
Project Zero, Google’s security analyst unit, has proved that rowhammer can be used as an exploit to gain superuser privileges on some computers. Row Hammer, or rowhammer is a method of flipping bits in DRAM by hammering rows with fast read accesses. [Mark Seaborn] and the rest of the Project Zero team learned of rowhammer by reading [Yoongu Kim’s] 2014 paper “Flipping Bits in Memory Without Accessing Them:
An Experimental Study of DRAM Disturbance Errors” (PDF link). According to [Kim], the memory industry has known about the issue since at least 2012, when Intel began filing patents for mitigation techniques.
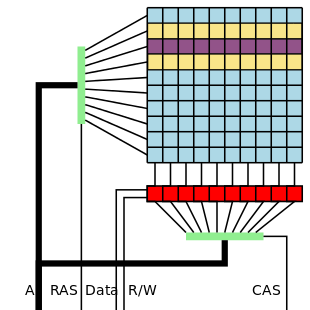
The technique is deceptively simple. Dynamic RAM is organized into a matrix of rows and columns. By performing fast reads on addresses in the same row, bits in adjacent rows can be flipped. In the example image to the left, fast reads on the purple row can cause bit flips in either of the yellow rows. The Project Zero team discovered an even more aggressive technique they call “double-sided hammering”. In this case, fast reads are performed on both yellow rows. The team found that double-sided hammering can cause more than 25 bits to flip in a single row on a particularly vulnerable computer.
Why does this happen? The answer lies within the internal structure of DRAM, and a bit of semiconductor physics. A DRAM memory bit is essentially a transistor and a capacitor. Data is stored by charging up the capacitor, which immediately begins to leak. DRAM must be refreshed before all the charge leaks away. Typically this refresh happens every 64ms. Higher density RAM chips have forced these capacitors to be closer together than ever before. So close in fact, that they can interact. Repeated reads of one row will cause the capacitors in adjacent rows to leak charge faster than normal. If enough charge leaks away before a refresh, the bit stored by that capacitor will flip.
Cache is not the answer
If you’re thinking that memory subsystems shouldn’t work this way due to cache, you’re right. Under normal circumstances, repeated data reads would be stored in the processor’s data cache and never touch RAM. Cache can be flushed though, which is exactly what the Project Zero team is doing. The X86 CLFLUSH opcode ensures that each read will go out to physical RAM.
Wanton bit flipping is all fine and good, but the Project Zero team’s goal was to use the technique as an exploit. To pull that off, they had to figure out which bits they were flipping, and flip them in such a way as to give elevated access to a user level process. The Project Zero team eventually came up with two working exploits. One works to escape Google’s Native Client (NaCL) sandbox. The other exploit works as a userspace program on x86-64 Linux boxes.
Native Client sandbox escape exploit
Google defines Native Client (NaCL) as ” a sandbox for running compiled C and C++ code in the browser efficiently and securely, independent of the user’s operating system.” It was designed specifically as a way to run code in the browser, without the risk of it escaping to the host system. Let that sink in for a moment. Now consider the fact that rowhammer is able to escape the walled garden and access physical memory. The exploit works by allocating 250MB of memory, and rowhammering on random addresses, and checking for bit flips. Once bit flips are detected, the real fun starts. The exploit hides unsafe instructions inside immediate arguments of “safe” institutions. In an example from the paper:
20EA0: 48 b8 0f 05 EB 0C F4 F4 F4 F4 movabs $0xF4F4F4F40CEB050F,%rax
Viewed from memory address 0x20EA0, this is an absolute move of a 64 bit value to register rax. However, if we move off alignment and read the instruction from address 0x20EA02, now it’s a SYSCALL – (0F 05). The NaCL escape exploit does exactly this, running shell commands which were hidden inside instructions that appeared to be safe.
Linux kernel privilege escalation exploit
The Project Zero team used rowhammer to give a Linux process access to all of physical memory. The process is more complex than the NaCL exploit, but the basic idea revolves around page table entries (PTE). Since the underlying structure of Linux’s page table is well known, rowhammer can be used to modify the bits which are used to translate virtual to physical addresses. By carefully controlling which bits are flipped, the attacking process can relocate its own pages anywhere in RAM. The team used this technique to redirect /bin/ping to their own shell code. Since Ping normally runs with superuser privileges, the shell code can do anything it wants.
The TL;DR
Rowhammer is a nasty vulnerability, but the sky isn’t falling just yet. Google has already patched NaCL by removing access to the CLFLUSH opcode, so NaCL is safe from any currently known rowhammer attacks. Project Zero didn’t run an exhaustive test to find out which computer and RAM manufacturers are vulnerable to rowhammer. In fact, they were only able to flip bits on laptops. The desktop machines they tried used ECC RAM, which may have corrected the bit flips as they happened. ECC RAM will help, but doesn’t guarantee protection from rowhammer – especially when multiple bit flips occur. The best protection is a new machine – New RAM technologies include mitigation techniques. The LPDDR4 standard includes “Targeted Row Refresh” (TRR) and “Maximum Activate Count” (MAC), both methods to avoid rowhammer vulnerability. That’s a good excuse to buy a new laptop if we ever heard one!
If you want to play along at home, the Project Zero team have a rowhammer test up on GitHub.














another attack vector: waiting for a cosmic ray to do the bit flip..
Make sure to keep your computers in the basement!
http://www.networkworld.com/article/2172130/data-center/sc13–elevation-plays-a-role-in-memory-error-rates.html
(This was for SRAM, not DRAM, but similar issues apply.)
Or a big ol’ chunk of plutonium!
There might be an issue with radon gas accumulating in basements at least in some parts of the world. The radiation can cause DRAM errors. There are a few patents on using DRAM error as Radon gas detector.
http://www.google.ca/patents/US4983843
At a few floors up, you wouldn’t have to worry about Radon gas, but not running the risk of cosmic rays issue at high altitude.
Radon’s decay chain contains only alpha and beta emitters. They do not penetrate the casing of a memory chip.
And Gamma. After the decay, you’re typically left with an excited daughter nucleus. This is true of all decay modes.
Get a protable partical accelerator.
http://www.sciencedaily.com/releases/2013/06/130620132412.htm
Saying that a software attack “literally hammers” something would only be confusing to someone if you included an actual hammer in the header photo. Oh wait…
+1
Guilty – I abused “literally”. Fixed in the article text.
Yep, you literally abused literally.
I literally smirked at this thread.
I would contest that ‘hammering’ digitally is now in the vernacular and that, while not ideal, saying “literally hammers” is not incorrect.
Now that I think of it. I bet I use the word hammer in the digital sense way more frequently than in the physical sense. But I digress.
Adjacent row / column disturb tests were a standard part of DRAM testing in the 1970’s (we used the 1103, a 1k bit device). That was when driving a DRAM and reading its data was a major challenge, since none of the signals were at anything like regular logic levels. Have manufacturers forgotten how to test their products?
To make things cheaper and bigger some decisions are made that reduce quality. Look at Hard disks for example 5 year warranty period have come down to 1 year..
The warranty is a reassurance against manufacturing defects and faults, which are more probable to manifest right away. A company which offers a product with 12 month warranty, which breaks at month 13, will see its customers flee rather quickly.
The reduction in warranty doesn’t necessarily mean that the product has gotten worse, but that manufacturing tolerances have gotten better and there is no longer that tail of duds that extend up to 5 years from purchase, which need replacement to maintain good public relations. That way one doesn’t need to keep a 5 year inventory of an EOL product just for potential replacements.
Rather, if a product has an excessively long warranty compared to its expected use, that can be an indication that the company tries to reassure you to buy it despite its known high failure rate, on the point that if it fails at least you get a new one.
This of course doesn’t apply to individual cases like Leatherman tools, which have a “lifetime” warranty, because the producer knows you’ll probably forget and lose the tool before you ever think of turning it in for a blade swap.
Not true, life time warranties in some areas do not mean “your life time” but rather product lifetime. This can and is abused by manufacturers. If they release a product with a lifetime warranty but discontinue that product after a year with the “1502a” model your warranty period is now over.
Depends entirely on the area and manufacturer, for instance Mastercraft tools are a legitimate and unlimited lifetime warranty. Break one, bend one, need a shorter wrench and cut it in half with a plasma cutter… No problem, drop it on the customer service desk and go grab a new one off the shelf!
” A company which offers a product with 12 month warranty, which breaks at month 13, will see its customers flee rather quickly.”
That’s a great theory, but in this reality we have “vendor lock in”
What kind of warranty does Microsoft offer?
“You have the right -SLAP- to shut your goddam -SLAP- face!”.
The humiliation of having to take a beating from Paul Allen stops most people complaining.
You don’t have to keep 5-year-old hard drives (sitting there in the dark, lubricants coagulating) to replace a 5-year-old hard drive. Typically if something fails under warranty it’ll be replaced by a new model. Most people wouldn’t complain at getting a 5TB replacement for their broken 1TB drive. If you actually NEED the exact model, it’s your own responsibility to buy a few spares (to sit there in the dark).
I can’t think of reducing the warranty as anything but a bad thing. If only a few go wrong between years 2-5, that’s a small price in replacements for a lot of customer confidence.
I’ve heard that the majority of hardrives that die within 5 years of purchase die in the first 12 months. I personally still have harddrives from 10 years ago still running fine.
Chip testing costs money especially when you are testing large memory density devices that now only cost a few dollars a piece.
The memory chip designers probably knows about these issues, but cannot address it as it would seriously limit the memory density if they move things further apart and larger DRAM cell capacitance. They would assume that there is CPU cache and in some cases ECC/Parity bits and call it a day.
It is very common (issue) for each suppliers (or even your software/mechanical/PCB/Electrical team) to only look into their own area and leave someone else to worry system level concerns. They have enough problem just doing their part of the job.
Usually that’s the engineer responsible for the overall design and pick up the slacks in the responsibilities.
This is a system level issue – added ECC bit in the memory modules could detect the errors and may be correct some of it. The memory controller could add the extra wait states to prevent this if the designers know about this.
If it’s not in the datasheet it’s a bug …
you say: “The memory chip designers probably knows about these issues,”
Really? Why would you say that? Did you read this:
“New RAM technologies include mitigation techniques. ”
If they knew about it and decided that it was an acceptable state of affairs, then why would they take measures to fix it?
Also, why do you call this a “system level issue” when the issue lies solely within the memory chips? As pinky asks, what other parts of the computer are violating specifications? !NONE! Only the memory chips. This is a memory chip issue, not a system issue.
“Leaky” memory chips are the ones people want. Because they’re also cheap, fast, high capacity. You can’t have those without hammer-vulnerability, and you can’t sue the laws of physics. There’s nowhere else you can go to get fast, cheap, etc chips that aren’t vulnerable, cos it’s impossible.
This means the RAM leakage is an insoluble problem, which means everyone else has to shift a bit to accomodate. Make it a system-level problem, or stick to 4116’s and have 512K laptops the size of a briefcase (again!). Blaming things you can’t do anything about is pointless.
Manufacturers must have been aware … it’s not like DRAM is always used with processors with semi-predictable access patterns. I assume it was semi-public knowledge within the industry but left alone for NSA type use.
yeah just like how people intentionally leave bugs in their code for NSA type use
could this be used to get the encryption key to say itunes downloads or even be used to extract un protected content from memory?
It can be used to get root priveliges from an unpriveliged (even sandboxed) process, so the answer to pretty much any question is “yes, but if it was difficult to do with root before, it’s not any easier now”.
To do what you are asking wouldnt need this, this is about breaking out of a protected area and overwriting things you dont have privilege to do.
For your two examples, the best approach would be to load them into a debugger, and execute them, at some point the content will be unprotected and extractable.
However for the key, usually newer programs encrypt your input and compare the hash against the stored hash, they do not decrypt the original in memory, just re-encrypt your input to make sure it matches. Unless there is a error in the implementation this is less useful. However, the usual method is to look at the execution of the protected part of the program and see what it does after its decided if you have permission or not, and patch it so the binary case becomes true for wrong input, or you can set a breakpoint before and step past the JNE breakout or similar.
The rowhammer attack is about programs being ran on systems where they do not have the administrator or root privileges, using the attack to break out their space into a more protected part of address space, so typically a piece of software would be ran with low privs by a low level user, then try to overwrite space owned by a more privileged process for a privilege violation or elevation attack.
I didn’t realize cache operations weren’t privileged on x86! Isn’t that a strange design decision on Intel’s part?
There is no reason for them to be privileged. Use of cache flushing and prefetching instructions can improve performance some software operations like memcpy tremendously.
This is a fault with RAM design not a security problem to be dealt with by changing instructions and software.
You’re right. I think that I was mistaken by the fact that the cacheability attributes of memory are managed by the OS. These instructions do not indeed pose any threat because they are not invalidating/flushing random cache lines, only lines that map to memory owned by the user process… my bad!
Aside from the big and scary “you can be root” exploit, is it not disturbing enough that you can just corrupt RAM at will by reading from it? I mean, how do I know this isn’t happening all the time already?
You don’t.
It does.
That’s one of the reasons why computers crash.
There’s some certain probability that any of the parts of your computer at any time will experience a bit error and corrupt your data. The probability of error in simply copying a terabyte of data from one HDD to another is greater than 1, which is why you compare checksums after making backups.
So you are saying that it is impossible to copy a terabyte or two without corruption? Sure about probability being greater than? Probably that is a new definition of probability.
He is saying the probability is extremely high that data will be corrupted during the transfer, but the OS continuously checks the file(s) after writing and fixes the problem(s) as needed. So, in most cases, you won’t have any problem with the copied file(s). If it can’t correct the problem(s), then you will see the check-sum error.
BS! If the probability is “greater than 1” then there’s no way you can do the transfer error free right? No matter how many times you try.
You will need error correcting codes to implement what you describe. That is HDD firmware level stuff not OS.
Not BS. The probability of at least one error when copying a file of more than one terabyte is 1. ECC is implemented in hardware to help correct the problem(s), and the OS will attempt to re-copy the corrupted data to try to fix the problem(s), and will give you a check-sum error message if it can’t fix the problem(s).
He simply misstated “greater than 1”, rather than stating “equal to 1”.
The chance of an error is never 1 or “over 1”. You’re confusing the expected number of errors with the probability of an error.
There has been quite a bit of conversation on the topic of corrupted RAM in the wild. [Berke Durak] has some interesting links on his site http://lambda-diode.com/opinion/ecc-memory (also read the update). He suggests one bit error per 4GB every three days due to cosmic rays. I’m not saying he’s right – but it is an interesting read. Bits do flip though – and often you get away with it. Not every time though…
Yeah, I saw that… the discussion on Reddit is enlightening. User experience seems to be that random bit errors are rare (based on ECC correction logs), unless the chip itself is dying, in which case cosmic rays are not the pressing concern.
The probability based on a paper from Google suggests something on the order of 3% per DIMM per year.
http://www.reddit.com/r/programming/comments/ayleb/got_4gb_ram_no_ecc_then_you_have_95_probability/
I seem to recall an interview with the creators of a big-name MMORPG (WoW?) on the prevalence of RAM corruption in the wild, but can’t seem to find it now. The gist is the game’s anti-cheat features periodically checksummed its process’s RAM contents for tampering (exploits to give oneself extra items, or whatever), and as a baseline also allocated and checked hunks of memory that were just initialized with garbage and never used by the game. They ended up finding a surprisingly high prevalence of upsets in the wild unrelated to cheating, and were able to correlate the highest prevalences to specific computer and memory manufacturers. These “shouldn’t” happen more than extremely rarely on a well-designed machine, but in practice many real-world machines are not that well-designed (thermal budget / RAM operating temperature is a huge factor too).
The rowhammer use case is very uncommon. It requires literal reads of the DRAM, not reads from it in a normal sense.
In modern CPUs (anything with an MMU) RAM speeds are much lower than CPU speeds. However, reading and writing memory is the most common operation you’ll do. To circumvent the speed limitations of DRAM, currently used RAM is cached in the CPU. That’s what CPU caches are primarily used for.
What this means with respect to rowhammer: If you’re running normally, your rows get loaded once, and they can be read/written all they like in the CPU without any corruption. Then, they’re written back to the DRAM only once, when the cache needs to load something else. The only case where significant corruption happens (multiple row reads in quick succession, or “hammering”) never occurs, since each row is loaded once, used, and updated.
Didn’t know the MMU handled that. I’ve seen lots of DRAM based systems without MMUs.
The effect seems to rely on very large RAM with very fast access, so that the charge is low enough, and can be drained fast enough, to have an effect. Usually systems like that (basically PCs and up, performance-wise) have MMUs. The lower-performance computers that tend to have no MMU wouldn’t be able to mess with the RAM fast enough.
That’s why rowhammer attacks flush the cache lines. Did you read “cache is not the answer” in the article? Google’s solution is to take out the instruction that lets programs do the flushing. Which is fair enough, what sort of sandbox has CPU cache control available? A bit too close to the metal IMHO.
How on earth did you go from “cache is not the answer” to suggesting that cache is the answer in two sentences?
If you read the unfortunately titled paragraph, cache IS the answer, and the rowhammer attack needs to disable cache in order to work. So in the Google NACL case, “not letting programs disable the cache” is the actual, detailed answer.
This functionality problem has led me to think about unexplained mysterious bugs you sometimes encounter when developing low level applications… Unless you know it might happen, hoe else would you explain a sudden memory corruption like this ?
If the problem is repeatable, an explaination is likely to be found by studying the conditions in which it repeats.
If not, you can’t. One may postulate, but for a freak accident there is no way to know and no conclusions to be made.
This is a very particular and deliberate attack. Reading from the same address many times in a row, with cache flushed, is something you’d never have in a normal program. Unless it was either a rowhammer attack, or a really severe memory tester.
Reminds me of the infamous “CGA snow” phenomenon where updating display memory would result in nasty artifacts in adjacent pixels.
That was avoidable with proper techniques, and it was only when the display controller and the CPU were both accessing the same memory
Also have suspicions that some problems on older laptops could be due to this.
I had a spate of random W7 BSoDs on an X520 and also Itunes crashes, Firefox random fail and other problems that happened when running on battery power, yet when the memory (2*2GB DDR3 1066) was replaced with used memory from a scrap machine the problems went away although Explorer still sometimes crashes when plugging in a USB device.
I suspect the issue could have been rowhammer because despite the drive being replaced and a fresh install being done from a known clean drive the problem reoccurred within hours.
Its worth noting that all the chips on the two modules got uncomfortably warm yet the replacements did not so maybe heat buildup makes rowhammer worse?
The battery itself wasn’t the problem as tested it on another machine and all worked fine.
Just run Memtest86+ for some hours, separate test for each of memory sticks you used plugged in, one stick at a time. Problem traced.
Obviously any RAM sold should not be able to be read with the specified timing parameters and have bits flip spontaneously.
If RAM can be read so fast it flips bits then they cheated on the timing specs in my opinion, and it’s grounds for a lawsuit since the product is faulty and sold as such while the manufacturer knew it.
It seems intrinsic to fast, large capacity RAM. It’s not a manufacturing error if it happens for everybody, using the same RAM techniques they’ve always used. And DRAM hasn’t changed from the implied-capacitor-transistor since it was invented.
The only alternatives would be slower or smaller RAM. And industry has already chosen speed and size. You could add protection mechanisms at the input, but that would add latency, and we HATE latency! Fixing it in software, or in the RAM / cache / CPU interface, is the way to do it.
It’s all very well sending every RAM chip made in the last couple of years back to the manufacturers, but where would you run your programs from?
Disabling clflush is not a solution to the problem as you can force cachelines to be flushed with a high probability merely by accessing memory in a certain pattern. It will be a bit more inefficient than using clflush, but I wouldn’t claim that the problem has been fixed for good merely by disabling clflush.
That would require many assumptions about memory and cache sizes that are harder to make than the sample implementation. CLFLUSH guarantees the RAM will be updated. Loading more memory only does if you can guarantee there is no remaining cache, and the caching method doesn’t prefer that RAM over everything else in the system.
But would the time taken by accessing that certain pattern leave enough time for the RAM you’re targetting to recharge? Cos if it did, then the attack wouldn’t work. It relies on hammering the address in question over and over, very fast.
I haven’t tested this myself of course, but note that a cache miss is very fast and a cache miss is very slow. Since CLFLUSH should have very similar timings to a normal cache miss I’m guessing that it will not take that much extra time to run a non-CLFLUSH implementation as it takes to run a CLFLUSH-based implementation.
Sorry, I meant that a cache hit is of course very fast while a cache miss is very slow. To further expand upon this, if you know the associativity of a cache it takes only a few load instructions to force at least one cache line to be evicted (i.e. associativity + 1). (With a few exceptions such as if there is a victim cache or some other special feature, but those can be defeated with a few extra load instructions as well if necessary.)
Wonder if this is a tactic by the manufacturers to get the last % out of substandard parts? Back in the day overclocking of CPUs was a real problem and caused quite a lot of data loss. Typically a CPU with an FSB of 400MHz could be overclocked to nearly 566MHz and it could work very well until it started failing randomly during high precision calculations.
The E2prom chips on memory are in a lot of cases programmed in bulk using a batch system so sometimes you get a few which are substandard but work 99.995% of the time, re-marking of parts is also quite common and very hard to detect unless you know what to look for (ie single word changes in the unused areas of the e2prom)
Also relevant, some high spec machines heatsink their RAM to reduce single bit errors without resorting to ECC or actively cool it with thermal pads to the chassis ie Blades.
For those folks who want to try this with their £229 budget netbook gut an old plasma panel circa 200x and behind the glass screen are large thermal pads which can be used as makeshift heat transfer pads and work very well due to the minimal thermal load.
I just like to congratulate Google on a) Having this wing do this stuff. b) Immediately target their own (supposed) most secure stuff c) Publish the results.
I know they got a lot to lose, but I cant help thinking other companies might not be quite so dedicated to security issues.
The bit flips occur because the charge from the bit-capacitor has depleted before the next refresh cycle because of the “hammering reads”, right? If I remember correctly, DRAM cells hold their charge longer with lower temperature, so can we cool them down to avoid this type of attack?
I suppose, but as RAM cells get smaller, and accesses faster, the problem’s going to come back. You could look at it as a triangle with RAM size / speed / temperature on the corners.
Also exotic cooling is a pain in the arse, or else they’d be doing it on CPUs and graphics chips. I’d guess moving away from air-cooling would cause a massive increase in failure and returns. Liquid-cooling for PCs is an at-your-own-risk kind of affair, sold to people who are aware of what might go wrong.
A subject like this and not a single person mentioned “bit banging”?
I theorized that sufficiently advanced code might be able to use this effect and a very large array of connected laptops to become self aware due to the exponential increase in complexity caused by the quantum interactions and a cemi field analog induced by say the switchmode inverter on the motherboard.
One relatively minor Windows update glitch, virus or combination of zerodays and voila, Singularity.
It is also worth considering that this could be done intentionally by say a hacker bent on world domination.