The PalmPilot doesn’t seem to get much retrocomputing love, but maybe it should. After all, it might not have been the very first handheld, but it was probably the most successful, and that ultimately led to the era of the smartphone. Whether you miss your old Palm applications, or never got to experience them the first time around, fear not. You can now relive them in all their glory in your browser thanks to the Internet Archive project.
There are over 500 applications and games all running in a browser-based emulator. Some of the programs don’t seem to work well, and some don’t make sense in the context of a virtual environment. But many work fine, and if you want the classic apps, just open up anything and press the home button. If you want a review of the Palm IIIe PDA from 1999, check out [VWestlife’s] video, below.
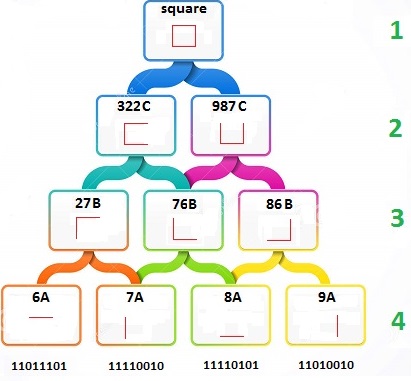
The Grafitti handwriting recognition system was state-of-the-art for the day. The key was the system could more easily recognize printing if it were mostly single strokes that always worked the same way. For example, the “A” had no crossbar and the “F” was missing the bottom horizontal line. As much as possible, you make letters with a single stroke and there was only one way to form each letter. Good times!
What was high tech back then you can now build out of spare parts. If you happen to have a Palm, you might consider giving it a much-needed backlight.
Continue reading “The PalmPilot Returns, This Time In Your Browser”