Evolution is one clever fellow. Next time you’re strolling about outdoors, pick up a pine cone and take a look at the layout of the bract scales. You’ll find an unmistakable geometric structure. In fact, this same structure can be seen in the petals of a rose, the seeds of a sunflower and even the cochlea bone in your inner ear. Look closely enough, and you’ll find this spiraling structure everywhere. It’s based on a series of integers called the Fibonacci sequence. Leonardo Bonacci discovered the sequence while trying to figure out how many rabbits he could make starting with just two. It’s quite simple — add the right most integer to the previous one to get the next one in the sequence. Starting from zero, this would give you 0-1-1-2-3-5-8-13-21 and so on. If one was to look at this sequence in the form of geometric shapes, they can create square tiles whose sides are the length of the value in the sequence. If you connect the diagonal corners of these tiles with an infinite curve, you end up with the spiral that you saw in the pine cone and other natural objects.
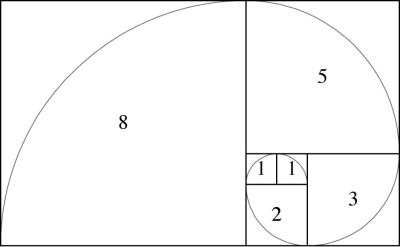
So how did mother nature discover this geometric structure? Surely it does not know math. How then can it come up with intricate and sophisticated structures? It turns out that this Fibonacci spiral is the most efficient way of squeezing the most amount of stuff in the least amount of space. And if one takes natural selection seriously, this makes perfect sense. Eons of trial and error to make the most copies of itself has stumbled upon a mathematical principle that permeates life on earth.

The homo sapiens brain is the product of this same evolutionary process, and has been evolving for an estimated 7 million years. It would be foolish to think that this same type of efficiency natural selection has stumbled across would not be present in the current homo sapiens brain. I want to impress upon you this idea of efficiency. Natural selection discovered the Fibonacci sequence solely because it is the most efficient way to do a particular task. If the brain has a task of storing information, it is perfectly reasonable that millions of years of evolution has honed it so that it does this in the most efficient way possible as well. In this article, we shall explore this idea of efficiency in data storage, and leave you to ponder its applications in the computer sciences.

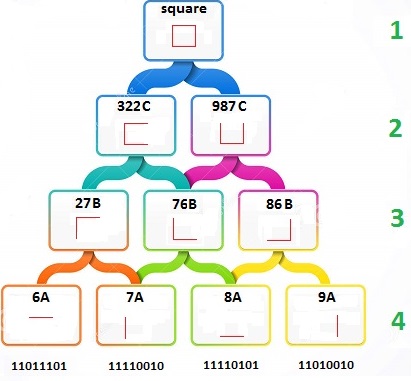
 mind, however, is a simple question Google asked, and the resulting answer. To better understand the process, they wanted to know what was going on in the inner layers. They feed the network a picture of a truck, and out comes the word “truck”. But they didn’t know exactly how the network came to its conclusion. To answer this question, they showed the network an image, and then extracted what the network was seeing at different layers in the hierarchy. Sort of like putting a serial.print in your code to see what it’s doing.
mind, however, is a simple question Google asked, and the resulting answer. To better understand the process, they wanted to know what was going on in the inner layers. They feed the network a picture of a truck, and out comes the word “truck”. But they didn’t know exactly how the network came to its conclusion. To answer this question, they showed the network an image, and then extracted what the network was seeing at different layers in the hierarchy. Sort of like putting a serial.print in your code to see what it’s doing. This technique gives them the level of abstraction for different layers in the hierarchy and reveals its primitive understanding of the image. They call this process
This technique gives them the level of abstraction for different layers in the hierarchy and reveals its primitive understanding of the image. They call this process