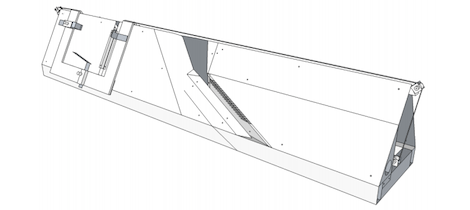

It’s no secret that Google has been scanning hundreds of thousands of books in the hope of recreating the Library of Alexandria. Publishers and authors really didn’t like that idea, so the Google books team is doing the next best thing: they’re releasing the plans for a very clever book scanner in the hope others will pick up the torch of creating a digital library of every book ever written.
Unlike some other book scanners we’ve seen that rely on an operator manually flipping pages, this linear book scanner turns the pages automatically with the help of a vacuum cleaner and a cleverly designed sheet metal structure after passing them over two image sensors taken from a desktop scanner.
The bill of materials comes in at around $1500, but according to the official design documents this includes a very expensive scanner, something that could be replaced in true hacker style with a few salvaged flatbed scanners.
After the break you can check out a Google Tech Talk presented by [Dany Qumsiyeh] going over the design and function of his DIY book scanner. There’s also a relatively thorough design document over on a Google code page.
[youtube=https://www.youtube.com/watch?v=4JuoOaL11bw&w=470]














this is great, a proven design that really works.
I love the fact it’s open source, and they’ve provided complete plans in the pdf to build the thing.
It should be possible to half the scan time by having another vacuum slot and scanner in the reverse direction shouldn’t it?
@Fredrik,
He mentions that the factor limiting speed was due to their particular stepper motor not being powerful enough to go faster. That can be changed.
Near the end of the presentation he talks about scaling it up. One idea is that a single operator could keep about 10 of these machines loaded and scanning, making the human more efficient.
Another idea was a drawing of a stretched model with a dozen page flipping mechanisms and scanners, and a conveyor belt carrying several carriages with books one way over the scanners, a return belt path that included unfinished books, and two operators. The forward passes would each scan two dozen pages from each book, and it would carry multiple books at the same time. The far end operator would send back the books that hadn’t completed scanning.
If I was a librarian I’d be horrified if someone turned up with this contraption. I guess Google did it all by hand at the libraries they were allowed to digitize.
Nice work though and with a bit more development it could be very good. If building one to the plans I would use 3mm Foamex board instead of stainless steel. It’s as easy to work as cardboard but totally dimensionally stable and hard wearing.
Why are you horrified?
Probably the back and forth motion over stainless steel. It does look more than a little like a cross between a bucking bronco and a table saw.
It’s a clever design, but compared to the earlier diybookscanner its harder on the books.
“Hello, may I put all your books into my electric guillotine?”
That does not look like it’s gentle on the books at all.
@Zee,
The presenter mentions that about 40% of books scanned have some kind of problem, either a folded or a torn page, but they’ve done some work on preventing problems.
But, he talked to an archivist, who pointed out that risks of damage are always present for any library book. And the risks of losing the information forever are higher than the risks of damage from scanning it once.
And compare this device to the common book scanning method of sawing off the binding and feeding the pages through a sheet scanner. Much less damaging.
I beg to differ. The 100k scanners are certified to be gentle on the books. He says so himself in the presentation.
Even if they’re “certified” if it grabs a damaged page, it can still tear it out. Like the saying goes, “shit happens”.
Yeah but guess what that guarantee does? If they wreck your book, they’ll buy you a new one up to a certain cost.
My problem with this is that opening the book FLAT is damaging to some rare books. the manual page turn V shaped ones work best for rare one of a kind books that you dont want to damage.
@fartface
What are you talking about, the books aren’t opened flat, they’re moved over a V shaped scanner.
Looks like someone might have hit the comments before watching the video or reading the linked article. :-)
It’s amazing that if I were to do this, the feds would swoop in and beat me down like Kim.com but since it’s Google there’s no problem.
Because Google is only dealing with out of copyright or works with no copyright claimed, or ones they have got licenses too.
The contaversy of Google Books was if anyone had the right to publish orphaned works.
This is quite different to megaupload that was hosting things with very well known copyright owners.
Both had some dodgyness to the decisions, but there is a clear difference here.
I hardly think that this needs to be this large, I’m sure a much smaller and effective version could be made for much cheaper, however I don’t hold enough interest in this to theorise, just seems overdone, but the whole vacume method to turn a page should be able to be shrunk. Perhaps a vacume suction cup like in automated assembly lines.
crap, i did theorise. oh well.
i was wondering wich scanner has two imaging sensors in it.
Practically any scanner or MFP printer that says it does duplex single pass scanning has two scanner bars. Another words probably about 40% of the market. There are probably a lot of scanners as well that are not duplex capable but the board that comes with the scanner is capable of doing so. i.e. one board used by an entire product suite to reduce overall design count by the mfr.
$750 one, as author mentioned scanner is half the cost.
I you are on a budget, you could build it with just one sensor, scanning only one side, rotate the book 180 degrees, and then scan all opposite pages.
I like the design but agree it could be done with a smaller footprint. He does mention some methods to address this and I understand the ‘let us get it working first then optimize’ approach.
To address the margins issue, the photo arrays could be mounted parallel to the wall and use a long and thin 90 degree prism to refract the image along the correct plane. This would get them much closer to the edge of the margin. Of course the image would be mirrored but an easy post processing fix.
That’s not Google’s book scanner, that’s some guy’s beta book scanner he brought to Google to demo
He is a Google employee. He developed it during his 20% time.
There have been ideas passed around to convert public libraries into places to use tools (kind of like a hacker space). I’d love for my local library to have one of these I could reserve to scan my own journals. Doesn’t make sense to build one myself to scan only a few thousand pages.
If anyone in Salt Lake City does build one, I’d love to use it for an afternoon :)
A wonderful build and some very elegant solutions.
Is there working link to the scanner software somewhere?
There is a new scanner out of Tokyo or somewhere in Asia that can flip the pages and take pictures of each page. It uses lasers to re-align bends in the images where motion created bending along the normal curvature of the book. It can go through an entire large book in about 10 seconds. I wonder what the benefits of this vs that are.
Cost. Definitely Cost.
A quicker and dirtier way. Cut the spine of the book using a bandsaw, then feed the pages though a photocopier scanner sheet feeder. Once done comb bind it or recyle the lot.
Bandsaw? Most printing places have a guillotine cutter that can cut up to 1000 pages cleanly in one cut. Much quicker, cleaner and easier than a bandsaw.
I can udnerstand this for the old books. But for recent books, wouldnt it be easier to get the soft copy directly from the publishers? Do they do that for newer books?
This is a nice project. I am planning to built the structure. I am confused about the vaccum structure. Can you help me guide how to join the pieces you mentioned in your PDF file for the vaccuum section?
how did you able to interface scanner, scanner usually calibrates whenever it is powered, how can u change it to calibrate through this structure.
They attached the white calibration surface to the saddle that holds (and moves) the book. When powered up, the scanner will calibrate using that.
I used a similar size glass with white strips but my scanner didn’t work. It gives an error, but whenever i place all the components back to casing, it works fine. its a Canon LiDE 110
Is the software they used (make photo and compensate for curved pages) availavle?