manufacturers are vulnerable to rowhammer. In fact, they were only able to flip bits on laptops. The desktop machines they tried used ECC RAM, which may have corrected the bit flips as they happened. ECC RAM will help, but doesn’t guarantee protection from rowhammer – especially when multiple bit flips occur. The best protection is a new machine – New RAM technologies include mitigation techniques. The LPDDR4 standard includes “Targeted Row Refresh” (TRR) and “Maximum Activate Count” (MAC), both methods to avoid rowhammer vulnerability. That’s a good excuse to buy a new laptop if we ever heard one!